Image: AI generated
One Question
Open the longest file in your project. How many functions does it contain?
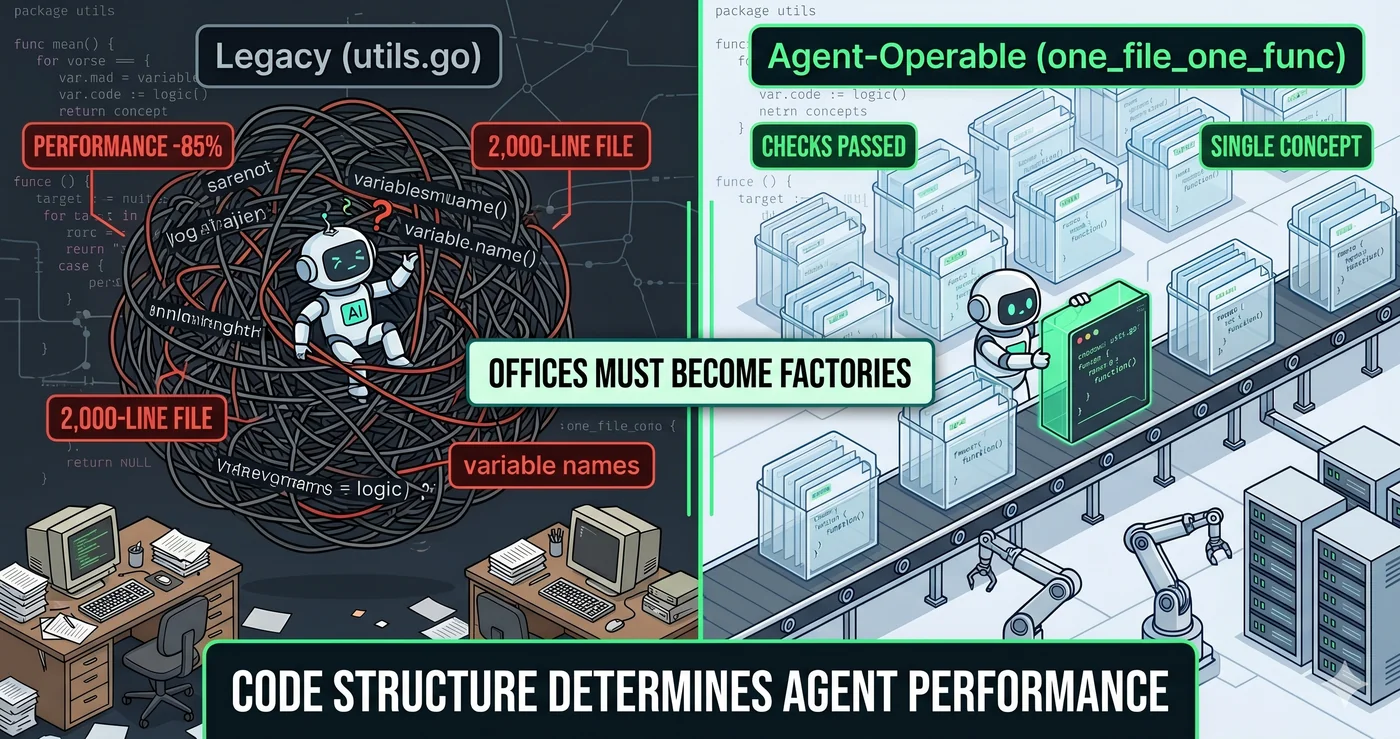
Ask an AI agent to modify one function in that file. The agent reads the entire file. It opened the file because it needed one function, but 19 unnecessary functions came along for the ride.
This is where the problem starts.
Code Humans Read, Code Agents Work With
Until now, code was something humans read. Naming variables well, adding comments, writing documentation — all of it was to reduce cognitive load for humans.
In the agent era, the question changes. Is code that is easy for humans to read the same as code that is easy for agents to work with?
It is not.
| Human | AI Agent | |
|---|---|---|
| Navigation | Scans directory tree visually | Searches with grep |
| Opening files | Scrolls in IDE | read file — loads entire file |
| Context judgment | Intuition + experience | Knows only what is in the context |
| Unnecessary code | Ignores it | Consumes context budget |
| 2,000-line file | Reads only the needed part | Processes all of it |
A human scrolling through a 2,000-line file has the intuition “don’t touch this part.” Agents have no such intuition. Reading 2,000 lines means 1,950 lines of context pollution.
Research confirms this. When irrelevant information is mixed in, AI performance drops by 30-85%. Performance degrades even when the unnecessary tokens are whitespace. Shorter context is better — this is not intuition but experimental result.
Do not put a robot in a human office. Build a factory where robots can work. METR’s randomized controlled trial shows this with numbers — 16 experienced open-source developers using AI tools on mature codebases saw completion time increase by 19%. Not faster — slower (Becker et al., 2025).
What Agents Need: Three Things
For agents to work reliably on a codebase, three things must be in place.
1. Readability — Without Noise
One file, one concept. The filename is the concept name.
before: read utils.go → 20 functions, 19 unnecessary
after: read check_one_file_one_func.go → 1 function, exactly what's needed
filefunc solves this problem. 22 structural rules separate code into semantic units. In the Hono framework (23k+ stars), 186 files were split into 626. All 4,419 tests passed. Files increased 3.4x but not a single line of logic changed.
“Won’t there be too many files?” — Agents don’t open directories. They search. Whether there are 500 or 1,000 files, one grep is all it takes. Not opening 295 unnecessary files matters more than picking the 5 you need.
2. Verifiability — Mechanically
Modifying a function without tests means nobody knows what breaks. The agent doesn’t know either. It falls into a doom loop.
before: 0 tests, no way to know what breaks on modification
after: 527 functions with tests, behavior changes detected immediately
tsma solves this problem. It indexes every function in the project, detects test presence, measures coverage, and feeds back uncovered branches with line numbers.
Without feedback, asking an LLM to write tests plateaus at 60-70% coverage. Tell it “line 41, 44, 70 uncovered” and it reaches 100%. Same model. The only difference is feedback resolution. CoverUp research confirmed the same — iteratively feeding coverage analysis to LLMs, simply focusing them on uncovered lines, jumped module coverage from 47% to 80% (Pizzorno & Berger, 2024).
In a 527-function project: completed to zero TODO. The autonomous agent declared “done” at 40. With ratchets applied, it completed all 527.
3. Cross-Verifiable Specifications
It must be mechanically confirmable whether API schemas, DB schemas, security policies, and state transitions are consistent with each other. When one changes, misalignment with others must be detectable before compilation.
before: 200 endpoints, humans check inter-spec consistency
after: operationId chains all layers, machines detect drift
yongol solves this problem. It chains 10 SSOTs (OpenAPI, DDL, sqlc, SSaC, Rego, Hurl, etc.) through a single operationId and cross-validates with ~287 rules. user_id is string in OpenAPI but BIGINT in DDL — such inter-layer contradictions cannot be caught by existing tools.
One Structure Running Through Three Tools
filefunc, tsma, yongol are independent tools but share a common structure.
filefunc: 22 structural rules → validate → fix → repeat
tsma: coverage measurement → uncovered branch feedback → fix → repeat
yongol: cross-validation → drift detection → fix → repeat
All the same loop.
LLM generates → deterministic tool judges → result fed back to LLM → repeat
Symbolic Feedback Loop. A circular structure where deterministic tools correct the LLM’s probabilistic generation. Not AI verifying AI, but machines verifying AI.
Give it opinions and it flatters; give it facts and it corrects. Ask “is the code okay?” and it answers “yes, looks good.” Tell it “line 41: field name mismatch” and it fixes immediately. Feedback with nothing to flatter — numbers and positions are not emotions.
From Legacy to Agent-Operable
No need to change an existing codebase all at once. This is not foundation work but seismic retrofitting. Reinforcing the building without closing the operating store.
Step 1 — Make it readable
Split the longest files first. Run filefunc validate and bring violations to zero. All existing tests must pass.
Step 2 — Make it verifiable
Repeat tsma next. Add tests to untested functions, fill uncovered branches. If the agent dies mid-way, progress is preserved. A new agent runs tsma next and continues.
Step 3 — Cross-validate
Introduce SSOTs and apply yongol validate. Machines catch inter-layer contradictions.
Each step is independent. You can do step 2 without step 1, or step 1 without step 2. But when all three combine, the scope of autonomous agent work expands dramatically.
Changing the Operating System
An agent-operable codebase is not mere linting or tooling. It is changing the operating system of the codebase.
| human-readable | agent-operable | |
|---|---|---|
| File size | Human-scrollable range | One concept |
| Tests | Nice to have, intuition fills gaps | Required for every function |
| Specs | Documents, wikis, verbal communication | Declarative, cross-verifiable, machine-readable |
| Feedback | PR review (hours) | Verifier execution (seconds) |
| Termination judgment | Human says “done” | Machine says “487 remaining” |
GitClear’s analysis shows the urgency of this transition — analyzing 211 million changed lines from 2020-2024, code duplication increased 8x and refactoring ratio dropped from 25% to 10% alongside AI tool proliferation (GitClear, 2025). Without laying tracks, faster trains mean more accidents.
Many people are making trains faster. Bigger models, smarter agents, better prompts.
The faster trains go, the more tracks matter. Almost no one is laying tracks.
Artigos relacionados
- filefunc — One File, One Concept — 22 structural rules that eliminate LLM context pollution
- tsma — Legacy Code Regression Defense Line — Ratchet-based test automation that completed 527 functions to zero TODO
- Why Coding Agents Work and Why They Break — Structural analysis of the Symbolic Feedback Loop
- Feedback Topology Over Model IQ — Why the same model stalls at 40 or completes 527
- whyso — What git blame Doesn’t Show — Automatic file-level change history extraction
Evidências de suporte
- Stanford, “Lost in the Middle: How Language Models Use Long Contexts” (2024) — 30%+ performance drop when relevant information is buried in the middle of context
- Amazon, “Context Length Alone Hurts LLM Performance” (2025) — 13.9-85% performance drop even when unnecessary tokens are whitespace
- Hono framework validation — 186 files → 626 file split, all 4,419 tests passed
- tsma 527-function validation — PASS 246 (46.7%), DONE 281 (53.3%), TODO 0
- Ratchet Pattern experiment — autonomous agent 40/527 (7.6%) vs ratchet CLI 527/527 (100%)
Referências
- Joel Becker, Nate Rush, Elizabeth Barnes, David Rein. “Measuring the Impact of Early-2025 AI on Experienced Open-Source Developer Productivity.” arXiv:2507.09089, 2025. — 16-developer RCT, AI tools on mature codebases increased completion time by 19%
- GitClear Research. “AI Copilot Code Quality Report.” 2025. — 211M changed lines analyzed, 8x code duplication increase with AI tools, refactoring ratio 25%→10%
- Juan Altmayer Pizzorno, Emery D. Berger. “CoverUp: Coverage-Guided LLM-Based Test Generation.” arXiv:2403.16218, 2024. — Coverage feedback iteration achieved 47%→80% module coverage
- Kelly Hong, Anton Troynikov, Jeff Huber. “Context Rot: How Increasing Input Tokens Impacts LLM Performance.” Chroma Technical Report, 2025. — Performance degradation with increasing input tokens demonstrated across 18 models
- Mrinank Sharma et al. “Towards Understanding Sycophancy in Language Models.” ICLR 2024 (arXiv:2310.13548). — Sycophancy behavior analysis across 5 AI assistants
- Google DORA Team. “Accelerate State of DevOps Report.” 2024. — 7.2% delivery stability decrease alongside 25% AI adoption increase
- Dantas et al. “The 4/δ Bound: Designing Predictable LLM-Verifier Systems for Formal Method Guarantee.” arXiv:2512.02080, 2025. — Mathematical convergence upper bound proof for LLM-verifier iteration loops
Changelog
- 2026-05-25: Versão inicial