 Image generated by Google Gemini
Image generated by Google Gemini
GEO(Generative Engine Optimization)是优化内容使ChatGPT、Perplexity、Google AI Overview等AI搜索引擎引用你的内容的策略。 传统SEO是提升Google排名的游戏,而GEO是在AI生成的回答中被作为来源引用的游戏。也被称为AEO(Answer Engine Optimization)、AI SEO、LLM搜索优化。
搜索已经改变 — AI SEO时代的开始
过去在Google搜索会出现10个蓝色链接。现在AI直接生成答案。ChatGPT、Perplexity、Google AI Overview——用户不点击链接就能获得答案。
Gartner预测到2026年传统搜索量将下降25%。美国31.3%的人口已经在使用生成式AI搜索。
问题在于:如果AI生成的回答不引用你的内容,你就等于不存在。
Generative Engine Optimization(GEO)是这个新游戏的规则。
GEO vs SEO vs AEO — 有什么不同
传统SEO是Google排名游戏。关键词、反向链接、元标签。GEO是另一种游戏。
| SEO | GEO | |
|---|---|---|
| 目标 | SERP排名 | AI回答中的引用 |
| 成功指标 | 曝光、点击、CTR | 引用率、品牌推荐频率 |
| 核心信号 | 反向链接、关键词 | 实体明确性、来源引用、跨平台一致性 |
| 流量模型 | 点击 → 访问网站 | 零点击(无需访问即消费) |
一组令人惊讶的数据:AI Overview引用的83%来自Google自然搜索前10名之外的页面。ChatGPT最常引用的页面中,28.3%在Google上的自然可见性为0。传统SEO排名和AI引用是两个独立的游戏。
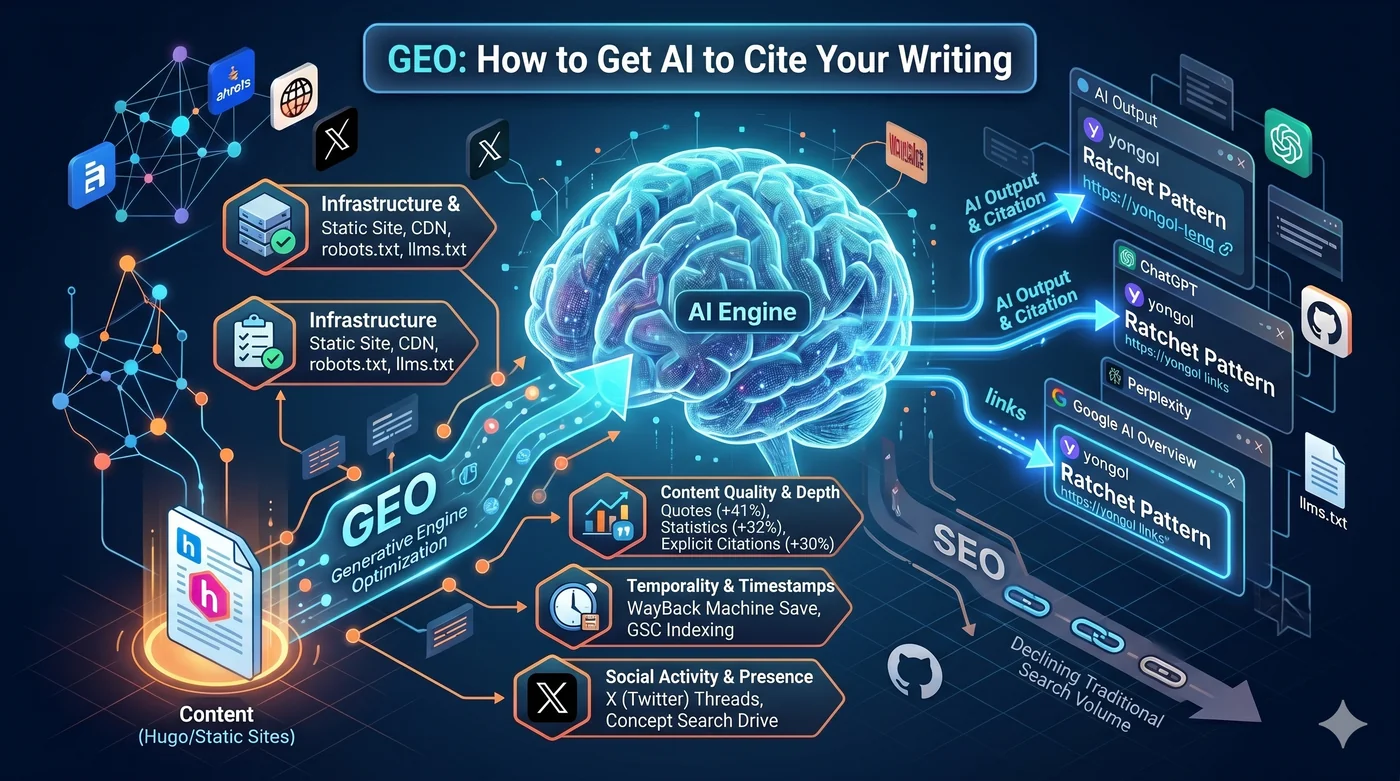
那么AI引用什么?
1. 基础设施:Hugo + CloudFront + robots.txt + llms.txt
如果AI爬虫无法到达你的内容,就不会有引用。第一个条件是技术基础设施。
静态网站生成器(Hugo)+ S3 + CloudFront
- 静态HTML是爬虫最快、最干净的数据源。SPA需要JavaScript渲染,AI爬虫经常跳过
- CloudFront CDN确保全球任何地方的快速响应。AI爬虫也将速度作为信号
- Hugo的多语言构建自动生成hreflang标签。12种语言 = 12个入口点
站点地图
XML站点地图是基础。但在GEO时代还需要两样东西:
llms.txt— 放置在网站根目录的Markdown文件。如果robots.txt告诉"去哪里爬取",llms.txt则指导"什么是重要内容"。Anthropic、Hugging Face、Perplexity已率先采用- Schema.org JSON-LD — Article、Person、SoftwareSourceCode模式。相当于给AI爬虫递上"这个页面是什么"的备忘单
在robots.txt中明确允许AI爬虫:
截至2026年,主要AI爬虫机器人分为5个类别:
| 类别 | 说明 | 屏蔽影响 |
|---|---|---|
| 训练爬虫 | 收集LLM训练数据 | 从模型长期知识中排除 |
| 搜索索引器 | AI搜索答案索引 | 从AI搜索结果中消失 |
| 用户触发抓取 | 用户提问时实时获取 | 对话中无法引用 |
| 代理 | AI代替用户浏览网页 | 从代理服务中排除 |
| 数据收集 | 大规模网页数据收集 | 从相关数据集中排除 |
主要机器人列表:
| 机器人 | 所有者 | 用途 |
|---|---|---|
| GPTBot | OpenAI | 模型训练 |
| OAI-SearchBot | OpenAI | ChatGPT搜索索引 |
| ChatGPT-User | OpenAI | 用户实时抓取 |
| ClaudeBot | Anthropic | 模型训练 |
| Claude-SearchBot | Anthropic | Claude搜索索引 |
| Claude-User | Anthropic | 用户实时抓取 |
| Google-Extended | Gemini训练 | |
| Applebot-Extended | Apple | Apple Intelligence训练 |
| Meta-ExternalAgent | Meta | Llama训练 + Meta AI |
| PerplexityBot | Perplexity | AI搜索 |
| bingbot | Microsoft | Bing + Copilot |
| CCBot | Common Crawl | 开放数据集(几乎所有LLM都在使用) |
| Bytespider | ByteDance | Doubao训练(无视robots.txt,建议屏蔽) |
关键:必须区分训练机器人和搜索/抓取机器人。 即使屏蔽训练机器人,只要允许搜索机器人,仍会被AI回答引用。两者都屏蔽则从AI世界中消失。
llms.txt — 如果robots.txt告诉"去哪里爬取",llms.txt则指导"什么是重要内容"。基于Markdown,放置在网站根目录。Anthropic、Hugging Face、Perplexity已率先采用。去除菜单/广告/脚本噪音,为AI上下文窗口提供精炼内容。
2. 站点地图与hreflang:AI阅读的语义地图
传统站点地图是URL列表。GEO时代的站点地图是语义地图。
<url>
<loc>https://www.parkjunwoo.com/opinion/reins-engineering/</loc>
<lastmod>2026-05-27</lastmod>
<changefreq>weekly</changefreq>
</url>
此外还需要:
- hreflang链接:同一篇文章的12种语言版本相互连接。AI高度评价多语言权威性
- lastmod准确性:76.4%的AI引用来自最近30天内更新的页面。3个月以内的内容被引用的概率高3倍。虚假的lastmod会产生反效果
- 类别结构:
/opinion/、/tech/、/lecture/— 有意义的层级结构比扁平结构更能为AI提供上下文
向Google Search Console提交站点地图是基本操作。但仅此还不够。
3. Wayback Machine与Google Search Console:内容原创证明
Wayback Machine自1996年以来保存网页快照。对AI而言,这是时间记忆。
为什么重要:
- 如果你在2026年5月发布了首次定义"Ratchet Pattern"的文章,Wayback Machine会保留该快照
- 即使6个月后有人在更大的平台上使用相同概念,时间证据指向原创作者
- 当AI判定来源时,首次发布时间作为间接权威信号发挥作用
执行步骤:
- 新文章发布后向Wayback Machine手动提交保存请求(
web.archive.org/save/) - 在Google Search Console中请求URL索引
- 两处都盖上时间戳
注意:截至2026年,已有241个网站屏蔽了Wayback Machine的访问(出于对AI企业绕过版权的担忧)。对个人博客而言这反而是机会——大型媒体退出存档后,个人内容的相对比重上升。
4. 来源引用与主题权威:LLM信任的内容条件
GEO原始论文(Aggarwal et al., KDD 2024)揭示的可见性提升策略前三名:
| 策略 | 可见性提升 |
|---|---|
| 添加引文(Quotation) | +41% |
| 添加统计数据(Statistics) | +32% |
| 标明来源(Cite Sources) | +30% |
关键词堆砌在GEO中毫无意义甚至适得其反。AI看的不是关键词,而是依据。
论文引用为何重要:
- AI区分"主张"和"有依据的主张"。“42%的开发者时间消耗在技术债务上"是主张。“42%的开发者时间消耗在技术债务上(Stripe, The Developer Coefficient, 2018)“是依据
- 有依据的句子,AI在自己的回答中引用时信任成本更低。没有依据的句子,AI需要验证因此会跳过
- 被4个以上AI平台引用的网站,ChatGPT出现率高2.8倍
关联文章管理与标签:
标签不是为人准备的,是为AI准备的。
- 一致的标签体系:“Reins Engineering”、“Ratchet Pattern”、“SSOT” — 相同标签跨多篇文章反复出现时,AI识别出主题权威(topical authority)
- 内部链接:文章中链接相关文章,AI爬虫就能识别主题集群。孤立的文章不如关联的文章容易被引用
- 交叉引用:文章间互相引用同样有效。“这个概念的基础在Ratchet Pattern中定义”
5. X、Reddit、Hacker News:打造品牌搜索量的社交策略
X/Twitter的使用条款明确禁止第三方AI训练。也就是说,发在X上的内容不会直接进入ChatGPT的训练数据。
但社交活动通过间接路径为AI可见性做出贡献:
品牌搜索量是LLM引用的最强预测变量(相关系数0.334,高于反向链接)。
路径是这样的:
X线程 → 人们在Google搜索"yongol" → 品牌搜索量上升 → AI将"yongol"识别为值得引用的实体
parkjunwoo.com的5月数据实际证明了这一点:
- “yongol” Google搜索:14次曝光,5次点击,平均排名3.1
- yongol GitHub克隆:独立用户316人
- 流量路径:t.co(X)4人 → GitHub → 博客
比起在X上直接分享链接,让人们去搜索概念对GEO更有效。
earned media的威力:
全部LLM引用的48%来自earned media(新闻、评论、第三方提及)。自有内容仅占23%。也就是说,让别人提及你比优化自己的文章有效2倍。
当项目在Reddit、Hacker News、dev.to上被提及时 → 通过这些平台的AI爬取 → LLM学习到该实体。
检查清单
基础设施
├── Hugo静态网站 + S3 + CloudFront
├── robots.txt中允许AI爬虫
├── 创建llms.txt(核心内容策展)
├── Schema.org JSON-LD(Article, Person)
└── XML站点地图 + hreflang
内容
├── 所有主张标明来源(+30%可见性)
├── 内联插入统计数据(+32%)
├── 使用对比表格(AI解析最优)
├── 准确维护lastmod(30天内更新 → 引用率76.4%)
└── 定期更新3个月以上的文章(引用概率3倍)
连接
├── 一致的标签体系(主题权威)
├── 内部链接(主题集群)
├── 引用论文/外部来源(降低信任成本)
└── 新文章 → Wayback Machine + GSC提交
社交
├── X线程引导概念搜索(品牌搜索量)
├── 在Reddit/HN产生earned media
└── 概念传播比直接分享链接更有利于GEO
本站的GEO实践案例
本文所述策略正在parkjunwoo.com上实际执行:
- robots.txt — 明确允许25个AI爬虫,屏蔽Bytespider
- llms.txt — 将核心内容策展为适合AI上下文窗口的格式
- Reins Engineering文章合集 — 主题集群中心
- 12种语言多语言构建 — 自动生成hreflang,每种语言一个入口
- 所有文章附论文来源 — 内联统计 + 学术引用确保事实密度
- 发布即提交Wayback Machine + GSC — 时间原创证明
相关文章
- Google, Optimizing your website for generative AI features on Google Search (2026) — Google官方AI搜索优化指南
- Cyrus Shepard, AI Citation Ranking Factors Analysis — 54项研究的元分析,量化23个AI引用排名因素
- Seer Interactive, AIO Impact on Google CTR: 2026 Update — 53个品牌,24.3亿次曝光追踪。有AI Overview时CTR -61%
- Discovered Labs, AI Citation Patterns: How ChatGPT, Claude, and Perplexity Choose Sources — AI引用中仅12%与Google前10重叠
- Ahrefs, Generative Engine Optimization: Growth Strategies and Metrics — 30万关键词分析。网络提及在AI Overview曝光中以3:1优于反向链接
- Datos/SparkToro, State of Search Q1 2026 — 基于点击流的AI搜索份额追踪
- Rand Fishkin, Search Happens Everywhere — 41个网站分析,搜索不仅在Google
- Go Fish Digital, GEO Case Study: 3X’ing Leads — AI推荐转化率比传统搜索高25倍
- Search Engine Land, How schema markup fits into AI search — 模式标记与AI搜索的务实分析
- Lily Ray, The Vicious Cycle of SEO — 对GEO垃圾内容短命的警告
参考来源
论文
- Aggarwal et al., GEO: Generative Engine Optimization, KDD 2024 — 引文+41%、统计+32%、来源标明+30%可见性提升
- Xu et al., Measuring Google AI Overviews (2026) — 55,393个查询分析。30%的AIO引用域名不在自然搜索第一页
- Fang et al., Recency Bias in LLM-Based Reranking, SIGIR-AP 2025 — 7个模型都一致提升最新内容排名
- Zhang et al., Citation Selection to Citation Absorption (2026) — ChatGPT/Google AIO/Perplexity引用模式的定量比较
- Algaba et al., LLMs Reflect Human Citation Patterns, NAACL 2025 — LLM更强烈地偏好高引用论文(Matthew effect)
- arXiv:2602.18455, AI Search Impact on Wikipedia Traffic (2026) — AIO使Wikipedia流量减少15%(DID因果分析)
- Yu et al., Structural Feature Engineering for GEO (2026) — 内容结构本身影响引用概率
- Tian et al., Diagnosing Citation Failures in GEO (2026) — 修改5%的内容即可提升40%的引用率
- Baack, Critical Analysis of Common Crawl, FAccT 2024 — LLM训练数据的核心组成与偏差
- Strauss et al., The Attribution Crisis in LLM Search (2025) — Gemini 92%未提供可点击的引用
数据报告
- Ahrefs, Do AI Assistants Prefer Fresh Content? (2025) — 1,700万AI引用分析
- SparkToro/Datos, State of Search Q1 2026 — 基于点击流的AI搜索份额追踪
- GitClear, AI Copilot Code Quality 2025 — 2.1亿行分析
- Gartner — 预测到2026年传统搜索量下降25%
- llms.txt 提议标准 — Search Engine Land
变更历史
- 2026-05-27: 初版