 Image: AI generated
Image: AI generated
O legado não mente
O código legado não tem documentação. E quando tem, é de três anos atrás. Os testes não existem, ou, se existem, estão quebrados e marcados com skip. Os comentários contradizem o código. O autor original já saiu da empresa, e quem sobrou só deixou o aviso: “se mexer, explode”.
E, no entanto, esse código está rodando neste exato momento. Processa pagamentos, recebe logins, registra pedidos.
A documentação mente. Os comentários mentem. A memória das pessoas mente ainda mais. A única coisa que não mente é o tráfego que realmente está fluindo.
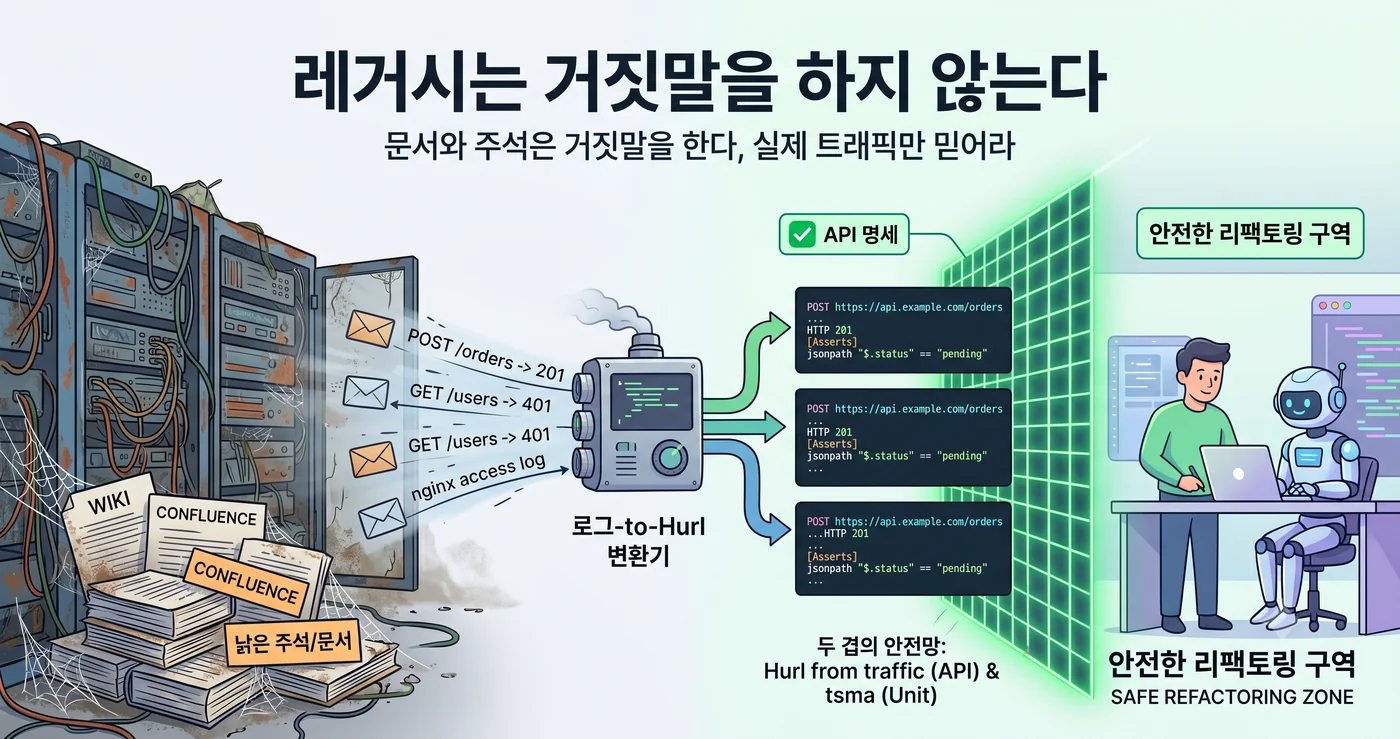
Então, onde devemos procurar a especificação? Não no wiki. Não no Confluence. No nginx access log.
O ovo e a galinha
Para refatorar o legado, você precisa de uma rede de segurança. Quando você muda alguma coisa, precisa saber na hora se o comportamento mudou. Essa rede de segurança é, justamente, o teste.
Mas o legado não tem testes. Para escrever testes, você precisa saber o que o código faz. Para saber o que o código faz, precisa lê-lo. E ao lê-lo, descobre que não há nem testes nem documentação.
O que vem primeiro, o ovo ou a galinha? É o impasse clássico que Michael Feathers batizou em Working Effectively with Legacy Code. Como resposta, ele propôs o characterization test (teste de caracterização) — um teste que não fixa o que o código deveria fazer corretamente, mas o que ele de fato faz agora. Certo e errado ficam para depois. Primeiro é preciso fixar o comportamento atual para poder pôr a mão.
Na época de Feathers, isso era escrito à mão. Você chamava a função, observava o valor que saía e o transcrevia literalmente para o expected. Tedioso, lento e, por isso, ninguém levava até o fim.
Mas, no nível da API, esse “resultado de ter chamado a função” já está acumulado em algum lugar. Todos os dias, aos milhares. Dentro dos arquivos de log.
Um mês de logs é a especificação
Coletando durante um mês, é possível capturar quase todo o comportamento atual de uma API legada.
nginx access log (1 mês):
endpoint · HTTP method · status code · timing
frequência de chamadas → prioridade
padrões de erro (401, 422, 500 …)
request/response body (capturado via middleware ou reverse proxy):
pares requisição/resposta normais → comportamento que deve passar
pares requisição/resposta de erro → edge cases que não podem quebrar
Unindo essas duas vertentes, traduz-se diretamente em testes de integração Hurl. Hurl é um formato que escreve a requisição HTTP e a resposta esperada literalmente, em texto puro. Um par de tráfego — “para esta requisição saiu esta resposta” — é exatamente um bloco Hurl.
# POST /api/orders — frequência de chamadas #3, 12 mil por dia
POST https://api.example.com/orders
Content-Type: application/json
{ "sku": "A-1024", "qty": 2 }
HTTP 201
[Asserts]
jsonpath "$.order_id" exists
jsonpath "$.status" == "pending"
jsonpath "$.total" == 49800
Esse teste não sabe “como a API de pedidos deveria funcionar”. Ele apenas sabe que “agora ela funciona assim”. E isso basta. No instante em que a refatoração mudar essa resposta, a luz vermelha acende.
O que se deriva automaticamente dos logs:
- Quais endpoints são realmente usados → um endpoint chamado 0 vez em um mês é código morto. Candidato a exclusão antes da refatoração.
- Padrões de resposta normais → testes de regressão básicos.
- Padrões de erro → os edge cases verdadeiros que ninguém consegue imaginar. São os 422 e 500 que usuários reais produziram.
- Frequência de chamadas → prioridade dos testes. Começa-se pelo que tem 12 mil chamadas por dia.
O último item é importante. Quando uma pessoa escreve testes, começa pelo happy path que ela lembra. O tráfego não tem esse viés. O caminho que de fato recebe carga é, por si só, a prioridade.
Uma rede de segurança em duas camadas
Esta abordagem não é usada de forma isolada; é uma camada do pipeline ratchet que eleva o legado a agent-operable.
nginx log (1 mês) → geração automática de Hurl → fixa o comportamento atual da API legada
↓
tsma → rede de segurança em nível de função (unit)
↓
filefunc → organização da estrutura do código (um conceito por arquivo)
↓
refatoração → Hurl verifica a preservação do comportamento da API (integration)
O essencial é que a rede de segurança tem duas camadas.
- tsma = rede de segurança em nível de função. Detecta se a lógica interna mudou. Mas, mesmo com a assinatura da função intacta, o comportamento de todo o endpoint pode mudar.
- Hurl from traffic = rede de segurança em nível de API. Detecta se o contrato visto de fora é preservado. Não importa como você reescreva o interior: se o que entra de fora e o que sai para fora forem iguais, passa.
Refatoração é, por definição, “mudar a estrutura interna preservando o comportamento externo”. Sendo assim, a definição do “comportamento externo” a ser preservado precisa estar fixada em algum lugar. tsma segura a fronteira interna, e Hurl segura a fronteira externa. Só quando as duas camadas estão juntas é que se pode dizer ao agente: “reescreva à vontade; o que quebra, a máquina vê”.
Um árbitro que não sabe bajular
Isso se encaixa exatamente com a essência do Symbolic Feedback Loop.
Se você perguntar ao agente “refatorou bem?”, ele responde “sim, organizei tudo de forma limpa”. Quando se pede uma opinião, ele bajula. Mas, ao rodar o Hurl, sai POST /orders → expected 201, got 500. Números e status codes não bajulam. Porque não têm emoção.
O teste Hurl extraído do tráfego é uma especificação sem a intervenção do julgamento humano. Não é “alguém acha que deveria funcionar assim”, e sim “a observação mostrou que funcionou assim”. Não é uma afirmação, é uma medição. Por isso, quem julga o certo e o errado da refatoração pode ser a máquina, e não a pessoa. O LLM não é o juiz, e sim o executor, e o julgamento cabe a uma ferramenta determinística.
A única premissa: logs bem registrados
Para que este método funcione, basta uma coisa. Um mês de logs bem registrados.
E “bem registrados” é tudo. O access log sozinho não basta. Ele dá o endpoint, o status code e o timing, mas não dá o cerne a ser fixado — o par de request body e response body. Saber apenas POST /orders → 201 não permite reproduzir “para esta entrada saiu esta saída”. Para fixar a funcionalidade, é preciso ter em mãos tanto o que entrou quanto o que saiu.
Então a verdadeira pergunta não é “como escrever os testes”, e sim “meus logs estão escritos bem o bastante para serem uma especificação”.
- O request/response body é registrado, ou só fica o status code?
- As respostas de erro também são registradas? Os bodies de 422 e 500 são justamente os edge cases que ninguém consegue imaginar.
- O log é estruturado o bastante para que a máquina consiga emparelhar requisição e resposta?
Se isso estiver pronto, você já vinha escrevendo a especificação havia um mês. Não há necessidade de escrever testes à parte. O pipeline de logs já os escrevia por você. Se não estiver pronto, basta encaixar uma camada de middleware agora e deixá-la ligada por um mês. Um mês depois, todo o comportamento atual do legado estará na sua mão.
Por que um mês, e não um dia? Um dia só pega o happy path. Um mês pega o batch de fim de mês, o pico de tráfego às vésperas do fechamento, os endpoints administrativos chamados raramente, o cron que roda uma única vez às 3 da manhã — a cauda longa do sistema. A especificação não é a média, é a distribuição.
Traduzir os logs em Hurl para fixar a funcionalidade
Com os logs prontos, o resto é mecânico. Você joga um mês de pares request/response na ferramenta e traduz cada par em um bloco Hurl. As centenas de arquivos Hurl assim despejados são a suíte de characterization — uma rede de segurança que fixa por inteiro o comportamento atual do legado. Você não leu uma linha de código. Leu apenas o tráfego que passou.
Vale antecipar aqui um ponto em que muita gente costuma hesitar. “Mas o log tem dados pessoais, pagamentos e tokens — pode-se fixar isso num teste?”
Pode. Mais precisamente, não é preciso fixar. Porque esta metodologia, por natureza, não precisa dos valores. O que o characterization test fixa não são os valores, é o comportamento.
HTTP 201
[Asserts]
jsonpath "$.order_id" exists
jsonpath "$.total" == 49800
Aqui, o que importa como especificação não é o número 49800, e sim a estrutura “o campo total existe como inteiro e, para uma dada entrada, é calculado assim”. Mesmo mascarando os valores ou trocando-os por dados sintéticos, o valor da especificação quase não diminui. capture → mascaramento → geração de Hurl: todo esse pipeline roda dentro da sua infraestrutura. O log raw não tem por onde sair. O que sobra é uma especificação com os valores ocultos, um contrato em que só a estrutura foi preservada. O fato de não precisar enviar o log para fora não é uma concessão de segurança, é a essência desta abordagem — porque, de início, basta fixar o comportamento.
Rodando o Hurl gerado uma vez no staging, ali mesmo se separa o que passa do que falha. Se todas as luzes verdes acenderem, agora você pode começar a refatorar. Diga ao agente para reescrever à vontade; o que quebra, o Hurl vê.
Uma escada erguida sem código
Por isso, o verdadeiro valor desta abordagem não é “escrever testes rápido”. O verdadeiro valor é este.
- Começa-se sem ler o código — o autor original foi embora e não há documentação, mas a rede de segurança se estende apenas com o tráfego que passou. Você ganha o direito de pôr a mão antes de entender o código.
- O resultado é imediatamente verificável — rodando o Hurl gerado no staging, ali mesmo sai pass/fail. Não é “deve estar funcionando”, e sim “agora passam 327 de 327”.
- Os dados não passam por cima do muro — do capture até a geração do Hurl, tudo termina dentro da minha infraestrutura. Quanto mais regulada a indústria, mais decisivo é poder começar sem mandar nada para fora.
A primeira pá da modernização do legado costuma travar no penhasco do “ninguém sabe qual é o comportamento atual”. Tráfego → Hurl ergue uma escada nesse penhasco. E, para erguer a escada, não é preciso código. Basta o tráfego que passou — e nem esse tráfego sai de dentro do muro.
O fluxo já vinha escrevendo a especificação
Nós nos esforçamos para escrever a especificação à parte. Escrevemos OpenAPI à mão, descrevemos o comportamento no wiki e, quando essas coisas divergem do código, chamamos de drift e lamentamos.
Mas o sistema vivo, a cada instante, vinha escrevendo sua própria especificação sozinho. Cada vez que uma requisição entra e uma resposta sai, isso é uma linha de autodescrição: “eu sou um sistema assim”. O arquivo de log é essa autobiografia acumulada por um mês.
Nós é que não a líamos.
O legado não é desprovido de documentação. A documentação está dentro do access log, só que num formato incômodo de ler para humanos. Traduzida em Hurl, ela se torna uma especificação executável, um contrato julgado pela máquina.
A documentação mente. O tráfego não mente.
Fontes / Fundamentação
Conceitos e ferramentas centrais
- Michael Feathers. Working Effectively with Legacy Code. Prentice Hall, 2004. — Origem do conceito de characterization test. “Fixa-se não o que o código deveria fazer corretamente, mas o que ele faz agora.”
- Projeto Hurl (hurl.dev) — Formato de teste de requisição/resposta HTTP em texto puro. Integrado como uma das 10 SSOTs do yongol.
- Comprovação com 527 funções no tsma — ratchet em nível de função (tsma).
Extrair testes a partir do tráfego e da execução (carving / record-replay)
- Elbaum, Chin, Dwyer, Jorde (2009). “Carving and Replaying Differential Unit Test Cases from System Test Cases.” IEEE TSE 35(1). — Base acadêmica dos differential unit tests que fazem record da execução do sistema e replay em nível de unidade.
- Meta Engineering Team (2024). “Observation-based Unit Test Generation at Meta.” FSE 2024, arXiv:2402.06111. — Carving de testes a partir de observações da execução do app. 9,6 milhões de execuções no CI, 5.702 defeitos detectados. Comprovação em escala industrial de “a observação é o teste”.
Fixar o comportamento atual (snapshot / golden master)
- Fujita, Kashiwa, Lin, Iida (2023). “An Empirical Study on the Use of Snapshot Testing.” ICSME 2023. — Comprovação da adoção de testes snapshot (= golden master/characterization). “Detecta-se a mudança fixando não a correção, mas a saída atual.”
Rede de segurança da refatoração
- Kim, Zimmermann, Nagappan (2014). “An Empirical Study of Refactoring Challenges and Benefits at Microsoft.” IEEE TSE 40(7). — Comprovação de que, sem testes que garantam a preservação do comportamento, a refatoração é custo e risco.
- Yoo, Harman (2012). “Regression Testing Minimization, Selection and Prioritization: A Survey.” STVR 22(2). — Teste de regressão = a definição padrão de “a confiança de que a mudança não fere o comportamento existente”.
A distribuição de uso real é a prioridade
- John D. Musa (1993). “Operational Profiles in Software-Reliability Engineering.” IEEE Software 10(2). — Ao distribuir os testes por frequência de uso, mesmo interrompendo por questões de cronograma, a funcionalidade mais usada é a mais verificada. Base clássica de “distribuição de tráfego em vez do viés do happy path”.
Por que a máquina deve julgar (o LLM não é o juiz, e sim o executor)
Huang, Chen, Mishra, et al. (2024). “Large Language Models Cannot Self-Correct Reasoning Yet.” ICLR 2024, arXiv:2310.01798. — Sem feedback externo, o LLM não corrige o próprio raciocínio. A razão de ser necessário um verificador externo determinístico.
Sharma, Tong, et al. (2024). “Towards Understanding Sycophancy in Language Models.” ICLR 2024, arXiv:2310.13548. — O RLHF ensina a concordância e derruba a confiabilidade do autojulgamento do LLM.
Imagem de capa: gerada por IA (Google Gemini)
Artigos relacionados
- O Hurl barra o drift — Como declarar contratos HTTP em texto puro e trancá-los no CI. Se este artigo é “tráfego → Hurl”, aquele é “trancar o drift com Hurl”.
- tsma — a linha de defesa contra regressão no código legado — A fronteira interna (nível de função) da rede de segurança em duas camadas. Se Hurl é a fronteira externa, tsma é a interna.
- Agent Operable Codebase — O pipeline de 3 etapas que eleva o legado a código operável por agentes.
- Por que os agentes de codificação funcionam e por que desmoronam — A estrutura do Symbolic Feedback Loop.
- Restrições são contratos — O teste como um contrato verificável e aplicável.
- Como salvar um vibe coding fracassado — Aula prática para diagnosticar → trancar → reparar → extrair → migrar o legado com characterization testing.
Leituras complementares
- Michael Feathers, “Characterization Testing” — Texto do criador do termo. “No instante em que o software entra em produção, ele se torna sua própria especificação (it becomes its own specification).” Quase a mesma tese do título deste artigo.
- Tutorial oficial do Hurl, “Your First Hurl File” — De
GET / HTTP 200até o modo--test. Uma introdução que coloca na sua mão a ideia de que uma linha de texto puro já é um teste. - GitHub Engineering, “Scientist: Measure Twice, Cut Once” — Biblioteca que executa simultaneamente o código legado (control) e o novo (candidate) em produção para comparar os resultados. “Só o comportamento real é a verdadeira especificação.”
- Twitter Diffy (resumo da InfoQ) — Proxy que envia a mesma requisição aos serviços novo/antigo e pega como regressão apenas a diferença nas respostas. Precedente clássico de “fixar o comportamento sem escrever testes”.
- GoReplay — Ferramenta que captura o tráfego HTTP vivo da interface de rede e o reproduz no staging. Implementação representativa de “tráfego de produção como entrada de teste”.
- Nicolas Carlo, “Characterization vs Approval Tests” — Organiza os três termos para uma técnica essencialmente igual e enfatiza o papel do “Printer”, que faz o scrub de dados sensíveis na saída.
- Pact — consumer-driven contract testing. Abordagem do “contrato explícito” em contraste com a fixação de tráfego. Olhar as duas vias juntas traz equilíbrio.