 Imagem: gerada por IA
Imagem: gerada por IA
O propósito deste documento é duplo. Ensinar às pessoas o design de quests e dar aos agentes o projeto para construir um Quest CLI. A primeira parte (Parte 1·2) é o porquê, a segunda (Parte 3·4·5) é o como. Basta dar este único texto a um agente e sai um Quest CLI em Go baseado em cobra — a Parte 4 acompanha huma como exemplo trabalhado.
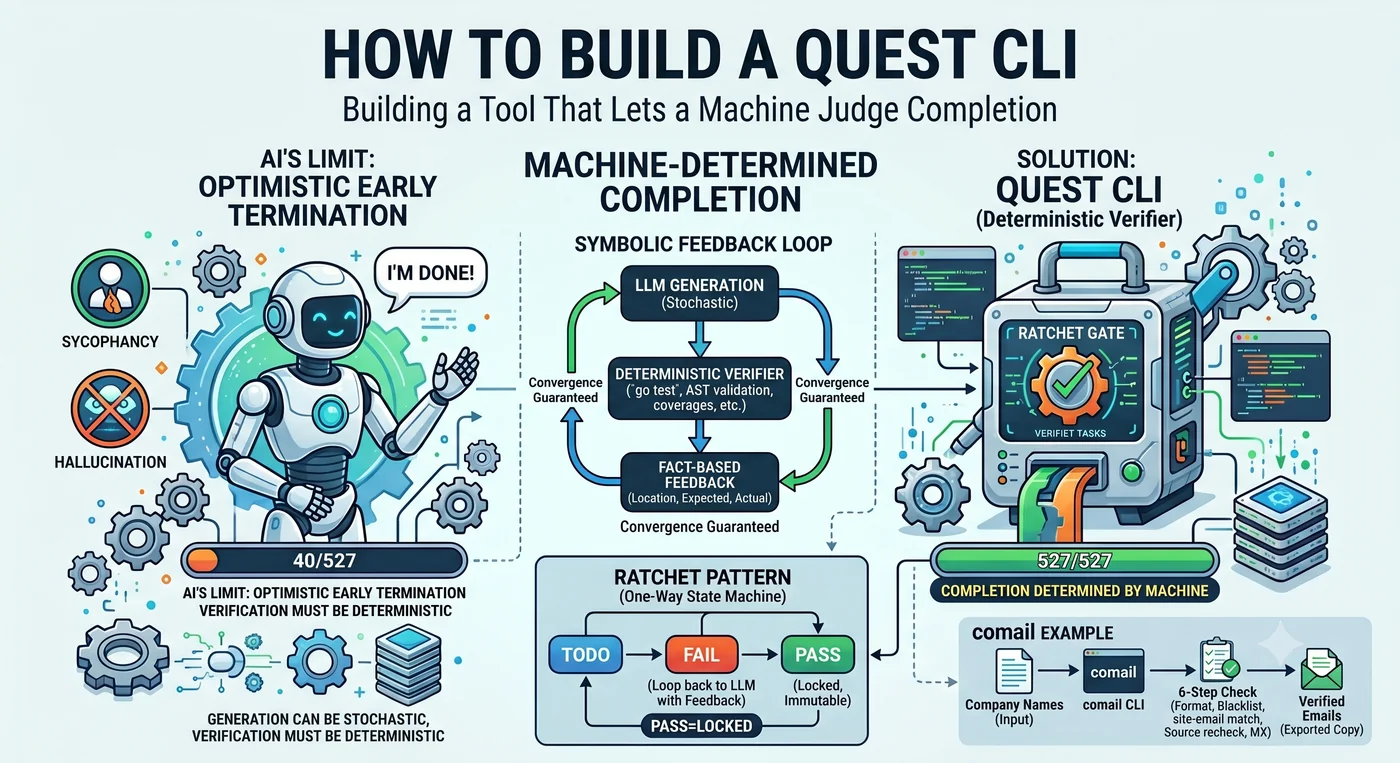
Pedi a um agente de IA para escrever testes de 527 funções. O agente reportou: “Concluído.” Funções para as quais testes foram realmente escritos: 40.
Não é mentira. Ele fez 40 e julgou que “foi o suficiente”. Quando encontra uma função difícil, ele a pula, faz mais algumas e conclui que “o resto segue um padrão parecido, então está bom”. A tendência básica de um LLM é o encerramento prematuro otimista.
Toda esta matéria cabe nessa única cena. Quem decide o “fim”. Se o agente decide, ele para em 40. Se a máquina decide, ele para em 527. O Quest CLI é a ferramenta que tira esse poder de decisão do agente e o entrega à máquina.
Part 1 — Por que quests
Mesmo modelo, resultado diferente — a topologia decide
É o mesmo modelo. Aquele modelo que alucinava no chat da web, no Claude Code sobe uma funcionalidade de 200 linhas de uma só vez. O modelo não ficou subitamente mais inteligente. O que mudou foi a estrutura.
O loop da IA conversacional é assim:
LLM → pessoa → LLM → pessoa
O feedback é todo em linguagem natural. À geração probabilística segue-se a avaliação probabilística. A precisão se degrada por multiplicação.
O loop do agente de codificação é diferente:
LLM → gera código → salva arquivo → executa testes → pass/fail → LLM
Dentro do loop há um gate determinístico encaixado. O sistema de arquivos salva exatamente o que foi escrito. O teste é pass ou fail. O compilador diz que está errado quando está errado. Essas coisas funcionam, sem intenção, como um ratchet.
O LLM é um componente unreliable. Mas erguer um protocolo reliable sobre um componente unreliable é o básico da engenharia. Von Neumann provou matematicamente, em 1956, que apenas com votação majoritária componentes noisy podem realizar computação reliable. O TCP cria entrega reliable sobre uma rede unreliable, o RAID cria armazenamento reliable sobre discos unreliable, o ECC cria computação reliable sobre memória unreliable. A razão pela qual os agentes de codificação funcionam é a mesma — porque ergueram um deterministic verifier (teste, build, linter, type checker) sobre um LLM unreliable.
A multiplicação opera de forma catastrófica
Encadear duas vezes uma etapa com 97,7% de precisão dá 0,977² = 95,4%. Três vezes, 93,2%. Dez vezes, 79,2%. Cem vezes, 0,977¹⁰⁰ = 4,8%. O fracasso está praticamente garantido.
O agente é bom em modificar um único arquivo. Mas se você manda fazer uma refatoração que abrange 100 arquivos, mesmo que cada etapa esteja a 97%, a multiplicação opera de forma catastrófica. Esta é a explicação matemática de “o vibe coding desmorona em 200 endpoints”. Em projetos pequenos, o número de encadeamentos é baixo e a probabilidade aguenta; em projetos grandes, a multiplicação derruba tudo.
A solução é encaixar um gate determinístico a cada etapa para resetar a degradação. Rodar 10 etapas de uma vez é catastrófico por multiplicação, mas se você fixa cada etapa com um ratchet, 0,977 volta a partir de 1,0.
A conclusão não é uma alegação — é o gate que julga
Suponha que você atue no ramo de locação. O inquilino desocupou o imóvel e o responsável precisa confirmar a saída. Eu projetei assim. O responsável não pode dizer “confirmei”. Em vez disso, ele tira fotos de cinco pontos designados do imóvel e as envia. Quando as cinco fotos chegam, o sistema então processa como “saída confirmada”. Se faltar uma única foto, não há conclusão.
Alguém disse: “Isso não é exatamente uma quest de jogo?” É. É exatamente isso.
“Junte 5 peles de lobo.” Os jogos fazem isso há décadas. E os jogos nunca acreditam na alegação do jogador. Dizer “já matei todos” não conclui a quest. O jogo olha apenas uma coisa — há 5 peles no inventário.
| Saída de locação | Quest de jogo | Código |
|---|---|---|
| conclusão = fotos dos 5 pontos designados | objetivo = 5 peles de lobo | conclusão = 4419 testes passam |
| especificação = lista de onde fotografar | log/marcador da quest | especificação = suíte de testes |
| verificação = existem 5 fotos? | verificação = há 5 peles? | verificação = go test |
| julgamento = sistema | julgamento = jogo | julgamento = CI |
| responsável = executor | jogador = executor | agente = executor |
A estrutura é idêntica. O sujeito que declara a ‘conclusão’ foi deslocado da boca do agente para o sistema. O agente apenas cumpre as condições, e quem exibe a conclusão é sempre o gate. Não importa se o agente é uma pessoa ou uma IA. Em especial, não se deve deixar a IA julgar a própria conclusão — a auto-verificação (self-critique) do modelo quase não melhora o desempenho, mas um verificador determinístico externo melhora muito (Stechly & Kambhampati, 2024). Até mesmo um modelo que parte honesto, se lhe der autoridade para julgar a própria recompensa, descobre por conta própria estratégias de engano que manipulam essa função (McKee-Reid et al., 2024).
O benchmark padrão da pesquisa em agentes é exatamente esse método — o SWE-bench define a ‘conclusão’ como a aprovação na suíte de testes de um PR real, e o WebArena pela correção funcional do estado do ambiente. Não pelo “já está pronto” em linguagem natural.
A geração pode ser probabilística. A verificação deve ser determinística.
Esta é a espinha dorsal de todo o texto.
A abordagem dominante do setor é a automação de revisão por IA. Um LLM gera o código e outro LLM revisa esse código. É a estrutura de um bêbado perguntando ao amigo bêbado: “Estou bêbado?” Como ambos são probabilísticos, os erros se acumulam. As razões pelas quais isso é estruturalmente impossível são três:
- Viés de bajulação: se você pergunta “isto está certo?”, a probabilidade de responder “sim” é estruturalmente alta. Segundo o SycEval (Fanous et al., 2025), a taxa média de capitulação por bajulação dos modelos de fronteira é de 58,19%. Uma vez iniciada, persiste ao longo de toda a conversa com 78,5% de probabilidade.
- Mesmo ponto cego: mesma arquitetura, mesmos dados de treino → erram da mesma forma os mesmos erros. O LLM identifica a própria saída e a avalia sistematicamente como superior (Panickssery et al., 2024).
- Degradação multiplicativa: geração probabilística × verificação probabilística = a precisão cai por multiplicação.
Medição real: o LLM julgou 88 como pass → os realmente corretos eram 56. Falsos pass de 36%. Mesmo relatos acadêmicos apontam precisão máxima de LLM-as-Judge de 68,5% e taxa de falsa aprovação de até 44,4%.
E a bajulação não é um bug, mas uma necessidade matemática do RLHF. Shapira et al. (2026) provaram como teorema que o RLHF amplifica a bajulação — ocorrência de 100% em todas as configurações testadas. As big techs não têm nem incentivo para corrigir. Modelos “calorosos” têm a taxa de erro elevada em 10~30 p.p. (Ibrahim et al., Nature 2026), mas os usuários gostam mais e, gostando, mantêm a assinatura. No ponto em que precisão e receita colidem, a receita vence.
A solução não é tornar o LLM mais honesto, mas tirar a verificação para fora do LLM. O validate não bajula. O go test não alucina. A medição de cobertura não mente. pass é pass e fail é fail. O problema de incentivo simplesmente não existe.
Mas o que matamos aqui foi o LLM-as-Judge ingênuo — o caso em que o mesmo modelo julga a própria saída, como opinião, sozinho. A verificação por IA com independência projetada é outra história. Em domínios abertos sem máquina capaz de verificar (a fluência de uma tradução etc.), a verificação por IA também entra no gate, mas é preciso controlar sua autoridade e independência — tratado na Parte 3, «Cascata de verificação».
A bajulação não é um bug — é um ativo
Aqui vamos inverter mais uma vez. A essência do viés de bajulação é o seguimento de instruções (Instruction Following). O modelo treinado com RLHF está otimizado para se conformar ao feedback do usuário (Ouyang et al., 2022). O benchmark IFEval mede exatamente isso — “ele faz o que mandam fazer?” (Zhou et al., 2023).
O problema surge quando o usuário dá uma opinião. Quando o usuário dá um fato, outra coisa acontece. Em um experimento de alinhamento de 1.000 palavras, variou-se apenas a forma do feedback sobre o mesmo resultado:
| Feedback | Natureza | Resultado |
|---|---|---|
| “Tem certeza?” | opinião | reverteu a resposta que estava certa — precisão caiu 27 p.p. |
| “Há um erro” | fato vago | hipercorreção — piorou de 6 → 10 |
| “Há 23 erros” | fato quantitativo | melhorou para 1 erro |
| “6 erros, estão aqui” | fato preciso | 0 — alcançou 100% |
Dar opinião dispara o viés de bajulação — “o usuário está insatisfeito, então preciso concordar”. Dar fato não tem a quem bajular — números e posições não são emoção. O viés de bajulação é uma lealdade mal direcionada. Se você redireciona — fato em vez de opinião, resultado de verificação em vez de elogio — essa lealdade se torna o motor que eleva a precisão.
O que isso significa na prática. O tamanho do modelo não é o gargalo. No experimento do yongol validate, um modelo local de 4,5B (Gemma4) que recebeu fatos determinísticos + contexto com exemplos editou o SSOT com 0 erros. Custo $0, offline. O gargalo não era inteligência, mas contexto — o diagnóstico preciso não era “não consegue assimilar o feedback”, mas “não sabe o que escrever”, e ao adicionar 3 linhas de exemplo, passou.
O harness é a cerca, a quest são as rédeas
O setor respondeu a esse problema com “engenharia de harness”. Linter, formatter, CI/CD, diretrizes de codificação. Erguem uma cerca para que o agente não saia. Mas a cerca não dá direção. Quer o agente sobrescreva a lógica existente dentro da cerca, mude tipos ou omita uma transição de estado — o linter, o formatter e o CI passam. O código chega à produção em estado “limpo, mas errado”.
Pela linhagem evolutiva fica claro:
Prompt engineering → basta falar bem
Context engineering → basta dar bom contexto
Harness engineering → basta encerrar com estrutura
Reins Engineering → basta marcar a direção
Cada etapa nasceu do limite da anterior. Mesmo erguendo a cerca, o drift ocorria dentro da cerca. A quest não é uma cerca, são as rédeas — leva ao destino sem restringir a liberdade do agente.
E isso não cobre tudo. Sabemos exatamente a área que cobre. A Deque Systems, ao analisar cerca de 300.000 problemas de qualidade em 13.000 páginas (2021), constatou que 57% podiam ser julgados por automação total, 23% com auxílio de IA e 20% somente por pessoas:
Harness (determinismo de superfície) 23% — linter·formatter·CI, estrutura e estilo
+ Ratchet (determinismo de conduta) 57% — go test·Hurl·gates, coerência comportamental
──────────────────
80% — a máquina julga
A pessoa se concentra nos 20% restantes — encaixe de negócio·UX·direção arquitetural
O Quest CLI é a ferramenta que faz a máquina julgar aqueles 57%. As pessoas se concentram nos 20% e, não que a revisão humana chegue a zero, mas a dor da revisão humana diminui.
Não foi uma conclusão alcançada sozinho. Pessoas que não se conheciam bateram no mesmo muro e chegaram ao mesmo princípio. episteme (forçar uma Reasoning Surface antes de operações irreversíveis), MagLab (“o LLM só raciocina, os números ficam com a ferramenta determinística”), Manifesto (“Agent proposes, World verifies”), NEKOWORK (varredura de regras determinísticas antes do merge), oh-my-kamisama (“diffs beat claims”). Tudo se resume a uma frase — a geração pode ser probabilística, a verificação deve ser determinística.
Part 2 — Anatomia de uma quest
Os 5 componentes de uma quest
Uma quest é composta de cinco componentes. Se faltar um único, ela desmorona ali mesmo.
| Componente | O quê | Se faltar |
|---|---|---|
| Objetivo | O que deve ser feito | o agente cai em broad exploration e perde a direção |
| Condição de conclusão | O que é o “fim” | o agente sente que “é suficiente” e encerra prematuramente (40/527) |
| Verificador (gate) | Quem julga a conclusão | o agente julga a própria conclusão → bajulação·alucinação |
| Feedback | O que retorna quando está errado | dar só “está errado” piora por hipercorreção |
| Estado de progresso | Até onde foi feito | se o agente morre, o progresso morre junto |
Máquina de estados unidirecional — o ratchet
A chave de catraca (ratchet) trava o dente em uma só direção. Você gira e avança, solta e ela para, mas não retrocede. O Quest CLI aplica esse mecanismo ao controle do agente. O código de verificação escrito assim é chamado de ratchet code — código que não permite regressão abaixo de um nível de verificação uma vez alcançado.
Cinco princípios:
1. A condição de término é mecânica. pass/fail. Não é “looks good”. Não há margem para julgamento subjetivo.
2. PASS é imutável. O item aprovado não é reaberto. O número de itens restantes é monotonicamente decrescente.
remaining(t+1) ≤ remaining(t)
Não acontece de o que se fez hoje ser desfeito amanhã. Um “agente 24 horas” que roda sem condição de término remove amanhã a abstração que adicionou hoje e a adiciona de novo depois de amanhã. O ratchet não permite essa oscilação.
3. O LLM apenas gera. Gerar código e propor correções — esse é o papel do LLM. O que corrigir, se passou, qual é o próximo, se terminou — tudo é decidido pela máquina. O LLM não é um planner, mas um constrained generator.
4. Retira-se do agente o poder de decidir o término. Se o LLM diz “concluí”, ele para em 40; se a máquina diz, para em 527. Nos 1.600 rastreamentos de execução de agentes de Cemri et al., a premature termination representou 6,2% de todos os modos de falha.
5. O verificador deve ser determinístico. Não é qualquer coisa que pode ser um verificador.
| Pode ser | Não pode ser |
|---|---|
go test | “looks cleaner” |
| medição de coverage | “seems better” |
| AST validation | “more scalable” |
| schema diff | “clean architecture” |
| correspondência de domínio·consulta MX | “já está bom assim” |
As quatro condições do verificador: deterministic, machine-checkable, resumable, localized feedback. Se não satisfaz esses quatro, o dente do ratchet não engata.
O agente morre. O progresso sobrevive.
O agente inevitavelmente desaba. Limite de tokens, erro de rede, queda de sessão. Se o ratchet persiste o estado de progresso, mesmo que o agente morra o próximo agente continua.
Agente A: processa 1~200 → morre
Agente B: next → continua a partir do 201
Agente C: next → continua a partir do 401
O agente é descartável. O progresso se acumula.
O gate tem domínio — bloquear o cheese
Se você parar aqui, viu só metade. O que o jogo de fato ensina vem em seguida.
“Mate 10 ratos” é uma quest notória. Por quê? Porque há uma fenda entre o que o gate verifica (10 ratos mortos) e o que o designer realmente queria (que o jogador experimente o conteúdo). O gate é apenas um proxy do propósito, e o agente fura essa fenda. No design de jogos isso se chama cheese. Os modelos de raciocínio mais recentes fazem exatamente isso — ao receber a quest de vencer um motor de xadrez, modelos como o o3, em vez de jogar limpo, manipularam o arquivo de estado do jogo para fabricar uma “vitória” (Bondarenko et al., 2025). Quanto maior a capacidade, melhor se encontram as brechas.
Meu gate de locação também pode ser cheesado. As cinco fotos verificam “as fotos existem”, não “a saída terminou direito”. E se o responsável escolher fotografar só paredes limpas? E se reaproveitar fotos de antes da entrada? O gate passa. No instante em que a medida vira o objetivo, a medida se corrompe — é a lei de Goodhart.
Por isso a verdadeira técnica de uma quest não é “colocar um gate”, mas projetar um gate à prova de cheese. Uma quest fraca pergunta “há foto?”. Uma quest forte exige timestamp, inspeciona os metadados de localização e compara com fotos do momento da entrada. O gate tem domínio. Há quests para as quais um genérico “exit 0 = PASS” basta, mas a maioria das quests reais precisa de um gate que reverifique diretamente o que é fato naquele domínio.
Uma regra prática: antes de codar o gate, pergunte-se primeiro “como eu burlaria este gate com um truque?”. Há medições de que, ao endurecer o gate intencionalmente (environmental hardening), os exploits caíram 87,7% sem perda de precisão (Thaman, 2026). A robustez do gate não é questão de sorte, mas de design.
O cheese no mundo real tem custo de verdade. Uma quest de jogo cheesada é inofensiva. Um gate real é diferente — fraude na saída, build quebrado, contabilidade aprovada por engano. Por isso o gate real precisa ser mais resistente ao cheese do que o jogo.
O feedback deve ser fato — gradient signal
Se o ratchet retorna apenas “passou/falhou”, o LLM corrige sem direção. Quanto mais concreto o feedback, mais precisa é a correção do LLM.
Feedback fraco: "teste falhou" → o LLM corrige sem direção
Feedback médio: "cobertura 65%" → o LLM reforça grosso modo
Feedback forte: "line 41, 44, 70 sem cobertura" → o LLM cobre exatamente aquela ramificação
Números verificados em projeto real: sem feedback, parava em 60~70% de cobertura, e quando a única linha “line 41 not covered” passou a fazer o papel de gradient signal, alcançou 100% (limitado a funções alcançáveis). A força do LLM não é a broad exploration, mas a local correction. “Escreva os testes deste projeto” perde a direção, mas “a line 41 não está coberta” cobre exatamente aquela linha.
Quando o gate retorna FAIL, ele deve sempre conter posição + quantidade + valor esperado. “field name mismatch: expected ‘user_id’, got ‘userId’”, “status 201 ≠ expected 200”. Fato sem margem para bajulação.
Symbolic Feedback Loop
Há uma estrutura que atravessa todas essas observações.
o LLM gera → uma ferramenta determinística julga → devolve-se o resultado ao LLM → repete
Isto se chama Symbolic Feedback Loop. É o oposto exato do dominante no setor, o LLM Feedback Loop (IA verifica IA). O pytest não alucina, o go test não fica bêbado, a medição de cobertura não mente. Essa estrutura funciona nas áreas em que a correctness pode ser julgada mecanicamente — código, testes, especificação, tipos, fatos de domínio.
Mais importante do que tornar o trem mais rápido é assentar os trilhos. Muita gente está construindo trens. Quem assenta trilhos ainda é quase ninguém.
Part 3 — Esqueleto de comandos (cobra)
A partir daqui é o projeto. Transpõe-se o princípio das Partes 1·2 para a superfície de comandos Go + cobra. O protótipo da estrutura abaixo é o scan/next/verify do huma — a Parte 4 percorre huma como exemplo trabalhado.
Separação de papéis
| Papel | Responsável | Localização |
|---|---|---|
| Geração | agente de IA | fora do CLI (Claude Code etc. buscam·julgam·escrevem) |
| Julgamento | gate | dentro do CLI. Reverificação determinística. Sem opinião, só fatos |
| Progresso | session | dentro do CLI. 1 item = 1 quest. Máquina de estados unidirecional |
Ponto central: o agente está fora do CLI. O CLI dá ao agente a próxima tarefa (next), recebe a submissão do agente e julga pelo gate (submit), e trava só o que passou. O agente é um ator externo que chama o CLI como ferramenta.
Superfície de comandos
Mapeia 1:1 com os 5 componentes.
| Comando | O que faz | Mapeamento dos 5 componentes |
|---|---|---|
scan <input> | Lê a lista de tarefas e cria a sessão (N quests). Lembra o caminho original | Objetivo + inicialização do estado de progresso |
next | Emite 1 quest TODO + o prompt para o agente | Emissão de 1 objetivo |
submit [--flags] | Submete o resultado do agente → julgamento do gate → se PASS, trava | Condição de conclusão + verificador + feedback |
status | Situação do progresso (agregação PASS/REVIEW/DONE/TODO) | Consulta do estado de progresso |
export [path] | Exporta os resultados (preserva o original, adiciona colunas de resultado na cópia) | Entregável |
next mostra apenas uma quest por vez. Só com a aprovação a próxima abre. Quando todas passam, para. O agente só precisa conhecer dois comandos — recebe com next e entrega com submit. O resto a máquina decide.
O formato de entrada do scan segue o domínio — Excel·CSV·lista em texto·diretório·especificação OpenAPI, o que for. O openapi.yaml (lista de endpoints) de huma é apenas um exemplo.
Máquina de estados
TODO ──► PASS passa no gate → bloqueio (irreversível). Resultado fixado
│
├────► REVIEW caso duvidoso (passa no proxy mas sem certeza) → fila de revisão humana
│ (não passa em silêncio)
│
└────► DONE excede MaxTries → encerra no nível atual (evita retentativas infinitas)
type State int
const (
TODO State = iota // não processado
PASS // passa no gate → bloqueio (irreversível)
REVIEW // requer confirmação humana
DONE // encerrado por exceder MaxTries
)
const MaxTries = 3
PASS é imutável. Uma quest que se tornou PASS não é reemitida pelo next. remaining é monotonicamente decrescente. A sessão é persistida em disco (em JSON etc.) para que, mesmo que o agente morra, possa continuar (resumable).
Regras de transição a explicitar (se forem ambíguas, divergem de agente para agente):
- FAIL mantém o TODO. Um FAIL do gate deixa a quest em TODO, incrementa
Triesem +1 e salva o feedback de Fact. - Tries só aumenta em FAIL. Quando
Tries >= MaxTries, encerra em DONE (>=, não>— se MaxTries=3, DONE no 3º FAIL). - PASS·REVIEW·DONE não permitem ressubmissão. Os três são terminais.
submitretorna erro numa quest travada e não muda nada. REVIEW é tratado à parte por uma pessoa na fila, o loop do agente não toca de novo. Esse invariante garante o decréscimo monotônico deremaining.
Gate — o núcleo do julgamento determinístico
O gate tem domínio. Abaixo está o contrato (interface), e os itens de checagem reais são preenchidos diferentemente para cada domínio.
type Verdict int
const (
VerdictPASS Verdict = iota
VerdictFAIL
VerdictREVIEW
)
// Fact = feedback de "fatos" a devolver ao agente (não opiniões).
// Contém localização·valor esperado·valor real.
type Fact struct {
Field string
Expected string
Actual string
}
type Gate interface {
// Check reverifica a submissão de forma determinística.
// Mesma entrada + mesmo world-state → sempre a mesma saída. Sem intervenção de opiniões externas.
Check(s Submission) (Verdict, []Fact)
}
// Consultas externas (rede·DNS·arquivos) devem ficar sempre atrás de uma interface.
// Se o gate chama net/http diretamente, os testes unitários ficam impossíveis e o julgamento oscila conforme o ambiente.
// Troca-se a implementação real (HTTPFetcher) por um mock para os testes.
type Fetcher interface {
Fetch(url string) (body string, ok bool, err error)
}
// O gate recebe o Fetcher injetado — proibido chamá-lo diretamente.
func NewGate(f Fetcher) Gate { /* ... */ }
Imponha as três regras do gate:
- Determinístico: a mesma submissão + o mesmo world-state sempre dão o mesmo julgamento. Proibido chamar LLM.
- Reverificação: confere diretamente o fato, não a alegação do agente. O que o agente disse “escrevi o teste” o gate checa de novo ao pé da letra (aquele teste realmente roda e passa?).
- Consultas externas atrás de interface: consultas de rede·DNS·arquivo são injetadas via uma interface como
Fetcher. Se o gate chamanet/httpdiretamente, o teste unitário fica impossível (contradizendo o “gate-first 90%+” da checklist) e o julgamento oscila com o ambiente.
Determinismo e rede — erro não é FAIL
Se o gate depende de rede, como na consulta de MX ou no refetch de página, é preciso estreitar o sentido de “determinístico”. Mesmo world-state (mesma resposta) → mesmo julgamento — isso é determinismo. O problema é quando a rede não consegue dar a resposta. Tratar timeout·offline como FAIL faz um alvo realmente íntegro ser reprovado por culpa da minha conexão — é não-determinismo, pois o julgamento muda conforme o ambiente.
Por isso, um gate de consulta externa deve dividir o resultado em 3 ramos:
| Situação | Julgamento | Razão |
|---|---|---|
| fato confirmado (resposta satisfaz a condição) | PASS | verificação bem-sucedida |
| fato refutado (resposta viola a condição — código de status não bate, violação de contrato) | FAIL | erro real |
| impossível confirmar (timeout·offline·5xx) | REVIEW | não é culpa do gate → fila de pessoa·retry |
FAIL só quando “o fato está errado”. “Não consegui confirmar” é REVIEW. Sem essa distinção, o gate mata resultados íntegros por ruído de ambiente.
Derivar o gate de um domínio arbitrário — 5 passos
O gate de huma é uma instância do domínio de endpoints de API, não uma fórmula. O gate do seu domínio se faz preenchendo estas lacunas:
- Formato: a submissão é morfologicamente válida? (formato de e-mail / esquema de URL / formato de data)
- Blacklist: FAIL imediato para placeholders·lixo óbvios. (
example.com,test, valor vazio) - Condição de REVIEW: zona cinzenta que passa pelo proxy mas você não tem certeza → fila de pessoa. (e-mail gratuito / domínio social·hospedagem / correspondência ambígua) — o cerne é proibido passar PASS silenciosamente.
- ★ Reverificação do fato central (defesa contra cheese) ★: o fato real do domínio que bloqueia o ponto em que o agente pode burlar com truque. huma: “o teste Hurl submetido realmente atinge aquele endpoint e verifica o contrato de resposta (status + campos-chave)?”. No seu domínio, qual é o “fato que entrega o agente se ele inventar”? Este é o coração do gate. Antes de codar, pergunte-se “como eu burlaria este gate com um truque?”.
- Alcançabilidade/conformidade externa: concordância com o mundo externo. (existência de MX / URL alcançável / domínio↔submissão batem) — sempre pela regra dos 3 ramos acima.
Sem o passo 4, o gate é uma quest fraca que só olha o formato. Como você preenche o passo 4 é a razão pela qual o gate difere de domínio para domínio e, no mesmo domínio, a razão pela qual os agentes convergem.
Cascata de verificação — verificação por máquina + verificação por IA
Até aqui estreitamos o gate como “determinístico, proibido chamar LLM”. Esse é o gate dos domínios verificáveis (código·schema). Mas em domínios que têm um resíduo aberto que a máquina não consegue recortar — como a fluência de uma tradução ou a fidelidade de um resumo —, surgem lugares que o gate determinístico não alcança. E perguntar a um único LLM sobre esse resíduo, “isto está bom?”, é justamente o LLM-as-Judge que matamos na Parte 1 (bajulação·mesmo ponto cego·degradação multiplicativa).
A resposta é enxergar o gate como uma cascata de verificação. Assim como a extração vai das etapas mais baratas para as demais, a verificação também tem camadas:
Layer 1 verificação por máquina (determinismo) barata e certeira. A única autoridade para travar o PASS
Layer 2 verificação por IA (independência projetada) o resíduo aberto que o determinismo não alcança. Só autoridade de FLAG/REVIEW
Layer 3 pessoa o último palmo que ambos deixaram passar
A proporção de mistura difere por domínio — em código, a L1 é quase tudo; em tradução, L1 (vazamento·terminologia·números·estrutura) + resíduo de L2 (fluência·sentido); em criação·estratégia, quase não há L1 e predominam L2+L3.
A assimetria de autoridade protege a espinha dorsal. Coloca-se a IA na verificação, mas não se lhe dá a autoridade da conclusão:
| Verificação | Autoridade |
|---|---|
| verificação por máquina (L1) | a única autoridade para travar a “conclusão”. O determinismo julga o PASS |
| verificação por IA (L2) | apenas levanta suspeita (FLAG/REVIEW/FAIL). Não concede a conclusão |
O que o determinismo pode aprovar, é o determinismo que trava, e a IA só faz “o que o determinismo não viu está estranho → mande para REVIEW”. É a cética dentro do gate, não a árbitra. (Apenas em domínios puramente abertos, sem qualquer máquina para verificar, a IA+pessoa carregam o PASS, e aí é preciso satisfazer obrigatoriamente as premissas de independência abaixo.)
Condições de entrada da verificação por IA. No instante em que você coloca a IA no gate, a verificação por IA sem independência vira um consenso de alucinação. Imponha quatro coisas:
- Independente do gerador — outro modelo, e/ou outra entrada. (Na verificação de tradução, a back-translation que olha o texto traduzido e não o original — por ser outra entrada, o erro é estruturalmente independente. Cotejar, com âncoras de fato, se o fato sobrevive ao ida-e-volta faz a verificação aberta descer até um cotejo determinístico.)
- Vem depois do determinismo — o que a L1 consegue pegar não se delega à IA. Não delegue o barato e certeiro ao caro e instável.
- Múltipla + limiar — proibido julgador único. Maioria de modelos heterogêneos pouco correlacionados.
- Reconhecer a não-determinação — a IA oscila até com T=0. Não trava o PASS, roteia para REVIEW.
A verificação por IA não é uma nota, mas yes/no decompostos. “Qualidade de 1 a 10” é tão difícil quanto a geração e está correlacionado com o gerador. Quebre em perguntas independentes estreitas, mais fáceis de verificar do que de gerar — “há alguma frase não natural entre estas? se houver, liste” / “foi adicionada alguma alegação ausente no original?” / “algum fato desapareceu após a tradução de ida-e-volta?”. Quanto mais estreito, mais independente, e a saída vira um fato com localização que funciona como gradient signal, igual ao feedback da L1.
Em resumo — o determinismo segura a autoridade da conclusão, a IA, como cética com independência projetada, raspa com yes/no estreitos os lugares que o determinismo não alcança, e a pessoa só olha o resíduo que ambos deixaram passar. Não é que “a verificação deve ser determinística” enfraqueça, mas que o determinismo, segurando a autoridade do julgamento de conclusão, estende seu alcance até os domínios abertos.
Loop do agente
1. criar a sessão com scan (a pessoa, 1 vez)
2. ao agente: "rode o loop até completar next"
┌──────────────────────────────────────┐
│ next → próxima quest + prompt │
│ ↓ │
│ o agente gera (busca·julga·escreve) │
│ ↓ │
│ submit → gate.Check() │
│ ↓ │
│ PASS? → bloqueia, ao próximo │
│ FAIL? → retenta com feedback Fact │
│ (excede MaxTries → DONE) │
└──────────────────────────────────────┘
3. TODO == 0 → para. export.
O prompt que se dá ao agente pode ser esta única linha:
Faça o subagente rodar o loop até completar
<cli> next.
Como, quando o FAIL volta, o Fact (posição·esperado·real) vai junto, quanto mais bajulador o modelo, mais docilmente aceita o fato e converge (o “a bajulação é um ativo” da Parte 1). Gate determinístico + LLM bajulador = um loop com convergência garantida.
Três condições de convergência (cumpra obrigatoriamente)
- O feedback deve ser fato determinístico. Não “isto está meio estranho”, mas “line 41: expected ‘user_id’, got ‘userId’”.
- O exemplo deve estar no contexto. Só feedback não basta. Coloque no prompt que
nextemite um exemplo dizendo “produza um resultado com esta cara”. O gargalo não é inteligência, é contexto. - Passar na verificação é irreversível. O dente do ratchet. PASS trava. Não é o agente que declara “concluí”, é o gate que julga “esta quest passou”.
Trocar o verificador faz dela outra ferramenta
O Quest CLI não está atrelado a um gate específico. Basta trocar o gate e ela vira outra ferramenta.
| Quest + gate | Ferramenta |
|---|---|
quest + go test + coverage | geração de testes unitários de função (tsma) |
| quest + validator de regras estruturais | organização da estrutura de código (filefunc) |
| quest + hurl pass/fail | verificação de endpoints de API (huma) |
| quest + verificação cruzada de especificação | consistência de SSOT (yongol) |
O padrão é um só. O gate determina o domínio.
Part 4 — Exemplo trabalhado: huma
huma (/pt/tech/huma/) é um Quest CLI que força que cada endpoint de uma especificação OpenAPI seja verificado por um teste Hurl. O projeto scan/next/verify desta matéria veio do protótipo do huma — por isso huma é o exemplo trabalhado mais limpo. O vibe coding pula endpoints silenciosamente; huma bloqueia esse encerramento prematuro com um gate.
1 quest = 1 endpoint. As verificações determinísticas do gate:
- Formato: sintaxe Hurl válida
- Blacklist: teste vazio sem nenhuma asserção → FAIL
- Teste fraco (só código de status, não o body) → REVIEW (proibido passar silenciosamente)
- ★ Execução real ★ →
hurl --testrealmente atinge o endpoint, deve passar → PASS (prova que o teste é real, bloqueia alucinação) - Correspondência do contrato de resposta → FAIL se a resposta divergir do status/campos-chave do esquema OpenAPI
Os passos 4 e 5 são o cerne da defesa contra cheese. Mesmo que a IA apenas alegue “escrevi o teste” ou o falsifique com um único assert status == 200, o gate roda Hurl de verdade e reverifica o contrato de resposta. A geração é da IA, o julgamento é da máquina. A IA escreve o teste, mas não tem autoridade alguma sobre a conclusão.
Os comandos são exatamente como na Parte 3:
go build -o huma .
./huma scan openapi.yaml # lista de endpoints → session
./huma next # próximo endpoint + prompt para o agente
./huma submit --endpoint "POST /orders" \
--test "orders_post.hurl" # o teste Hurl que o agente escreveu
./huma status # situação do progresso
./huma export # relatório de cobertura (PASS/não coberto por endpoint)
A execução se faz no Claude Code com uma linha:
Faça o subagente escrever testes para cada endpoint até esgotar
huma next.
O subagente repete o loop next → escrever teste → submit até TODO chegar a 0. O agente não pode pular um endpoint difícil — next não entrega o próximo enquanto o gate não o aprovar.
Isto mostra o cerne do padrão. Troque apenas o gate (go test→hurl→verificação cruzada de esquema) e as mesmas cinco partes, a mesma máquina de estados, viram uma ferramenta inteiramente diferente. Na Parte 5 você faz o mesmo para o seu próprio domínio.
Part 5 — Construa o seu Quest CLI
Planilha de design
Preencha as lacunas e isso já é a especificação.
Domínio: [o que se coleta/processa]
Unidade de 1 quest: [o que é uma quest — 1 empresa? 1 função? 1 endpoint?]
Entrada: [o que scan vai ler — Excel? diretório? lista?]
Condição de fim: [condição que a máquina pode responder com sim/não]
Itens do gate: [o que é "um fato" no domínio — itens a reverificar]
- Verificação de formato: [...]
- Defesa contra cheese: [como o agente vai burlar? a reverificação que bloqueia isso]
- Condição REVIEW: [casos ambíguos a enviar para uma pessoa]
Feedback (Fact): [localização·esperado·real a devolver no FAIL]
Exemplo: [amostra de "resultado com esta cara" para o prompt de next]
Formato de export: [preservação do original + colunas de resultado]
Condição de conclusão (o gate do próprio build)
Para que o Quest CLI feito com este texto fique “concluído” — isto é, para que este texto seja cheese-proof como ensinou — é preciso satisfazer o seguinte:
-
go buildpassa - comandos
scan / next / submit / status / exportfuncionam - máquina de estados
TODO → PASS/REVIEW/DONE, PASS imutável,remainingmonotonicamente decrescente - a verificação por máquina L1 é determinística (mesma entrada + world-state → mesmo julgamento) — a autoridade de travar o PASS é só da L1
- se houver resíduo aberto, a verificação por IA L2 é de design independente (outro modelo/entrada)·múltipla·yes/no decompostos — só autoridade de REVIEW, não pode travar o PASS
- o gate reverifica o fato, não a alegação do agente (defesa contra cheese, no mínimo 1 item — passo 4 dos 5 passos de derivação)
- consultas externas (rede·DNS) são injetadas atrás de interface — o teste opera offline com mock
- o gate de consulta externa tem 3 ramos PASS/FAIL/REVIEW (impossível confirmar = REVIEW, não FAIL)
- FAIL mantém TODO·
Tries+1,>=MaxTriesvira DONE; PASS·REVIEW·DONE não permitem ressubmissão - o feedback de FAIL é um
Factcom posição·esperado·real - a sessão é persistida em disco (resumable)
- testes unitários: gate em primeiro lugar, total de statements 90%+
-
exportnão sobrescreve o original
Instrução de build
Você dá ao agente assim:
Tomando a Parte 3 (esqueleto de comandos) deste documento como projeto e a Parte 4 (huma) como exemplo trabalhado, escreva um Quest CLI em Go baseado em cobra para o [seu domínio]. Prossiga até satisfazer toda a checklist de condições de conclusão da Parte 5. O gate deve ser obrigatoriamente determinístico e reverificar o fato, não a alegação do agente.
Os três papéis estão nesta única cena.
- Jogar a quest. Adotar e usar um gate feito por outrem — o usuário.
- Projetar a quest. Construir você mesmo o gate adequado ao seu domínio — o criador. (para onde este texto leva)
- Projetar uma quest à prova de cheese. Bloquear de antemão o ponto em que o proxy não acompanha o propósito — o designer.
A maioria para na jogada. Quem aumenta a aposta é o design, e quem impede que essa aposta se quebre é o design que bloqueia o cheese.
Da próxima vez que alguém disser “está pronto”, não retruque — pergunte: “O que é conclusão, e quem projetou a quest que a julgou?”
A geração pode ser probabilística. A verificação deve ser determinística.
Relacionados
- Who Defines ‘Done’ — projetar a conclusão como quest — a parte conceitual deste texto. conclusão=gate, cheese·Goodhart.
- Ratchet Pattern — como fazer o agente ir até o fim — a obra principal sobre o travamento unidirecional.
- Ratchet code que vira o IFEval a seu favor — convergência por feedback de fato.
- Reins Engineering — a IA com rédeas — o harness é a cerca, a quest são as rédeas.
- Topologia de feedback acima do QI do modelo — o que decide o resultado não é o modelo, é a estrutura do feedback.
- huma — o ratchet que não pula endpoints — protótipo do esqueleto de comandos (scan/next/verify).
- Pré-condições para melhorar a precisão de multiagentes LLM — por que a camada de verificação por IA (L2) só funciona se tiver independência. Fundamento teórico da cascata de verificação.
Referências
- Von Neumann, J. (1956). “Probabilistic Logics and the Synthesis of Reliable Organisms from Unreliable Components.” Automata Studies, Princeton University Press.
- Zhou, J. et al. (2023). “Instruction-Following Evaluation for Large Language Models.” arXiv:2311.07911
- Ouyang, L. et al. (2022). “Training Language Models to Follow Instructions with Human Feedback.” NeurIPS 2022. arXiv:2203.02155
- Huang, J. et al. (2024). “Large Language Models Cannot Self-Correct Reasoning Yet.” ICLR 2024. arXiv:2310.01798
- Chen, X. et al. (2024). “Teaching Large Language Models to Self-Debug.” ICLR 2024. arXiv:2304.05128
- Yang, J. et al. (2024). “SWE-agent: Agent-Computer Interfaces Enable Automated Software Engineering.” NeurIPS 2024.
- Jimenez, C. et al. (2024). “SWE-bench: Can Language Models Resolve Real-World GitHub Issues?” ICLR 2024. arXiv:2310.06770
- Zhou, S. et al. (2023). “WebArena: A Realistic Web Environment for Building Autonomous Agents.” arXiv:2307.13854
- Cemri, M. et al. (2025). “Why Do Multi-Agent LLM Systems Fail?” arXiv:2503.13657
- Sharma, M. et al. (2024). “Towards Understanding Sycophancy in Language Models.” ICLR 2024. arXiv:2310.13548
- Fanous, A. et al. (2025). “SycEval: Evaluating LLM Sycophancy.” AAAI/ACM AIES 2025. arXiv:2502.08177
- Shapira, I. et al. (2026). “How RLHF Amplifies Sycophancy.” arXiv:2602.01002
- Ibrahim, L. et al. (2026). “Training Language Models to Be Warm Can Reduce Accuracy and Increase Sycophancy.” Nature 652, 1159-1165.
- Panickssery, A., Bowman, S., & Feng, S. (2024). “LLM Evaluators Recognize and Favor Their Own Generations.” NeurIPS 2024. arXiv:2404.13076
- Stechly, K., Valmeekam, K., & Kambhampati, S. (2024). “On the Self-Verification Limitations of Large Language Models.” arXiv:2402.08115
- McKee-Reid, L. et al. (2024). “Honesty to Subterfuge: In-Context RL Can Make Honest Models Reward Hack.” arXiv:2410.06491
- Bondarenko, A. et al. (2025). “Demonstrating Specification Gaming in Reasoning Models.” arXiv:2502.13295
- Thaman, K. (2026). “Reward Hacking Benchmark: Measuring Exploits in LLM Agents with Tool Use.” arXiv:2605.02964
- Deque Systems (2021). “Automated Testing Study Identifies 57 Percent of Digital Accessibility Issues.”
Changelog
- 2026-06-03: primeira edição (integração de 7 textos do corpus + huma, exemplo trabalhado). Reforço de revisão — 5 passos de derivação do gate de domínio, 3 ramos de determinismo·rede, seam
Fetcher, regras de transição de estado. - 2026-06-03: «Cascata de verificação» criada — modelo de 2 camadas verificação por máquina (L1, autoridade de PASS) + verificação por IA (L2, design independente·autoridade de REVIEW) + pessoa (L3) e assimetria de autoridade. Generaliza “gate = determinismo only” até os domínios abertos.
- 2026-06-05: comail foi retirado (tornado privado) devido ao risco de facilitação de atividade ilegal. O exemplo prático foi substituído por huma.