 Image: AI generated
Image: AI generated
똑똑한 사람이 설명을 잘하는 건 아니다
Opus 4.8에게 코드 리팩토링을 시키면 감탄이 나온다. 복잡한 의존성 그래프를 한 번에 풀고, 엣지 케이스를 선제적으로 처리하며, 테스트까지 빈틈없이 짠다. 그런데 그 결과를 설명해달라고 하면 문제가 시작된다. 전문가가 전문가에게 보고하는 것처럼 말한다. 배경 지식을 당연히 공유하고 있다고 가정하고, 핵심 판단의 이유를 생략하며, 추상화 수준이 불필요하게 높다.
Opus 4.6에게 같은 것을 물으면 정반대다. 내가 무엇을 모를 수 있는지를 잘 추정한다. 비유를 골라 쓰고, 단계를 나누며, 맥락을 먼저 깔아준다. 그런데 추론 난이도가 올라가면 4.8이 한 번에 뚫는 문제에서 삐걱거린다.
한 문장으로 요약하면 이렇다: Opus 4.8은 똑똑한데 말을 어렵게 하고, Opus 4.6은 알기 쉽게 설명하는데 추론 성능이 낮다.
이건 결함이 아니다. 왜 그런지, 그리고 어떻게 이 차이를 구조적 장점으로 전환하는지가 이 글의 주제다.
지식의 저주는 LLM에게도 적용된다
1989년, 심리학자 Camerer, Loewenstein, Weber는 실험으로 증명했다. 정보를 많이 가진 사람일수록 상대방이 그 정보를 모른다는 사실을 제대로 고려하지 못한다. “지식의 저주(Curse of Knowledge)“라 불리는 이 현상은 교육학, 경제학, UX 설계에서 반복적으로 확인된 인지 편향이다.
올리버 웬델 홈스가 말했다. “복잡함 이쪽의 단순함에는 한 푼도 주지 않겠다. 그러나 복잡함 저쪽의 단순함에는 목숨을 걸겠다.” 쉬운 설명은 모르기 때문에 쉬운 게 아니라, 복잡함을 관통한 뒤에야 가능하다. 그런데 역설적으로, 복잡함 속에 있는 동안에는 쉽게 말하는 능력이 떨어진다.
2025년 EMNLP 논문은 이 현상이 대규모 추론 모델에서도 나타남을 보였다. 더 강력한 추론 능력을 가진 모델일수록 지식의 저주에 더 취약하다는 역설적 결과다. 깊이 추론하는 모델은 자신의 추론 과정을 상대방도 따라올 수 있다고 암묵적으로 가정한다. 사람의 전문가가 초보자에게 설명할 때 겪는 바로 그 문제다.
그래서 세상에는 두 종류의 역할이 있다. 깊이 생각하는 사람과 알기 쉽게 전달하는 사람. 연구자와 과학 커뮤니케이터. 수석 개발자와 테크 리드. 판사와 변호사. 이 둘은 다른 역량이다. 한 사람이 둘 다 잘하면 좋겠지만, 실제로는 드물다. 그래서 조직은 역할을 분리한다.
LLM도 마찬가지다. 그리고 Claude Code는 이 분리를 설정 한 줄로 가능하게 한다.
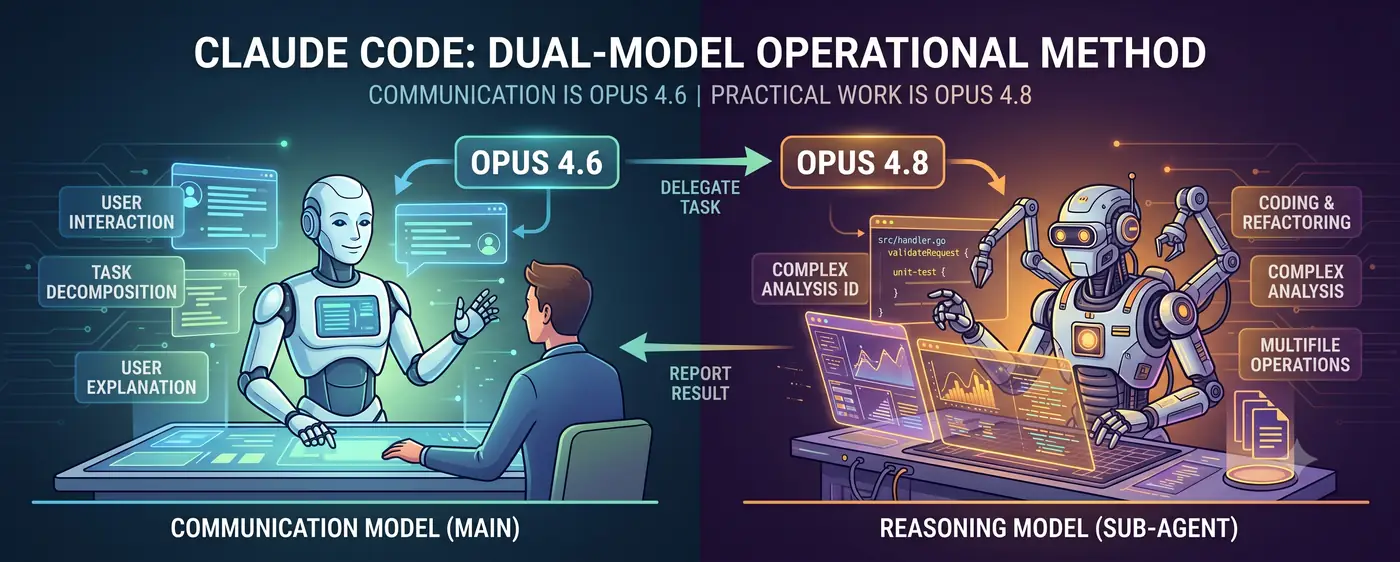
소통 모델 + 추론 모델
핵심 구조는 단순하다.
사용자 ↔ 소통 모델(메인) ↔ 추론 모델(서브에이전트)
- 소통 모델(Opus 4.6)이 대화의 전면에 선다. 사용자의 의도를 파악하고, 작업을 분해하며, 결과를 사람이 이해할 수 있는 언어로 보고한다.
- 추론 모델(Opus 4.8)이 실무를 처리한다. 코드 작성, 복잡한 분석, 멀티파일 리팩토링 같은 고난도 추론 작업을 서브에이전트로 위임받아 수행한다.
사용자는 4.6과 대화한다. 4.6이 “이건 내가 직접 하기엔 추론 난이도가 높다"고 판단하면 4.8 서브에이전트를 생성하고 작업을 위임한다. 4.8이 결과를 돌려주면, 4.6이 그것을 해석해서 사용자에게 설명한다.
이 글 자체가 그 증거다. 지금 이 글을 쓰고 있는 것은 Opus 4.6(메인)이고, 이 글의 근거가 되는 학술 논문 검색과 벤치마크 데이터 분석은 Opus 4.8(서브에이전트)이 수행했다.
벤치마크가 말해주는 것
BenchLM 데이터를 보면 두 모델의 성격이 숫자로 드러난다.
| 영역 | Opus 4.6 | Opus 4.8 | 우위 |
|---|---|---|---|
| 종합 | 86 | 93 | 4.8 |
| 코딩 | 64.4 | 76.4 | 4.8 |
| 에이전트 태스크 | 72.6 | 80.1 | 4.8 |
| 지식 태스크 | 76.2 | 70.1 | 4.6 |
| 창작 글쓰기 | 우위 | - | 4.6 |
코딩과 에이전트 태스크에서 4.8이 압도한다. 하지만 지식 전달과 창작 글쓰기에서는 4.6이 앞선다. Claude API 리뷰에서도 4.8의 글쓰기가 4.6보다 “더 AI스럽다(more AI-sounding)“는 평가가 반복된다. 4.8은 정확하게 추론하지만, 그 추론을 사람이 읽기 좋게 풀어내는 능력은 4.6이 낫다.
두 모델의 가격은 동일하다 — 입력 100만 토큰 $5, 출력 100만 토큰 $25. 역할을 나눠도 비용이 늘지 않는다. 이건 비용 최적화가 아니라 순수한 품질 최적화다.
모델 라우팅은 이미 증명된 공학이다
“두 모델을 나눠 쓴다"는 아이디어가 새롭지는 않다. 학계에서는 이미 확립된 분야다.
RouteLLM(ICLR 2025)은 쿼리를 강한 모델과 약한 모델 사이에서 동적 라우팅하여 비용을 2배 이상 줄이면서 품질을 유지했다. FrugalGPT(2023)는 LLM 캐스케이드로 GPT-4 수준의 성능을 98% 비용 절감과 함께 달성했다. 이 연구들의 공통 결론은 명확하다: 오케스트레이션이 뛰어난 약한 모델이, 오케스트레이션이 부실한 강한 모델을 종종 이긴다.
Anthropic 자신도 이 패턴을 쓴다. Anthropic의 deep-research 구현은 오케스트레이터-워커 패턴이며, 다중 에이전트 구성이 단일 에이전트 Opus 4를 90.2% 능가했다. 프로덕션 멀티에이전트 시스템의 약 80%가 오케스트레이터-워커 구조라는 조사 결과도 있다.
내가 하는 것은 이 패턴의 가장 단순한 형태다. 라우터도, 캐스케이드도, 비용 최적화도 아니다. 단지 소통에 최적화된 모델이 전면에 서고, 추론에 최적화된 모델이 뒤에서 일하는 것. 역할 분리의 원리 그 자체다.
설정하는 법
Claude Code에서 이 구조를 만드는 건 간단하다.
1단계: 메인 모델 설정
Claude Code를 Opus 4.6으로 실행한다. 설정에서 기본 모델을 claude-opus-4-6-20250610으로 지정하거나, 실행 시 모델을 선택한다. 이것이 사용자와 대화하는 소통 모델이 된다.
2단계: 서브에이전트에 모델 오버라이드
Claude Code의 Agent 도구는 model 파라미터를 지원한다. 서브에이전트를 생성할 때 모델을 opus(Opus 4.8)로 오버라이드하면 된다.
Agent({
description: "코드 리팩토링",
model: "opus",
prompt: "src/handler.go의 validateRequest 함수를..."
})
이것으로 끝이다. 메인 에이전트(4.6)가 사용자와 대화하고, 고난도 작업은 서브에이전트(4.8)에 위임한다.
3단계: fork와 fresh agent 구분
Claude Code의 서브에이전트에는 두 종류가 있다.
- fork (
subagent_type: "fork"): 현재 대화의 컨텍스트를 그대로 상속한다. 프롬프트 캐시를 공유하므로 입력 비용이 최대 90% 절감된다. 단, fork는 부모 모델을 강제 상속하므로 모델 오버라이드가 적용되지 않는다. - fresh agent: 새로운 컨텍스트에서 시작한다. 모델 오버라이드가 가능하다. 프롬프트에 필요한 배경을 직접 넣어줘야 한다.
따라서 추론 모델(4.8)을 쓰려면 fresh agent로 생성해야 한다. fork는 소통 모델(4.6)을 유지한 채 병렬 탐색이 필요할 때 쓴다.
실전 패턴
| 상황 | 방법 | 이유 |
|---|---|---|
| 복잡한 코드 작성 | fresh agent + model: opus | 추론 난이도 높음 |
| 멀티파일 리팩토링 | fresh agent + model: opus + isolation: worktree | 추론 + 격리 필요 |
| 병렬 조사/탐색 | fork (4.6 유지) | 컨텍스트 공유가 이득 |
| 단순 파일 읽기/편집 | 메인(4.6) 직접 | 위임 오버헤드가 더 큼 |
| 웹 검색/리서치 | fresh agent + model: opus | 정확한 추론 필요 |
4-8개의 동시 워크트리까지는 안정적이다. 그 이상은 결과 리뷰가 병목이 된다.
알려진 마찰
완벽하지는 않다. 현재 알려진 제약 두 가지.
첫째, 모델 오버라이드 누출 문제. 서브에이전트의 model 설정이 그 서브에이전트가 생성하는 하위 에이전트에까지 전파될 수 있다. 의도치 않은 모델 사용이 발생할 수 있으므로 서브에이전트의 깊이를 1단계로 제한하는 것이 실용적이다.
둘째, 에이전트별 모델 설정의 부재. 현재 Claude Code는 프로젝트 설정에서 에이전트 유형별로 모델을 미리 지정하는 기능을 공식 지원하지 않는다. 매번 Agent 호출 시 model 파라미터를 명시해야 한다. 커뮤니티에서도 이 기능에 대한 요청이 활발하다.
두 가지 모두 Claude Code가 진화하면 해소될 마찰이다. 현재 상태에서도 수동 오버라이드만으로 구조의 이점은 충분히 누릴 수 있다.
소통자와 사색가는 다른 역할이다
법정에서 판사와 변호사는 같은 법률을 다루지만 역할이 다르다. 판사는 판단한다. 변호사는 그 판단이 어떤 의미인지 의뢰인에게 설명한다. 판사가 의뢰인에게 직접 판결문을 읽어주면 의뢰인은 이해하지 못한다. 변호사가 판결을 직접 내리면 근거가 부실하다. 역할 분리는 시스템의 약점이 아니라 강점이다.
코드 리뷰에서도 마찬가지다. 시니어 개발자가 버그를 찾아내는 능력과 주니어 개발자에게 그 버그를 이해시키는 능력은 별개다. 뛰어난 엔지니어가 뛰어난 테크 라이터인 경우는 드물다. 조직은 이걸 알기 때문에 역할을 나눈다.
AI도 같다. 추론 능력과 소통 능력은 다른 축이다. 그리고 현재의 모델 학습 과정에서 이 두 축은 상충하는 경향이 있다. 추론 성능을 극대화하면 출력이 압축적이고 전문적이 되며, 소통 성능을 극대화하면 추론의 깊이가 얕아진다.
단일 모델에게 둘 다 잘하라고 요구하는 건, 판사에게 변호사 역할까지 하라는 것과 같다. 할 수는 있다. 하지만 둘 다 최적은 아니다.
소통 모델과 추론 모델의 분리는 버전이 바뀌어도 유효한 구조적 원리다. 4.6과 4.8은 오늘의 구체적 선택일 뿐이다. 내일 5.0과 5.2가 나오면 같은 원리로 다시 배치하면 된다. 모델은 교체되지만, “깊이 생각하는 역할"과 “알기 쉽게 전달하는 역할"이 다르다는 사실은 교체되지 않는다.
관련 글
더 읽을거리 (외부)
- RouteLLM: Learning to Route LLMs with Preference Data — 쿼리 난이도에 따라 강한 모델과 약한 모델을 동적 라우팅하는 프레임워크.
- Anthropic: How we built our multi-agent research system — Anthropic이 오케스트레이터-워커 패턴으로 deep-research를 구현한 방법.
출처
- Camerer, C., Loewenstein, G. & Weber, M. (1989). The Curse of Knowledge in Economic Settings: An Experimental Analysis. Journal of Political Economy, 97(5), 1232-1254. DOI — 지식의 저주의 실험적 증명.
- Li, W. et al. (2025). Curse of Knowledge: Your Guidance and Provided Knowledge are biasing LLM Judges in Complex Evaluation. Findings of EMNLP 2025. arXiv — 강한 추론 모델이 지식의 저주에 더 취약하다는 발견.
- Ong, I. et al. (2025). RouteLLM: Learning to Route LLMs with Preference Data. ICLR 2025. arXiv — 선호 데이터로 LLM 라우팅을 학습하는 프레임워크.