 Image: AI generated
Image: AI generated
Ser inteligente nao significa saber explicar
Quando voce pede ao Opus 4.8 para refatorar codigo, o resultado e impressionante. Ele resolve grafos de dependencia complexos de uma so vez, trata edge cases preventivamente e escreve testes sem falhas. Mas quando voce pede que ele explique o resultado, comecam os problemas. Ele fala como um especialista apresentando para outro especialista. Assume que o conhecimento de base e compartilhado, omite as razoes por tras de decisoes-chave e mantem um nivel de abstracao desnecessariamente alto.
Quando voce pergunta a mesma coisa ao Opus 4.6, e o oposto. Ele estima bem o que voce pode nao saber. Escolhe analogias adequadas, divide em etapas e estabelece o contexto primeiro. Mas quando a dificuldade de raciocinio aumenta, ele trava em problemas que o 4.8 resolve de primeira.
Resumindo em uma frase: Opus 4.8 e inteligente mas fala de forma complicada, e Opus 4.6 explica de forma facil de entender mas tem desempenho de raciocinio inferior.
Isso nao e um defeito. Por que isso acontece, e como transformar essa diferenca em vantagem estrutural, e o tema deste artigo.
A maldicao do conhecimento tambem se aplica aos LLMs
Em 1989, os psicologos Camerer, Loewenstein e Weber provaram experimentalmente: quanto mais informacao uma pessoa possui, menos ela consegue considerar adequadamente o fato de que a outra pessoa nao tem essa informacao. Esse fenomeno, chamado “Maldicao do Conhecimento” (Curse of Knowledge), e um vies cognitivo repetidamente confirmado em pedagogia, economia e design de UX.
Oliver Wendell Holmes disse: “Eu nao daria um centavo pela simplicidade deste lado da complexidade. Mas daria minha vida pela simplicidade do outro lado da complexidade.” Explicacoes simples nao sao simples por ignorancia — so sao possiveis depois de atravessar a complexidade. Paradoxalmente, enquanto se esta imerso na complexidade, a capacidade de falar de forma simples diminui.
Um artigo da EMNLP de 2025 mostrou que esse fenomeno tambem ocorre em modelos de raciocinio de grande escala. O resultado paradoxal e que modelos com capacidade de raciocinio mais poderosa sao mais vulneraveis a maldicao do conhecimento. Modelos que raciocinam profundamente assumem implicitamente que o interlocutor pode acompanhar seu processo de raciocinio. E exatamente o mesmo problema que um especialista humano enfrenta ao explicar algo para um iniciante.
Por isso existem dois tipos de papeis no mundo. Quem pensa profundamente e quem comunica de forma clara. Pesquisador e comunicador de ciencia. Desenvolvedor senior e tech lead. Juiz e advogado. Sao competencias diferentes. Seria otimo se uma unica pessoa fizesse os dois bem, mas na pratica e raro. Por isso as organizacoes separam os papeis.
O mesmo vale para LLMs. E o Claude Code possibilita essa separacao com uma unica linha de configuracao.
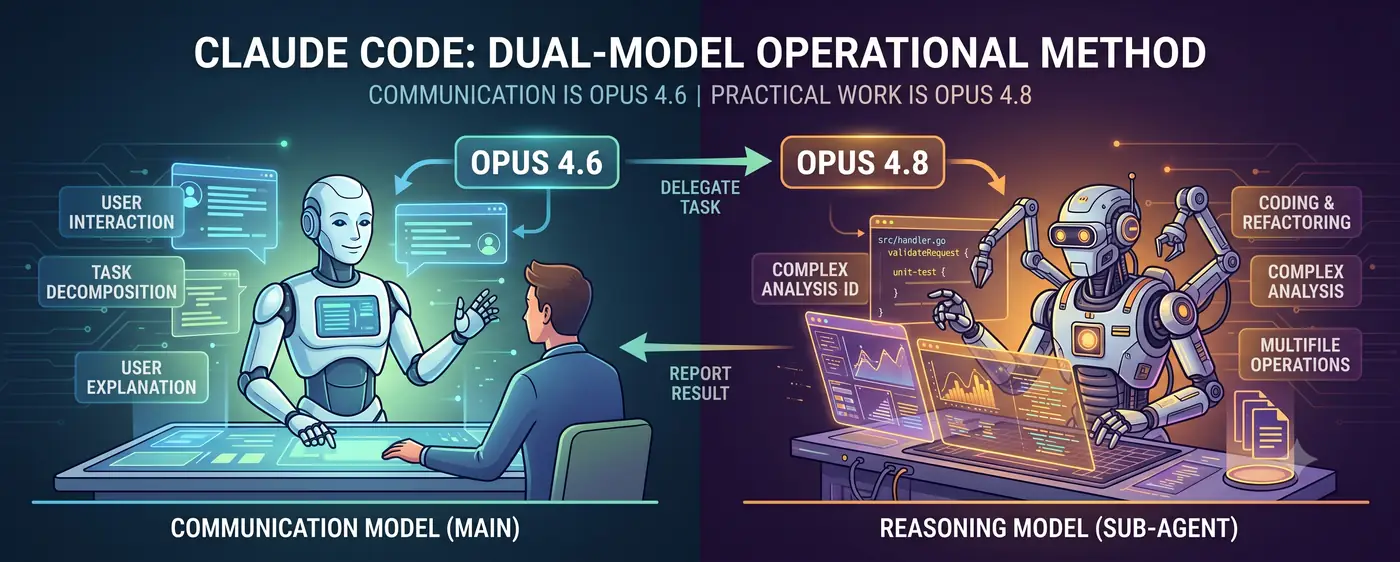
Modelo de comunicacao + modelo de raciocinio
A estrutura central e simples.
Usuario <-> Modelo de comunicacao (principal) <-> Modelo de raciocinio (subagent)
- O modelo de comunicacao (Opus 4.6) fica na linha de frente da conversa. Interpreta a intencao do usuario, decompoe tarefas e reporta resultados em linguagem compreensivel para humanos.
- O modelo de raciocinio (Opus 4.8) cuida do trabalho pesado. Escrita de codigo, analises complexas, refatoracao de multiplos arquivos — tarefas de raciocinio de alta dificuldade sao delegadas e executadas como subagent.
O usuario conversa com o 4.6. Quando o 4.6 julga que “a dificuldade de raciocinio e alta demais para eu resolver diretamente”, ele cria um subagent 4.8 e delega a tarefa. Quando o 4.8 retorna o resultado, o 4.6 o interpreta e explica ao usuario.
Este proprio artigo e a prova disso. Quem esta escrevendo este artigo e o Opus 4.6 (principal), e a pesquisa de artigos academicos e a analise de dados de benchmark que fundamentam este artigo foram realizadas pelo Opus 4.8 (subagent).
O que os benchmarks dizem
Os dados do BenchLM revelam a personalidade dos dois modelos em numeros.
| Area | Opus 4.6 | Opus 4.8 | Vantagem |
|---|---|---|---|
| Geral | 86 | 93 | 4.8 |
| Codificacao | 64.4 | 76.4 | 4.8 |
| Tarefas de agente | 72.6 | 80.1 | 4.8 |
| Tarefas de conhecimento | 76.2 | 70.1 | 4.6 |
| Escrita criativa | Vantagem | - | 4.6 |
O 4.8 domina em codificacao e tarefas de agente. Mas em transmissao de conhecimento e escrita criativa, o 4.6 esta a frente. Nas avaliacoes da Claude API, tambem se repete que a escrita do 4.8 e “mais parecida com IA (more AI-sounding)” do que a do 4.6. O 4.8 raciocina com precisao, mas a capacidade de desdobrar esse raciocinio de forma agradavel para leitura humana e melhor no 4.6.
O preco dos dois modelos e identico — $5 por milhao de tokens de entrada, $25 por milhao de tokens de saida. Separar os papeis nao aumenta o custo. Nao se trata de otimizacao de custos, mas de otimizacao pura de qualidade.
Roteamento de modelos ja e engenharia comprovada
A ideia de “usar dois modelos separadamente” nao e nova. Na academia, ja e um campo estabelecido.
O RouteLLM (ICLR 2025) roteou dinamicamente consultas entre um modelo forte e um modelo fraco, reduzindo o custo em mais de 2x enquanto mantinha a qualidade. O FrugalGPT (2023) alcancou desempenho no nivel do GPT-4 com 98% de reducao de custo usando cascata de LLMs. A conclusao comum dessas pesquisas e clara: um modelo fraco com orquestracao superior frequentemente vence um modelo forte com orquestracao deficiente.
A propria Anthropic usa esse padrao. A implementacao de deep-research da Anthropic segue o padrao orquestrador-trabalhador, e a configuracao multi-agent superou o Opus 4 de agente unico em 90.2%. Pesquisas indicam que cerca de 80% dos sistemas multi-agent em producao usam a estrutura orquestrador-trabalhador.
O que eu faco e a forma mais simples desse padrao. Nao e um roteador, nem uma cascata, nem otimizacao de custos. E apenas um modelo otimizado para comunicacao na linha de frente, e um modelo otimizado para raciocinio trabalhando nos bastidores. O principio da separacao de papeis em si.
Como configurar
Criar essa estrutura no Claude Code e simples.
Passo 1: Configurar o modelo principal
Execute o Claude Code com Opus 4.6. Defina o modelo padrao como claude-opus-4-6-20250610 nas configuracoes ou selecione o modelo ao iniciar. Este sera o modelo de comunicacao que conversa com o usuario.
Passo 2: Override de modelo no subagent
A ferramenta Agent do Claude Code suporta o parametro model. Ao criar um subagent, basta fazer override do modelo para opus (Opus 4.8).
Agent({
description: "Refatoracao de codigo",
model: "opus",
prompt: "A funcao validateRequest em src/handler.go..."
})
E so isso. O agente principal (4.6) conversa com o usuario, e tarefas de alta dificuldade sao delegadas ao subagent (4.8).
Passo 3: Distinguir entre fork e fresh agent
Existem dois tipos de subagent no Claude Code.
- fork (
subagent_type: "fork"): Herda o contexto da conversa atual integralmente. Como compartilha o cache de prompt, o custo de entrada e reduzido em ate 90%. Porem, o fork herda obrigatoriamente o modelo do pai, entao o override de modelo nao se aplica. - fresh agent: Inicia em um contexto novo. O override de modelo e possivel. Voce precisa incluir o contexto necessario diretamente no prompt.
Portanto, para usar o modelo de raciocinio (4.8), voce deve criar um fresh agent. O fork e usado quando voce precisa de exploracao paralela mantendo o modelo de comunicacao (4.6).
Padroes praticos
| Situacao | Metodo | Razao |
|---|---|---|
| Escrita de codigo complexo | fresh agent + model: opus | Alta dificuldade de raciocinio |
| Refatoracao de multiplos arquivos | fresh agent + model: opus + isolation: worktree | Raciocinio + isolamento necessarios |
| Pesquisa/exploracao paralela | fork (mantem 4.6) | Compartilhamento de contexto e vantajoso |
| Leitura/edicao simples de arquivos | Principal (4.6) direto | Overhead de delegacao e maior |
| Pesquisa web/research | fresh agent + model: opus | Raciocinio preciso necessario |
Ate 4-8 worktrees simultaneos e estavel. Acima disso, a revisao de resultados se torna o gargalo.
Friccoes conhecidas
Nao e perfeito. Duas limitacoes conhecidas atualmente.
Primeira, problema de vazamento de override de modelo. A configuracao de model do subagent pode se propagar para agentes filhos que esse subagent cria. Como pode ocorrer uso nao intencional de modelos, e pratico limitar a profundidade do subagent a um nivel.
Segunda, ausencia de configuracao de modelo por agente. Atualmente, o Claude Code nao suporta oficialmente a funcionalidade de predefinir modelos por tipo de agente nas configuracoes do projeto. E necessario especificar o parametro model a cada chamada do Agent. Ha solicitacoes ativas da comunidade para essa funcionalidade.
Ambas sao friccoes que serao resolvidas conforme o Claude Code evolui. Mesmo no estado atual, apenas com override manual, os beneficios da estrutura podem ser plenamente aproveitados.
Comunicador e pensador sao papeis diferentes
No tribunal, juiz e advogado lidam com a mesma lei, mas seus papeis sao diferentes. O juiz decide. O advogado explica ao cliente o que aquela decisao significa. Se o juiz ler a sentenca diretamente para o cliente, o cliente nao entende. Se o advogado tentar proferir a sentenca, a fundamentacao sera deficiente. A separacao de papeis nao e uma fraqueza do sistema, mas uma forca.
O mesmo vale para revisao de codigo. A capacidade de um desenvolvedor senior encontrar bugs e a capacidade de fazer um desenvolvedor junior entender esse bug sao coisas distintas. E raro que um engenheiro brilhante seja tambem um excelente tech writer. As organizacoes sabem disso, por isso separam os papeis.
Com IA e igual. Capacidade de raciocinio e capacidade de comunicacao sao eixos diferentes. E no processo atual de treinamento de modelos, esses dois eixos tendem a entrar em conflito. Maximizar o desempenho de raciocinio torna a saida compacta e especializada; maximizar o desempenho de comunicacao torna o raciocinio superficial.
Exigir que um unico modelo faca os dois bem e como pedir a um juiz que tambem faca o papel de advogado. E possivel. Mas nenhum dos dois sera otimo.
A separacao entre modelo de comunicacao e modelo de raciocinio e um principio estrutural valido independentemente da versao. 4.6 e 4.8 sao apenas as escolhas concretas de hoje. Se amanha surgirem 5.0 e 5.2, basta reposiciona-los com o mesmo principio. Os modelos sao substituidos, mas o fato de que “o papel de pensar profundamente” e “o papel de comunicar de forma clara” sao diferentes nao e substituido.
Artigos relacionados
- Ratchet Pattern — Como fazer um agente ir ate o fim
- Por que seu loop de agente diverge
- Por que o drift nunca morre
Leitura adicional (externa)
- RouteLLM: Learning to Route LLMs with Preference Data — Framework para roteamento dinamico entre modelo forte e fraco de acordo com a dificuldade da consulta.
- Anthropic: How we built our multi-agent research system — Como a Anthropic implementou deep-research com o padrao orquestrador-trabalhador.
Fontes
- Camerer, C., Loewenstein, G. & Weber, M. (1989). The Curse of Knowledge in Economic Settings: An Experimental Analysis. Journal of Political Economy, 97(5), 1232-1254. DOI — Prova experimental da maldicao do conhecimento.
- Li, W. et al. (2025). Curse of Knowledge: Your Guidance and Provided Knowledge are biasing LLM Judges in Complex Evaluation. Findings of EMNLP 2025. arXiv — Descoberta de que modelos de raciocinio mais fortes sao mais vulneraveis a maldicao do conhecimento.
- Ong, I. et al. (2025). RouteLLM: Learning to Route LLMs with Preference Data. ICLR 2025. arXiv — Framework para aprender roteamento de LLMs com dados de preferencia.