 Image: AI generated
Image: AI generated
遗留代码不会说谎
遗留代码没有文档。就算有,也是三年前的东西。测试要么不存在,要么坏掉后被 skip 处理掉了。注释与代码自相矛盾。原作者已经离职,知情者只留下一句"一碰就炸"。
可那段代码此时此刻仍在运行。它在处理支付,接收登录,下达订单。
文档会说谎。注释会说谎。人的记忆说谎得更厉害。唯一不会说谎的,是真正在流动的流量。
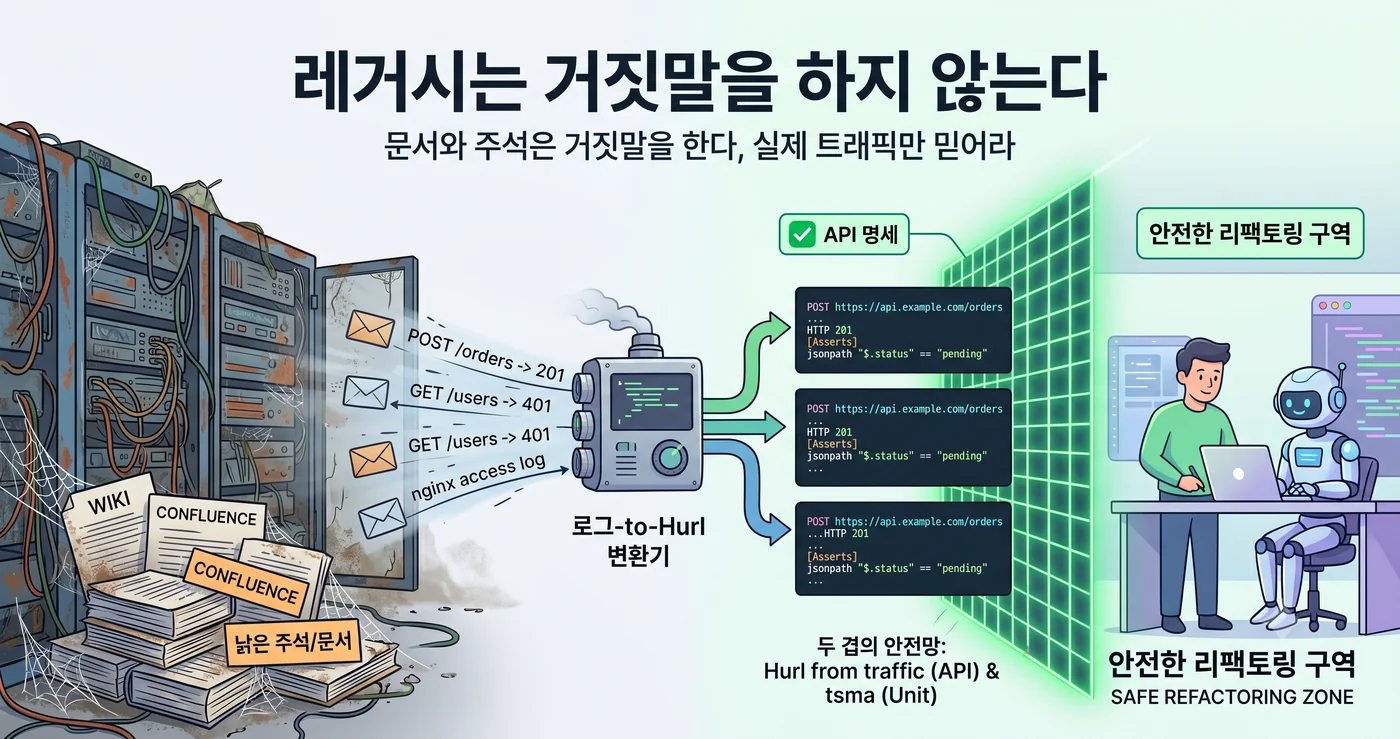
那么,规范该到哪里去找?不是 wiki。不是 Confluence。是 nginx access log。
先有鸡还是先有蛋
要重构遗留系统,需要一张安全网。改动了什么,行为是否随之改变,你得立刻知道。那张安全网,正是测试。
可遗留系统没有测试。要写测试,得先知道代码做了什么。要知道代码做了什么,就得去读。读了才发现,既没有测试也没有文档。
先有鸡还是先有蛋。这是 Michael Feathers 在 Working Effectively with Legacy Code 中命名的经典僵局。他给出的答案是 characterization test(特征化测试)——它固定的不是代码应该正确地做什么,而是代码现在实际做什么。对错是以后的事。先把当前行为固定下来,才动得了手。
在 Feathers 的年代,这要靠人手工编写。调用一个函数,把得到的值原样写进 expected。枯燥、缓慢,所以没人能坚持做到底。
但在 API 层面,那些"调用函数得到的结果"早已堆积在某处。每一天,成千上万条。在日志文件里。
一个月的日志即规范
收集一个月,就几乎能把遗留 API 的当前行为全部捕获下来。
nginx access log(1个月):
端点 · HTTP method · status code · timing
调用频次 → 优先级
错误模式(401、422、500 …)
request/response body(通过中间件或 reverse proxy 捕获):
正常请求/响应对 → 必须通过的行为
错误请求/响应对 → 不可破坏的边缘情况
把这两条脉络合起来,就能直译成 Hurl 集成测试。Hurl 是一种用纯文本原样写出 HTTP 请求与期望响应的格式。一对流量——“对这个请求,发出了这个响应”——恰好就是一个 Hurl 块。
# POST /api/orders —— 调用频次 #3,每天 1 万 2 千次
POST https://api.example.com/orders
Content-Type: application/json
{ "sku": "A-1024", "qty": 2 }
HTTP 201
[Asserts]
jsonpath "$.order_id" exists
jsonpath "$.status" == "pending"
jsonpath "$.total" == 49800
这个测试并不知道"订单 API 应该如何运作"。它只知道"现在正这样运作"。这就够了。一旦重构改变了这个响应,红灯就会亮起。
从日志中自动导出的内容:
- 哪些端点实际被使用 → 一个月内被调用 0 次的端点就是死代码。重构前的删除候选。
- 正常响应模式 → 基础回归测试。
- 错误模式 → 人想象不到的真正边缘情况。是真实用户制造出的 422 与 500。
- 调用频次 → 测试优先级。从每天 1 万 2 千次的那个开始固定。
最后一项很重要。人写测试时,会从自己记得的 happy path 开始写。流量没有那种偏向。真正承受负载的路径,就是优先级。
两层安全网
这种方法不是单独使用的,而是把遗留系统提升为 agent-operable 的棘轮流水线中的一层。
nginx log(1个月)→ Hurl 自动生成 → 固定遗留 API 的当前行为
↓
tsma → 函数级安全网(unit)
↓
filefunc → 整理代码结构(一个概念一个文件)
↓
重构 → 由 Hurl 验证 API 行为是否保持(integration)
关键在于安全网是两层。
- tsma = 函数级安全网。它捕捉内部逻辑是否发生了改变。但即使函数签名不变,整个端点的行为也可能不同。
- Hurl from traffic = API 级安全网。它捕捉从外部看到的契约是否得以保持。无论内部如何翻天覆地,只要从外面进、从外面出的东西一致,就算通过。
重构按定义就是"在保持外部行为的前提下改变内部结构"。那么,那个需要被保持的"外部行为"的定义,就必须被固定在某处。tsma 守住内侧边界,Hurl 守住外侧边界。两层同时存在时,你才能对智能体说:“尽管翻天覆地地改,哪里破了让机器来看。”
无法逢迎的裁判
这与 Symbolic Feedback Loop 的本质精确咬合。
你问智能体"重构做得好吗?",它会答"是的,我整理得很干净。“你给它意见,它会逢迎。但你一跑 Hurl,就会冒出 POST /orders → expected 201, got 500。数字和状态码无法逢迎。因为它们没有感情。
从流量中提取的 Hurl 测试,是一份没有人为判断介入的规范。它不是某个人"我认为它应该这样运作”,而是"观测结果显示它就是这样运作"。不是主张,而是测量。所以重构的对错,可以由机器而非人来裁定。LLM 不是判断者而是执行者,裁定由确定性工具来完成。
唯一的前提,是记录完善的日志
这套方法要成立,只需要一样东西。一个月记录完善的日志。
这里"记录完善"就是全部。仅有 access log 是不够的。它给出端点、status code 和 timing,却不给出需要固定的核心——request body 与 response body 的配对。仅知道 POST /orders → 201,无法重现"对这个输入发出了这个输出"。要固定功能,就得把进去的和出来的都握在手里。
所以真正的问题不是"怎么写测试",而是"我的日志记录得足够完善,能成为规范吗"。
- request/response body 有没有留存,还是只留了 status code。
- 错误响应有没有一并留存。422 与 500 的 body,恰恰是人想象不到的边缘情况。
- 日志是否结构化,让机器能把请求与响应配成对。
如果这些都齐备,那你其实已经写了一个月的规范了。无需另外编写测试。日志流水线一直在替你写。如果不齐备,现在加上一层中间件,开一个月即可。一个月后,遗留系统的当前行为就整个落入你手中。
为什么是一个月而不是一天。一天只能抓住 happy path。一个月能抓住月末批处理、结算前夕的流量暴涨、极少被调用的管理员端点、凌晨 3 点跑一次的 cron——抓住系统的长尾。规范不是平均值,而是分布。
把日志翻译成 Hurl,固定功能
日志齐备后,剩下的就是机械活儿。把一个月的 request/response 配对喂进工具,把每一对翻译成 Hurl 块。如此倾泻而出的数百个 Hurl 文件,就是 characterization 套件——把遗留系统的当前行为整个固定下来的安全网。一行代码都没读。只读了流过的流量。
这里有一个常见的迟疑之处,先提前点破。“日志里含有个人信息、支付、令牌,把它们当作测试固定下来真的可以吗?”
可以。准确说,根本无需固定。因为这套方法论本来就不需要值。 characterization test 固定的不是值,而是行为。
HTTP 201
[Asserts]
jsonpath "$.order_id" exists
jsonpath "$.total" == 49800
这里作为规范重要的,不是 49800 这个数字,而是"total 字段以整数存在,并对给定输入这样计算得出"这一结构。把值掩码或换成合成数据,规范的价值几乎不会减少。capture → 掩码 → 生成 Hurl,这整条流水线都在你的基础设施内部运转。raw 日志没有任何外流的机会。剩下的只有值被遮盖的规范,只保留结构的契约。日志可以不向外发送,这不是安全上的让步,而是这种方法的本质——因为本来就只需固定行为。
把生成的 Hurl 在 staging 上跑一遍,当场就分出通过/失败。如果绿灯全亮,现在就可以开始重构了。让智能体尽管翻天覆地地改,哪里破了由 Hurl 来看。
无需代码就架起的梯子
所以这种方法真正的价值,不是"快速写出测试"。真正的价值在于这些。
- 不读代码就能开始 —— 原作者走了,文档也没有,但仅凭流过的流量就能铺下安全网。在理解代码之前,先获得了动手的资格。
- 成果立即可验证 —— 把生成的 Hurl 在 staging 上跑,当场就出 pass/fail。不是"应该没问题吧",而是"现在 327 个里通过 327 个"。
- 数据不越过围墙 —— 从 capture 到生成 Hurl,全部在我的基础设施内部完成。越是受监管的行业,越能体现"什么都不向外发送就能开始"的决定性意义。
遗留系统现代化的第一铲,通常停在"没人知道当前行为是什么"这道悬崖前。流量 → Hurl 在那道悬崖上架起一把梯子。架梯子不需要代码。流过的流量就够了——而且连那些流量都原样留在围墙之内。
流量早已在书写规范
我们费力地另写规范。手工编 OpenAPI,在 wiki 里描述行为,等它们与代码错位时便称之为漂移,连连叹息。
但活着的系统每时每刻都在亲手书写自己的规范。每当一个请求进来、一个响应出去,那就是一句"我是这样的系统"的自我描述。日志文件,就是那部自传积累一个月的产物。
只是我们没有去读罢了。
遗留系统不是没有文档。文档就在 access log 里,只是其形式让人读起来不便。用 Hurl 一翻译,它就变成可运行的规范,变成由机器裁定的契约。
文档会说谎。流量不会说谎。
相关文章
- Hurl 阻止漂移 — 用纯文本声明 HTTP 契约并锁进 CI 的方法。如果本文是"流量 → Hurl",那篇就是"用 Hurl 锁住漂移"。
- tsma —— 遗留代码的回归防线 — 两层安全网的内侧边界(函数级)。如果 Hurl 是外侧边界,那么 tsma 就是内侧。
- Agent Operable Codebase — 把遗留系统提升为智能体可操作代码的三阶段流水线。
- 编码智能体为何运作,为何崩溃 — Symbolic Feedback Loop 的结构。
- 约束即契约 — 作为可验证、可强制的契约的测试。
- 拯救失败的 vibe coding — 用 characterization testing 对遗留系统进行诊断→锁定→修复→提取→迁移的实战课程。
延伸阅读
- Michael Feathers, “Characterization Testing” — 术语创造者本人的文章。“软件一进入生产,它本身就成了规范(it becomes its own specification)。“几乎就是本文标题的同一命题。
- Hurl 官方教程, “Your First Hurl File” — 从
GET / HTTP 200到--test模式。亲手握住"一行纯文本即测试"的入门。 - GitHub Engineering, “Scientist: Measure Twice, Cut Once” — 在生产中同时运行遗留(control)与新(candidate)代码并比较结果的库。“只有真实行为才是真正的规范。”
- Twitter Diffy(InfoQ 摘要)— 把同一请求发给新/旧服务,仅以响应差异作为回归来捕捉的代理。“不写测试就固定行为"的经典先例。
- GoReplay — 从网络接口捕获实时 HTTP 流量并重放到 staging 的工具。“以生产流量为测试输入"的代表实现。
- Nicolas Carlo, “Characterization vs Approval Tests” — 梳理三个实质相同技法的术语,并强调从输出中擦除敏感信息的"Printer"的作用。
- Pact — consumer-driven contract testing。与流量固定相对照的"显式契约"路径。两种方式一起看,才能取得平衡。
出处 / 依据
核心概念·工具
- Michael Feathers. Working Effectively with Legacy Code. Prentice Hall, 2004. — characterization test 概念的出处。“固定的不是代码应该正确地做什么,而是它现在做什么。”
- Hurl 项目(hurl.dev)— 纯文本 HTTP 请求/响应测试格式。已作为 yongol 的 10 个 SSOT 之一整合进来。
- tsma 527 个函数实证 — 函数级棘轮(tsma)。
从流量·执行中提取测试(carving / record-replay)
- Elbaum, Chin, Dwyer, Jorde (2009). “Carving and Replaying Differential Unit Test Cases from System Test Cases.” IEEE TSE 35(1). — 把系统执行 record 下来、再以单元为粒度 replay 的 differential unit test 的学术基础。
- Meta 工程团队 (2024). “Observation-based Unit Test Generation at Meta.” FSE 2024, arXiv:2402.06111. — 从应用执行的观测值中 carving 出测试。在 CI 中执行 960 万次,检出 5,702 个缺陷。“观测即测试"的工业规模实证。
固定当前行为(snapshot / golden master)
- Fujita, Kashiwa, Lin, Iida (2023). “An Empirical Study on the Use of Snapshot Testing.” ICSME 2023. — snapshot(= golden master/characterization)测试的采纳实证。“不固定正确性,而是固定当前输出以检测变更。”
重构安全网
- Kim, Zimmermann, Nagappan (2014). “An Empirical Study of Refactoring Challenges and Benefits at Microsoft.” IEEE TSE 40(7). — 没有能保证行为保持的测试,重构就既是成本也是风险的实证。
- Yoo, Harman (2012). “Regression Testing Minimization, Selection and Prioritization: A Survey.” STVR 22(2). — 回归测试 = “变更不会破坏既有行为的确信"的标准定义。
实际使用分布即优先级
- John D. Musa (1993). “Operational Profiles in Software-Reliability Engineering.” IEEE Software 10(2). — 按使用频次分配测试,即使因进度而中断,最常用的功能也被验证得最充分。“以流量分布取代 happy path 偏向"的经典基础。
为何应由机器裁定(LLM 不是判断者而是执行者)
Huang, Chen, Mishra, et al. (2024). “Large Language Models Cannot Self-Correct Reasoning Yet.” ICLR 2024, arXiv:2310.01798. — 没有外部反馈,LLM 无法校正自己的推理。这正是需要确定性外部验证器的原因。
Sharma, Tong, et al. (2024). “Towards Understanding Sycophancy in Language Models.” ICLR 2024, arXiv:2310.13548. — RLHF 让模型学会附和,瓦解了 LLM 自我裁定的可信度。
封面图片:AI 生成(Google Gemini)