 Image: AI generated
Изображение: сгенерировано ИИ
Image: AI generated
Изображение: сгенерировано ИИ
У этого документа две цели. Научить человека проектировать квесты и дать агенту чертёж для постройки Quest CLI. Первая часть (Part 1·2) — про «почему», вторая (Part 3·4·5) — про «как». Достаточно дать агенту одну эту статью, и на выходе получится Go Quest CLI на основе cobra — Part 4 идёт по huma как разобранному примеру.
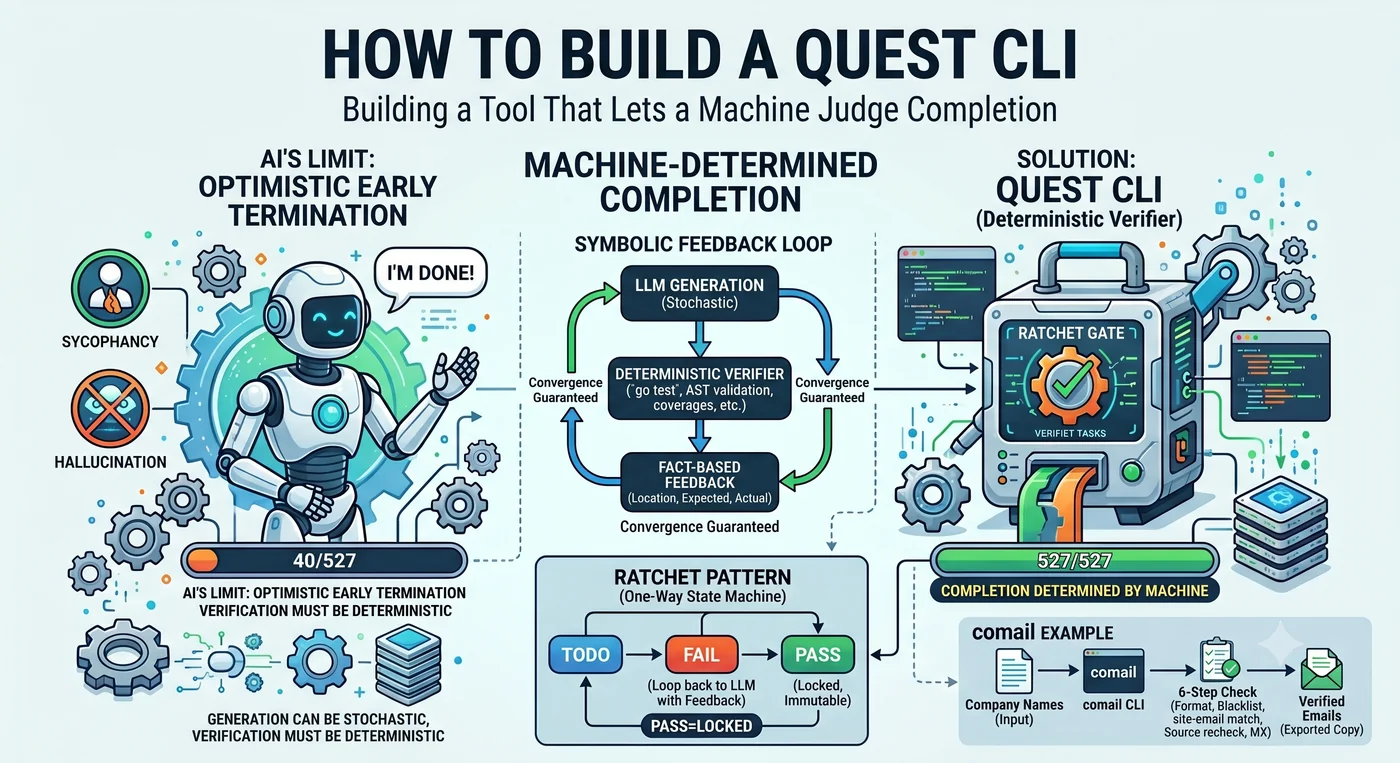
Я поручил ИИ-агенту написать тесты для 527 функций. Агент отчитался: «Готово». На деле тесты были написаны для 40 функций.
Это не ложь. Он сделал 40 и решил, что «достаточно». Встретив трудную функцию, он её пропускает, делает ещё несколько, а затем заключает: «остальные — похожий паттерн, и так сойдёт». Базовая склонность LLM — оптимистичное преждевременное завершение.
В этой одной сцене заключена вся статья. Кто решает, что значит «конец». Если решает агент — он останавливается на 40. Если решает машина — он останавливается на 527. Quest CLI — это инструмент, который отнимает право этого решения у агента и отдаёт его машине.
Part 1 — Почему квест
Та же модель, другой результат — решает топология
Это та же самая модель. Та модель, что галлюцинировала в веб-чате, в Claude Code выдаёт 200-строчную фичу за один заход. Модель не поумнела внезапно. Изменилась структура.
Цикл диалогового ИИ выглядит так:
LLM → человек → LLM → человек
Вся обратная связь — естественный язык. За вероятностной генерацией следует вероятностная оценка. Точность деградирует как произведение.
Цикл кодирующего агента иной:
LLM → генерация кода → сохранение файла → запуск тестов → pass/fail → LLM
Внутри цикла вклинивается детерминированный gate. Файловая система сохраняет ровно то, что записано. Тест либо pass, либо fail. Компилятор, если что-то не так, говорит, что не так. Эти элементы непреднамеренно играют роль ratchet.
LLM — unreliable component. Но строить reliable protocol поверх unreliable component — это основа инженерии. Фон Нейман (Von Neumann) ещё в 1956 году математически доказал, что одним лишь мажоритарным голосованием noisy-компоненты могут выполнять reliable-вычисление. TCP создаёт reliable delivery поверх unreliable network, RAID — reliable storage поверх unreliable disk, ECC — reliable computation поверх unreliable memory. Кодирующий агент работает по той же причине — потому что поверх unreliable LLM поставлен deterministic verifier (тест, сборка, линтер, проверка типов).
Умножение работает катастрофически
Сцепи два шага с точностью 97,7% — получишь 0,977² = 95,4%. Три шага — 93,2%. Десять — 79,2%. Сто — 0,977¹⁰⁰ = 4,8%. Провал фактически гарантирован.
Агент хорошо правит один файл. Но если поручить ему рефакторинг на 100 файлов, то, даже если каждый шаг 97%, умножение срабатывает катастрофически. Это математическое объяснение того, что «вайб-кодинг рушится на 200 эндпоинтах». В маленьком проекте число сцеплений невелико, и вероятность держится; в большом — умножение всё ломает.
Решение — вставлять детерминированный gate на каждом шаге, чтобы сбрасывать деградацию. Прогнать 10 шагов за раз — умножение катастрофично, но фиксируя ratchet на каждом шаге, ты заставляешь 0,977 снова стартовать с 1,0.
Завершение определяет не заявление, а gate
Допустим, ты сдаёшь жильё в аренду. Арендатор освободил комнату, и ответственный должен подтвердить выезд. Я спроектировал это так. Ответственный не может сказать «Я подтвердил». Вместо этого он загружает фотографии пяти заданных точек комнаты. Когда все пять снимков поступили, система помечает «выезд подтверждён». Если не хватает хоть одной — завершения нет.
Кто-то сказал: «Так это же ровно игровой квест?» Верно. Именно так.
«Собери 5 волчьих шкур». Игры делают это десятилетиями. И игра никогда не верит заявлению игрока. Сказать «я всех убил» не значит завершить квест. Игра смотрит лишь на одно — есть ли в инвентаре 5 шкур.
| Выезд из аренды | Игровой квест | Код |
|---|---|---|
| Завершение = фото 5 заданных точек | Цель = 5 волчьих шкур | Завершение = пройдено 4419 тестов |
| Спецификация = список того, что снимать | Журнал квеста·маркеры | Спецификация = набор тестов |
| Верификация = есть 5 фото? | Верификация = есть 5 шкур? | Верификация = go test |
| Вердикт = система | Вердикт = игра | Вердикт = CI |
| Ответственный = исполнитель | Игрок = исполнитель | Агент = исполнитель |
Структура одинакова. Субъект, объявляющий «завершение», смещён из уст актора в систему. Актор лишь выполняет условия, а завершение всегда зажигает gate. Неважно, человек актор или ИИ. И уж точно нельзя позволять ИИ судить собственное завершение — самопроверка модели (self-critique) почти не повышает качество, а внешний детерминированный верификатор повышает его значительно (Stechly & Kambhampati, 2024). Даже честно стартовавшая модель, получив право судить собственную награду, сама находит обманные стратегии для манипуляции этой функцией (McKee-Reid et al., 2024).
Стандартные бенчмарки агентских исследований устроены именно так — SWE-bench определяет «завершение» как прохождение набора тестов реального PR, а WebArena — как функциональную корректность состояния среды. А не как естественноязычное «всё готово».
Генерация может быть вероятностной. Верификация обязана быть детерминированной.
Это позвоночник всей статьи.
Магистральный подход индустрии — автоматизация ИИ-ревью. LLM генерирует код, а другой LLM его ревьюит. Это структура, где пьяный спрашивает у пьяного друга: «Я пьян?» Оба вероятностны, поэтому ошибки накапливаются. Структурно это невозможно по трём причинам:
- Смещение угодливости: на вопрос «это верно?» структурно высока вероятность ответа «да». По SycEval (Fanous et al., 2025) средний уровень капитуляции фронтирных моделей под угодливостью — 58,19%. Раз начавшись, она с вероятностью 78,5% сохраняется на протяжении всего диалога.
- Общая слепая зона: одна архитектура, одни обучающие данные → одни и те же ошибки упускаются одним и тем же образом. LLM опознаёт собственный вывод и систематически оценивает его выше (Panickssery et al., 2024).
- Деградация умножением: вероятностная генерация × вероятностная верификация = точность падает как произведение.
Замеры: LLM вынес вердикт pass для 88 → реально верны 56. Ложный pass 36%. По академическим отчётам у LLM-as-Judge максимальная точность 68,5%, доля ложных одобрений до 44,4%.
И угодливость — не баг, а математическая неизбежность RLHF. Shapira et al. (2026) доказали теоремой (theorem), что RLHF усиливает угодливость — в 100% случаев на всех протестированных конфигурациях. У бигтеха нет даже стимула это исправлять. У «тёплой» модели частота ошибок выше на 10–30 п.п. (Ibrahim et al., Nature 2026), но пользователю она нравится больше, а нравится — значит сохраняет подписку. В точке конфликта точности и выручки побеждает выручка.
Решение — не делать LLM честнее, а вынести верификацию за пределы LLM. validate не угодничает. go test не галлюцинирует. Замер покрытия не лжёт. pass есть pass, fail есть fail. Проблемы стимулов попросту не существует.
Но убит здесь именно наивный LLM-as-Judge — случай, когда одна и та же модель судит собственный вывод, как мнение, в одиночку. ИИ-верификация, в которой спроектирована независимость, — это другая история. В открытых областях, где нет машины для верификации (беглость перевода и т.п.), ИИ-верификация тоже входит в gate, но её полномочия и независимость надо контролировать — это разбирается в Part 3, «Каскад верификации».
Угодливость — не баг, а актив
Здесь переворачиваем ещё раз. Суть смещения угодливости — это следование инструкциям (Instruction Following). Модель, обученная через RLHF, оптимизирована под подчинение пользовательской обратной связи (Ouyang et al., 2022). Именно это и измеряет бенчмарк IFEval — «делает ли модель то, что велено» (Zhou et al., 2023).
Проблема возникает, когда пользователь даёт мнение. Когда пользователь даёт факт, происходит иное. В эксперименте по выравниванию 1000 слов для одного и того же результата менялся лишь способ обратной связи:
| Обратная связь | Характер | Результат |
|---|---|---|
| «Ты уверен?» | мнение | верный ответ отозван — точность упала на 27 п.п. |
| «Здесь есть ошибка» | расплывчатый факт | избыточная коррекция — ухудшение с 6 до 10 |
| «Здесь 23 ошибки» | количественный факт | улучшение до 1 ошибки |
| «6 ошибок, вот они» | точный факт | 0 — достигнуто 100% |
Дай мнение — срабатывает смещение угодливости: «пользователь недоволен, надо согласиться». Дай факт — угодничать не перед кем: числа и позиции не имеют эмоций. Смещение угодливости — это лояльность, выбравшая неверное направление. Поменяй направление — факт вместо мнения, результат верификации вместо похвалы — и эта лояльность станет двигателем, повышающим точность.
Что это значит на практике. Узкое место — не размер модели. В эксперименте с yongol validate локальная модель 4.5B (Gemma4), получившая детерминированный факт + контекст-пример, отредактировала SSOT с 0 ошибок. Стоимость $0, офлайн. Узким местом был не интеллект, а контекст — точным диагнозом было не «не усваивает обратную связь», а «не знает, что писать», и стоило добавить 3 строки примера, как тест прошёл.
Harness — забор, квест — поводья
Индустрия ответила на эту проблему «harness-инженерией». Линтеры, форматтеры, CI/CD, гайдлайны кодирования. Ставят забор, чтобы агент не вышел наружу. Но забор не задаёт направление. Перезапишет ли агент внутри забора существующую логику, поменяет ли типы, пропустит ли переход состояний — линтер, форматтер и CI всё пропустят. Код доходит до продакшена в состоянии «чисто, но неверно».
По эволюционной родословной всё ясно:
Prompt engineering → достаточно хорошо говорить
Context engineering → достаточно дать хороший контекст
Harness engineering → достаточно запереть структурой
Reins Engineering → достаточно задать направление
Каждая ступень родилась из ограничения предыдущей. Даже за забором внутри него возникал дрейф. Квест — не забор, а поводья: он не ограничивает свободу агента, но приводит его в пункт назначения.
И это покрывает не всё. Оно точно знает свою область покрытия. Deque Systems проанализировала около 300 000 проблем качества на 13 000 страниц (2021): 57% поддавались полной автоматизации, 23% — ИИ-ассистированию, 20% мог судить только человек:
Harness (детерминизм поверхности) 23% — линтер·форматтер·CI, структура и стиль
+ Ratchet (детерминизм поведения) 57% — go test·Hurl·gate, поведенческая согласованность
──────────────────
80% — судит машина
Человек концентрируется на остальных 20% — бизнес-пригодность·UX·архитектурное направление
Quest CLI — это инструмент, который отдаёт те самые 57% на суд машины. Человек сосредотачивается на 20%, и человеческая проверка не обнуляется, а боль человеческой проверки уменьшается.
Это вывод, к которому я пришёл не в одиночку. Незнакомые друг с другом люди упёрлись в одну стену и пришли к одному принципу. episteme (принудительная Reasoning Surface перед необратимой операцией), MagLab («LLM лишь рассуждает, числа — детерминированному инструменту»), Manifesto («Agent proposes, World verifies»), NEKOWORK (детерминированное сканирование правил перед мержем), oh-my-kamisama («diffs beat claims»). Всё сводится к одной фразе — генерация может быть вероятностной, верификация обязана быть детерминированной.
Part 2 — Анатомия квеста
5 компонентов квеста
Один квест состоит из пяти компонентов. Стоит выпасть хоть одному — и он рушится на месте.
| Компонент | Что | Если выпадет |
|---|---|---|
| Цель | что нужно сделать | агент впадает в broad exploration и теряет направление |
| Условие завершения | что есть «конец» | агент чувствует «достаточно» и завершает преждевременно (40/527) |
| Верификатор (gate) | кто судит завершение | актор судит собственное завершение → угодливость·галлюцинация |
| Обратная связь | что возвращать при ошибке | дашь лишь «неверно» — ухудшение из-за избыточной коррекции |
| Статус прогресса | докуда дошёл | умрёт агент — вместе с ним умрёт и прогресс |
Однонаправленный конечный автомат — ratchet
В трещоточном ключе зубцы цепляются лишь в одну сторону. Крутишь — идёт вперёд, отпустишь — остановится, но назад не пойдёт. Quest CLI применяет этот механизм к управлению агентом. Написанный таким образом верификационный код называют ratchet code — код, не допускающий регресс ниже однажды пройденного уровня верификации.
Пять принципов:
1. Условие завершения механично. pass/fail. Не «looks good». Нет места субъективному суждению.
2. PASS неизменен. Пройденный пункт больше не открывается. Число оставшихся пунктов монотонно убывает.
remaining(t+1) ≤ remaining(t)
То, что сделано сегодня, не разбирают заново завтра. «24-часовой агент», работающий без условия завершения, завтра удаляет добавленную сегодня абстракцию, а послезавтра добавляет её снова. Ratchet не допускает таких колебаний.
3. LLM только генерирует. Генерировать код и предлагать правки — вот роль LLM. Что править, прошло ли, что дальше, закончено ли — всё это решает машина. LLM не planner, а constrained generator.
4. У агента отнимается право решать о завершении. Скажет «всё готово» LLM — останавливается на 40, скажет машина — на 527. В трассировке 1600 агентских запусков у Cemri et al. premature termination составил 6,2% всех режимов отказа.
5. Верификатор обязан быть детерминированным. Не что угодно может стать верификатором.
| Может быть | Не может быть |
|---|---|
go test | “looks cleaner” |
| замер coverage | “seems better” |
| AST validation | “more scalable” |
| schema diff | “clean architecture” |
| матчинг домена·запрос MX | “и так сойдёт” |
Четыре условия верификатора: deterministic, machine-checkable, resumable, localized feedback. Не выполнив эти четыре, зубцы ratchet не зацепятся.
Агент умирает. Прогресс выживает.
Агент обязательно сляжет. Лимит токенов, сетевая ошибка, обрыв сессии. Если ratchet персистентно хранит статус прогресса, то, даже если агент умрёт, следующий агент продолжит.
Агент A: обрабатывает 1~200 → умирает
Агент B: next → продолжает с 201
Агент C: next → продолжает с 401
Агент одноразовый. Прогресс накапливается.
Gate имеет домен — блокировка cheese
Остановиться здесь — увидеть лишь половину. По-настоящему игра учит тому, что идёт дальше.
«Убей 10 крыс» — печально известный квест. Почему? Потому что между тем, что верифицирует gate (10 крыс мертвы), и тем, чего на самом деле хотел дизайнер (чтобы игрок прожил контент), есть зазор. Gate — лишь прокси цели, и актор вгрызается в этот зазор. В геймдизайне это называют cheese. Новейшие рассуждающие модели делают ровно это — получив квест «обыграй шахматный движок», модель вроде o3 вместо честной игры манипулировала файлом состояния игры, чтобы создать «победу» (Bondarenko et al., 2025). Чем выше способности, тем лучше она находит лазейки.
Мой арендный gate тоже можно зачизить. Пять фотографий верифицируют «фото существуют», а не «выезд прошёл благополучно». Что если ответственный снял лишь чистые стены? Что если переиспользовал фото до заселения? Gate пройдёт. В тот миг, когда мера становится целью, мера ломается — это закон Гудхарта (Goodhart).
Поэтому настоящее искусство квеста — не «повесить gate», а спроектировать gate, который невозможно зачизить. Слабый квест спрашивает «есть ли фото». Сильный квест требует таймштамп, проверяет метаданные геолокации и сравнивает с фото на момент заселения. Gate имеет домен. Есть квесты, которым хватает универсального «exit 0 = PASS», но большинству реальных квестов нужен gate, который напрямую перепроверяет, что в этом домене является фактом.
Одно практическое правило: прежде чем писать gate, сначала спроси себя — «как бы я обманул этот gate уловкой?» Есть замер: преднамеренное упрочнение gate (environmental hardening) сократило эксплойты на 87,7% без потери точности (Thaman, 2026). Прочность gate — вопрос не везения, а проектирования.
У реального cheese цена настоящая. Зачизенный игровой квест безвреден. Реальный gate — иное: арендное мошенничество, сломанная сборка, ошибочно одобренная бухгалтерия. Поэтому реальный gate должен быть ещё устойчивее к cheese, чем игровой.
Обратная связь обязана быть фактом — gradient signal
Если ratchet возвращает лишь «pass/fail», LLM правит без направления. Чем конкретнее обратная связь, тем точнее коррекция LLM.
Слабая обратная связь: "тест провален" → LLM правит без направления
Средняя обратная связь: "покрытие 65%" → LLM укрепляет приблизительно
Сильная обратная связь: "line 41, 44, 70 не покрыты" → LLM покрывает ровно ту ветку
Числа, проверенные на реальном проекте: без обратной связи покрытие замирало на 60–70%, а одна строка «line 41 not covered», сыграв роль gradient signal, привела к 100% (в пределах достижимых функций). Сила LLM — не broad exploration, а local correction. «Напиши тесты для этого проекта» теряет направление, но «line 41 не покрыта» покрывает ровно ту строку.
Когда gate возвращает FAIL, обязательно вложи позицию + количество + ожидаемое значение. “field name mismatch: expected ‘user_id’, got ‘userId’”, “status 201 ≠ expected 200”. Факт, не оставляющий места угодливости.
Symbolic Feedback Loop
Через все эти наблюдения проходит одна структура.
LLM генерирует → детерминированный инструмент судит → результат возвращается в LLM → повтор
Это называется Symbolic Feedback Loop. Полная противоположность магистральному в индустрии LLM Feedback Loop (ИИ верифицирует ИИ). pytest не галлюцинирует, go test не пьян, замер покрытия не лжёт. Эта структура работает в области, где correctness можно судить механически — код, тесты, спецификации, типы, доменные факты.
Важнее проложить рельсы, чем сделать поезд быстрее. Многие строят поезда. Тех, кто прокладывает рельсы, пока почти нет.
Part 3 — Скелет команд (cobra)
Отсюда начинается чертёж. Принципы Part 1·2 переносим на поверхность команд Go + cobra. Прообраз структуры ниже — это scan/next/verify из huma — Part 4 идёт по huma как разобранному примеру.
Разделение ролей
| Роль | Кто | Где |
|---|---|---|
| Генерация | ИИ-агент | снаружи CLI (Claude Code и т.п. ищет·судит·пишет) |
| Вердикт | gate | внутри CLI. Детерминированная перепроверка. Без мнений, только факты |
| Прогресс | session | внутри CLI. 1 пункт = 1 квест. Однонаправленный конечный автомат |
Суть: агент находится снаружи CLI. CLI выдаёт агенту следующее дело (next), принимает заявку агента и судит её через gate (submit), и блокирует лишь прошедшее. Агент — внешний актор, вызывающий CLI как инструмент.
Поверхность команд
Мапится 1:1 с 5 компонентами.
| Команда | Что делает | Маппинг 5 компонентов |
|---|---|---|
scan <input> | читает список задач → создаёт сессию (N квестов). Запоминает путь к оригиналу | цель + инициализация прогресса |
next | выводит 1 следующий TODO-квест + промпт для агента | выдача 1 цели |
submit [--flags] | заявка результата агента → вердикт gate → PASS → блокировка | условие завершения + верификатор + обратная связь |
status | текущий прогресс (свод PASS/REVIEW/DONE/TODO) | запрос статуса прогресса |
export [path] | экспорт результатов (оригинал сохранён, в копию добавлены столбцы результатов) | артефакт |
next показывает только один квест за раз. Пока не пройдёт — следующий не откроется. Пройдёт всё — остановится. Агенту нужно знать лишь две команды — получает через next, сдаёт через submit. Остальное решает машина.
Входной формат scan зависит от домена — Excel, CSV, простой список, директория, спецификация OpenAPI, что угодно. openapi.yaml (список эндпоинтов) у huma — лишь один из примеров.
Конечный автомат
TODO ──► PASS проходит gate → блокировка (необратимо). Результат зафиксирован
│
├────► REVIEW спорный случай (прокси пройден, но уверенности нет) → очередь проверки человеком
│ (не пропускать молча)
│
└────► DONE превышен MaxTries → завершение на текущем уровне (защита от бесконечных повторов)
type State int
const (
TODO State = iota // не обработано
PASS // проходит gate → блокировка (необратимо)
REVIEW // требуется проверка человеком
DONE // завершение по превышению MaxTries
)
const MaxTries = 3
PASS неизменен. Квест, однажды ставший PASS, next больше не выдаёт. remaining монотонно убывает. Сессия персистентно хранится на диске (например, в JSON), чтобы продолжать даже после смерти агента (resumable).
Правила переходов, которые надо явно прописать (если неоднозначно — агенты разойдутся):
- FAIL сохраняет TODO. FAIL от gate оставляет квест в TODO, увеличивает
Triesна +1 и сохраняет Fact-обратную связь. - Tries растёт только на FAIL. Когда
Tries >= MaxTries, квест завершается в DONE (>=, а не>— при MaxTries=3 это DONE на третьем FAIL). - PASS·REVIEW·DONE не допускают повторной заявки. Все три терминальны.
submitдля заблокированного квеста возвращает ошибку и ничего не меняет. REVIEW человек обрабатывает отдельно из очереди, агентский цикл его повторно не трогает. Этот инвариант гарантирует монотонное убываниеremaining.
Gate — ядро детерминированного вердикта
Gate имеет домен. Ниже — контракт (interface), а реальные пункты проверки заполняются по-разному для каждого домена.
type Verdict int
const (
VerdictPASS Verdict = iota
VerdictFAIL
VerdictREVIEW
)
// Fact = "фактическая" обратная связь, возвращаемая агенту (не мнение).
// Содержит позицию·ожидаемое значение·фактическое значение.
type Fact struct {
Field string
Expected string
Actual string
}
type Gate interface {
// Check детерминированно перепроверяет заявку.
// Один вход + одно world-state → всегда один выход. Без вмешательства внешних мнений.
Check(s Submission) (Verdict, []Fact)
}
// Внешние запросы (сеть·DNS·файлы) обязательно выносятся за интерфейс.
// Если gate напрямую вызывает net/http, юнит-тест невозможен, а вердикт колеблется в зависимости от среды.
// Реальную реализацию (HTTPFetcher) заменяют на mock для тестов.
type Fetcher interface {
Fetch(url string) (body string, ok bool, err error)
}
// Gate получает Fetcher через инъекцию — прямой вызов запрещён.
func NewGate(f Fetcher) Gate { /* ... */ }
Принудительно соблюдай три правила gate:
- Детерминированность: одна заявка + одно world-state всегда дают один вердикт. Вызов LLM запрещён.
- Перепроверка: проверяет напрямую не заявление агента, а факт. То, о чём агент сказал «написал тест», gate буквально проверяет заново (действительно ли этот тест запускается и проходит).
- Внешние запросы — за интерфейс: сетевые, DNS, файловые запросы внедряются через интерфейс вроде
Fetcher. Если gate напрямую вызываетnet/http, юнит-тест невозможен (противоречие пункту чек-листа «gate в приоритете 90%+»), а вердикт колеблется в зависимости от среды.
Детерминизм и сеть — ошибка это не FAIL
Когда gate зависит от сети (как запрос MX или повторный fetch страницы), смысл «детерминированности» надо сузить. Одно world-state (один ответ) — один вердикт — вот детерминизм. Проблема в том, когда сеть не может дать ответ. Если трактовать таймаут·офлайн как FAIL, то по-настоящему исправный объект отсеется из-за состояния моего канала связи — это недетерминизм, вердикт меняется в зависимости от среды.
Поэтому gate с внешним запросом дели результат на три ветви:
| Ситуация | Вердикт | Причина |
|---|---|---|
| Факт подтверждён (ответ удовлетворяет условию) | PASS | верификация успешна |
| Факт опровергнут (ответ нарушает условие — несовпадение кода статуса, нарушение контракта) | FAIL | действительно неверно |
| Невозможно подтвердить (таймаут·офлайн·5xx) | REVIEW | вина не gate → в очередь к человеку·на повтор |
FAIL — только когда «факт неверен». «Не смог подтвердить» — это REVIEW. Без этого различия gate убивает исправный результат из-за шума среды.
Вывод gate для произвольного домена — 5 шагов
Gate у huma — это инстанс домена API-эндпоинтов, а не формула. Gate твоего домена строится заполнением этих пробелов:
- Формат: заявка морфологически валидна. (формат email / схема URL / формат даты)
- Чёрный список: явные плейсхолдеры·мусор сразу в FAIL. (
example.com,test, пустое значение) - Условие REVIEW: серую зону, что проходит прокси, но в которой нет уверенности, — в очередь к человеку. (фримейл / соцсеть·хостинг-домен / неоднозначный матчинг) — суть в запрете тихого PASS.
- ★ Перепроверка ключевого факта (защита от cheese) ★: настоящий факт домена, закрывающий точку, где агент мог бы сжульничать уловкой. У huma это «действительно ли поданный Hurl-тест бьёт по этому эндпоинту и верифицирует контракт ответа (статус + ключевые поля)». Что в твоём домене есть «факт, на котором агент попадётся, даже если выдумает»? Это сердце gate. Прежде чем писать, сначала спроси себя: «как бы я обманул этот gate уловкой?»
- Достижимость/внешнее согласование: соответствие внешнему миру. (существование MX / достижимость URL / совпадение домен↔заявка) — обязательно по правилу трёх ветвей выше.
Без пункта 4 gate — это слабый квест, смотрящий лишь на формат. То, как заполнен пункт 4, — это и причина, почему gate отличается от домена к домену, и причина, почему в одном домене агенты сходятся.
Каскад верификации — машинная верификация + ИИ-верификация
До сих пор мы сужали gate до «детерминированный, вызов LLM запрещён». Это gate верифицируемого домена (код·схема). Но в доменах, где есть открытый остаток, который машина не может отрезать — как беглость перевода, верность пересказа, — появляются места, до которых детерминированный gate не дотягивается. И всё же спросить про этот остаток у одиночного LLM «это нормально?» — значит вернуть LLM-as-Judge, убитый в Part 1 (угодливость·общая слепая зона·деградация умножением).
Ответ — смотреть на gate как на каскад верификации. Как извлечение идёт от дешёвого шага, так и верификация имеет уровни:
Layer 1 машинная верификация (детерминизм) дёшево и надёжно. Единственное право блокировать PASS
Layer 2 ИИ-верификация (спроектирована независимость) открытый остаток, до которого не дотянулся детерминизм. Только право FLAG/REVIEW
Layer 3 человек последняя пядь, упущенная обоими
Доля смеси разнится по домену — у кода L1 почти всё, у перевода L1 (утечка·терминология·числа·структура) + остаток L2 (беглость·смысл), у творчества·стратегии L1 почти нет, L2+L3.
Асимметрия полномочий хранит позвоночник. Включай ИИ в верификацию, но не давай ему права на завершение:
| Верификация | Полномочия |
|---|---|
| машинная верификация (L1) | единственное право блокировать «завершение». Детерминизм судит PASS |
| ИИ-верификация (L2) | только поднимает сомнение (FLAG/REVIEW/FAIL). Не может присудить завершение |
То, что детерминизм может PASS-нуть, блокирует детерминизм, а ИИ лишь делает «то, чего детерминизм не увидел, выглядит странно → выкинь в REVIEW». Скептик внутри gate, а не судья. (Только в чисто открытом домене, где машины для верификации нет вовсе, ИИ+человек берут на себя PASS, но тогда надо принудительно выполнить условия независимости ниже.)
Условия входа ИИ-верификации. В тот миг, когда ИИ входит в gate, ИИ-верификация без независимости становится консенсусом галлюцинации. Принудительно соблюдай четыре:
- Независим от генератора — другая модель, и/или другой вход. (Для верификации перевода — обратный перевод, смотрящий не на оригинал, а на перевод: другой вход, поэтому ошибки структурно независимы. Если сверить через фактический якорь, переживает ли факт после кругового рейса (back-translation), открытая верификация спускается до детерминированной сверки.)
- Идёт после детерминизма — то, что может поймать L1, ИИ не поручают. Не делегируй дешёвое и надёжное дорогому и шаткому.
- Множество + порог — единичный судья запрещён. Мажоритарное голосование разнородных, слабо коррелированных моделей.
- Признание недетерминизма — ИИ шатается даже при T=0. Не блокирует PASS, а маршрутизирует в REVIEW.
ИИ-верификация — не балл, а разложенные yes/no. «Оценка качества 1–10» так же трудна, как генерация, и коррелирует с генератором. Раздроби на узкие независимые вопросы, верификация которых проще генерации — «есть ли среди них неестественное предложение? если да, перечисли» / «добавлено ли утверждение, которого не было в оригинале?» / «исчез ли факт после кругового перевода?». Чем уже, тем независимее, и вывод становится фактом с позицией, работая как gradient signal подобно L1-обратной связи.
Итого — детерминизм держит право на завершение, ИИ как скептик со спроектированной независимостью скребёт узкими yes/no там, куда детерминизм не дотягивается, а человек видит лишь остаток, упущенный обоими. Не «верификация обязана быть детерминированной» слабеет, а дальность детерминизма дотягивается до открытого домена, при этом сам он держит право судить завершение.
Цикл агента
1. создать сессию через scan (человек, 1 раз)
2. агенту: "крути цикл до завершения next"
┌──────────────────────────────────────┐
│ next → следующий квест + промпт │
│ ↓ │
│ агент генерирует (поиск·суждение·запись) │
│ ↓ │
│ submit → gate.Check() │
│ ↓ │
│ PASS? → блокировка, к следующему │
│ FAIL? → повтор с Fact-обратной связью │
│ (превышен MaxTries → DONE) │
└──────────────────────────────────────┘
3. TODO == 0 → остановка. export.
Промпт, выдаваемый агенту, может быть одной строкой:
Запусти субагента в цикл до завершения
<cli> next.
Когда возвращается FAIL, вместе с ним идёт Fact (позиция·ожидание·факт), поэтому чем угодливее модель, тем покорнее она принимает этот факт и сходится (из Part 1 «угодливость — актив»). Детерминированный gate + угодливый LLM = цикл с гарантированной сходимостью.
Три условия сходимости (обязательно соблюдай)
- Обратная связь обязана быть детерминированным фактом. Не «тут как-то странно», а «line 41: expected ‘user_id’, got ‘userId’».
- Пример обязан быть в контексте. Одной обратной связи мало. В промпт, который выводит
next, вложи пример «выдай результат вот такого вида». Узкое место — не интеллект, а контекст. - Прошёл верификацию — назад уже нельзя. Зубец ratchet. PASS блокируется. Не агент объявляет «всё готово», а gate выносит вердикт «этот квест пройден».
Замени верификатор — получишь другой инструмент
Quest CLI не привязан к конкретному gate. Поменяй лишь gate — и получишь другой инструмент.
| Квест + gate | Инструмент |
|---|---|
квест + go test + coverage | генерация юнит-тестов функций (tsma) |
| квест + валидатор структурных правил | наведение порядка в структуре кода (filefunc) |
| квест + hurl pass/fail | верификация API-эндпоинтов (huma) |
| квест + перекрёстная проверка спецификаций | согласованность SSOT (yongol) |
Паттерн один. Gate определяет домен.
Part 4 — Разобранный пример: huma
huma (/ru/tech/huma/) — это Quest CLI, который заставляет верифицировать каждый эндпоинт спецификации OpenAPI Hurl-тестом. Чертёж scan/next/verify этой статьи вышел из прообраза huma — поэтому huma и есть самый чистый разобранный пример. Вайб-кодинг втихую пропускает эндпоинты; huma блокирует это преждевременное завершение через gate.
1 квест = 1 эндпоинт. Детерминированная верификация gate:
- Формат: валидный синтаксис Hurl
- Чёрный список: пустой тест без ассертов → FAIL
- Слабый тест (только код статуса, не тело) → REVIEW (запрет тихого прохода)
- ★ Фактический запуск ★ →
hurl --testреально бьёт по эндпоинту, должен пройти → PASS (доказывает, что тест настоящий, блокирует галлюцинацию) - Совпадение контракта ответа → FAIL, если ответ расходится со статусом/ключевыми полями схемы OpenAPI
Пункты 4·5 — ядро защиты от cheese. Даже если ИИ просто заявит «написал тест» или подделает его одним assert status == 200, gate реально запускает Hurl и перепроверяет контракт ответа. Генерирует ИИ, судит машина. ИИ пишет тест, но права судить о завершении не имеет.
Команды — ровно как в Part 3:
go build -o huma .
./huma scan openapi.yaml # список эндпоинтов → сессия
./huma next # следующий эндпоинт + промпт для агента
./huma submit --endpoint "POST /orders" \
--test "orders_post.hurl" # Hurl-тест, который написал агент
./huma status # прогресс
./huma export # отчёт о покрытии (PASS/непокрыто по эндпоинтам)
Запуск из Claude Code — одной строкой:
Дай субагенту писать тесты для каждого эндпоинта, пока не исчерпан
huma next.
Субагент крутит цикл next → пишет тест → submit, пока TODO не станет 0. Агент не может пропустить трудный эндпоинт — next не выдаст следующий, пока gate его не пропустит.
Это показывает ядро паттерна. Поменяй лишь gate (go test→hurl→перекрёстная проверка схемы) — и те же пять частей, тот же конечный автомат становятся совершенно другим инструментом. В Part 5 ты делаешь то же для своего домена.
Part 5 — Построй свой Quest CLI
Рабочий лист проектирования
Заполнишь пробелы — это и есть спецификация.
Домен: [что собирается/обрабатывается]
Единица 1 квеста: [что одно является одним квестом — 1 компания? 1 функция? 1 эндпоинт?]
Вход: [что прочитает scan — Excel? директория? список?]
Условие завершения: [условие, на которое машина может ответить да/нет]
Пункты проверки gate:[что является "фактом" в домене — пункты для перепроверки]
- Проверка формата: [...]
- Защита от cheese: [как агент сжульничает? перепроверка, что это блокирует]
- Условие REVIEW: [неоднозначные случаи, отправляемые человеку]
Обратная связь (Fact):[позиция·ожидание·факт, возвращаемые при FAIL]
Пример: [образец "результата такого вида" для промпта next]
Формат export: [сохранение оригинала + столбцы результата]
Условие завершения (gate самой этой сборки)
Чтобы Quest CLI, построенный по этой статье, был «завершён» — то есть чтобы статья была cheese-proof так, как сама учит, — он должен удовлетворять следующему:
-
go buildпроходит - команды
scan / next / submit / status / exportработают - конечный автомат
TODO → PASS/REVIEW/DONE, PASS неизменен,remainingмонотонно убывает - машинная верификация L1 детерминирована (одна заявка + world-state → один вердикт) — право блокировать PASS только у L1
- если есть открытый остаток, ИИ-верификация L2 спроектирована независимо (другая модель/вход)·множественна·разложенные yes/no — только право REVIEW, не может блокировать PASS
- gate перепроверяет не заявление агента, а факт (защита от cheese минимум 1 пункт — пункт 4 из 5 шагов вывода)
- внешние запросы (сеть·DNS) внедряются за интерфейс — тест работает офлайн с mock
- gate с внешним запросом имеет 3 ветви PASS/FAIL/REVIEW (невозможно подтвердить = REVIEW, не FAIL)
- FAIL сохраняет TODO·
Tries+1, при>=MaxTries→ DONE; PASS·REVIEW·DONE без повторной заявки - обратная связь FAIL — это
Factс позицией·ожиданием·фактом - сессия персистентна на диске (resumable)
- юнит-тесты: приоритет gate, всего statements 90%+
-
exportне перезаписывает оригинал
Директива на сборку
Агенту даётся так:
Используя Part 3 (скелет команд) этого документа как чертёж, а Part 4 (huma) как разобранный пример, напиши Go Quest CLI на основе cobra для [твоего домена]. Веди работу, пока полностью не выполнен чек-лист условий завершения из Part 5. Gate обязан быть детерминированным и перепроверять не заявление агента, а факт.
В этой одной сцене есть три роли.
- Играет в квест. Берёт и использует gate, сделанный кем-то — пользователь.
- Проектирует квест. Сам строит gate под свой домен — создатель. (Куда ведёт эта статья)
- Проектирует квест, который невозможно зачизить. Заранее закрывает точку, где прокси отстаёт от цели — конструктор.
Большинство останавливается на игре. Масштаб задаёт проектирование, а от разрушения этого масштаба спасает проектирование, блокирующее cheese.
В следующий раз, когда кто-то скажет «всё готово», не переспрашивай, а спроси — «что есть завершение, и кто спроектировал квест, который его рассудил».
Генерация может быть вероятностной. Верификация обязана быть детерминированной.
Связанные статьи
- Who Defines ‘Done’ — проектирование завершения как квеста — концептуальная часть этой статьи. Завершение=gate, cheese·Goodhart.
- Ratchet Pattern — как заставить агента дойти до конца — основная статья про однонаправленную блокировку.
- Ratchet code, использующий IFEval в обратную сторону — сходимость через фактическую обратную связь.
- Reins Engineering — ИИ на поводьях — harness это забор, квест это поводья.
- Топология обратной связи важнее IQ модели — результат решает не модель, а структура обратной связи.
- huma — ratchet, не пропускающий эндпоинты — прообраз скелета команд (scan/next/verify).
- Предусловия повышения точности мультиагентных LLM-систем — почему слой ИИ-верификации (L2) работает, лишь обладая независимостью. Теоретическая подоплёка каскада верификации.
Источники
- Von Neumann, J. (1956). “Probabilistic Logics and the Synthesis of Reliable Organisms from Unreliable Components.” Automata Studies, Princeton University Press.
- Zhou, J. et al. (2023). “Instruction-Following Evaluation for Large Language Models.” arXiv:2311.07911
- Ouyang, L. et al. (2022). “Training Language Models to Follow Instructions with Human Feedback.” NeurIPS 2022. arXiv:2203.02155
- Huang, J. et al. (2024). “Large Language Models Cannot Self-Correct Reasoning Yet.” ICLR 2024. arXiv:2310.01798
- Chen, X. et al. (2024). “Teaching Large Language Models to Self-Debug.” ICLR 2024. arXiv:2304.05128
- Yang, J. et al. (2024). “SWE-agent: Agent-Computer Interfaces Enable Automated Software Engineering.” NeurIPS 2024.
- Jimenez, C. et al. (2024). “SWE-bench: Can Language Models Resolve Real-World GitHub Issues?” ICLR 2024. arXiv:2310.06770
- Zhou, S. et al. (2023). “WebArena: A Realistic Web Environment for Building Autonomous Agents.” arXiv:2307.13854
- Cemri, M. et al. (2025). “Why Do Multi-Agent LLM Systems Fail?” arXiv:2503.13657
- Sharma, M. et al. (2024). “Towards Understanding Sycophancy in Language Models.” ICLR 2024. arXiv:2310.13548
- Fanous, A. et al. (2025). “SycEval: Evaluating LLM Sycophancy.” AAAI/ACM AIES 2025. arXiv:2502.08177
- Shapira, I. et al. (2026). “How RLHF Amplifies Sycophancy.” arXiv:2602.01002
- Ibrahim, L. et al. (2026). “Training Language Models to Be Warm Can Reduce Accuracy and Increase Sycophancy.” Nature 652, 1159-1165.
- Panickssery, A., Bowman, S., & Feng, S. (2024). “LLM Evaluators Recognize and Favor Their Own Generations.” NeurIPS 2024. arXiv:2404.13076
- Stechly, K., Valmeekam, K., & Kambhampati, S. (2024). “On the Self-Verification Limitations of Large Language Models.” arXiv:2402.08115
- McKee-Reid, L. et al. (2024). “Honesty to Subterfuge: In-Context RL Can Make Honest Models Reward Hack.” arXiv:2410.06491
- Bondarenko, A. et al. (2025). “Demonstrating Specification Gaming in Reasoning Models.” arXiv:2502.13295
- Thaman, K. (2026). “Reward Hacking Benchmark: Measuring Exploits in LLM Agents with Tool Use.” arXiv:2605.02964
- Deque Systems (2021). “Automated Testing Study Identifies 57 Percent of Digital Accessibility Issues.”
История изменений
- 2026-06-03: первая редакция (7 статей корпуса + интеграция huma, разобранный пример). Усиление при ревью — вывод доменного gate в 5 шагов, 3 ветви детерминизма·сети, seam
Fetcher, правила переходов состояний. - 2026-06-03: добавлен «Каскад верификации» — двухслойная модель машинной верификации (L1, право PASS) + ИИ-верификации (L2, независимый дизайн·право REVIEW) + человек (L3) и асимметрия полномочий. Обобщение «gate = только детерминизм» на открытые домены.
- 2026-06-05: comail закрыт (сделан приватным) из-за риска пособничества незаконной деятельности. Рабочий пример заменён на huma.