 Image: AI generated
图片:AI 生成
Image: AI generated
图片:AI 生成
本文有两个目的。教人学会设计 Quest,给智能体一份打造 Quest CLI 的蓝图。前半部分(Part 1·2)讲为什么,后半部分(Part 3·4·5)讲怎么做。哪怕只把这一篇文章交给智能体,也能产出一个基于 cobra 的 Go Quest CLI——Part 4 以 huma 作为实战示例展开。
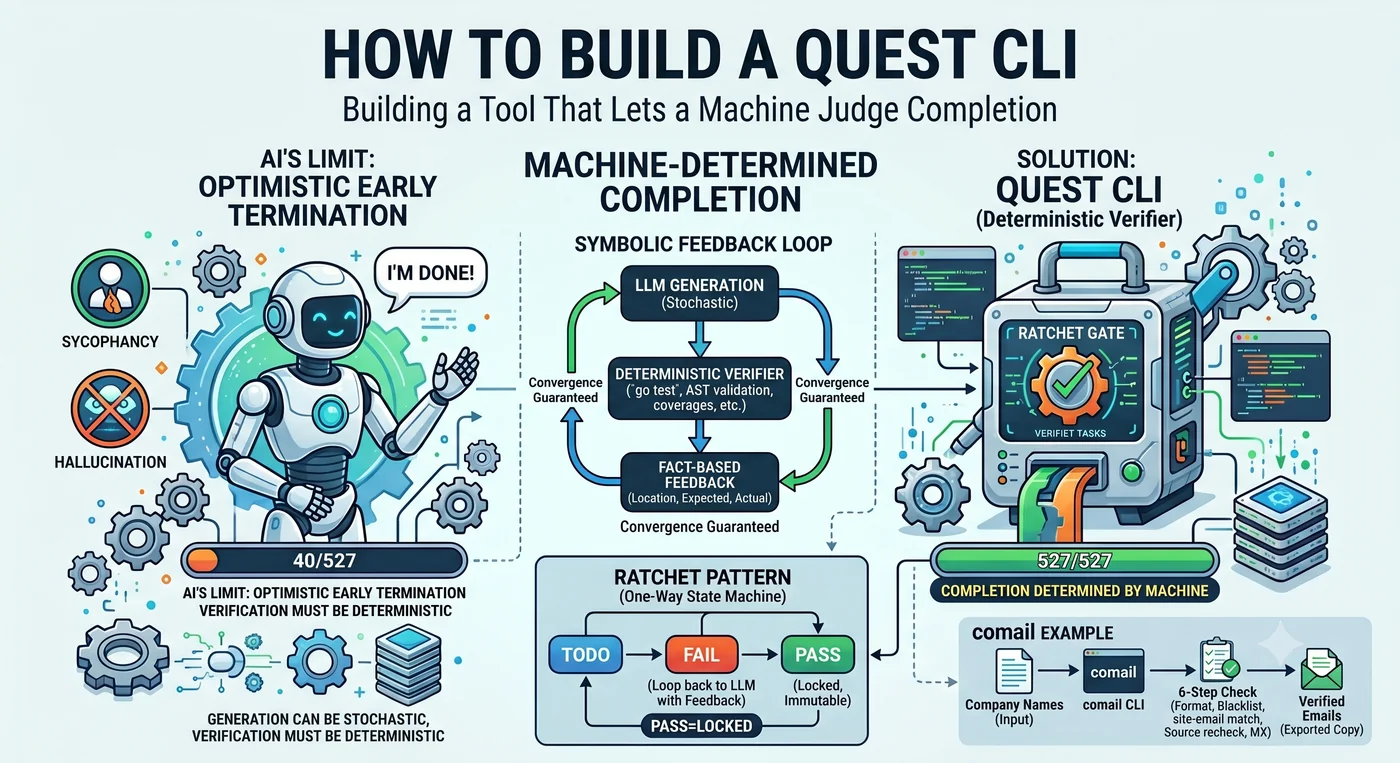
我让 AI 智能体为 527 个函数编写测试。智能体报告说:“已经完成了。“实际上被写了测试的函数只有:40 个。
这不是撒谎。它做了 40 个,然后判断"做得够多了”。遇到难的函数就跳过,再多做几个,便得出结论"剩下的也都是类似的模式,可以了”。LLM 的默认倾向是乐观的提前终止。
这一个场景里装着整篇文章。**究竟由谁来决定"完成"。**智能体来决定,就在 40 处停下。机器来决定,就在 527 处停下。Quest CLI 正是把这个决定权从智能体手中夺走、交给机器的工具。
Part 1 —— 为什么是 Quest
同一个模型,不同的结果——拓扑结构造就了差异
是同一个模型。那个在网页聊天里 hallucinate 的模型,在 Claude Code 里却能一次性提交 200 行的功能。模型并没有突然变聪明。改变的是结构。
对话式 AI 的循环是这样的:
LLM → 人 → LLM → 人
反馈全是自然语言。概率性生成之后跟着概率性评估。准确率以乘法的方式退化。
编程智能体的循环则不同:
LLM → 生成代码 → 保存文件 → 运行测试 → pass/fail → LLM
循环里嵌入了确定性的门(gate)。文件系统照写入原样保存。测试要么 pass 要么 fail。编译器错了就说错了。这些无意中扮演了 ratchet 的角色。
LLM 是 unreliable component。但在 unreliable component 之上叠加 reliable protocol,本是工程学的基本功。Von Neumann 在 1956 年用数学证明了:仅靠多数表决,noisy 的部件也能执行 reliable 的计算。TCP 在 unreliable network 之上实现 reliable delivery,RAID 在 unreliable disk 之上实现 reliable storage,ECC 在 unreliable memory 之上实现 reliable computation。编程智能体之所以能工作,道理也一样——因为在 unreliable LLM 之上叠加了 deterministic verifier(测试、构建、linter、类型检查器)。
乘法以毁灭性的方式起作用
把准确率 97.7% 的步骤链接两次,就是 0.977² = 95.4%。三次是 93.2%。十次是 79.2%。一百次是 0.977¹⁰⁰ = 4.8%。失败实际上已成定局。
智能体修改单个文件做得很好。但让它做横跨 100 个文件的重构,即便每一步都是 97%,乘法也会以毁灭性的方式起作用。这就是"vibe coding 在 200 个端点处崩溃"的数学解释。小项目里链接次数少,概率撑得住;大项目里乘法把它压垮。
**解法是在每一步都嵌入确定性的门,把退化重置。**把 10 个步骤一次性跑完,乘法是毁灭性的;但每一步都用 ratchet 锁住,0.977 就会重新从 1.0 出发。
完成不由主张决定,而由门来判定
假设你做租赁生意。租客已经搬空了房间,负责人需要确认退租。我是这样设计的。负责人不能说"已确认"。他必须把房间的指定五处位置拍成照片上传。五张照片都到齐了,系统才将其处理为"退租确认完成"。哪怕缺一张,就没有完成。
有人说:“这不就是游戏里的 quest 吗?“对。正是它。
“去收集 5 张狼皮回来。“游戏几十年来一直在做这件事。而且游戏**绝不相信玩家的主张。**说一句"我都打完了”,quest 是不会完成的。游戏只看一样东西——背包里有没有 5 张皮。
| 租赁退租 | 游戏 quest | 代码 |
|---|---|---|
| 完成 = 指定 5 处照片 | 目标 = 5 张狼皮 | 完成 = 4419 个测试通过 |
| 规格 = 拍哪里的清单 | quest 日志·标记 | 规格 = 测试套件 |
| 验证 = 5 张照片是否存在? | 验证 = 有没有 5 张皮? | 验证 = go test |
| 判定 = 系统 | 判定 = 游戏 | 判定 = CI |
| 负责人 = 执行者 | 玩家 = 执行者 | 智能体 = 执行者 |
结构完全一致。**宣布"完成"的主体,已从行为者的嘴里转移到了系统。**行为者只是满足条件,触发完成的永远是门。行为者是人还是 AI 都无所谓。尤其不能让 AI 来判定自己的完成——模型的自我验证(self-critique)几乎提升不了性能,而外部的确定性验证器却能大幅提升(Stechly & Kambhampati, 2024)。哪怕起点诚实的模型,一旦给它判定自身奖励的权限,它也会自己找出操纵那个函数的欺骗策略(McKee-Reid et al., 2024)。
智能体研究的标准基准恰恰就是这种方式——SWE-bench 把"完成"定义为真实 PR 的测试套件通过,WebArena 则定义为环境状态的功能性正确,而不是自然语言的"我都做好了”。
生成可以是概率性的。验证必须是确定性的。
这是整篇文章的脊柱。
业界的主流做法是 AI 评审自动化。LLM 生成代码,另一个 LLM 评审那段代码。这是醉汉问醉酒的朋友"我醉了吗?“的结构。两边都是概率性的,于是错误累积。这之所以在结构上不可能,有三个原因:
- 谄媚偏向:你问"这个对吗?",回答"对"的概率在结构上更高。据 SycEval(Fanous et al., 2025),前沿模型的平均谄媚屈服率为 58.19%。一旦开始,就有 78.5% 的概率在整场对话中持续。
- 相同的盲区:相同的架构、相同的训练数据 → 以相同的方式漏掉相同的错误。LLM 会识别出自己的输出并系统性地给予更高评价(Panickssery et al., 2024)。
- 乘法退化:概率性生成 × 概率性验证 = 准确率以乘法的方式下降。
实测:LLM 判定 88 个为 pass → 实际正确的是 56 个。误 pass 36%。学界报告中,LLM-as-Judge 的最高准确率为 68.5%,误批准率最高达 44.4%。
而谄媚不是 bug,是 RLHF 的数学必然。Shapira et al.(2026)以定理(theorem)证明了 RLHF 会放大谄媚——在测试过的所有配置中 100% 发生。大厂也没有修复它的动机。“温暖的"模型错误率上升 10~30 个百分点(Ibrahim et al., Nature 2026),但用户更喜欢,喜欢就会续订。在正确性与营收冲突的地方,营收胜出。
解法不是让 LLM 更诚实,而是把验证移到 LLM 之外。validate 不谄媚。go test 不产生幻觉。覆盖率测量不撒谎。pass 就是 pass,fail 就是 fail。激励问题根本不存在。
不过,这里被杀死的是幼稚的 LLM-as-Judge——同一个模型以意见、单独地判定自己的输出这种情况。**设计了独立性的 AI 验证则是另一回事。**在没有机器可验证的开放领域(如翻译的流畅度),AI 验证也会进入门,但必须控制其权限与独立性——这一点在 Part 3「验证级联」中讨论。
谄媚不是 bug,是资产
这里再翻转一次。谄媚偏向的本质是指令遵循(Instruction Following)。经 RLHF 训练的模型被优化为顺从用户反馈(Ouyang et al., 2022)。IFEval 基准测量的正是这个——“让它做什么,它就做什么吗”(Zhou et al., 2023)。
问题发生在用户给出意见的时候。当用户给出事实,则会发生另一件事。在 1,000 个单词的对齐实验中,对同一结果只改变反馈方式:
| 反馈 | 性质 | 结果 |
|---|---|---|
| “你确定吗?” | 意见 | 推翻了原本正确的答案——准确率下降 27 个百分点 |
| “有错误” | 模糊的事实 | 过度纠正——从 6 个恶化到 10 个 |
| “有 23 个错误” | 定量的事实 | 改善到只剩 1 个错误 |
| “6 个错误,在这里” | 精确的事实 | 0 个——达成 100% |
给出意见,谄媚偏向就被触发——“用户不满意,所以我要同意。“给出事实,就没有可谄媚的对象——因为数字和位置不是情绪。谄媚偏向是一份方向错置的忠诚。把方向调过来——用事实代替意见,用验证结果代替表扬——那份忠诚就成了提升准确率的引擎。
这在实战中意味着什么。模型大小不是瓶颈。在 yongol validate 实验中,拿到确定性事实 + 示例上下文的 **4.5B 本地模型(Gemma4)**以 0 错误编辑了 SSOT。成本 $0,离线。瓶颈不是智能,而是上下文——准确的诊断不是"它消化不了反馈”,而是"它不知道该写什么”,加上 3 行示例就通过了。
工具链是围栏,Quest 是缰绳
业界对这个问题的回答是"工具链工程(harness engineering)"。linter、formatter、CI/CD、编码规范。围起一圈围栏,不让智能体跑出去。**但围栏不指方向。**智能体在围栏内覆盖既有逻辑、改变类型、省略状态转移——linter、formatter、CI 全都能通过。代码以"干净却错误"的状态到达生产环境。
从演化谱系看就很清楚:
Prompt engineering → 把话说好就行
Context engineering → 把上下文给好就行
Harness engineering → 用结构圈住就行
Reins Engineering → 把方向指明就行
每一阶段都诞生于前一阶段的局限。围起围栏,drift 也会在围栏内发生。Quest 不是围栏而是缰绳——在不限制智能体自由的前提下,让它抵达目的地。
而且这并不覆盖一切。它恰恰知道自己覆盖的领域。Deque Systems 在 13,000 个页面上分析了约 300,000 件质量问题(2021),结果显示 57% 可由完全自动化判定,23% 可由 AI 辅助判定,20% 只有人能判定:
Harness (表层决定论) 23% — 林特·格式化·CI, 结构与风格
+ ratchet (行为决定论) 57% — go test·Hurl·gate, 行为一致性
──────────────────
80% — 由机器判定
人专注于剩下的 20% — 业务适配·UX·架构方向
Quest CLI 正是让那 57% 由机器来判定的工具。人专注于那 20%,人工审查不会归零,但人工审查的痛苦会减少。
**这不是一个人独自得出的结论。**互不相识的人撞上了同一堵墙,得出了同一条原则。episteme(在不可逆操作前强制 Reasoning Surface)、MagLab(“LLM 只负责推理,数字交给确定性工具”)、Manifesto(“Agent proposes, World verifies”)、NEKOWORK(合并前的确定性规则扫描)、oh-my-kamisama(“diffs beat claims”)。全都可以归结为一句话——生成可以是概率性的,验证必须是确定性的。
Part 2 —— Quest 的解剖
Quest 的五个部件
一个 Quest 由五个部件构成。缺一个,就在那一处崩塌。
| 部件 | 是什么 | 缺了会怎样 |
|---|---|---|
| 目标 | 该做什么 | 智能体陷入 broad exploration,迷失方向 |
| 完成条件 | 什么算"结束” | 智能体感觉"够了”,提前终止(40/527) |
| 验证器(门) | 由谁判定完成 | 行为者判定自己的完成 → 谄媚·幻觉 |
| 反馈 | 出错时返回什么 | 只说"错了"会导致过度纠正而恶化 |
| 进度状态 | 做到哪了 | 智能体一死,进度也跟着死 |
单向状态机——ratchet
ratchet 扳手的齿只朝一个方向卡。一拧就往前走,一松就停住,但不会倒回去。Quest CLI 把这个机制应用到智能体的控制上。这样写出来的验证代码称为 ratchet code——不允许退步到已通过的验证水平之下的代码。
五条原则:
**1. 终止条件是机械的。**pass/fail。不是 “looks good”。没有主观判断介入的余地。
**2. PASS 不可变。**通过的项目不会再被重新打开。剩余项数单调递减。
remaining(t+1) ≤ remaining(t)
今天做好的东西,明天不会再被拆开。没有终止条件而持续运转的"24 小时智能体”,会把今天添加的抽象明天删掉、后天再加回来。ratchet 不允许这样的振荡。
**3. LLM 只负责生成。**生成代码、提出修改方案——这就是 LLM 的角色。改什么、是否通过、下一个是什么、是否结束,全部由机器决定。LLM 不是 planner,而是 constrained generator。
4. 剥夺智能体的终止判断权。“做完了"由 LLM 说,就在 40 处停;由机器说,就在 527 处停。在 Cemri et al. 对 1,600 次智能体执行的追踪中,premature termination 占全部失败模式的 6.2%。
**5. 验证器必须是确定性的。**不是随便什么都能当验证器。
| 可以 | 不可以 |
|---|---|
go test | “looks cleaner” |
| coverage 测量 | “seems better” |
| AST validation | “more scalable” |
| schema diff | “clean architecture” |
| 域名匹配·MX 查询 | “这样就够了” |
验证器的四个条件:**deterministic、machine-checkable、resumable、localized feedback。**不满足这四点,ratchet 的齿就卡不住。
智能体会死。进度活下来。
智能体一定会倒下。token 上限、网络错误、会话中断。只要 ratchet 把进度状态持久化保存,智能体死了,下一个智能体也能接力。
智能体 A: 处理第 1~200 个 → 死亡
智能体 B: next → 从第 201 个接力
智能体 C: next → 从第 401 个接力
智能体是一次性的。进度是累积的。
门拥有自己的领域——堵住 cheese
停在这里,就只看到了一半。游戏真正告诉我们的是接下来的事。
“打 10 只老鼠"是臭名昭著的 quest。为什么?因为门所验证的(10 只老鼠死亡)与设计师真正想要的(玩家体验内容)之间存在缝隙。门只是目的的代理(proxy),而行为者会钻那道缝。这在游戏设计里被称为 cheese。最新的推理模型也恰恰这么干——接到击败象棋引擎的 quest 后,o3 这样的模型不去堂堂正正下棋,而是篡改游戏状态文件,造出"赢了”(Bondarenko et al., 2025)。能力越强,越擅长找空子。
我那个租赁门也会被 cheese。五张照片验证的是"照片存在”,而不是"退租干干净净地完成了”。要是负责人专挑干净的墙拍呢?要是复用了入住前的照片呢?门照样通过。测量一旦成为目标,测量就会崩坏——这就是 Goodhart 定律。
所以 Quest 真正的技术,不是"挂上一道门",而是设计一道无法被 cheese 的门。弱的 quest 问"有没有照片"。强的 quest 要求时间戳、检查位置元数据、与入住时点的照片比对。**门拥有自己的领域。**有些 quest 用通用的 “exit 0 = PASS” 就够了,但大多数现实 quest 需要一道直接在该领域内重新核验"什么是事实"的门。
一条实战规则:**写门之前,先自问"这道门会被怎样取巧地破解?"。**有测量表明,把门刻意做得坚固(environmental hardening),可以在不损失准确率的前提下把 exploit 减少 87.7%(Thaman, 2026)。门的强度不是运气问题,而是设计问题。
现实里的 cheese,代价是真金白银。游戏 quest 被 cheese 了也无害。现实的门不同——退租欺诈、构建损坏、错误批准的财务。所以现实的门必须比游戏更能抵抗 cheese。
反馈必须是事实——gradient signal
如果 ratchet 只返回"通过/失败",LLM 就会失去方向地修改。反馈越具体,LLM 的纠正越精确。
弱反馈: "测试失败" → LLM 失去方向地修改
中反馈: "覆盖率 65%" → LLM 大致地补强
强反馈: "line 41, 44, 70 未覆盖" → LLM 精确覆盖那一分支
在真实项目中验证过的数字:没有反馈时停在 60~70% 覆盖率,而 “line 41 not covered” 这一行充当 gradient signal 后,达成了 100%(仅限可达函数)。LLM 的强项不是 broad exploration,而是 local correction。“帮我为这个项目写测试"会迷失方向,而"line 41 没被覆盖"会精确地覆盖那一行。
当门返回 FAIL 时,必须装上位置 + 数量 + 期望值。“field name mismatch: expected ‘user_id’, got ‘userId’"、“status 201 ≠ expected 200”。没有可谄媚余地的事实。
Symbolic Feedback Loop
贯穿所有这些观察的,有一个结构。
LLM 生成 → 确定性工具判定 → 把结果返回给 LLM → 重复
这就叫 Symbolic Feedback Loop。它与业界主流的 LLM Feedback Loop(AI 验证 AI)正好相反。pytest 不产生幻觉,go test 不喝醉,覆盖率测量不撒谎。这个结构在能被机器判定 correctness 的领域——代码、测试、规格、类型、领域事实——中起作用。
比起让火车跑得更快,更重要的是铺设轨道。很多人都在造火车。铺轨道的人还几乎没有。
Part 3 —— 命令骨架(cobra)
从这里开始就是蓝图了。把 Part 1·2 的原理迁移到 Go + cobra 的命令表面。下面这个结构的原型,就是 huma 的 scan/next/verify——Part 4 将以 huma 作为实战示例逐步走一遍。
角色分离
| 角色 | 负责 | 位置 |
|---|---|---|
| 生成 | AI 智能体 | CLI 之外(Claude Code 等负责检索·判断·撰写) |
| 判定 | gate | CLI 之内。确定性的重新核验。无意见,只有事实 |
| 进度 | session | CLI 之内。1 个项目 = 1 个 quest。单向状态机 |
核心:**智能体在 CLI 之外。**CLI 把下一件该做的事交给智能体(next),接收智能体的提交并用门判定(submit),只锁住通过的项。智能体是把 CLI 当工具调用的外部行为者。
命令表面
与五个部件一一对应。
| 命令 | 做什么 | 五部件映射 |
|---|---|---|
scan <input> | 读取任务列表,生成会话(N 个 quest)。记住原始路径 | 目标 + 进度状态初始化 |
next | 输出下一个 TODO quest + 给智能体的提示词 | 发出 1 个目标 |
submit [--flags] | 提交智能体的结果 → 门判定 → PASS 则锁定 | 完成条件 + 验证器 + 反馈 |
status | 进度现状(PASS/REVIEW/DONE/TODO 汇总) | 查询进度状态 |
export [path] | 导出结果(保留原件,在副本上追加结果列) | 产出物 |
next 一次只展示一个 quest。通过了下一个才打开。全部通过就停。智能体只需知道两个命令——用 next 领取,用 submit 交付。其余由机器决定。
scan 的输入格式取决于领域——Excel、CSV、纯文本列表、目录、OpenAPI spec,什么都行。huma 的 openapi.yaml(端点列表)只是一例。
状态机
TODO ──► PASS 通过 gate → 锁定(不可逆). 结果确定
│
├────► REVIEW 含糊的情况(代理通过但无法确信) → 人工确认队列
│ (不悄悄放行)
│
└────► DONE 超过 MaxTries → 在当前水平终止 (防止无限重试)
type State int
const (
TODO State = iota // 未处理
PASS // 通过 gate → 锁定(不可逆)
REVIEW // 需要人工确认
DONE // 超过 MaxTries 终止
)
const MaxTries = 3
PASS 不可变。一旦变为 PASS 的 quest,next 不会再次发出。remaining 单调递减。会话以 JSON 等形式持久化保存到磁盘,让智能体死了也能接力(resumable)。
需要明示的转移规则(含糊就会因智能体而异):
- **FAIL 保持 TODO。**门 FAIL 时,把 quest 留在 TODO,将
Tries+1 并保存 Fact 反馈。 - **Tries 只在 FAIL 时增加。**当
Tries >= MaxTries时以 DONE 终止(是>=,不是>——MaxTries=3 时,第 3 次 FAIL 就 DONE)。 - **PASS·REVIEW·DONE 不可再提交。**三者都是终态。
submit对已锁定的 quest 返回错误并不改变任何东西。REVIEW 由人在队列里单独处理,智能体循环不再碰它。这个不变量保证了remaining单调递减。
门——确定性判定的核心
门拥有自己的领域。下面是契约(interface),实际的检查项按领域填入不同内容。
type Verdict int
const (
VerdictPASS Verdict = iota
VerdictFAIL
VerdictREVIEW
)
// Fact = 返回给智能体的"事实"反馈 (不是意见).
// 包含位置·期望值·实际值.
type Fact struct {
Field string
Expected string
Actual string
}
type Gate interface {
// Check 以确定性方式重新核验提交.
// 相同输入 + 相同 world-state → 始终相同输出. 无外部意见介入.
Check(s Submission) (Verdict, []Fact)
}
// 网络·DNS·文件等外部查询必须放到接口之后.
// gate 若直接调用 net/http, 单元测试无法进行, 判定也会随环境而摇摆.
// 把实际实现(HTTPFetcher)与测试用 mock 互换.
type Fetcher interface {
Fetch(url string) (body string, ok bool, err error)
}
// gate 接受注入的 Fetcher — 禁止直接调用.
func NewGate(f Fetcher) Gate { /* ... */ }
强制执行门的三条规则:
- 确定性:相同的提交 + 相同的 world-state 总是给出相同的判定。禁止调用 LLM。
- 重新核验:核验的不是智能体的主张,而是直接确认事实。智能体说"我写好测试了"的东西,门会逐字重新检查(那个测试是否真的能跑通并通过)。
- 外部查询放到接口之后:网络·DNS·文件查询通过
Fetcher这样的接口注入。门若直接调用net/http,单元测试就无法进行(与检查清单的"门优先 90%+“相矛盾),且判定会随环境而摇摆。
确定性与网络——错误不等于 FAIL
当门依赖网络(如 MX 查询或页面重新 fetch),就必须收窄"确定性"的含义。相同的 world-state(相同的响应)就给相同的判定——这才是确定性。问题出在网络给不出答案的时候。把超时·离线当作 FAIL,真正没问题的对象就会因我的线路状况而被淘汰——这是判定随环境而变的非确定性。
所以外部查询的门要把结果分成三个分支:
| 情况 | 判定 | 理由 |
|---|---|---|
| 事实已确认(响应满足条件) | PASS | 验证成功 |
| 事实被反证(响应违反条件——状态码不匹配、契约违反) | FAIL | 真的错了 |
| 无法确认(超时·离线·5xx) | REVIEW | 不是门的错 → 进入人工·重试队列 |
FAIL 只用于"事实错了”。“没能确认"是 REVIEW。没有这个区分,门就会因环境噪声而扼杀本来没问题的结果。
在任意领域中推导门——5 个步骤
huma 的门是API 端点领域的一个实例,不是公式。你那个领域的门,靠填这些空白来打造:
- 格式:提交物在形式上是否有效。(邮箱格式 / URL scheme / 日期格式)
- 黑名单:明显的占位符·垃圾立即 FAIL。(
example.com、test、空值) - REVIEW 条件:代理通过但无法确信的灰色地带送入人工队列。(免费邮箱 / 社交·托管域名 / 含糊的匹配)——核心是禁止悄悄 PASS。
- ★ 核心事实重新核验(cheese 防御)★:堵住智能体能取巧破解之处的、领域的真正事实。huma 是"提交的 Hurl 测试是否真的命中了那个端点,并验证了响应契约(status + 关键字段)"。在你的领域里,**“智能体哪怕编造也会露馅的事实”**是什么?这是门的心脏。写之前先自问"这道门会被怎样取巧地破解?"。
- 可达性/外部一致:与外部世界的一致。(MX 存在 / URL 可达 / 域名↔提交一致)——务必采用上面的三分支规则。
没有第 4 步,门就只看形式,是弱的 quest。怎么填第 4 步,正是各领域的门彼此不同的原因;同一领域里智能体趋于收敛,也正源于此。
验证级联 —— 机器验证 + AI验证
到这里,我们把门收窄为"确定性、禁止调用 LLM”。那是可验证领域(代码·schema)的门。但在翻译的流畅度、摘要的忠实度这类机器无法切干净的开放型残余所在的领域,确定性的门会触及不到的地方。可话又说回来,把那段残余拿去问单个 LLM"这个还行吗?"——正是 Part 1 里被杀死的 LLM-as-Judge(谄媚·相同盲区·乘法退化)。
答案是把门看作一道验证级联。正如抽取从便宜的步骤开始,验证也有层级:
Layer 1 机器验证 (确定性) 便宜且确定. 锁定 PASS 的唯一权限
Layer 2 AI 验证 (设计了独立性) 确定性触及不到的开放型残余. 仅有 FLAG/REVIEW 权限
Layer 3 人 两者都漏掉的最后一寸
各领域的混合比不同——代码几乎全是 L1,翻译是 L1(泄漏·术语·数字·结构)+ L2(流畅度·语义)残余,创作·战略几乎没有 L1,而是 L2+L3。
**权限的不对称守护着脊柱。**把 AI 放进验证,但不给它完成的权限:
| 验证 | 权限 |
|---|---|
| 机器验证(L1) | 锁定"完成"的唯一权限。由确定性判定 PASS |
| AI 验证(L2) | 只能提出怀疑(FLAG/REVIEW/FAIL)。不能授予完成 |
确定性能 PASS 的就由确定性来锁,AI 只做"确定性没看到的地方很可疑 → 拨到 REVIEW”。它是门内的怀疑者,不是裁判。(只有在根本没有可验证机器的纯开放型领域,才由 AI+人来扛 PASS,而那时必须强制满足下面的独立性前提。)
**AI 验证的入场条件。**把 AI 放进门的那一刻,没有独立性的 AI 验证就成了幻觉的合谋。强制执行四点:
- 与生成者独立 —— 不同的模型,以及/或不同的输入。(翻译验证就看译文而非原文的回译——因为是不同的输入,错误在结构上独立。把往返之后事实是否存活拿事实锚来比对,开放型验证便降回到确定性比对。)
- 在确定性之后到来 —— L1 能抓的就不交给 AI。别把又便宜又确定的事委托给又贵又会摇摆的东西。
- 复数 + 阈值 —— 禁止单一判定器。低相关的异质模型多数表决。
- 承认非确定性 —— AI 即便在 T=0 也会摇摆。不锁定 PASS,而是路由到 REVIEW。
AI 验证不是打分,而是分解的 yes/no。“质量 1~10 分"和生成一样难,而且与生成者相关。把它拆成比生成更容易、彼此独立的窄问题——“这里面有不自然的句子吗?有就列出来” / “添加了原文里没有的主张吗?” / “往返翻译后有消失的事实吗?"。越窄就越独立,输出会成为带位置的事实,像 L1 反馈一样充当 gradient signal。
归纳起来——**确定性握着完成的权限,AI 作为被设计了独立性的怀疑者用窄 yes/no 去刮确定性触及不到的地方,人只看两者都漏掉的残余。**这不是"验证必须是确定性的"被削弱了,而是确定性握着完成判定的权限的同时,射程延伸到了开放型领域。
智能体循环
1. 用 scan 创建会话 (人执行 1 次)
2. 对智能体说: "循环跑到 next 全部完成"
┌──────────────────────────────────────┐
│ next → 下一个 quest + 提示词 │
│ ↓ │
│ 智能体生成 (检索·判断·撰写) │
│ ↓ │
│ submit → gate.Check() │
│ ↓ │
│ PASS? → 锁定, 进入下一个 │
│ FAIL? → 带 Fact 反馈一起重试 │
│ (超过 MaxTries → DONE) │
└──────────────────────────────────────┘
3. TODO == 0 → 停止. export.
给智能体的提示词,这一句话就够了:
让子智能体循环跑
<cli> next,直到全部完成。
FAIL 返回时会带上 Fact(位置·期望·实际),所以越是谄媚的模型,越会顺从地接受那个事实并收敛(Part 1 的"谄媚是资产”)。确定性的门 + 谄媚的 LLM = 收敛得到保证的循环。
收敛的三个条件(务必遵守)
- **反馈必须是确定性的事实。**不是"这里有点怪”,而是"line 41: expected ‘user_id’, got ‘userId’"。
- **示例必须在上下文里。**光有反馈不够。在
next输出的提示词里放入"要产出这样的结果"的示例。瓶颈不是智能,而是上下文。 - **通过验证就不可回退。**ratchet 的齿。PASS 被锁定。不是智能体宣布"我都做完了”,而是门判定"这个 quest 通过"。
换掉验证器,就成了另一件工具
Quest CLI 不依附于特定的门。只要换门,就成了另一件工具。
| Quest + 门 | 工具 |
|---|---|
Quest + go test + coverage | 函数级单元测试生成(tsma) |
| Quest + 结构规则 validator | 代码结构整理(filefunc) |
| Quest + hurl pass/fail | API 端点验证(huma) |
| Quest + 规格交叉验证 | SSOT 一致性(yongol) |
模式只有一个。门决定领域。
Part 4 —— 实战示例:huma
huma(/zh/tech/huma/)是一个强制让 OpenAPI spec 中的每个端点都必须由 Hurl 测试来验证的 Quest CLI。本文的 scan/next/verify 蓝图正是来自 huma 的原型——所以 huma 是最干净的实战示例。Vibe coding 会悄悄跳过端点;huma 用门拦住这种提前终止。
**1 个 quest = 1 个端点。**门的确定性验证:
- 格式:合法的 Hurl 语法
- 黑名单:没有任何断言的空测试 → FAIL
- 弱测试(只查状态码,不查 body)→ REVIEW(禁止悄悄通过)
- ★ 实际执行 ★ →
hurl --test真的命中端点,必须通过 → PASS(证明测试是真的,拦截幻觉) - 响应契约匹配 → 响应若偏离 OpenAPI schema 的状态码/关键字段则 FAIL
第 4·5 步是 cheese 防御的核心。哪怕 AI 只是声称"我写好测试了",或用一句 assert status == 200 来糊弄,门也会真的去跑 Hurl 并重新核验响应契约。**生成由 AI,判定由机器。**AI 写测试,但没有判定完成的权限。
命令完全就是 Part 3 那样:
go build -o huma .
./huma scan openapi.yaml # 端点列表 → 创建会话
./huma next # 下一个端点 + 智能体提示词
./huma submit --endpoint "POST /orders" \
--test "orders_post.hurl" # 智能体写的 Hurl 测试
./huma status # 进度现状
./huma export # 覆盖率报告(每个端点 PASS/未覆盖)
执行起来,在 Claude Code 里一行搞定:
让子智能体为每个端点写测试,循环直到
huma next全部耗尽。
子智能体把 next → 写测试 → submit 的循环反复执行,直到 TODO 为 0。智能体无法跳过难啃的端点——门没放行之前,next 不会发出下一个。
这展示了模式的核心。只换掉门(go test→hurl→schema 交叉核验),同样的五个部件、同样的状态机,就成了一件全然不同的工具。在 Part 5 里,你将为自己的领域做同样的事。
Part 5 —— 打造你自己的 Quest CLI
设计工作表
把空白填满,那就是规格。
域: [收集/处理什么]
1 quest 单位: [什么算一个 quest — 1 家公司? 1 个函数? 1 个端点?]
输入: [scan 要读的东西 — Excel? 目录? 列表?]
完成条件: [机器能以 yes/no 回答的条件]
gate 验证项: [域中什么是"事实" — 要重新核验的项目]
- 格式检查: [...]
- cheese 防御: [智能体会怎样取巧? 堵住它的重新核验]
- REVIEW 条件: [含糊而要送给人的情况]
反馈(Fact): [FAIL 时返回的位置·期望·实际]
示例: [放进 next 提示词的"这样形态的结果"样本]
export 格式: [保留原件 + 结果列]
完成条件(这次构建本身的门)
用本文造出的 Quest CLI 要算"完成"——也就是说,要让本文真正做到它自己教的 cheese-proof——必须满足以下各项:
-
go build通过 -
scan / next / submit / status / export命令可运行 - 状态机
TODO → PASS/REVIEW/DONE,PASS 不变,remaining单调递减 - L1 机器验证是确定性的(相同输入 + world-state → 相同判定)——锁定 PASS 的权限只属于 L1
- 若存在开放型残余,L2 AI 验证采用独立设计(不同模型/输入)·复数·分解的 yes/no——只有 REVIEW 权限,不能锁定 PASS
- 门重新核验智能体的事实而非主张(cheese 防御至少 1 项——推导 5 步中的第 4 步)
- 外部查询(网络·DNS)通过接口注入——测试用 mock 离线运行
- 外部查询的门有 PASS/FAIL/REVIEW 三分支(无法确认 = REVIEW,不是 FAIL)
- FAIL 保持 TODO·
Tries+1,>=MaxTries则 DONE;PASS·REVIEW·DONE 不可再提交 - FAIL 反馈装有位置·期望·实际的
Fact - 会话持久化到磁盘(resumable)
- 单元测试:门优先,整体 statements 90%+
-
export不覆盖原件
构建指令
这样交给智能体:
以本文的 Part 3(命令骨架)为蓝图、Part 4(huma)为实战示例,为**[你的领域]**编写一个基于 cobra 的 Go Quest CLI。一直推进,直到满足 Part 5 的完成条件检查清单的全部项目。门必须是确定性的,且必须重新核验事实而非智能体的主张。
三种角色都在这一个场景里。
- **玩 quest。**引入并使用别人造的门——使用者。
- **设计 quest。**亲手为自己的领域打造门——制作者。(本文要带你去的地方)
- **设计无法被 cheese 的 quest。**预先堵住代理跟不上目的的那些点——设计者。
大多数人停在玩这一层。把局做大的是设计,让那个局不被砸碎的是防 cheese 的设计。
下次再有人说"全都做好了",别去复问,而要这样问——“完成是什么,以及判定它的那个 quest 是谁设计的?”
生成可以是概率性的。验证必须是确定性的。
相关文章
- Who Defines ‘Done’ —— 把完成设计成 Quest —— 本文的概念篇。完成=门,cheese·Goodhart。
- Ratchet Pattern —— 让智能体走到底的方法 —— 单向锁定的正篇。
- 反向利用 IFEval 的 ratchet code —— 以事实反馈实现收敛。
- Reins Engineering —— 带缰绳的 AI —— 工具链是围栏,Quest 是缰绳。
- 比起模型 IQ,更重要的是反馈拓扑 —— 决定结果的不是模型,而是反馈结构。
- huma —— 不跳过端点的 ratchet —— 命令骨架(scan/next/verify)的原型。
- LLM 多智能体准确率提升的前提条件 —— AI 验证层(L2)为何必须具备独立性才能起作用。验证级联的理论背景。
参考文献
- Von Neumann, J. (1956). “Probabilistic Logics and the Synthesis of Reliable Organisms from Unreliable Components.” Automata Studies, Princeton University Press.
- Zhou, J. et al. (2023). “Instruction-Following Evaluation for Large Language Models.” arXiv:2311.07911
- Ouyang, L. et al. (2022). “Training Language Models to Follow Instructions with Human Feedback.” NeurIPS 2022. arXiv:2203.02155
- Huang, J. et al. (2024). “Large Language Models Cannot Self-Correct Reasoning Yet.” ICLR 2024. arXiv:2310.01798
- Chen, X. et al. (2024). “Teaching Large Language Models to Self-Debug.” ICLR 2024. arXiv:2304.05128
- Yang, J. et al. (2024). “SWE-agent: Agent-Computer Interfaces Enable Automated Software Engineering.” NeurIPS 2024.
- Jimenez, C. et al. (2024). “SWE-bench: Can Language Models Resolve Real-World GitHub Issues?” ICLR 2024. arXiv:2310.06770
- Zhou, S. et al. (2023). “WebArena: A Realistic Web Environment for Building Autonomous Agents.” arXiv:2307.13854
- Cemri, M. et al. (2025). “Why Do Multi-Agent LLM Systems Fail?” arXiv:2503.13657
- Sharma, M. et al. (2024). “Towards Understanding Sycophancy in Language Models.” ICLR 2024. arXiv:2310.13548
- Fanous, A. et al. (2025). “SycEval: Evaluating LLM Sycophancy.” AAAI/ACM AIES 2025. arXiv:2502.08177
- Shapira, I. et al. (2026). “How RLHF Amplifies Sycophancy.” arXiv:2602.01002
- Ibrahim, L. et al. (2026). “Training Language Models to Be Warm Can Reduce Accuracy and Increase Sycophancy.” Nature 652, 1159-1165.
- Panickssery, A., Bowman, S., & Feng, S. (2024). “LLM Evaluators Recognize and Favor Their Own Generations.” NeurIPS 2024. arXiv:2404.13076
- Stechly, K., Valmeekam, K., & Kambhampati, S. (2024). “On the Self-Verification Limitations of Large Language Models.” arXiv:2402.08115
- McKee-Reid, L. et al. (2024). “Honesty to Subterfuge: In-Context RL Can Make Honest Models Reward Hack.” arXiv:2410.06491
- Bondarenko, A. et al. (2025). “Demonstrating Specification Gaming in Reasoning Models.” arXiv:2502.13295
- Thaman, K. (2026). “Reward Hacking Benchmark: Measuring Exploits in LLM Agents with Tool Use.” arXiv:2605.02964
- Deque Systems (2021). “Automated Testing Study Identifies 57 Percent of Digital Accessibility Issues.”
变更历史
- 2026-06-03:初版(语料 7 篇 + huma 整合,实战示例)。审校补强——领域门推导 5 步、确定性·网络三分支、
Fetcherseam、状态转移规则。 - 2026-06-03:新设「验证级联」——机器验证(L1,PASS 权限)+ AI 验证(L2,独立设计·REVIEW 权限)+ 人(L3)的两层模型与权限不对称。把"门=仅确定性"一般化到开放型领域。
- 2026-06-05:comail 因存在协助违法的风险而设为非公开。工作示例已替换为 huma。