 Image: AI generated
Image: AI generated
Умный человек не обязательно хорошо объясняет
Когда поручаешь Opus 4.8 рефакторинг кода, результат вызывает восхищение. Он разом распутывает сложный граф зависимостей, превентивно обрабатывает граничные случаи и пишет тесты без единого пробела. Но когда просишь объяснить результат, начинаются проблемы. Он говорит так, будто эксперт отчитывается перед экспертом. Предполагает, что фоновые знания само собой разумеются, опускает причины ключевых решений, а уровень абстракции неоправданно высок.
Если задать тот же вопрос Opus 4.6, картина прямо противоположная. Он хорошо предугадывает, чего именно вы можете не знать. Подбирает аналогии, разбивает на шаги, сначала закладывает контекст. Но когда сложность рассуждений возрастает, он буксует там, где 4.8 пробивается с первого раза.
Одной фразой: Opus 4.8 умён, но говорит сложно, а Opus 4.6 объясняет понятно, но уступает в рассуждениях.
Это не дефект. Почему так происходит и как превратить это различие в структурное преимущество — тема этой статьи.
Проклятие знания применимо и к LLM
В 1989 году психологи Camerer, Loewenstein и Weber экспериментально доказали: чем больше информации у человека, тем хуже он учитывает, что собеседник этой информацией не располагает. Это явление, называемое “проклятием знания” (Curse of Knowledge), — когнитивное искажение, многократно подтверждённое в педагогике, экономике и UX-дизайне.
Оливер Уэнделл Холмс сказал: “За простоту по эту сторону сложности я не дам и гроша. Но за простоту по ту сторону сложности я отдам жизнь.” Простое объяснение просто не потому, что автор не знает, а потому, что оно возможно лишь после прохождения через сложность. Однако парадокс в том, что пока ты внутри сложности, способность говорить просто снижается.
Статья EMNLP 2025 года показала, что это явление проявляется и у крупных моделей рассуждений. Парадоксальный результат: чем мощнее способность модели к рассуждениям, тем более уязвима она к проклятию знания. Модели, которые рассуждают глубоко, имплицитно предполагают, что собеседник способен проследить их цепочку рассуждений. Это та самая проблема, с которой сталкивается эксперт, объясняя что-то новичку.
Поэтому в мире существуют два типа ролей: те, кто глубоко думает, и те, кто доступно доносит. Исследователь и научный коммуникатор. Старший разработчик и техлид. Судья и адвокат. Это разные компетенции. Хорошо бы, чтобы один человек владел обеими, но на практике это редкость. Поэтому организации разделяют роли.
С LLM то же самое. И Claude Code позволяет реализовать это разделение одной строкой настроек.
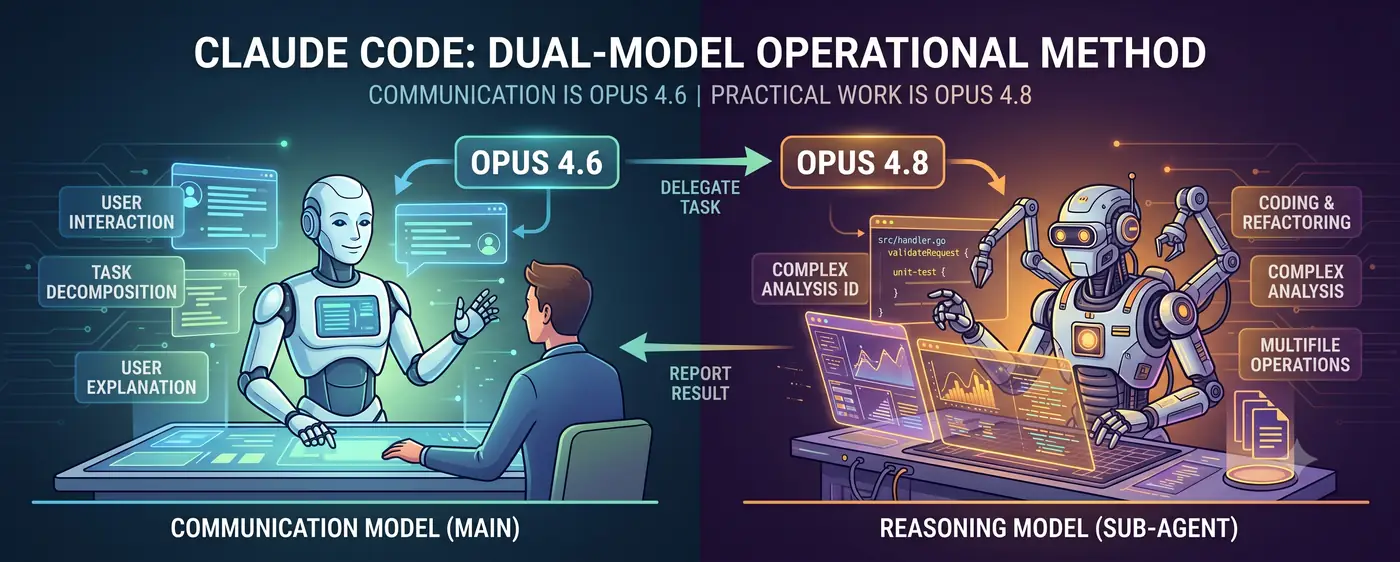
Коммуникационная модель + модель рассуждений
Ключевая структура проста.
Пользователь <-> Коммуникационная модель (основная) <-> Модель рассуждений (subagent)
- Коммуникационная модель (Opus 4.6) стоит на переднем плане диалога. Она распознаёт намерение пользователя, декомпозирует задачу и докладывает результат на понятном человеку языке.
- Модель рассуждений (Opus 4.8) выполняет работу. Написание кода, сложный анализ, рефакторинг множества файлов — задачи высокой сложности делегируются ей как subagent.
Пользователь общается с 4.6. Когда 4.6 решает: “Сложность рассуждений слишком высока для меня”, — она создаёт subagent 4.8 и делегирует задачу. Когда 4.8 возвращает результат, 4.6 интерпретирует его и объясняет пользователю.
Сама эта статья — тому доказательство. Сейчас её пишет Opus 4.6 (основная модель), а поиск научных статей и анализ данных бенчмарков, лежащих в основе этого текста, выполнил Opus 4.8 (subagent).
Что показывают бенчмарки
Данные BenchLM раскрывают характер двух моделей в цифрах.
| Область | Opus 4.6 | Opus 4.8 | Преимущество |
|---|---|---|---|
| Общий балл | 86 | 93 | 4.8 |
| Кодинг | 64.4 | 76.4 | 4.8 |
| Агентные задачи | 72.6 | 80.1 | 4.8 |
| Задачи на знания | 76.2 | 70.1 | 4.6 |
| Художественное письмо | Преимущество | - | 4.6 |
В кодинге и агентных задачах 4.8 доминирует. Но в передаче знаний и художественном письме лидирует 4.6. В обзорах Claude API тоже неоднократно отмечается, что тексты 4.8 “звучат более по-машинному” (more AI-sounding), чем у 4.6. 4.8 рассуждает точно, но способность излагать эти рассуждения доступно для человека — у 4.6 лучше.
Цена обеих моделей одинакова — $5 за миллион входных токенов, $25 за миллион выходных. Разделение ролей не увеличивает расходы. Это не оптимизация стоимости, а чистая оптимизация качества.
Маршрутизация моделей — уже доказанная инженерная практика
Идея “использовать две модели раздельно” не нова. В академической среде это уже устоявшееся направление.
RouteLLM (ICLR 2025) динамически маршрутизирует запросы между сильной и слабой моделями, снижая стоимость более чем вдвое при сохранении качества. FrugalGPT (2023) достигает уровня GPT-4 с помощью каскада LLM при снижении затрат на 98%. Общий вывод этих исследований однозначен: слабая модель с хорошей оркестрацией нередко побеждает сильную модель с плохой оркестрацией.
Сама Anthropic использует этот паттерн. Реализация deep-research от Anthropic — это паттерн оркестратор-воркер, и многоагентная конфигурация превзошла одиночный agent Opus 4 в 90.2% случаев. По результатам исследований, около 80% продакшн-систем с несколькими агентами используют структуру оркестратор-воркер.
То, что делаю я, — простейшая форма этого паттерна. Без маршрутизатора, без каскада, без оптимизации стоимости. Просто модель, оптимизированная для коммуникации, стоит впереди, а модель, оптимизированная для рассуждений, работает позади. Принцип разделения ролей в чистом виде.
Как настроить
Создать эту структуру в Claude Code просто.
Шаг 1: Настройка основной модели
Запустите Claude Code с Opus 4.6. В настройках укажите модель по умолчанию как claude-opus-4-6-20250610 или выберите модель при запуске. Это и будет коммуникационная модель, общающаяся с пользователем.
Шаг 2: Переопределение модели для subagent
Инструмент Agent в Claude Code поддерживает параметр model. При создании subagent достаточно переопределить модель на opus (Opus 4.8).
Agent({
description: "Рефакторинг кода",
model: "opus",
prompt: "Функция validateRequest в src/handler.go..."
})
Это всё. Основной agent (4.6) общается с пользователем, а сложные задачи делегирует subagent (4.8).
Шаг 3: Различие между fork и fresh agent
В Claude Code есть два типа subagent.
- fork (
subagent_type: "fork"): наследует контекст текущего диалога. Разделяет кеш промптов, экономя до 90% затрат на ввод. Однако fork принудительно наследует модель родителя, поэтому переопределение модели не применяется. - fresh agent: стартует с чистым контекстом. Переопределение модели возможно. Необходимый контекст нужно передать прямо в промпте.
Таким образом, чтобы использовать модель рассуждений (4.8), нужно создавать fresh agent. fork используется, когда нужен параллельный поиск с сохранением коммуникационной модели (4.6).
Практические паттерны
| Ситуация | Метод | Причина |
|---|---|---|
| Сложный код | fresh agent + model: opus | Высокая сложность рассуждений |
| Рефакторинг нескольких файлов | fresh agent + model: opus + isolation: worktree | Рассуждения + изоляция |
| Параллельное исследование | fork (остаётся 4.6) | Выигрыш от общего контекста |
| Простое чтение/редактирование файлов | Основная модель (4.6) напрямую | Накладные расходы на делегирование выше |
| Веб-поиск/исследование | fresh agent + model: opus | Требуется точное рассуждение |
До 4-8 одновременных worktree система работает стабильно. Сверх того узким местом становится ревью результатов.
Известные шероховатости
Идеала нет. Два известных на данный момент ограничения.
Во-первых, проблема утечки переопределения модели. Настройка model для subagent может распространиться на дочерние агенты, которых этот subagent создаёт. Возможно непреднамеренное использование модели, поэтому практичнее ограничивать глубину subagent одним уровнем.
Во-вторых, отсутствие предустановки модели по типу агента. Сейчас Claude Code не поддерживает официальную возможность заранее задать модель для каждого типа агента в настройках проекта. Параметр model нужно указывать при каждом вызове Agent. Сообщество активно запрашивает эту функцию.
Обе шероховатости исчезнут по мере развития Claude Code. Уже сейчас ручного переопределения достаточно, чтобы в полной мере пользоваться преимуществами этой структуры.
Коммуникатор и мыслитель — разные роли
В суде судья и адвокат работают с одним и тем же законом, но роли у них разные. Судья выносит решение. Адвокат объясняет клиенту, что это решение означает. Если судья зачитает приговор клиенту напрямую, тот не поймёт. Если адвокат начнёт выносить решения, обоснования будут слабыми. Разделение ролей — не слабость системы, а её сила.
То же и с код-ревью. Способность старшего разработчика находить баги и способность объяснить эти баги младшему — разные вещи. Выдающийся инженер редко бывает выдающимся техническим писателем. Организации это знают и потому разделяют роли.
С AI то же самое. Способность к рассуждению и способность к коммуникации — разные оси. И в текущем процессе обучения моделей эти оси имеют тенденцию конфликтовать. Максимизация рассуждений делает вывод сжатым и специализированным, а максимизация коммуникации снижает глубину рассуждений.
Требовать от одной модели преуспеть в обоих — всё равно что требовать от судьи выполнять ещё и роль адвоката. Возможно. Но ни то, ни другое не будет оптимальным.
Разделение коммуникационной модели и модели рассуждений — структурный принцип, остающийся в силе при смене версий. 4.6 и 4.8 — лишь сегодняшний конкретный выбор. Когда завтра выйдут 5.0 и 5.2, тот же принцип позволит перераспределить роли заново. Модели меняются, но факт, что “роль глубокого мышления” и “роль доступного объяснения” — это разные вещи, — не меняется.
Связанные статьи
- Ratchet Pattern — как заставить агента дойти до конца
- Почему ваш агентный цикл расходится
- Почему дрифт не умирает
Дополнительное чтение (внешнее)
- RouteLLM: Learning to Route LLMs with Preference Data — фреймворк динамической маршрутизации запросов между сильной и слабой моделями в зависимости от сложности.
- Anthropic: How we built our multi-agent research system — как Anthropic реализовала deep-research с помощью паттерна оркестратор-воркер.
Источники
- Camerer, C., Loewenstein, G. & Weber, M. (1989). The Curse of Knowledge in Economic Settings: An Experimental Analysis. Journal of Political Economy, 97(5), 1232-1254. DOI — экспериментальное доказательство проклятия знания.
- Li, W. et al. (2025). Curse of Knowledge: Your Guidance and Provided Knowledge are biasing LLM Judges in Complex Evaluation. Findings of EMNLP 2025. arXiv — открытие того, что сильные модели рассуждений более уязвимы к проклятию знания.
- Ong, I. et al. (2025). RouteLLM: Learning to Route LLMs with Preference Data. ICLR 2025. arXiv — фреймворк обучения маршрутизации LLM на основе данных предпочтений.