 Image: AI generated
图片:AI生成
Image: AI generated
图片:AI生成
如果你正在经历AI覆盖代码的问题,如果vibe coding在200个端点处崩溃了,如果你想把AI的工作对象从代码换成声明式规范——yongol就是那根龙骨。
第200个端点
用氛围编程构建SaaS。起初很快。5张表、12个端点——20分钟就能跑起来。
但超过50个端点后,奇怪的事情开始发生。AI今天创建的模式与昨天的矛盾。超过100个,已有功能悄然崩坏。超过200个,添加一个新功能的时间是最初10个的10倍。
DORA 2025报告用实证数据证明了这一点——AI工具将吞吐量提高了2-18%,但同时增加了变更失败率和返工[1]。AI是放大现有流程弱点的"镜子和乘数"。
不是模型太笨。
决策与实现
源代码中混杂着三种东西:
- 用户决策 —— 这个列是
BIGINT,这个端点仅限所有者访问,分页使用游标方式。 - 业务逻辑 —— 定价策略、工作流程、生命周期规则。
- 实现细节 —— 变量名、库调用顺序、错误包装。
AI读取这段代码时,无法分辨哪行是决策、哪行是细节。因此在"重构"或"整理"时,它会将决策误认为细节并悄然覆盖。用户直到行为已经出错后才会发现。1972年Parnas说"将可能变更的设计决策隐藏在接口之后"[2]时,他是在对人说的。但现在AI也在编辑代码,如果决策与细节的区分不存在于媒介本身,那么没有人——无论人类还是模型——能维护这种区分。
这就是氛围编程在200个端点处崩溃的原因。更大的模型也无法解决。**媒介(原始代码)本身无法保留决策。**所有模型最终都会撞上同一堵墙。
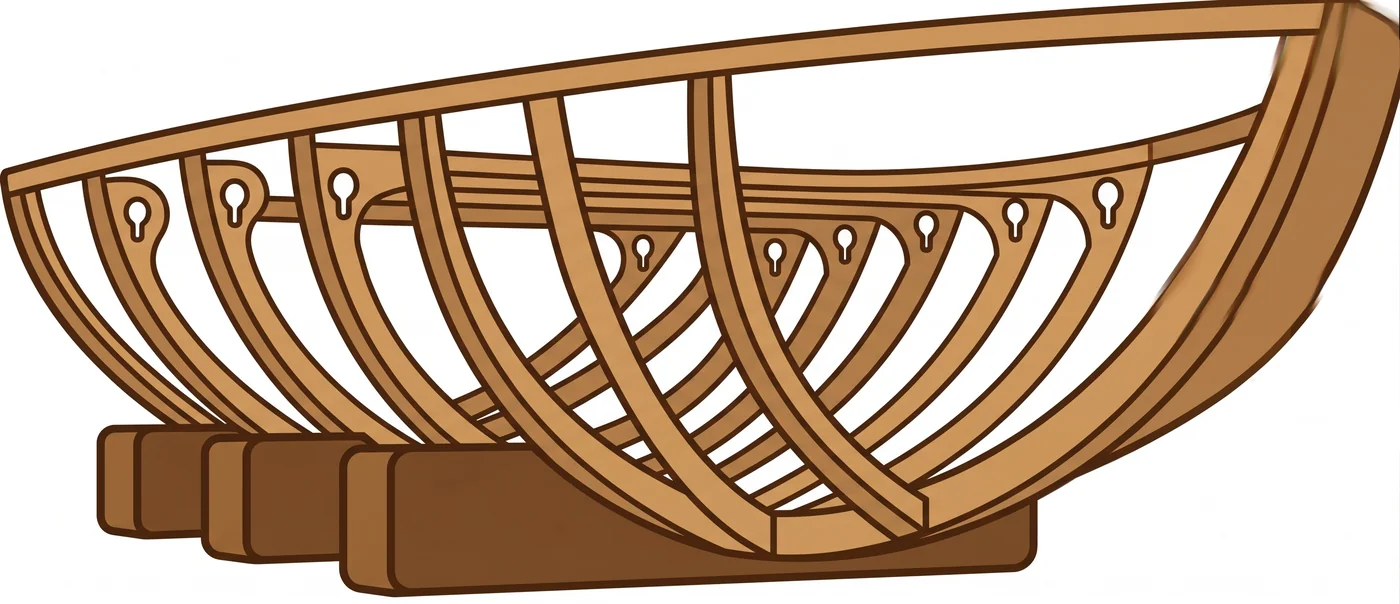
龙骨
造船时最先铺设的骨架就是龙骨。它承载船体的重量,防止左右摇晃,所有其他结构都建在龙骨之上。没有龙骨的船在平静的水面上能浮起来,但浪来了就会变形。
用氛围编程构建的SaaS也是如此。小的时候能浮起来。大了就会变形。
yongol是AI编程SaaS的龙骨。
Harness with reins —— 不是更大的模型,而是更精确的缰绳。确定性验证器判定每个产出物,棘轮强制推进,由机器决定任务是否完成。
将决策移出代码
yongol的核心很简单。将决策从代码中分离。
10个声明式规范(SSOT)各负责一个关注点:
| SSOT | 职责 |
|---|---|
| features.yaml | 功能目录——要构建什么 |
| manifest.yaml | 项目配置——认证、中间件、基础设施 |
| OpenAPI | API契约——路由、参数、响应 |
| SQL DDL + sqlc | 数据模型——表、列、约束、查询 |
| SSaC | 服务流程——端点内部的决策顺序 |
| Rego | 授权策略——谁能做什么 |
| Mermaid stateDiagram | 状态转换——实体的生命周期 |
| FuncSpec | 自定义函数——无法用CRUD表达的逻辑 |
| Hurl | 测试场景——smoke、scenario、invariant三分类 |
| STML | 前端——语义模板标记语言(基于data-*属性的HTML) |
10种中有8种是行业标准(OpenAPI、SQL、sqlc、Rego、Mermaid、Hurl、YAML)。只有SSaC和STML是yongol创建的DSL。AI需要从头学习的内容降到最低。
每个SSOT只包含决策。没有实现细节。AI编辑SSOT,yongol generate从中渲染代码。决策永久存活在SSOT中,代码只是一次性投影。
强制一致性
决策分散到了10个文件中,因此可能出现矛盾。DDL中是BIGINT但OpenAPI中是string?SSaC声明了@auth但Rego中没有对应规则?状态图中有转换但SSaC中没有对应函数?
矛盾的SSOT就是被污染的决策。代码再干净,决策有冲突,行为就会出错。
yongol validate捕获这些问题。
✓ manifest ✓ openapi_ddl ✓ ssac_rego
✓ openapi ✓ openapi_ssac ✓ ssac_authz
✓ ddl ✓ hurl_openapi ✓ ssac_sqlc
✓ query ✓ hurl_statemachine ✓ ddl_statemachine
✓ ssac ✓ hurl_manifest ✓ ddl_rego
✓ statemachine ✓ openapi_manifest ✓ rego_manifest
✓ rego ✓ ssac_ddl ✓ stml_openapi
✓ hurl ✓ ssac_statemachine
✓ funcspec ✓ ssac_func
0 errors, 0 warnings
先对每个SSOT单独验证,然后进行跨层交叉验证。约287条规则检查10个SSOT之间的所有符号引用。只要存在一个矛盾,就拒绝编译。Torres等人的系统文献综述[3]指出,大多数模型管理工具仅处理单一模型内部的一致性,异构模型间的交叉验证仍是未解决的课题——yongol validate填补的正是这个空白。
AI自由书写。偏离轨道,validate立即捕获。轨道上的自由。
yongol next —— 棘轮命令
yongol validate一次性显示所有错误,而yongol next逐个显示错误。这就是棘轮。
$ yongol next specs/
[ERROR] DDL-003: users.id must be BIGINT, got INT
file: specs/db/users.sql:2
▶ Fix this error. Then run `yongol next specs/`.
给AI代理的指令只需一句话:“运行yongol next specs/,修复错误直到为0。”
修复一个错误,下一个出现。全部通过则停止:
$ yongol next specs/
✓ All validations passed. 0 errors.
不是代理宣布"我完成了",而是机器裁定"还有剩余"或"全部通过"。终止判断权不在代理手中。
项目创建与功能管理
yongol init
从features.yaml自动生成SSOT脚手架。
yongol init Myapp features.yaml "My workflow automation SaaS"
cd Myapp && yongol validate specs # 0 errors
manifest、OpenAPI operationId桩、SSaC桩文件、Rego授权规则、Hurl冒烟测试、sqlc配置一次性生成。项目从一开始就处于yongol validate通过状态。
yongol features add / remove
添加或删除功能:
yongol features add new_features.yaml # 为新operationId生成SSaC桩
yongol features remove ExportWorkflow --yes # 删除operationId + SSaC桩
yongol import
从外部OpenAPI规范(Stripe、GitHub等)生成Go客户端包:
yongol import https://api.stripe.com/openapi.yaml ./external/
在SSaC中使用@call <pkg>.<Func>({...})调用生成的函数。
operationId是基石
如何将10个层绑定在一起?用一个PascalCase标识符。
输入operationId ExecuteWorkflow:
── Feature Chain: ExecuteWorkflow ──
OpenAPI api/openapi.yaml POST /workflows/{id}/execute
SSaC service/workflow/execute_workflow.ssac @get @empty @auth @state @call @publish @response
DDL db/workflows.sql CREATE TABLE workflows
DDL db/execution_logs.sql CREATE TABLE execution_logs
Rego policy/authz.rego resource: workflow
StateDiag states/workflow.md diagram: workflow → ExecuteWorkflow
FuncSpec func/billing/check_credits.go @func billing.CheckCredits
FuncSpec func/billing/deduct_credit.go @func billing.DeductCredit
FuncSpec func/worker/process_actions.go @func worker.ProcessActions
FuncSpec func/webhook/deliver.go @func webhook.Deliver
Hurl tests/scenario-happy-path.hurl scenario: scenario-happy-path.hurl
从API规范到数据库模式,从授权策略到状态转换,从函数实现到测试场景——一个功能的完整拓扑在一个屏幕上呈现。数十次grep被一个命令取代。
operationId之所以是基石,是因为在全栈应用中,功能的单位是API端点。用户按下按钮,API被调用,该API贯穿所有其他层。一个名称将10个层物理串联。
SSaC —— 为什么要自定义DSL
yongol的10个SSOT中有8个是行业标准。只有SSaC(Service Sequences as Code)和STML是yongol创建的。SSaC捕获服务流程决策。
SSaC填补的空白。 看看声明式工具的光谱:一端是契约标准(OpenAPI、SQL、Rego)——它们声明什么但不声明以什么顺序。另一端是工作流运行时(Temporal、Inngest、Restate)——那些是代码。决策和实现细节在同一个文件中重新混合。SSaC坐在中间的空白处:“在一个端点内部,发生什么,以什么顺序,带什么守卫。”
SSaC共有16个注解。一页手册即可学会。
SSaC注解完整列表
| 注解 | 角色 | 格式 |
|---|---|---|
@get | 数据库查询 | Type var = Model.Method({args}) |
@post | 行创建 | Type var = Model.Method({args}) |
@put | 行更新(无返回) | Model.Method({args}) |
@delete | 行删除 | Model.Method({args}) |
@empty | nil守卫 → 404 | var "message" [STATUS] |
@exists | not-nil守卫 → 409 | var "message" [STATUS] |
@auth | 授权验证 | "action" "resource" {inputs} "message" [STATUS] |
@state | 状态机转换 | diagram {inputs} "transition" "message" [STATUS] |
@call | 函数调用 | [Type var =] pkg.Func({args}) |
@eval | 谓词守卫(true → 错误) | pkg.Func({args}) "message" STATUS |
@publish | 队列发布 | "topic" {payload} |
@subscribe | 队列触发函数 | "topic" |
@verify-password | 登录(时序安全) | Model.col=source Model.hash vs source -> var STATUS "msg" |
@response | JSON返回 | { field: var, ... } 或 var |
@no-pagination | 分页规则豁免 | (函数级别) |
@state-neutral | 状态机规则豁免 | (函数级别) |
SSaC示例 —— AcceptProposal
授权 + 双状态机 + 托管 + 队列:
package service
import "github.com/org/project/internal/billing"
// @get Proposal p = Proposal.FindByID({ID: request.id})
// @empty p "Proposal not found" 404
// @get Gig gig = Gig.FindByID({ID: p.GigID})
// @empty gig "Gig not found" 404
// @auth "AcceptProposal" "gig" {ResourceID: request.id} "Forbidden" 403
// @state proposal {status: p.Status} "AcceptProposal" "Cannot accept" 409
// @state gig {status: gig.Status} "AcceptProposal" "Cannot accept on gig" 409
// @put Proposal.UpdateStatus({ID: p.ID, Status: "accepted"})
// @put Gig.AssignFreelancer({ID: gig.ID, FreelancerID: p.FreelancerID, Status: "in_progress"})
// @call billing.HoldEscrowResponse escrow = billing.HoldEscrow({GigID: gig.ID, Amount: gig.Budget})
// @publish "proposal.accepted" {GigID: gig.ID, FreelancerID: p.FreelancerID}
// @get Proposal updated = Proposal.FindByID({ID: p.ID})
// @response { proposal: updated }
func AcceptProposal() {}
16行。10个注解。两个状态机、授权、托管、队列事件、响应——每个决策可见,每个细节缺席。
基准测试:ZenFlow
ZenFlow——多租户工作流自动化SaaS。
| 阶段 | 内容 | 时间 | 累计 |
|---|---|---|---|
| 初始构建 | 10个端点、6张表、认证、状态机 | 13分钟 | 13分钟 |
| + 版本管理 | 工作流复制、版本列表 | 6分钟 | 19分钟 |
| + Webhook | webhook CRUD、队列后端 | 6分钟 | 25分钟 |
| + 模板市场 | 游标分页、跨组织复制 | 3分钟 | 28分钟 |
| + 文件附件 | 执行报告、文件后端 | 4分钟 | 32分钟 |
| + 定时调度 | cron调度、会话后端 | 6分钟 | 38分钟 |
| + 审计日志 | 偏移量分页、缓存后端 | 3分钟 | 41分钟 |
| + 仪表盘 | 关联连接、func响应类型 | 7分钟 | 48分钟 |
| + 批量操作 | jsonb批量插入 | 14分钟 | 62分钟 |
| + 外部API | 地理编码func、添加列 | 3分钟 | 65分钟 |
| + 条件更新 | 哨兵模式、自动分配 | 4分钟 | 69分钟 |
最终:32个端点、14张表、47个Hurl请求。11/11阶段通过。
添加功能从未减速。已有测试从未崩坏。200端点的墙不存在。
Opus 4.7基准测试 —— 32个端点、14张表、47个Hurl请求,约69分钟。 Sonnet 4.6基准测试 —— 32个端点、9张表、37个Hurl请求,约43分钟。
yongol agent
LLM通过validate-fix循环自动修复SSOT文件。
yongol agent specs/ --model ollama:gemma4:e4b --max-rounds 20
将validate错误反馈给LLM,LLM进行修复,再次验证。循环重复直到0错误。本地4.5B模型(Gemma4)也能工作。
支持的后端:ollama(本地)、xai(Grok)、gemini。
能编辑生成的代码吗
可以。yongol generate在重新运行时保留用户编辑:
- 每个生成的文件都带有
//yg:checked llm=yongol-gen hash=<8hex>注解。 - 如果哈希不同,该文件被标记为**保留(preserved)**状态,下次
generate时跳过。 yongol status显示保留文件和契约漂移(PRV-01/PRV-02错误)。- 要记录意图,添加
//yg:preserve reason="..."(可选)。要取消保留,删除文件。
内置函数与模型
内置函数(在SSaC中通过@call调用)
| 包 | 函数 | 说明 |
|---|---|---|
auth | hashPassword, verifyPassword | bcrypt哈希/验证 |
auth | issueToken, verifyToken, refreshToken | JWT令牌 |
auth | generateResetToken | 密码重置 |
crypto | encrypt, decrypt | AES-256-GCM |
crypto | generateOTP, verifyOTP | TOTP |
storage | uploadFile, deleteFile, presignURL | S3 |
mail | sendEmail, sendTemplateEmail | SMTP |
text | generateSlug, sanitizeHTML, truncateText | 文本处理 |
image | ogImage, thumbnail | 图片生成 |
内置模型(通过manifest.yaml配置)
| 包 | 接口 | 后端 | SSaC用法 |
|---|---|---|---|
session | SessionModel (Set/Get/Delete + TTL) | PostgreSQL, Memory | session.Session.Get({key: ...}) |
cache | CacheModel (Set/Get/Delete + TTL) | PostgreSQL, Memory | cache.Cache.Set({key: ..., value: ..., ttl: ...}) |
file | FileModel (Upload/Download/Delete) | S3, LocalFile | file.File.Upload({key: ..., body: ...}) |
queue | singleton Pub/Sub (Publish/Subscribe) | PostgreSQL, Memory | @publish "topic" {payload} |
DDL迁移自动生成
yongol generate检测DDL变更并自动生成迁移文件。
specs/db/
└── users.sql # SSOT —— 在这里编辑
artifacts/db/
├── .latest_schema.sql # 基线快照
└── migrations/
├── 0001_initial.up.sql
├── 0001_initial.down.sql
├── 0002_add_users_email.up.sql
└── 0002_add_users_email.down.sql
模糊变更(列重命名、类型转换、NOT NULL回填)通过DDL注释提示(-- @rename、-- @cast、-- @backfill、-- @data_migration、-- @allow_destructive)消除歧义。6条规则(MIG-001到MIG-006)把关危险变更。实际的数据库应用委托给golang-migrate、flyway等标准工具。
为什么更大的模型不是答案
“GPT-6出来就解决了。”
解决不了。问题不在于模型的智力,而在于媒介。
代码作为媒介不区分决策与实现。无论什么模型读取代码,看到的都是决策与细节交织的文本。模型再聪明,如果媒介不提供区分,模型就无法区分。
yongol改变了媒介。它将AI编辑的对象从代码转移到声明式规范。规范中只有决策,没有实现细节,因此AI永远不会将决策误认为细节。决策的存活与模型大小无关。
小型LLM只编辑SSOT,validate对每个错误提供精确反馈,就能维持与更大模型编辑原始代码相同的决策完整性。yongol弥合了这个差距。
运行时测试
Hurl测试全部由用户编写。在specs/tests/中编写,yongol generate镜像到artifacts/tests/。验证时XOH-01到XOH-09规则将Hurl与OpenAPI、状态机、manifest.auth进行交叉验证。
hurl --test --variable host=http://localhost:8080 artifacts/my-project/tests/*.hurl
三种分类:
- smoke.hurl —— 端点冒烟测试
- scenario-*.hurl —— 业务场景测试
- invariant-*.hurl —— 跨端点不变式测试
当前状态
Go+Gin后端生成:Beta —— 端到端可用。React前端生成:Alpha(开发中)。
开始使用
方法一:安装技能(推荐)
npx skills add park-jun-woo/yongol
将yongol技能安装到你的AI代理(Claude Code、Cursor、Copilot等)中。代理会自动学习工作流。
/yongol 构建一个带认证和CRUD的多租户待办SaaS。
方法二:直接安装
需要Go 1.25+和gcc(cgo依赖:pg_query_go链接libpg_query用于DDL解析)。
git clone https://github.com/park-jun-woo/yongol && cd yongol
make install
yongol validate examples/zenflow
0 errors, 0 warnings。
在这些规范上让AI添加功能试试。validate铺设轨道,AI在轨道上奔跑。没有墙。
相关文章
- SSaC — Service Sequences as Code — yongol的基石DSL。声明端点内部的决策。
- Feature Chain — 用一个operationId追踪全栈 — 通过单个operationId贯穿8个层的追踪。
- Ratchet Pattern — 如何让代理走到终点 — validate向代理反馈的结构的理论基础。
- IFEval逆向利用的棘轮代码 — 利用谄媚偏差的代码生成循环与Reins。
代码:github.com/park-jun-woo/yongol
变更记录
| 日期 | 变更内容 |
|---|---|
| 2026-05-18 | 首次发布 |
| 2026-05-19 | 添加Opus基准测试。更新10个SSOT |
| 2026-05-21 | README同步:更新基准测试(Opus 32ep/14tbl/47hurl/69min,Sonnet 32ep/9tbl/37hurl/43min),添加"Harness with reins"声明,添加SSaC示例(AcceptProposal),添加yongol agent命令,添加Preserve系统,添加内置函数/模型列表,添加DDL迁移自动生成,添加STML说明,添加ifeval-ratchet相关文章链接 |
| 2026-05-26 | v0.6.10同步:添加yongol next棘轮命令,添加yongol init/features add/features remove项目创建与管理,添加yongol import外部OpenAPI导入,添加SSaC注解完整列表(16个)(@eval、@subscribe、@verify-password、@no-pagination、@state-neutral),Hurl测试三分类(smoke/scenario/invariant),运行时测试章节,Preserve详情(PRV错误代码),DDL迁移提示扩展(@data_migration、@allow_destructive、MIG规则),当前状态(Go+Gin Beta、React Alpha),安装方法分为2种 |
出处
- Google DORA Team. DORA State of AI-Assisted Software Development 2025. Google Cloud, 2025. dora.dev/dora-report-2025
- David L. Parnas. “On the Criteria to Be Used in Decomposing Systems into Modules.” Communications of the ACM 15(12): 1053-1058, 1972. doi:10.1145/361598.361623
- Weslley Torres, Mark G.J. van den Brand, Alexander Serebrenik. “A Systematic Literature Review of Cross-Domain Model Consistency Checking by Model Management Tools.” Software and Systems Modeling 20(3): 897-916, 2021. doi:10.1007/s10270-020-00834-1
- Deepak Babu Piskala. “Spec-Driven Development: From Code to Contract in the Age of AI Coding Assistants.” arXiv:2602.00180, January 2026. arxiv.org/abs/2602.00180
- Ehsani et al. “When AI Code Doesn’t Stick: An Empirical Study on Reverted Changes Introduced by AI Coding Agents.” MSR 2026 Mining Challenge, April 2026. 2026.msrconf.org
- Anton Jansen, Jan Bosch. “Software Architecture as a Set of Architectural Design Decisions.” EWSA 2005, LNCS 3527, Springer, 2005. semanticscholar.org
- Marco Brambilla, Jordi Cabot, Manuel Wimmer. Model-Driven Software Engineering in Practice. 2nd ed., Springer, 2017. doi:10.1007/978-3-031-02546-4
- GitClear. AI Copilot Code Quality 2025. February 2025. gitclear.com