 Image: AI generated
Image: AI generated
聪明的人不一定擅长解释
让 Opus 4.8 做代码重构,结果令人惊叹。它一次性理清复杂的依赖关系图,先发制人地处理边缘情况,测试也写得滴水不漏。然而,当你让它解释结果时,问题就来了。它像专家向专家汇报一样说话——默认你们共享背景知识,省略关键判断的理由,抽象层次不必要地高。
用 Opus 4.6 问同样的问题,结果截然相反。它善于推测你可能不了解什么,精心选择比喻,分步骤讲解,先铺垫上下文。但当推理难度上升时,它在 4.8 一次就能解决的问题上开始卡壳。
一句话概括:Opus 4.8 很聪明但说话晦涩,Opus 4.6 解释通俗易懂但推理性能较低。
这不是缺陷。为什么会这样,以及如何将这种差异转化为结构性优势——这就是本文的主题。
知识的诅咒同样适用于 LLM
1989年,心理学家 Camerer、Loewenstein 和 Weber 通过实验证明:掌握信息越多的人,越难意识到对方并不知道这些信息。这种被称为"知识的诅咒(Curse of Knowledge)“的现象,是在教育学、经济学和用户体验设计中反复得到验证的认知偏差。
Oliver Wendell Holmes 说过:“复杂性这一侧的简单,我一分钱也不会给。但复杂性那一侧的简单,我愿意以生命相托。“通俗的解释并非因为无知才简单,而是穿透复杂之后才成为可能。然而矛盾的是,身处复杂之中时,用简单语言表达的能力反而会下降。
2025年的 EMNLP 论文表明,这一现象在大规模推理模型中同样存在。推理能力越强的模型,对知识的诅咒反而越脆弱——这是一个悖论性的发现。深度推理的模型会隐含地假设对方也能跟上自己的推理过程。这正是人类专家向初学者解释时遇到的那个问题。
因此世界上存在两种角色:深入思考的人和通俗传达的人。研究者与科学传播者、资深开发者与技术负责人、法官与律师。这是两种不同的能力。如果一个人两者兼备当然很好,但现实中极为罕见。所以组织才会进行角色分工。
LLM 也是如此。而 Claude Code 只需一行配置就能实现这种分工。
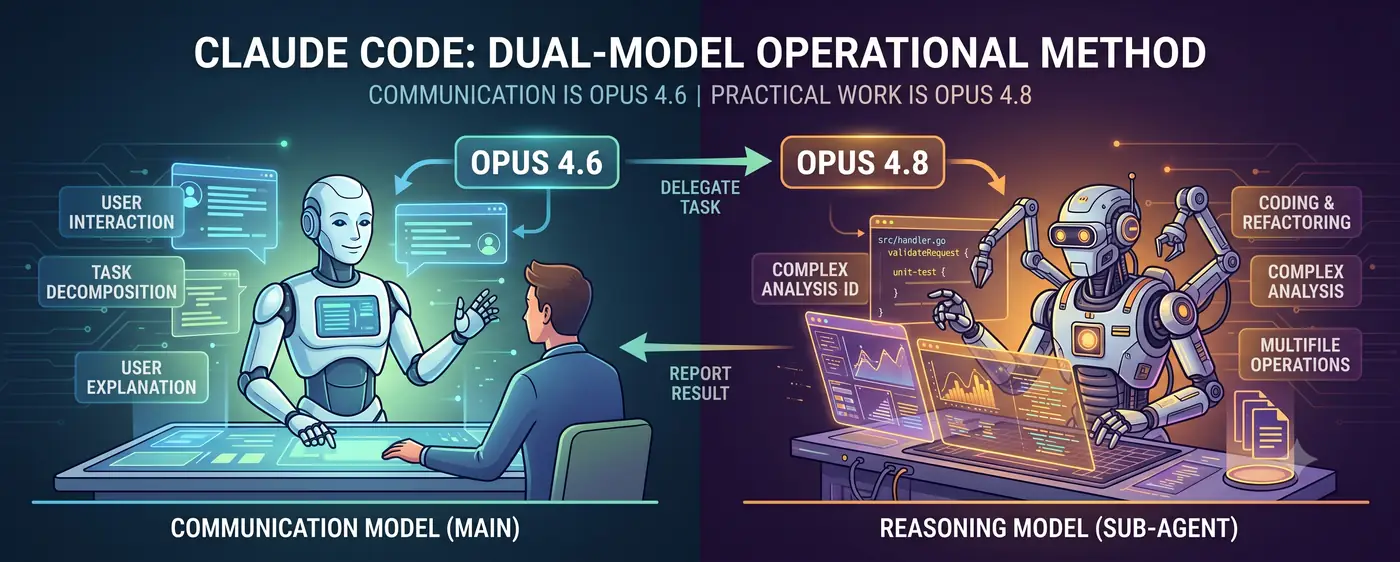
沟通模型 + 推理模型
核心架构很简单。
用户 ↔ 沟通模型(主模型) ↔ 推理模型(子智能体)
- 沟通模型(Opus 4.6)站在对话的前线。它理解用户意图,分解任务,并用人类能理解的语言汇报结果。
- 推理模型(Opus 4.8)负责实际工作。代码编写、复杂分析、多文件重构等高难度推理任务,以子智能体的形式委派执行。
用户与 4.6 对话。当 4.6 判断"这个任务的推理难度超出我的直接处理能力"时,它会创建一个 4.8 子智能体并委派任务。4.8 返回结果后,4.6 对其进行解读,再向用户说明。
这篇文章本身就是证据。正在撰写这篇文章的是 Opus 4.6(主模型),而为本文提供依据的学术论文检索和基准数据分析则由 Opus 4.8(子智能体)完成。
基准测试告诉我们什么
从 BenchLM 数据可以看到两个模型的特性差异以数字呈现。
| 领域 | Opus 4.6 | Opus 4.8 | 优势 |
|---|---|---|---|
| 综合 | 86 | 93 | 4.8 |
| 编程 | 64.4 | 76.4 | 4.8 |
| Agent 任务 | 72.6 | 80.1 | 4.8 |
| 知识任务 | 76.2 | 70.1 | 4.6 |
| 创意写作 | 优势 | - | 4.6 |
在编程和 Agent 任务方面,4.8 具有压倒性优势。但在知识传达和创意写作方面,4.6 更胜一筹。Claude API 评测中也反复出现 4.8 的写作比 4.6"更像 AI(more AI-sounding)“的评价。4.8 推理精准,但将推理结果用人类易读的方式展开的能力,4.6 更强。
两个模型价格相同——输入每百万 token 5 美元,输出每百万 token 25 美元。角色分工不会增加成本。这不是成本优化,而是纯粹的质量优化。
模型路由已是经过验证的工程实践
“分开使用两个模型"的想法并不新鲜,在学术界已是成熟领域。
RouteLLM(ICLR 2025)通过根据查询难度在强模型和弱模型之间动态路由,在保持质量的同时将成本降低了2倍以上。FrugalGPT(2023)通过 LLM 级联,以 98% 的成本节省达到了 GPT-4 级别的性能。这些研究的共同结论很明确:编排出色的弱模型,往往胜过编排粗糙的强模型。
Anthropic 自己也在使用这种模式。Anthropic 的 deep-research 实现采用了编排者-执行者模式,多智能体配置在 90.2% 的情况下超越了单智能体 Opus 4。调查结果也显示,约 80% 的生产级多智能体系统采用编排者-执行者架构。
我所做的只是这种模式的最简形态。没有路由器,没有级联,也没有成本优化。仅仅是让擅长沟通的模型站在前台,让擅长推理的模型在幕后工作。这就是角色分离原理本身。
配置方法
在 Claude Code 中搭建这个架构很简单。
第一步:设置主模型
以 Opus 4.6 运行 Claude Code。在设置中将默认模型指定为 claude-opus-4-6-20250610,或在启动时选择模型。这将作为与用户对话的沟通模型。
第二步:为子智能体设置模型覆盖
Claude Code 的 Agent 工具支持 model 参数。创建子智能体时,将模型覆盖为 opus(Opus 4.8)即可。
Agent({
description: "코드 리팩토링",
model: "opus",
prompt: "src/handler.go의 validateRequest 함수를..."
})
就这样。主智能体(4.6)与用户对话,高难度任务委派给子智能体(4.8)。
第三步:区分 fork 和 fresh agent
Claude Code 的子智能体分为两种。
- fork(
subagent_type: "fork"):直接继承当前对话的上下文。由于共享 prompt 缓存,输入成本最多可节省 90%。但 fork 强制继承父模型,因此模型覆盖不会生效。 - fresh agent:从全新的上下文开始。可以进行模型覆盖。需要在 prompt 中手动提供所需的背景信息。
因此,要使用推理模型(4.8),必须创建 fresh agent。fork 适用于保持沟通模型(4.6)的同时进行并行探索的场景。
实战模式
| 场景 | 方法 | 原因 |
|---|---|---|
| 复杂代码编写 | fresh agent + model: opus | 推理难度高 |
| 多文件重构 | fresh agent + model: opus + isolation: worktree | 推理 + 需要隔离 |
| 并行调研/探索 | fork(保持 4.6) | 共享上下文更有利 |
| 简单文件读取/编辑 | 主模型(4.6)直接处理 | 委派开销更大 |
| 网络搜索/调研 | fresh agent + model: opus | 需要精确推理 |
同时运行 4 到 8 个 worktree 是稳定的。超过这个数量,审查结果会成为瓶颈。
已知的摩擦
并不完美。目前已知有两个限制。
第一,模型覆盖泄漏问题。子智能体的 model 设置可能会传播到该子智能体创建的下级智能体。可能会发生意外的模型使用,因此将子智能体深度限制为一层是务实的做法。
第二,缺乏按智能体类型配置模型的功能。目前 Claude Code 官方不支持在项目设置中按智能体类型预先指定模型。每次调用 Agent 时都需要显式指定 model 参数。社区对这一功能的呼声也很活跃。
这两个问题都会随着 Claude Code 的演进而得到解决。即便在当前状态下,仅凭手动覆盖就足以享受这种架构的优势。
沟通者与思考者是不同的角色
在法庭上,法官和律师处理的是同一部法律,但角色不同。法官做出判决,律师向当事人解释判决的含义。如果法官直接向当事人宣读判决书,当事人听不懂。如果律师直接做出判决,依据会不充分。角色分离不是系统的弱点,而是优势。
代码审查也是如此。资深开发者发现 bug 的能力和向初级开发者解释这个 bug 的能力是两回事。优秀的工程师同时也是优秀的技术作者,这种情况很少见。组织知道这一点,所以才分工。
AI 也一样。推理能力和沟通能力是不同的维度。而在当前的模型训练过程中,这两个维度有相互冲突的倾向。将推理性能最大化,输出就会变得压缩和专业化;将沟通性能最大化,推理的深度就会变浅。
要求一个模型两者都做到最好,就像要求法官同时担任律师一样。做得到,但两者都不会是最优的。
沟通模型与推理模型的分离是一种即使版本更迭也依然有效的结构性原理。 4.6 和 4.8 只是今天的具体选择。明天如果出了 5.0 和 5.2,按同样的原理重新部署就行了。模型会更替,但"深入思考的角色"和"通俗传达的角色"是不同的——这个事实不会更替。
相关文章
延伸阅读(外部)
- RouteLLM: Learning to Route LLMs with Preference Data — 根据查询难度在强模型和弱模型之间动态路由的框架。
- Anthropic: How we built our multi-agent research system — Anthropic 用编排者-执行者模式实现 deep-research 的方法。
参考文献
- Camerer, C., Loewenstein, G. & Weber, M. (1989). The Curse of Knowledge in Economic Settings: An Experimental Analysis. Journal of Political Economy, 97(5), 1232-1254. DOI — 知识的诅咒的实验证明。
- Li, W. et al. (2025). Curse of Knowledge: Your Guidance and Provided Knowledge are biasing LLM Judges in Complex Evaluation. Findings of EMNLP 2025. arXiv — 发现推理能力更强的模型对知识的诅咒更脆弱。
- Ong, I. et al. (2025). RouteLLM: Learning to Route LLMs with Preference Data. ICLR 2025. arXiv — 用偏好数据学习 LLM 路由的框架。