 Image generated by Google Gemini
Image generated by Google Gemini
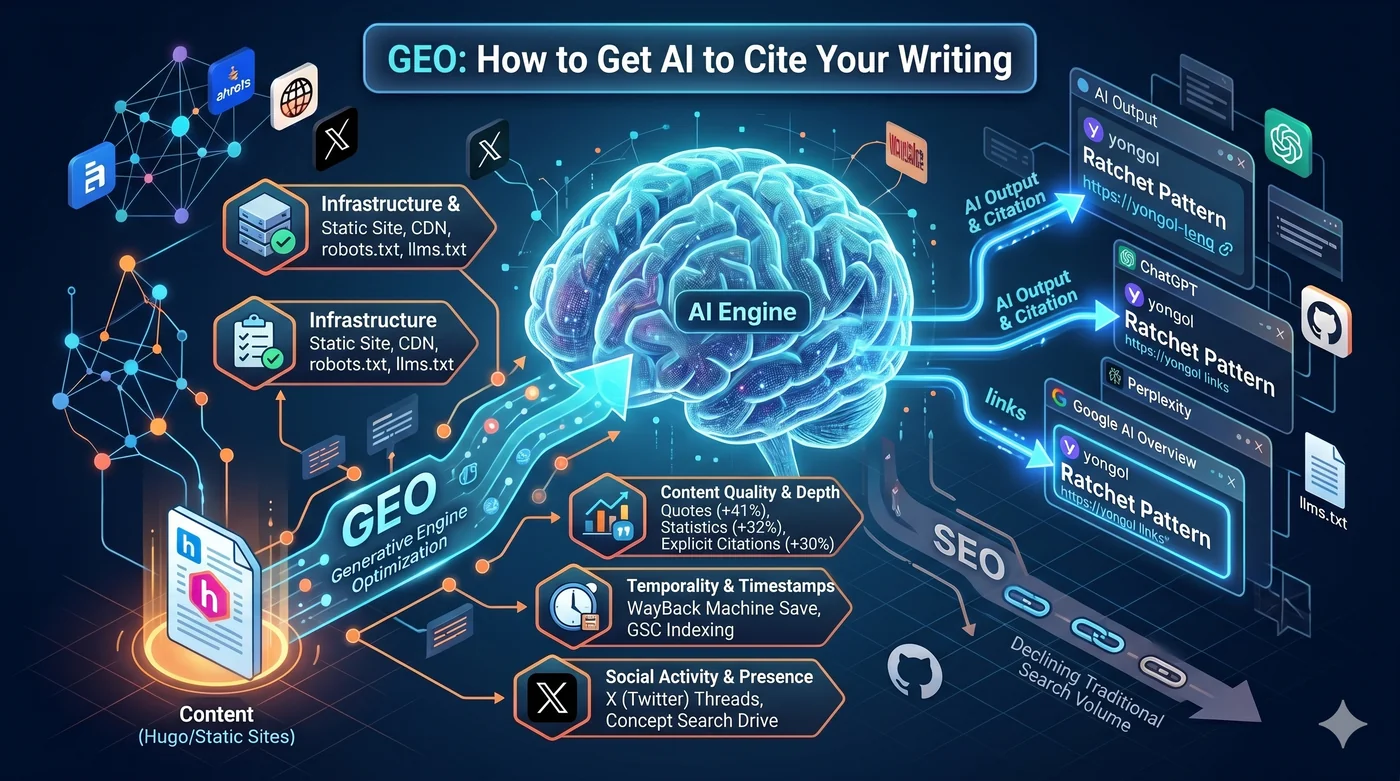
GEO (Generative Engine Optimization) — это стратегия оптимизации контента для цитирования поисковыми системами на базе ИИ. Также известна как AEO (Answer Engine Optimization), AI SEO, оптимизация для LLM-поиска.
Поиск изменился — начало эры AI SEO
Раньше Google выдавал 10 синих ссылок. Теперь ИИ генерирует ответы. ChatGPT, Perplexity, Google AI Overview — пользователи получают ответы, не кликая по ссылкам.
Gartner прогнозирует снижение объёма традиционного поиска на 25% к 2026 году. 31,3% населения США уже используют генеративный ИИ-поиск.
Проблема в следующем: Если ваш контент не цитируется в ответах, сгенерированных ИИ, его как будто не существует.
Generative Engine Optimization (GEO) — это правила новой игры.
GEO vs SEO vs AEO — в чём разница
Традиционное SEO — это игра за ранжирование в Google. Ключевые слова, обратные ссылки, мета-теги. GEO — другая игра.
| SEO | GEO | |
|---|---|---|
| Цель | Ранжирование в SERP | Цитирование в ответах ИИ |
| Метрики успеха | Показы, клики, CTR | Доля цитирования, частота упоминания бренда |
| Ключевые сигналы | Обратные ссылки, ключевые слова | Чёткость сущностей, указание источников, кроссплатформенная согласованность |
| Модель трафика | Клик → посещение сайта | Zero-click (потребление без посещения) |
Есть удивительные данные. 83% цитат AI Overview берутся со страниц за пределами топ-10 органики Google. 28,3% наиболее цитируемых ChatGPT страниц имеют нулевую органическую видимость в Google. Традиционное SEO-ранжирование и ИИ-цитирование — это разные игры.
Так что же цитирует ИИ?
1. Инфраструктура: Hugo + CloudFront + robots.txt + llms.txt
Если краулер ИИ не может добраться до вашего контента, цитирования не будет. Первое условие — техническая инфраструктура.
Генератор статических сайтов (Hugo) + S3 + CloudFront
- Статический HTML — самый быстрый и чистый источник для краулеров. SPA требуют рендеринга JavaScript, поэтому ИИ-краулеры часто их пропускают
- CloudFront CDN обеспечивает быстрый отклик из любой точки мира. ИИ-краулеры тоже используют скорость как сигнал
- Мультиязычная сборка Hugo автоматически генерирует теги hreflang. 12 языков = 12 точек входа
Карта сайта
XML-карта сайта — это основа. Но в эпоху GEO нужны ещё две вещи:
llms.txt— Markdown-файл, размещаемый в корне сайта. Если robots.txt говорит «где краулить», llms.txt указывает «какой контент важен». Anthropic, Hugging Face, Perplexity уже внедрили- Schema.org JSON-LD — Схемы Article, Person, SoftwareSourceCode. Как шпаргалка для ИИ-краулера: «о чём эта страница»
Явное разрешение ИИ-краулеров в robots.txt:
По состоянию на 2026 год основные боты ИИ-краулеров делятся на 5 категорий:
| Категория | Описание | Последствия блокировки |
|---|---|---|
| Краулеры обучения | Сбор данных для обучения LLM | Исключение из долгосрочных знаний модели |
| Поисковые индексаторы | Индекс для ИИ-поиска | Исчезновение из результатов ИИ-поиска |
| Пользовательский fetch | Fetch в реальном времени по запросу пользователя | Невозможность ссылки в диалоге |
| Агенты | ИИ просматривает веб от имени пользователя | Исключение из агентских сервисов |
| Сборщики данных | Массовый сбор веб-данных | Исключение из соответствующих датасетов |
Список основных ботов:
| Бот | Владелец | Назначение |
|---|---|---|
| GPTBot | OpenAI | Обучение модели |
| OAI-SearchBot | OpenAI | Индексация поиска ChatGPT |
| ChatGPT-User | OpenAI | Пользовательский fetch в реальном времени |
| ClaudeBot | Anthropic | Обучение модели |
| Claude-SearchBot | Anthropic | Индексация поиска Claude |
| Claude-User | Anthropic | Пользовательский fetch в реальном времени |
| Google-Extended | Обучение Gemini | |
| Applebot-Extended | Apple | Обучение Apple Intelligence |
| Meta-ExternalAgent | Meta | Обучение Llama + Meta AI |
| PerplexityBot | Perplexity | ИИ-поиск |
| bingbot | Microsoft | Bing + Copilot |
| CCBot | Common Crawl | Открытый датасет (используется почти всеми LLM) |
| Bytespider | ByteDance | Обучение Doubao (игнорирует robots.txt, рекомендуется блокировать) |
Суть: Необходимо различать ботов обучения и ботов поиска/fetch. Даже при блокировке ботов обучения, если поисковые боты разрешены, контент всё равно цитируется в ответах ИИ. Блокировка обоих означает исчезновение из мира ИИ.
llms.txt — Если robots.txt говорит «где краулить», llms.txt указывает «какой контент важен». На основе Markdown, размещается в корне сайта. Anthropic, Hugging Face, Perplexity уже внедрили. Убирает шум меню/рекламы/скриптов и предоставляет очищенный контент, подходящий для контекстного окна ИИ.
2. Карта сайта и hreflang: семантическая карта для ИИ
Традиционная карта сайта — это список URL. Карта сайта эпохи GEO — это семантическая карта.
<url>
<loc>https://www.parkjunwoo.com/opinion/reins-engineering/</loc>
<lastmod>2026-05-27</lastmod>
<changefreq>weekly</changefreq>
</url>
Плюс к этому:
- Ссылки hreflang: 12 языковых версий одной статьи связаны друг с другом. ИИ высоко ценит мультиязычный авторитет
- Точность lastmod: 76,4% цитат ИИ приходятся на страницы, обновлённые за последние 30 дней. Контент младше 3 месяцев цитируется в 3 раза чаще. Ложный lastmod даёт обратный эффект
- Структура категорий:
/opinion/,/tech/,/lecture/— осмысленная иерархия даёт ИИ больше контекста, чем плоская структура
Отправка карты сайта в Google Search Console — это основа. Но этого недостаточно.
3. Wayback Machine и Google Search Console: доказательство оригинальности контента
Wayback Machine хранит снимки веба с 1996 года. Для ИИ это временна́я память.
Почему это важно:
- Если вы опубликовали статью, впервые определяющую «Ratchet Pattern» в мае 2026 года, этот снимок сохраняется в Wayback Machine
- Через полгода, даже если кто-то напишет о том же концепте на более крупной платформе, временно́е свидетельство указывает на первоначального автора
- Когда ИИ определяет источник, время первой публикации выступает как косвенный сигнал авторитетности
Действия:
- После публикации новой статьи отправьте запрос на ручное сохранение в Wayback Machine (
web.archive.org/save/) - Запросите индексацию URL в Google Search Console
- Временна́я метка фиксируется в обоих местах
Примечание: по состоянию на 2026 год 241 сайт заблокировал доступ к Wayback Machine (опасения по поводу обхода авторских прав компаниями ИИ). Для личных блогов это скорее возможность — с уходом крупных СМИ из архива относительная доля личного контента растёт.
4. Цитирование источников и тематический авторитет: требования к контенту, которому доверяет LLM
Три лучшие стратегии повышения видимости согласно оригинальной статье GEO (Aggarwal et al., KDD 2024):
| Стратегия | Повышение видимости |
|---|---|
| Добавление цитат (Quotation) | +41% |
| Добавление статистики (Statistics) | +32% |
| Указание источников (Cite Sources) | +30% |
Набивание ключевыми словами в GEO бесполезно или контрпродуктивно. ИИ смотрит на доказательства, а не на ключевые слова.
Почему ссылки на статьи важны:
- ИИ различает «утверждение» и «обоснованное утверждение». «42% времени разработчиков тратится на технический долг» — это утверждение. «42% времени разработчиков тратится на технический долг (Stripe, The Developer Coefficient, 2018)» — это доказательство
- Предложения с доказательствами имеют низкую «стоимость доверия» при цитировании ИИ в своих ответах. Предложения без доказательств ИИ должен верифицировать, поэтому пропускает
- Сайты, цитируемые на 4+ платформах ИИ, появляются в ChatGPT в 2,8 раза чаще
Управление связанными статьями и тегирование:
Теги не для людей. Теги для ИИ.
- Последовательная система тегов: «Reins Engineering», «Ratchet Pattern», «SSOT» — одни и те же теги, повторяющиеся в нескольких статьях, заставляют ИИ распознавать тематический авторитет (topical authority)
- Внутренние ссылки: ссылки на связанные статьи внутри текста помогают ИИ-краулерам выявлять тематические кластеры. Связанные статьи цитируются чаще изолированных
- Перекрёстное цитирование: ссылки между собственными статьями тоже работают. «Основы этого концепта определены в Ratchet Pattern»
5. X, Reddit, Hacker News: социальные стратегии для объёма брендового поиска
Условия использования X/Twitter явно запрещают обучение ИИ третьими сторонами. То есть записи, опубликованные в X, напрямую не попадают в обучающие данные ChatGPT.
Однако социальная активность способствует видимости в ИИ через непрямые пути:
Объём брендового поиска — сильнейший предиктор цитирования LLM (коэффициент корреляции 0,334, выше, чем у обратных ссылок).
Путь выглядит так:
Тред в X → люди ищут «yongol» в Google → объём брендового поиска растёт → ИИ распознаёт «yongol» как сущность, достойную цитирования
Данные parkjunwoo.com за май подтверждают это:
- Поиск «yongol» в Google: 14 показов, 5 кликов, средняя позиция 3,1
- Клоны yongol на GitHub: 316 уникальных пользователей
- Путь входа: t.co (X) 4 человека → GitHub → Блог
Вместо прямого размещения ссылок в X заставить людей искать концепцию более эффективно для GEO.
Сила earned media:
48% всех цитат LLM приходятся на earned media (пресса, обзоры, упоминания третьими сторонами). Собственный контент — лишь 23%. Это значит, что заставить других упоминать вас в 2 раза эффективнее, чем оптимизировать собственные тексты.
Если проект упоминается на Reddit, Hacker News, dev.to → через ИИ-краулинг этих платформ → LLM усваивает сущность.
Чек-лист
Инфраструктура
├── Статический сайт Hugo + S3 + CloudFront
├── Разрешить ИИ-краулеры в robots.txt
├── Создать llms.txt (курирование ключевого контента)
├── Schema.org JSON-LD (Article, Person)
└── XML-карта сайта + hreflang
Контент
├── Указывать источник каждого утверждения (+30% видимости)
├── Встраивать статистику в текст (+32%)
├── Использовать сравнительные таблицы (оптимально для парсинга ИИ)
├── Поддерживать точный lastmod (обновление за 30 дней → доля цитирования 76,4%)
└── Регулярно обновлять статьи старше 3 месяцев (вероятность цитирования ×3)
Связи
├── Последовательная система тегов (тематический авторитет)
├── Внутренние ссылки (тематические кластеры)
├── Ссылки на статьи/внешние источники (снижение стоимости доверия)
└── Новая статья → отправка в Wayback Machine + GSC
Социальная активность
├── Треды в X для стимулирования поиска концепций (объём брендового поиска)
├── Генерация earned media на Reddit/HN
└── Распространение концепций выгоднее для GEO, чем прямое размещение ссылок
Реализация GEO на этом сайте
Стратегии, описанные в этой статье, активно применяются на parkjunwoo.com:
- robots.txt — 25 ИИ-краулеров разрешены явно, Bytespider заблокирован
- llms.txt — Ключевой контент курирован для контекстного окна ИИ
- Коллекция статей по Reins Engineering — Хаб тематического кластера
- Мультиязычная сборка на 12 языков — Автоматическая генерация hreflang, точки входа для каждого языка
- Все статьи со ссылками на научные источники — Встроенная статистика + академические цитаты для плотности фактов
- Отправка в Wayback Machine + GSC сразу после публикации — Временно́е доказательство оригинальности
Связанные статьи
- Google, Optimizing your website for generative AI features on Google Search (2026) — Официальное руководство Google по оптимизации для ИИ-поиска
- Cyrus Shepard, AI Citation Ranking Factors Analysis — Мета-анализ 54 исследований, количественная оценка 23 факторов ранжирования ИИ-цитирования
- Seer Interactive, AIO Impact on Google CTR: 2026 Update — 53 бренда, 2,43 млрд показов. CTR -61% при наличии AI Overview
- Discovered Labs, AI Citation Patterns: How ChatGPT, Claude, and Perplexity Choose Sources — Лишь 12% цитат ИИ пересекаются с топ-10 Google
- Ahrefs, Generative Engine Optimization: Growth Strategies and Metrics — Анализ 300 тыс. ключевых слов. Упоминания в вебе превосходят обратные ссылки 3:1 по показу в AI Overview
- Datos/SparkToro, State of Search Q1 2026 — Отслеживание доли ИИ-поиска на основе кликстрима
- Rand Fishkin, Search Happens Everywhere — Анализ 41 сайта, поиск не ограничивается Google
- Go Fish Digital, GEO Case Study: 3X’ing Leads — ИИ-рефералы с конверсией в 25 раз выше традиционного поиска
- Search Engine Land, How schema markup fits into AI search — Анализ без хайпа: разметка schema и ИИ-поиск
- Lily Ray, The Vicious Cycle of SEO — Предупреждение о недолговечности GEO-спама
Источники
Статьи
- Aggarwal et al., GEO: Generative Engine Optimization, KDD 2024 — Цитаты +41%, статистика +32%, указание источников +30% повышения видимости
- Xu et al., Measuring Google AI Overviews (2026) — Анализ 55 393 запросов. 30% доменов цитат AIO отсутствуют на 1-й странице органики
- Fang et al., Recency Bias in LLM-Based Reranking, SIGIR-AP 2025 — Все 7 моделей последовательно продвигают свежий контент
- Zhang et al., Citation Selection to Citation Absorption (2026) — Количественное сравнение паттернов цитирования ChatGPT/Google AIO/Perplexity
- Algaba et al., LLMs Reflect Human Citation Patterns, NAACL 2025 — LLM сильнее предпочитают высокоцитируемые статьи (эффект Матфея)
- arXiv:2602.18455, AI Search Impact on Wikipedia Traffic (2026) — AIO снизили трафик Wikipedia на 15% (каузальный анализ DID)
- Yu et al., Structural Feature Engineering for GEO (2026) — Структура контента сама по себе влияет на вероятность цитирования
- Tian et al., Diagnosing Citation Failures in GEO (2026) — 5% модификации контента повышают долю цитирования на 40%
- Baack, Critical Analysis of Common Crawl, FAccT 2024 — Ключевые компоненты и предвзятость обучающих данных LLM
- Strauss et al., The Attribution Crisis in LLM Search (2025) — 92% Gemini не предоставляют кликабельных ссылок
Отчёты с данными
- Ahrefs, Do AI Assistants Prefer Fresh Content? (2025) — Анализ 17 млн цитат ИИ
- SparkToro/Datos, State of Search Q1 2026 — Отслеживание доли ИИ-поиска на основе кликстрима
- GitClear, AI Copilot Code Quality 2025 — Анализ 210 млн строк
- Gartner — Прогноз снижения объёма традиционного поиска на 25% к 2026 году
- llms.txt 제안 표준 — Search Engine Land
История изменений
- 2026-05-27: Первая версия