Image: AI generated
一个问题
打开你项目中最长的文件。里面有几个函数?
让AI Agent修改其中一个函数。Agent会读取整个文件。它需要一个函数才打开文件,但19个不需要的函数跟着一起来了。
问题从这里开始。
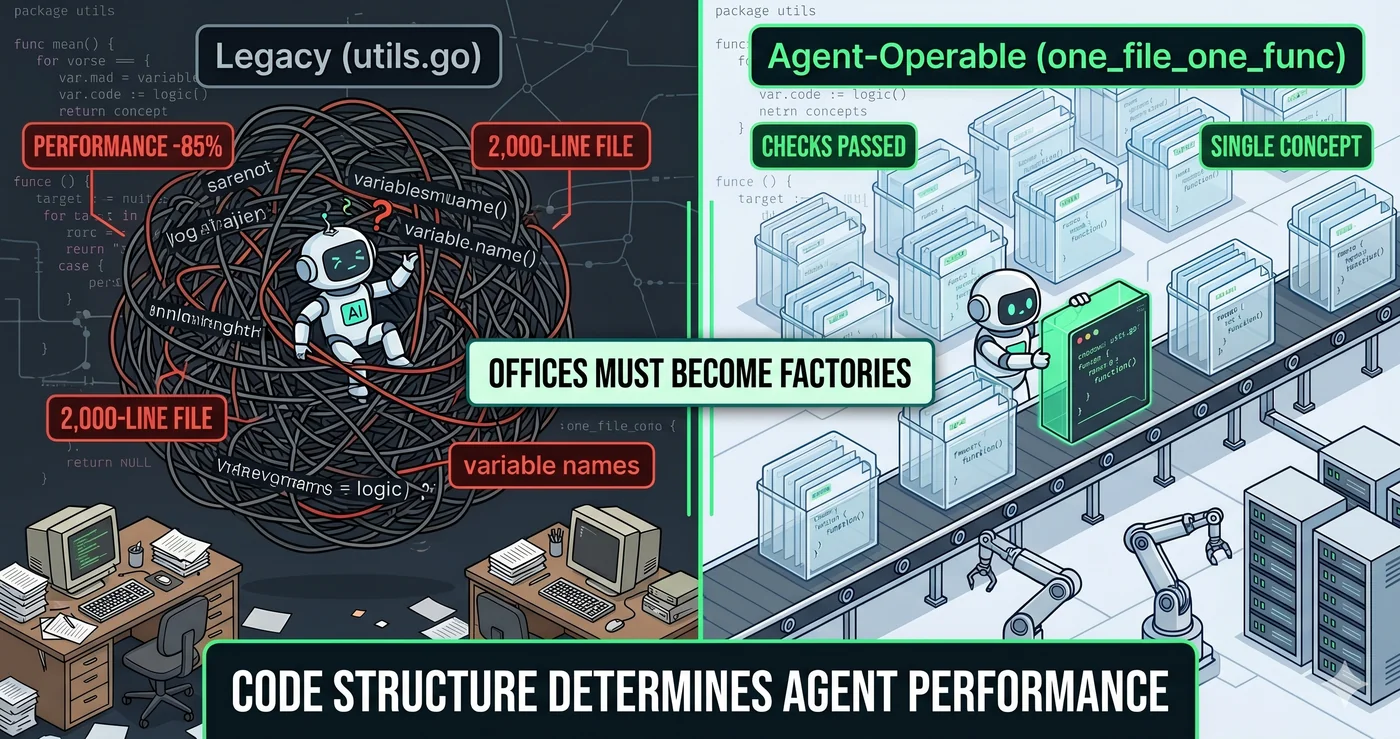
人读的代码,Agent操作的代码
一直以来,代码是给人读的。变量名起得好、加注释、写文档——全都是为了减轻人的认知负担。
Agent时代,问题变了。人读起来好的代码和Agent操作起来好的代码是一回事吗?
不是。
| 人 | AI Agent | |
|---|---|---|
| 导航方式 | 目视浏览目录树 | 用grep搜索 |
| 打开文件 | 在IDE中滚动 | read file — 加载整个文件 |
| 上下文判断 | 直觉 + 经验 | 只知道上下文中有的 |
| 不必要的代码 | 忽略它 | 消耗上下文预算 |
| 2,000行文件 | 只看需要的部分 | 处理全部 |
人在2,000行文件中滚动时有"这部分不要动"的直觉。Agent没有这种直觉。读2,000行意味着1,950行是上下文污染。
研究证实了这一点。不必要的信息混入时,AI性能下降30~85%。不必要的token即使是空白也会降低性能。上下文越短越好——这不是直觉,而是实验结果。
不要把机器人放进人的办公室。要建造机器人能工作的工厂。METR的随机对照实验用数字说明了这一点——16名熟练开源开发者在成熟代码库中使用AI工具时,完成时间增加了19%。不是更快了——而是更慢了(Becker et al., 2025)。
Agent需要的三件事
Agent要在代码库中稳定工作,需要三件事。
1. 可读性 — 无噪音
一个文件一个概念。文件名就是概念名。
before: read utils.go → 20个函数,19个不需要
after: read check_one_file_one_func.go → 1个函数,正好需要的
filefunc解决了这个问题。22条结构规则将代码按语义单元分离。在Hono框架(star 23k+)中,186个文件被分成626个。4,419个测试全部通过。文件增加了3.4倍但逻辑一行都没变。
“文件不会太多吗?"——Agent不打开目录。它搜索。无论是500个还是1,000个文件,grep一下就完了。不打开295个不需要的文件比挑出5个需要的更重要。
2. 可验证性 — 机械地
修改没有测试的函数,谁也不知道会坏什么。Agent也不知道。会陷入doom loop。
before: 0个测试,修改后不知道什么会坏
after: 527个函数都有测试,行为变化立即检测
tsma解决了这个问题。它索引项目中的每个函数,检测测试存在与否,测量覆盖率,用行号反馈未覆盖分支。
不给反馈让LLM写测试,覆盖率在60~70%停滞。告诉它"第41、44、70行未覆盖"就达到100%。同一个模型。差别只在反馈分辨率。CoverUp研究也得出相同结论——迭代地向LLM反馈覆盖率分析,仅聚焦未覆盖行,模块覆盖率就从47%跳到80%(Pizzorno & Berger, 2024)。
527个函数的项目中:完成到TODO为0。自主Agent在40个时宣布"完成了”。应用棘轮后,完成了全部527个。
3. 规范可交叉验证
API模式、DB模式、安全策略、状态转换是否相互一致,必须能机械确认。改了一个,和其他地方的偏差必须在编译前可检测。
before: 200个端点,人来确认规范间一致性
after: operationId链接所有层,机器检测漂移
yongol解决了这个问题。用单个operationId链接10个SSOT(OpenAPI, DDL, sqlc, SSaC, Rego, Hurl等),用~287条规则交叉验证。OpenAPI中user_id是string但DDL中是BIGINT——这种层间矛盾,现有工具抓不到。
贯穿三个工具的一个结构
filefunc、tsma、yongol是独立工具,但有共同结构。
filefunc: 22条结构规则 → validate → 修正 → 重复
tsma: 覆盖率测量 → 未覆盖分支反馈 → 修正 → 重复
yongol: 交叉验证 → 漂移检测 → 修正 → 重复
全是同一个循环。
LLM生成 → 确定性工具判定 → 结果反馈给LLM → 重复
Symbolic Feedback Loop。确定性工具纠正LLM概率性生成的循环结构。不是AI验证AI,而是机器验证AI。
给意见就谄媚,给事实就修正。问"代码没问题吧?“答"是的,很好”。告诉它"line 41: field name mismatch"立即修正。没有谄媚对象的反馈——数字和位置不是情感。
从遗留系统到agent-operable
不需要一次改变整个代码库。这不是基础工程,而是抗震加固。不关门就加固营业中的建筑。
第1步 — 使其可读
从最长的文件开始拆分。运行filefunc validate并将违规降到零。所有现有测试必须通过。
第2步 — 使其可验证
反复运行tsma next。给没有测试的函数添加测试,填充未覆盖分支。Agent中途挂了进度也保留。新Agent运行tsma next继续。
第3步 — 交叉验证
引入SSOT并运行yongol validate。机器捕捉层间矛盾。
每步都是独立的。不做第1步只做第2步也行,不做第2步只做第1步也行。但三者结合时,Agent自主工作范围将大幅扩展。
改变操作系统
agent-operable codebase不仅仅是lint或工具层面的事。是改变代码库的操作系统。
| human-readable | agent-operable | |
|---|---|---|
| 文件大小 | 人可滚动的范围 | 一个概念 |
| 测试 | 有最好,没有靠直觉 | 每个函数必须有 |
| 规范 | 文档、wiki、口头传达 | 声明式、可交叉验证、机器可读 |
| 反馈 | PR审查(小时级) | 验证器执行(秒级) |
| 终止判断 | 人说"好了" | 机器说"还剩487个" |
GitClear的分析显示了这一转型的紧迫性——分析2020~2024年2.11亿变更行,随着AI工具普及,代码重复增加8倍,重构比例从25%下降到10%(GitClear, 2025)。不铺铁轨,火车越快事故越多。
很多人在让火车跑得更快。更大的模型、更聪明的Agent、更好的Prompt。
火车越快,铁轨越重要。铺铁轨的人几乎没有。
相关文章
- filefunc — 一个文件一个概念 — 22条结构规则消除LLM上下文污染
- tsma — 遗留代码的回归防线 — 基于棘轮的测试自动化,527个函数完成到TODO为0
- 编程Agent为何能工作,又为何会崩溃 — Symbolic Feedback Loop的结构分析
- 比起模型IQ,更重要的是反馈拓扑 — 同一模型停在40或完成527的原因
- whyso — git blame不显示的东西 — 文件级变更历史自动提取
根据资料
- Stanford, “Lost in the Middle: How Language Models Use Long Contexts” (2024) — 相关信息埋在上下文中间时30%+性能下降
- Amazon, “Context Length Alone Hurts LLM Performance” (2025) — 不必要token即使是空白也13.9~85%性能下降
- Hono框架实证 — 186个文件 → 626个文件分离,4,419个测试全部通过
- tsma 527个函数实证 — PASS 246 (46.7%), DONE 281 (53.3%), TODO 0
- Ratchet Pattern实验 — 自主Agent 40/527 (7.6%) vs 棘轮CLI 527/527 (100%)
出处
- Joel Becker, Nate Rush, Elizabeth Barnes, David Rein. “Measuring the Impact of Early-2025 AI on Experienced Open-Source Developer Productivity.” arXiv:2507.09089, 2025.
- GitClear Research. “AI Copilot Code Quality Report.” 2025.
- Juan Altmayer Pizzorno, Emery D. Berger. “CoverUp: Coverage-Guided LLM-Based Test Generation.” arXiv:2403.16218, 2024.
- Kelly Hong, Anton Troynikov, Jeff Huber. “Context Rot: How Increasing Input Tokens Impacts LLM Performance.” Chroma Technical Report, 2025.
- Mrinank Sharma et al. “Towards Understanding Sycophancy in Language Models.” ICLR 2024 (arXiv:2310.13548).
- Google DORA Team. “Accelerate State of DevOps Report.” 2024.
- Dantas et al. “The 4/δ Bound: Designing Predictable LLM-Verifier Systems for Formal Method Guarantee.” arXiv:2512.02080, 2025.
变更历史
- 2026-05-25: 初版