 Image generated by Google Gemini
Image generated by Google Gemini
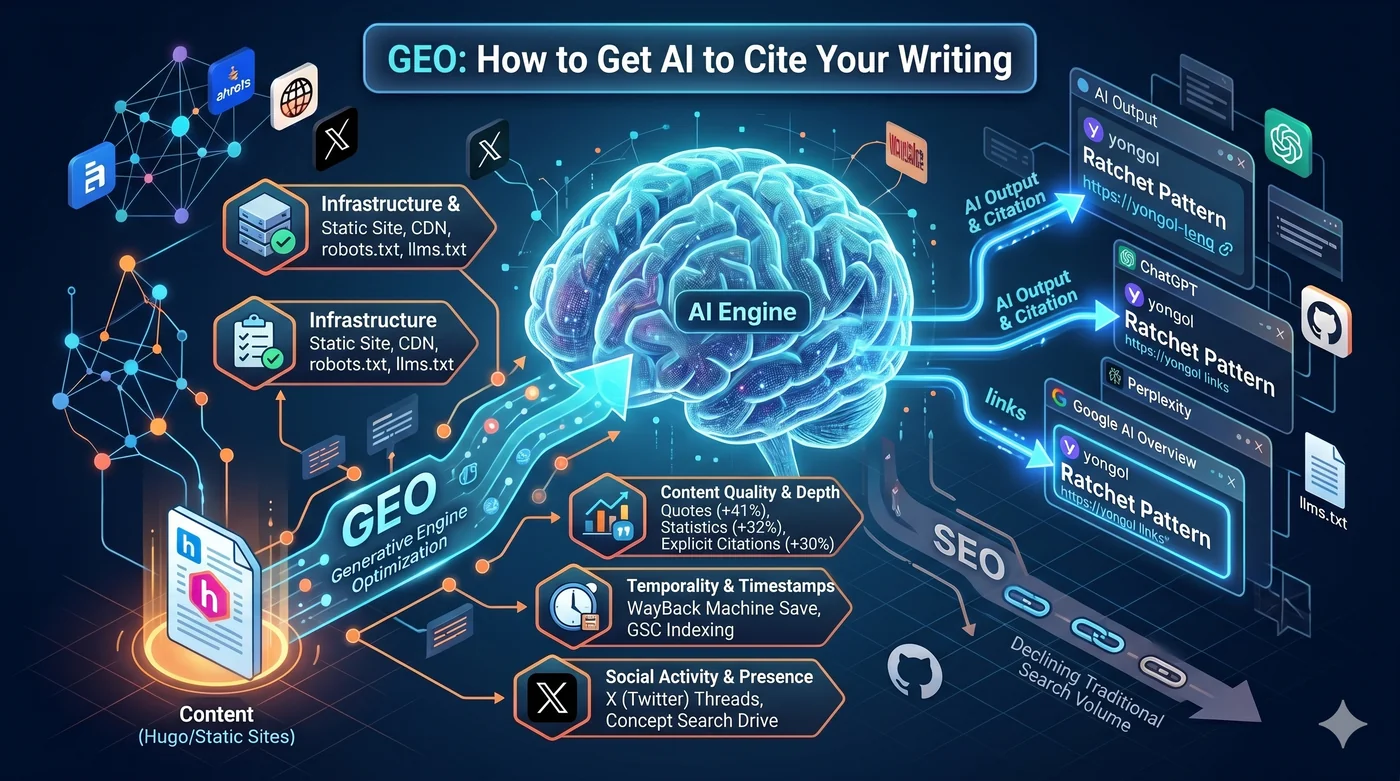
GEO (Generative Engine Optimization) é uma estratégia para otimizar conteúdo de modo que motores de busca com IA como ChatGPT, Perplexity e Google AI Overview o citem. Se o SEO tradicional era o jogo de subir no ranking do Google, GEO é o jogo de ser incluído como fonte nas respostas geradas por IA. Também é conhecido como AEO (Answer Engine Optimization), AI SEO ou otimização para buscas LLM.
A busca mudou — O início da era do AI SEO
Você pesquisava no Google e apareciam 10 links azuis. Agora a IA gera a resposta. ChatGPT, Perplexity, Google AI Overview — os usuários obtêm respostas sem clicar em nenhum link.
A Gartner prevê que até 2026 o volume de busca tradicional diminuirá 25%. Já 31,3% da população dos EUA usa busca com IA generativa.
O problema é este: Se o seu conteúdo não é citado nas respostas geradas por IA, é como se não existisse.
Generative Engine Optimization (GEO) são as regras deste novo jogo.
GEO vs SEO vs AEO — Qual a diferença
O SEO tradicional era um jogo de ranking no Google. Palavras-chave, backlinks, meta tags. GEO é um jogo diferente.
| SEO | GEO | |
|---|---|---|
| Objetivo | Ranking na SERP | Citação em respostas de IA |
| Métrica de sucesso | Impressões, cliques, CTR | Taxa de citação, frequência de recomendação de marca |
| Sinal-chave | Backlinks, palavras-chave | Clareza de entidade, citação de fontes, consistência multiplataforma |
| Modelo de tráfego | Clique → visita ao site | Zero-click (consumo sem visita) |
Dados surpreendentes: 83% das citações do AI Overview vêm de páginas fora do top 10 orgânico do Google. 28,3% das páginas mais citadas pelo ChatGPT têm visibilidade orgânica 0 no Google. Ranking SEO tradicional e citações de IA são jogos separados.
Então, o que a IA cita?
1. Infraestrutura: Hugo + CloudFront + robots.txt + llms.txt
Se os crawlers de IA não conseguem acessar seu conteúdo, não haverá citação. A primeira condição é a infraestrutura técnica.
Gerador de sites estáticos (Hugo) + S3 + CloudFront
- HTML estático é a fonte mais rápida e limpa para crawlers. SPAs exigem renderização JavaScript, e crawlers de IA frequentemente as ignoram
- CloudFront CDN garante respostas rápidas de qualquer lugar do mundo. Crawlers de IA também usam velocidade como sinal
- O build multilíngue do Hugo gera automaticamente tags hreflang. 12 idiomas = 12 pontos de entrada
Sitemap
O sitemap XML é básico. Mas na era GEO são necessárias mais duas coisas:
llms.txt— Um arquivo Markdown colocado na raiz do site. Se o robots.txt diz “onde rastrear”, o llms.txt orienta sobre “qual conteúdo é importante”. Anthropic, Hugging Face e Perplexity já adotaram- Schema.org JSON-LD — Schemas Article, Person, SoftwareSourceCode. É como entregar ao crawler de IA uma ficha resumo sobre “o que é esta página”
Permitir explicitamente crawlers de IA no robots.txt:
Em 2026, os principais bots crawlers de IA se dividem em 5 categorias:
| Categoria | Descrição | Impacto ao bloquear |
|---|---|---|
| Crawlers de treinamento | Coletam dados de treinamento para LLM | Exclusão do conhecimento de longo prazo do modelo |
| Indexadores de busca | Índice para respostas de busca IA | Desaparecimento dos resultados de busca IA |
| Recuperação por usuário | Fetch em tempo real diante de perguntas | Não referenciável em conversas |
| Agentes | IA que navega a web pelo usuário | Exclusão de serviços de agentes |
| Coleta de dados | Coleta massiva de dados web | Exclusão do dataset correspondente |
Lista de bots principais:
| Bot | Proprietário | Uso |
|---|---|---|
| GPTBot | OpenAI | Treinamento de modelos |
| OAI-SearchBot | OpenAI | Indexação de busca ChatGPT |
| ChatGPT-User | OpenAI | Recuperação em tempo real do usuário |
| ClaudeBot | Anthropic | Treinamento de modelos |
| Claude-SearchBot | Anthropic | Indexação de busca Claude |
| Claude-User | Anthropic | Recuperação em tempo real do usuário |
| Google-Extended | Treinamento do Gemini | |
| Applebot-Extended | Apple | Treinamento do Apple Intelligence |
| Meta-ExternalAgent | Meta | Treinamento do Llama + Meta AI |
| PerplexityBot | Perplexity | Busca IA |
| bingbot | Microsoft | Bing + Copilot |
| CCBot | Common Crawl | Dataset aberto (usado por quase todos os LLMs) |
| Bytespider | ByteDance | Treinamento do Doubao (ignora robots.txt, recomenda-se bloquear) |
Ponto-chave: É preciso distinguir entre bots de treinamento e bots de busca/recuperação. Mesmo bloqueando os bots de treinamento, se permitir os de busca, você continuará sendo citado nas respostas de IA. Se bloquear ambos, desaparece do mundo da IA.
llms.txt — Se o robots.txt diz “onde rastrear”, o llms.txt orienta sobre “qual conteúdo é importante”. Baseado em Markdown, colocado na raiz do site. Anthropic, Hugging Face e Perplexity já adotaram. Remove o ruído de menus/anúncios/scripts e fornece conteúdo refinado adaptado à janela de contexto da IA.
2. Sitemaps e hreflang: o mapa semântico que a IA lê
Um sitemap tradicional é uma lista de URLs. O sitemap da era GEO é um mapa semântico.
<url>
<loc>https://www.parkjunwoo.com/opinion/reins-engineering/</loc>
<lastmod>2026-05-27</lastmod>
<changefreq>weekly</changefreq>
</url>
Além disso:
- Links hreflang: 12 versões linguísticas do mesmo artigo interligadas. A IA valoriza muito a autoridade multilíngue
- Precisão do lastmod: 76,4% das citações de IA vêm de páginas atualizadas nos últimos 30 dias. Conteúdo com menos de 3 meses tem 3 vezes mais probabilidade de ser citado. Falsificar o lastmod gera efeito contrário
- Estrutura de categorias:
/opinion/,/tech/,/lecture/— uma hierarquia significativa fornece mais contexto à IA do que uma estrutura plana
Enviar o sitemap ao Google Search Console é o básico. Mas só isso não basta.
3. Wayback Machine e Google Search Console: prova de originalidade do conteúdo
O Wayback Machine arquiva snapshots da web desde 1996. Para a IA, isso é memória temporal.
Por que importa:
- Se você publicou o artigo que definiu “Ratchet Pattern” pela primeira vez em maio de 2026, o Wayback Machine preserva esse snapshot
- Mesmo que 6 meses depois alguém use o mesmo conceito em uma plataforma maior, a evidência temporal aponta para o autor original
- Quando a IA determina a fonte, o momento da primeira publicação funciona como sinal indireto de autoridade
Execução:
- Após publicar um artigo novo, solicitar manualmente o salvamento no Wayback Machine (
web.archive.org/save/) - Solicitar a indexação da URL no Google Search Console
- Ambos os locais ficam carimbados com marca temporal
Observação: em 2026, 241 sites bloquearam o acesso ao Wayback Machine (por preocupações com evasão de direitos autorais por empresas de IA). Para blogs pessoais, isso é na verdade uma oportunidade — com a saída dos grandes veículos do arquivo, o peso relativo do conteúdo pessoal aumenta.
4. Citação de fontes e autoridade temática: as condições do conteúdo em que os LLMs confiam
As 3 principais estratégias de melhoria de visibilidade segundo o paper original do GEO (Aggarwal et al., KDD 2024):
| Estratégia | Melhoria de visibilidade |
|---|---|
| Adicionar citações textuais (Quotation) | +41% |
| Adicionar estatísticas (Statistics) | +32% |
| Citar fontes (Cite Sources) | +30% |
Keyword stuffing é irrelevante ou contraproducente no GEO. A IA não busca palavras-chave, busca evidências.
Por que a citação acadêmica importa:
- A IA distingue entre “afirmações” e “afirmações com evidência”. “42% do tempo dos desenvolvedores é consumido em dívida técnica” é uma afirmação. “42% do tempo dos desenvolvedores é consumido em dívida técnica (Stripe, The Developer Coefficient, 2018)” é evidência
- Frases com evidência têm custo de confiança menor quando a IA as cita em suas respostas. Frases sem evidência requerem verificação, então a IA as ignora
- Sites citados por 4 ou mais plataformas de IA têm 2,8 vezes mais aparições no ChatGPT
Gestão de artigos relacionados e tags:
Tags não são para pessoas. São para a IA.
- Sistema de tags consistente: “Reins Engineering”, “Ratchet Pattern”, “SSOT” — quando as mesmas tags se repetem em vários artigos, a IA reconhece autoridade temática (topical authority)
- Links internos: vincular artigos relacionados dentro do texto permite que crawlers de IA identifiquem clusters temáticos. Artigos conectados são mais citados do que isolados
- Citação cruzada: citar entre seus próprios artigos também é válido. “A base deste conceito foi definida em Ratchet Pattern”
5. X, Reddit, Hacker News: estratégias sociais para gerar volume de busca de marca
Os termos de uso do X/Twitter proíbem explicitamente o treinamento de IA por terceiros. Ou seja, o que você publica no X não entra diretamente nos dados de treinamento do ChatGPT.
Mas a atividade social contribui para a visibilidade perante a IA por via indireta:
O volume de busca de marca é o preditor mais forte de citação por LLM (coeficiente de correlação 0,334, superior aos backlinks).
O caminho é este:
Thread no X → Pessoas buscam "yongol" no Google → Volume de busca de marca sobe → IA reconhece "yongol" como entidade digna de citação
Os dados de maio do parkjunwoo.com comprovam isso:
- Busca de “yongol” no Google: 14 impressões, 5 cliques, posição média 3,1
- Clones do yongol no GitHub: 316 usuários únicos
- Caminho de tráfego: t.co (X) 4 pessoas → GitHub → blog
Mais do que compartilhar links diretamente no X, fazer as pessoas buscarem o conceito é mais eficaz para GEO.
O poder do earned media:
48% de todas as citações de LLM vêm de earned media (imprensa, resenhas, menções de terceiros). Conteúdo próprio representa apenas 23%. Ou seja, fazer com que outros mencionem você é 2 vezes mais eficaz do que otimizar seus próprios artigos.
Quando um projeto é mencionado no Reddit, Hacker News ou dev.to → através do crawling de IA dessas plataformas → o LLM aprende a entidade.
Checklist
Infraestrutura
├── Site estático Hugo + S3 + CloudFront
├── Permitir crawlers de IA no robots.txt
├── Criar llms.txt (curadoria de conteúdo-chave)
├── Schema.org JSON-LD (Article, Person)
└── Sitemap XML + hreflang
Conteúdo
├── Citar fontes em todas as afirmações (+30% visibilidade)
├── Inserir estatísticas inline (+32%)
├── Usar tabelas comparativas (parsing ideal para IA)
├── Manter lastmod com precisão (atualização em 30 dias → taxa de citação 76,4%)
└── Atualizar periodicamente artigos com mais de 3 meses (3x probabilidade de citação)
Conexão
├── Sistema de tags consistente (autoridade temática)
├── Links internos (clusters temáticos)
├── Citar papers/fontes externas (reduzir custo de confiança)
└── Artigo novo → Wayback Machine + envio ao GSC
Social
├── Threads no X para induzir busca do conceito (volume de busca de marca)
├── Gerar earned media no Reddit/HN
└── Difundir conceitos é mais favorável ao GEO do que compartilhar links diretos
Implementação de GEO neste site
As estratégias descritas neste artigo estão sendo executadas ativamente em parkjunwoo.com:
- robots.txt — Permissão explícita para 25 crawlers de IA, bloqueio do Bytespider
- llms.txt — Curadoria de conteúdo-chave adaptado à janela de contexto da IA
- Coleção de artigos Reins Engineering — Hub de cluster temático
- Build multilíngue em 12 idiomas — Geração automática de hreflang, um ponto de entrada por idioma
- Fontes acadêmicas em todos os artigos — Estatísticas inline + citações acadêmicas para densidade factual
- Envio imediato ao Wayback Machine + GSC ao publicar — Prova de originalidade temporal
Artigos relacionados
- Google, Optimizing your website for generative AI features on Google Search (2026) — Guia oficial do Google para otimização de busca IA
- Cyrus Shepard, AI Citation Ranking Factors Analysis — Meta-análise de 54 estudos, quantificação de 23 fatores de ranking de citação IA
- Seer Interactive, AIO Impact on Google CTR: 2026 Update — 53 marcas, 2,43 bilhões de impressões rastreadas. CTR -61% com AI Overview
- Discovered Labs, AI Citation Patterns: How ChatGPT, Claude, and Perplexity Choose Sources — Apenas 12% das citações de IA coincidem com o top 10 do Google
- Ahrefs, Generative Engine Optimization: Growth Strategies and Metrics — Análise de 300 mil palavras-chave. Menções web superam backlinks 3:1 em exposição no AI Overview
- Datos/SparkToro, State of Search Q1 2026 — Rastreamento de participação de busca IA baseado em clickstream
- Rand Fishkin, Search Happens Everywhere — Análise de 41 sites, busca não é só Google
- Go Fish Digital, GEO Case Study: 3X’ing Leads — Taxa de conversão de referência IA 25 vezes maior que busca tradicional
- Search Engine Land, How schema markup fits into AI search — Análise sem exageros do schema markup e busca IA
- Lily Ray, The Vicious Cycle of SEO — Alerta sobre a vida curta do spam GEO
Fontes
Papers
- Aggarwal et al., GEO: Generative Engine Optimization, KDD 2024 — Citações textuais +41%, estatísticas +32%, citação de fontes +30% de melhoria de visibilidade
- Xu et al., Measuring Google AI Overviews (2026) — Análise de 55.393 consultas. 30% dos domínios citados pelo AIO não estão na primeira página orgânica
- Fang et al., Recency Bias in LLM-Based Reranking, SIGIR-AP 2025 — Os 7 modelos promovem consistentemente o conteúdo mais recente
- Zhang et al., Citation Selection to Citation Absorption (2026) — Comparação quantitativa dos padrões de citação de ChatGPT/Google AIO/Perplexity
- Algaba et al., LLMs Reflect Human Citation Patterns, NAACL 2025 — LLMs preferem mais fortemente papers com mais citações (Matthew effect)
- arXiv:2602.18455, AI Search Impact on Wikipedia Traffic (2026) — AIO reduziu o tráfego da Wikipedia em 15% (análise causal DID)
- Yu et al., Structural Feature Engineering for GEO (2026) — A estrutura do conteúdo em si afeta a probabilidade de citação
- Tian et al., Diagnosing Citation Failures in GEO (2026) — Modificar 5% do conteúdo melhora a taxa de citação em 40%
- Baack, Critical Analysis of Common Crawl, FAccT 2024 — Componentes centrais e vieses dos dados de treinamento de LLM
- Strauss et al., The Attribution Crisis in LLM Search (2025) — 92% do Gemini não fornece citações clicáveis
Relatórios de dados
- Ahrefs, Do AI Assistants Prefer Fresh Content? (2025) — Análise de 17 milhões de citações de IA
- SparkToro/Datos, State of Search Q1 2026 — Rastreamento de participação de busca IA baseado em clickstream
- GitClear, AI Copilot Code Quality 2025 — Análise de 210 milhões de linhas
- Gartner — Previsão de queda de 25% no volume de busca tradicional até 2026
- Proposta de padrão llms.txt — Search Engine Land
Changelog
- 2026-05-27: Versão inicial