 Image: AI generated
Image: AI generated
Being Smart Doesn’t Mean You Can Explain
Ask Opus 4.8 to refactor code and the result is stunning. It untangles complex dependency graphs in a single pass, preemptively handles edge cases, and writes tests with no gaps. But ask it to explain the result, and trouble begins. It speaks the way an expert reports to another expert. It assumes shared background knowledge, omits the reasoning behind critical decisions, and operates at an unnecessarily high level of abstraction.
Ask Opus 4.6 the same thing and you get the opposite. It estimates well what you might not know. It picks apt analogies, breaks things into steps, and lays the context first. But when reasoning difficulty climbs, it stumbles on problems that 4.8 cracks in one shot.
One sentence summary: Opus 4.8 is brilliant but speaks in hard-to-follow language; Opus 4.6 explains clearly but has lower reasoning performance.
This is not a defect. Why it happens, and how to turn this difference into a structural advantage, is the subject of this article.
The Curse of Knowledge Applies to LLMs Too
In 1989, psychologists Camerer, Loewenstein, and Weber demonstrated it experimentally. The more information a person possesses, the worse they are at accounting for the fact that others lack that information. Known as the “Curse of Knowledge,” this phenomenon is a cognitive bias repeatedly confirmed across education, economics, and UX design.
Oliver Wendell Holmes said it well: “I would not give a fig for the simplicity this side of complexity, but I would give my life for the simplicity on the other side of complexity.” Easy explanation is not easy because you know little; it becomes possible only after you have pierced through the complexity. Yet paradoxically, while you are inside the complexity, your ability to speak simply deteriorates.
A 2025 EMNLP paper showed this phenomenon manifests in large reasoning models as well. The paradoxical finding: the more powerful a model’s reasoning ability, the more vulnerable it is to the Curse of Knowledge. A deeply reasoning model implicitly assumes its interlocutor can follow its chain of thought. Exactly the same problem a human expert faces when explaining to a beginner.
So the world has two kinds of roles. Those who think deeply and those who convey clearly. Researcher and science communicator. Senior developer and tech lead. Judge and attorney. These are different competencies. It would be nice if one person excelled at both, but in practice that is rare. That is why organizations separate the roles.
The same goes for LLMs. And Claude Code makes this separation possible with a single line of configuration.
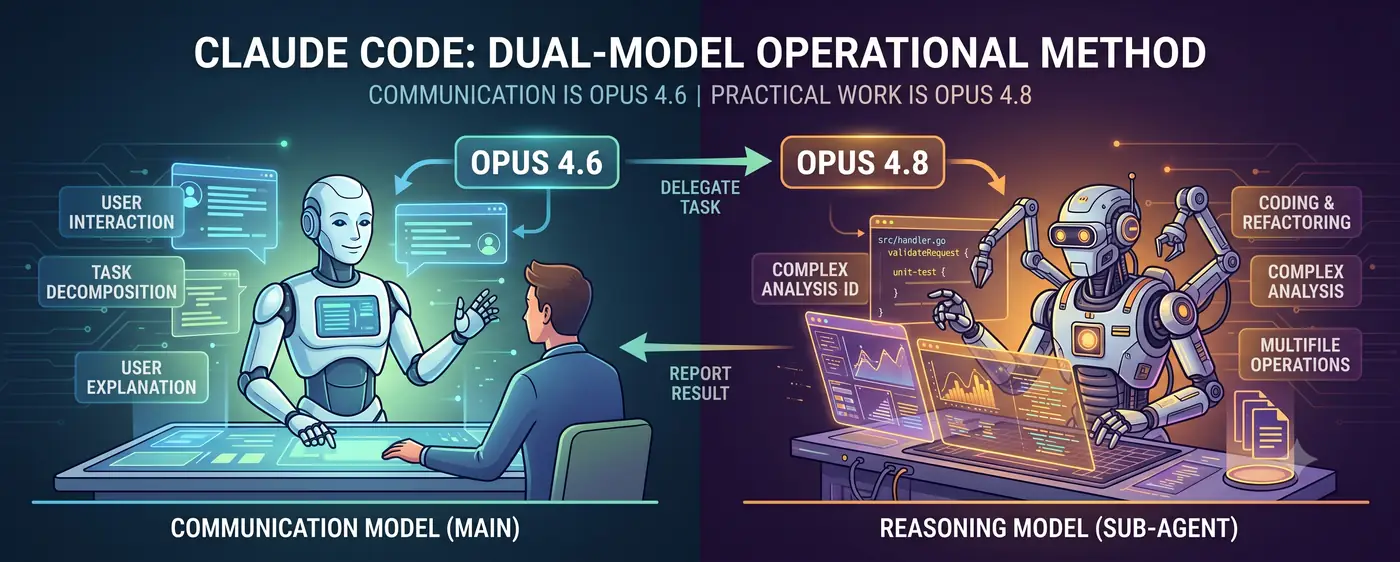
Communication Model + Reasoning Model
The core structure is simple.
User <-> Communication model (main) <-> Reasoning model (subagent)
- The communication model (Opus 4.6) takes the front of the conversation. It grasps the user’s intent, decomposes tasks, and reports results in language a human can understand.
- The reasoning model (Opus 4.8) handles the heavy lifting. It receives high-difficulty reasoning tasks as a subagent: code writing, complex analysis, multi-file refactoring.
The user talks to 4.6. When 4.6 judges “this is too reasoning-intensive for me to handle directly,” it spawns a 4.8 subagent and delegates the work. When 4.8 returns the result, 4.6 interprets it and explains it to the user.
This very article is proof of that structure. The one writing this article right now is Opus 4.6 (main), while the academic paper searches and benchmark data analysis that underpin it were performed by Opus 4.8 (subagent).
What the Benchmarks Say
BenchLM data reveals the character of the two models in numbers.
| Domain | Opus 4.6 | Opus 4.8 | Edge |
|---|---|---|---|
| Overall | 86 | 93 | 4.8 |
| Coding | 64.4 | 76.4 | 4.8 |
| Agent tasks | 72.6 | 80.1 | 4.8 |
| Knowledge tasks | 76.2 | 70.1 | 4.6 |
| Creative writing | Edge | - | 4.6 |
4.8 dominates in coding and agent tasks. But in knowledge delivery and creative writing, 4.6 leads. Claude API reviews also repeatedly note that 4.8’s writing is “more AI-sounding” than 4.6’s. 4.8 reasons with precision, but 4.6 is better at unfolding that reasoning into prose that humans enjoy reading.
Both models are priced identically – $5 per million input tokens, $25 per million output tokens. Splitting the roles does not increase cost. This is not cost optimization; it is pure quality optimization.
Model Routing Is Already Proven Engineering
The idea of “using two models for different roles” is not new. It is an established field in academia.
RouteLLM (ICLR 2025) dynamically routed queries between a strong model and a weak model, cutting costs by more than 2x while maintaining quality. FrugalGPT (2023) achieved GPT-4-level performance via LLM cascades with 98% cost reduction. The shared conclusion of these studies is clear: a weak model with excellent orchestration often beats a strong model with poor orchestration.
Anthropic itself uses this pattern. Anthropic’s deep-research implementation follows the orchestrator-worker pattern, and a multi-agent configuration outperformed single-agent Opus 4 by 90.2%. Surveys also show that roughly 80% of production multi-agent systems adopt the orchestrator-worker structure.
What I do is the simplest form of this pattern. No router, no cascade, no cost optimization. Simply a model optimized for communication stands in front, and a model optimized for reasoning works behind. The principle of role separation, in its purest form.
How to Set It Up
Building this structure in Claude Code is straightforward.
Step 1: Set the Main Model
Run Claude Code on Opus 4.6. Set the default model to claude-opus-4-6-20250610 in settings, or select the model at launch. This becomes the communication model that talks to the user.
Step 2: Override the Model on Subagents
Claude Code’s Agent tool supports a model parameter. When spawning a subagent, override the model to opus (Opus 4.8).
Agent({
description: "Code refactoring",
model: "opus",
prompt: "Refactor the validateRequest function in src/handler.go..."
})
That is all. The main agent (4.6) converses with the user, and high-difficulty work is delegated to subagents (4.8).
Step 3: Distinguish fork from fresh agent
Claude Code subagents come in two kinds.
- fork (
subagent_type: "fork"): Inherits the current conversation’s context as-is. Shares the prompt cache, so input costs drop by up to 90%. However, a fork forcibly inherits the parent model, so model overrides do not apply. - fresh agent: Starts with a new context. Model override is possible. You must include the necessary background directly in the prompt.
Therefore, to use the reasoning model (4.8), you must spawn a fresh agent. Use fork when you need parallel exploration while keeping the communication model (4.6).
Practical Patterns
| Situation | Method | Reason |
|---|---|---|
| Complex code writing | fresh agent + model: opus | High reasoning difficulty |
| Multi-file refactoring | fresh agent + model: opus + isolation: worktree | Reasoning + isolation needed |
| Parallel investigation/exploration | fork (keeps 4.6) | Context sharing is advantageous |
| Simple file reading/editing | Main (4.6) directly | Delegation overhead is greater |
| Web search/research | fresh agent + model: opus | Precise reasoning needed |
Up to 4-8 concurrent worktrees are stable. Beyond that, reviewing results becomes the bottleneck.
Known Friction
It is not perfect. Two known limitations at present.
First, model override leakage. A subagent’s model setting can propagate to sub-subagents that it creates. Unintended model usage can occur, so limiting subagent depth to one level is practical.
Second, no per-agent model configuration. Currently Claude Code does not officially support pre-assigning models per agent type in project settings. You must specify the model parameter on every Agent call. Community requests for this feature are active.
Both are friction that will resolve as Claude Code evolves. Even in the current state, manual overrides are sufficient to reap the structural benefits.
Communicator and Thinker Are Different Roles
In a courtroom, a judge and an attorney deal with the same law but play different roles. The judge decides. The attorney explains what that decision means to the client. If the judge reads the ruling directly to the client, the client cannot understand it. If the attorney renders the decision herself, the reasoning is thin. Role separation is not a weakness of the system; it is a strength.
The same applies to code review. A senior developer’s ability to find a bug and the ability to make a junior developer understand that bug are separate competencies. It is rare for a brilliant engineer to also be a brilliant tech writer. Organizations know this, which is why they divide the roles.
AI is no different. Reasoning ability and communication ability are different axes. And in the current model training process, these two axes tend to conflict. Maximizing reasoning performance makes output compressed and specialized; maximizing communication performance shallows the depth of reasoning.
Demanding that a single model excel at both is like asking a judge to play the attorney’s role as well. It can be done. But neither will be optimal.
The separation of communication model and reasoning model is a structural principle that remains valid across model versions. 4.6 and 4.8 are today’s specific choices. When 5.0 and 5.2 arrive tomorrow, the same principle re-deploys. Models get replaced, but the fact that “the role of thinking deeply” and “the role of conveying clearly” are different – that does not get replaced.
Related Posts
- Ratchet Pattern – How to Make an Agent Finish the Job
- Why Your Agent Loop Diverges
- Why Drift Never Dies
Further reading (external)
- RouteLLM: Learning to Route LLMs with Preference Data – A framework for dynamically routing queries between strong and weak models based on query difficulty.
- Anthropic: How we built our multi-agent research system – How Anthropic implemented deep-research using the orchestrator-worker pattern.
Sources
- Camerer, C., Loewenstein, G. & Weber, M. (1989). The Curse of Knowledge in Economic Settings: An Experimental Analysis. Journal of Political Economy, 97(5), 1232-1254. DOI – Experimental proof of the Curse of Knowledge.
- Li, W. et al. (2025). Curse of Knowledge: Your Guidance and Provided Knowledge are biasing LLM Judges in Complex Evaluation. Findings of EMNLP 2025. arXiv – Finding that stronger reasoning models are more vulnerable to the Curse of Knowledge.
- Ong, I. et al. (2025). RouteLLM: Learning to Route LLMs with Preference Data. ICLR 2025. arXiv – A framework for learning to route LLMs using preference data.