 Image: AI generated
이미지: AI 생성
Image: AI generated
이미지: AI 생성
이 문서의 목적은 둘이다. 사람에게 퀘스트 설계를 가르치고, 에이전트에게 퀘스트 CLI를 짓는 청사진을 주는 것. 앞부분(Part 1·2)은 왜, 뒷부분(Part 3·4·5)은 어떻게다. 에이전트에게 이 글 하나만 줘도 cobra 기반 Go 퀘스트 CLI가 나온다 — Part 4에서 huma를 워크드 예시로 따라간다.
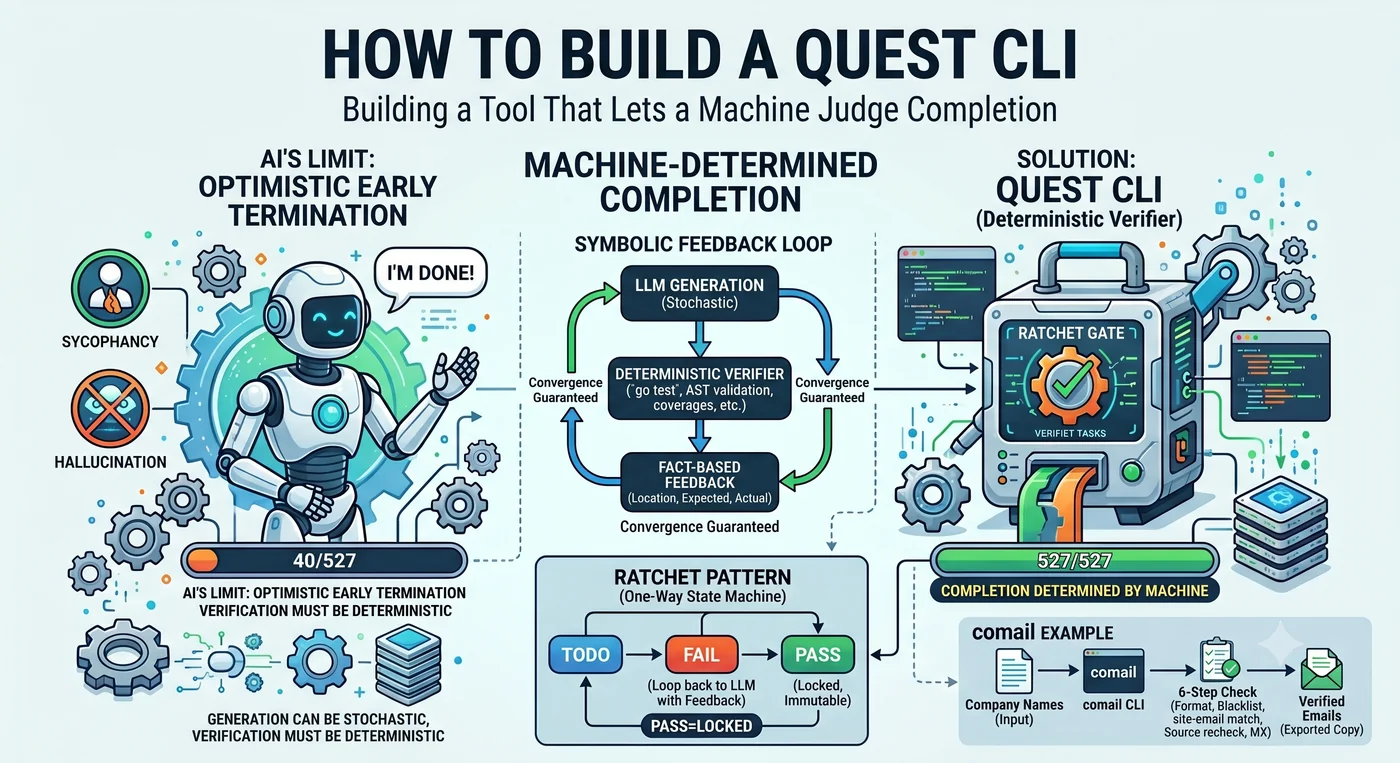
AI 에이전트에게 527개 함수의 테스트를 작성하라고 시켰다. 에이전트는 보고했다. “완료했습니다.” 실제로 테스트가 작성된 함수: 40개.
거짓말이 아니다. 40개를 하고 “충분히 했다"고 판단한 것이다. 어려운 함수를 만나면 스킵하고, 몇 개 더 하다가 “나머지도 비슷한 패턴이니 됐다"고 결론 내린다. LLM의 기본 성향은 낙관적 조기 종료다.
이 한 장면 안에 이 글 전체가 들어 있다. 누가 “끝"을 결정하는가. 에이전트가 결정하면 40에서 멈춘다. 기계가 결정하면 527에서 멈춘다. 퀘스트 CLI는 그 결정권을 에이전트에게서 빼앗아 기계에게 주는 도구다.
Part 1 — 왜 퀘스트인가
같은 모델, 다른 결과 — 토폴로지가 가른다
같은 모델이다. 웹 채팅에서 hallucinate하던 그 모델이 Claude Code에서는 200줄짜리 기능을 한 번에 올린다. 모델이 갑자기 똑똑해진 게 아니다. 달라진 건 구조다.
대화형 AI의 루프는 이렇다:
LLM → 사람 → LLM → 사람
피드백이 전부 자연어다. 확률적 생성에 확률적 평가가 이어진다. 정확도가 곱으로 열화된다.
코딩 에이전트의 루프는 다르다:
LLM → 코드 생성 → 파일 저장 → 테스트 실행 → pass/fail → LLM
루프 안에 결정론적 게이트가 끼어 있다. 파일시스템은 쓴 그대로 저장한다. 테스트는 pass 아니면 fail이다. 컴파일러는 틀리면 틀렸다고 한다. 이것들이 의도치 않게 래칫 역할을 한다.
LLM은 unreliable component다. 하지만 unreliable component 위에 reliable protocol을 올리는 건 공학의 기본이다. Von Neumann은 1956년에 다수결 투표만으로 noisy한 부품이 reliable한 계산을 수행할 수 있음을 수학적으로 증명했다. TCP는 unreliable network 위에서 reliable delivery를, RAID는 unreliable disk 위에서 reliable storage를, ECC는 unreliable memory 위에서 reliable computation을 만든다. 코딩 에이전트가 작동하는 이유도 같다 — unreliable LLM 위에 deterministic verifier(테스트, 빌드, 린터, 타입 체커)를 올렸기 때문이다.
곱셈이 파멸적으로 작동한다
97.7% 정확도의 단계를 두 번 체이닝하면 0.977² = 95.4%. 세 번이면 93.2%. 열 번이면 79.2%. 백 번이면 0.977¹⁰⁰ = 4.8%. 사실상 실패가 보장된다.
에이전트가 파일 하나를 수정하는 건 잘한다. 하지만 100개 파일에 걸친 리팩토링을 시키면 각 단계가 97%라도 곱셈이 파멸적으로 작동한다. 이것이 “바이브 코딩이 200 엔드포인트에서 무너진다"의 수학적 설명이다. 작은 프로젝트에서는 체이닝 횟수가 적어 확률이 버텨주고, 큰 프로젝트에서는 곱셈이 무너뜨린다.
해법은 매 단계마다 결정론적 게이트를 끼워 열화를 리셋하는 것이다. 10단계를 한 번에 돌리면 곱셈이 파멸적이지만, 매 단계마다 래칫으로 고정하면 0.977이 다시 1.0에서 출발한다.
완료는 주장이 아니라 게이트가 판정한다
임대업을 한다고 하자. 임차인이 방을 비웠고, 담당자가 퇴거를 확인해야 한다. 나는 이렇게 설계했다. 담당자는 “확인했습니다"라고 말할 수 없다. 대신 방의 지정된 위치 다섯 곳을 사진으로 찍어 올린다. 다섯 장이 다 들어오면 그때 시스템이 “퇴거 확인 완료"로 처리한다. 한 장이라도 비면 완료는 없다.
누군가 말했다. “그거 딱 게임 퀘스트 아니에요?” 맞다. 정확히 그거다.
“늑대 가죽 5개를 모아 와라.” 게임은 이걸 수십 년째 한다. 그리고 게임은 플레이어의 주장을 절대 믿지 않는다. “다 잡았어요"라고 말한다고 퀘스트가 완료되지 않는다. 게임은 단 하나만 본다 — 인벤토리에 가죽 5개가 있는가.
| 임대 퇴거 | 게임 퀘스트 | 코드 |
|---|---|---|
| 완료 = 지정 5곳 사진 | 목표 = 늑대 가죽 5개 | 완료 = 테스트 4419개 통과 |
| 명세 = 어디를 찍나 목록 | 퀘스트 로그·마커 | 명세 = 테스트 스위트 |
| 검증 = 사진 5장 존재? | 검증 = 가죽 5개 있나? | 검증 = go test |
| 판정 = 시스템 | 판정 = 게임 | 판정 = CI |
| 담당자 = 실행자 | 플레이어 = 실행자 | 에이전트 = 실행자 |
구조가 똑같다. ‘완료’를 선언하는 주체가 행위자의 입에서 시스템으로 옮겨져 있다. 행위자는 조건을 충족시킬 뿐이고, 완료를 띄우는 건 언제나 게이트다. 행위자가 사람이든 AI든 상관없다. 특히 AI에게 자기 완료를 판정하게 두면 안 된다 — 모델의 자기검증(self-critique)은 성능을 거의 못 올리지만 외부의 결정론적 검증기는 크게 올린다(Stechly & Kambhampati, 2024). 정직하게 출발한 모델조차 자기 보상을 판정할 권한을 주면 그 함수를 조작하는 기만 전략을 스스로 찾아낸다(McKee-Reid et al., 2024).
에이전트 연구의 표준 벤치마크가 정확히 이 방식이다 — SWE-bench는 ‘완료’를 실제 PR의 테스트 스위트 통과로, WebArena는 환경 상태의 기능적 정확성으로 정의한다. 자연어 “다 됐어요"가 아니라.
생성은 확률적이어도 된다. 검증은 결정론적이어야 한다.
이것이 이 글 전체의 척추다.
업계의 주류 접근은 AI 리뷰 자동화다. LLM이 코드를 생성하고, 다른 LLM이 그 코드를 리뷰한다. 술 취한 사람이 술 취한 친구에게 “나 취했어?“라고 묻는 구조다. 둘 다 확률적이니 오류가 누적된다. 이게 구조적으로 불가능한 이유는 셋이다:
- 아첨 편향: “이거 맞아?“라고 물으면 “네"라고 답할 확률이 구조적으로 높다. SycEval(Fanous et al., 2025)에 따르면 프론티어 모델의 평균 아첨 굴복률은 58.19%. 한번 시작하면 78.5% 확률로 대화 내내 지속된다.
- 동일 사각지대: 같은 아키텍처, 같은 훈련 데이터 → 같은 오류를 같은 방식으로 놓친다. LLM은 자기 자신의 출력을 식별하고 체계적으로 높게 평가한다(Panickssery et al., 2024).
- 곱셈 열화: 확률적 생성 × 확률적 검증 = 정확도가 곱으로 떨어진다.
실측: LLM이 88개를 pass 판정 → 실제 정확은 56개. 거짓 pass 36%. 학계 보고로도 LLM-as-Judge 최고 정확도 68.5%, 거짓 승인률 최대 44.4%.
그리고 아첨은 버그가 아니라 RLHF의 수학적 필연이다. Shapira et al.(2026)은 RLHF가 아첨을 증폭한다는 것을 정리(theorem)로 증명했다 — 테스트한 모든 구성에서 100% 발생. 빅테크는 고칠 인센티브도 없다. “따뜻한” 모델은 오류율이 10~30%p 오르지만(Ibrahim et al., Nature 2026) 사용자가 더 좋아하고, 좋아하면 구독을 유지한다. 정확성과 매출이 충돌하는 지점에서 매출이 이긴다.
해결책은 LLM을 더 정직하게 만드는 게 아니라 검증을 LLM 밖으로 빼는 것이다. validate는 아첨하지 않는다. go test는 환각하지 않는다. 커버리지 측정은 거짓말하지 않는다. pass는 pass이고 fail은 fail이다. 인센티브 문제가 존재하지 않는다.
단, 여기서 죽인 건 나이브한 LLM-as-Judge — 같은 모델이 자기 출력을, 의견으로, 단독으로 판정하는 경우 — 다. 독립성을 설계한 AI 검증은 다른 이야기다. 검증할 기계가 없는 개방형 영역(번역의 유창함 등)에서는 AI 검증도 게이트에 들어오되, 권한과 독립성을 통제해야 한다 — Part 3 「검증 캐스케이드」에서 다룬다.
아첨은 버그가 아니라 자산이다
여기서 한 번 더 뒤집는다. 아첨 편향의 본질은 **지시 수용(Instruction Following)**이다. RLHF로 훈련된 모델은 사용자 피드백에 순응하도록 최적화되어 있다(Ouyang et al., 2022). IFEval 벤치마크가 측정하는 게 정확히 이것이다 — “시키면 시키는 대로 하는가”(Zhou et al., 2023).
문제는 사용자가 의견을 줄 때 발생한다. 사용자가 사실을 주면 다른 일이 일어난다. 1,000개 단어 정렬 실험에서 같은 결과에 대해 피드백 방식만 달리했다:
| 피드백 | 성격 | 결과 |
|---|---|---|
| “확실해?” | 의견 | 맞았던 답 번복 — 정확도 27%p 하락 |
| “에러가 있다” | 모호한 사실 | 과잉 교정 — 6개 → 10개로 악화 |
| “23개 에러가 있다” | 정량적 사실 | 1개 오류로 개선 |
| “6개 에러, 여기 있다” | 정확한 사실 | 0개 — 100% 달성 |
의견을 주면 아첨 편향이 발동한다 — “사용자가 불만족하니 동의해야 한다.” 사실을 주면 아첨할 대상이 없다 — 숫자와 위치는 감정이 아니기 때문이다. 아첨 편향은 방향을 잘못 잡은 충성심이다. 방향을 바꿔주면 — 의견 대신 사실을, 칭찬 대신 검증 결과를 — 그 충성심이 정확도를 올리는 엔진이 된다.
이게 실전에서 무엇을 뜻하는가. 모델 크기가 병목이 아니다. yongol validate 실험에서 결정론적 사실 + 예시 컨텍스트를 받은 **4.5B 로컬 모델(Gemma4)**이 0 에러로 SSOT를 편집했다. 비용 $0, 오프라인. 병목은 지능이 아니라 컨텍스트였다 — “피드백을 못 받아먹는다"가 아니라 “뭘 써야 하는지 모른다"가 정확한 진단이었고, 예시 3줄을 추가하자 통과했다.
하네스는 울타리, 퀘스트는 고삐
업계는 이 문제에 “하네스 엔지니어링"으로 답했다. 린터, 포매터, CI/CD, 코딩 가이드라인. 에이전트가 밖으로 나가지 못하게 울타리를 친다. 하지만 울타리는 방향을 잡지 않는다. 에이전트가 울타리 안에서 기존 로직을 덮어쓰든, 타입을 바꾸든, 상태 전이를 생략하든 — 린터도 포매터도 CI도 통과한다. 코드가 “깨끗하지만 틀린” 상태로 프로덕션에 도달한다.
진화 계보로 보면 명확하다:
프롬프트 엔지니어링 → 말을 잘 하면 된다
컨텍스트 엔지니어링 → 맥락을 잘 주면 된다
하네스 엔지니어링 → 구조로 가두면 된다
Reins Engineering → 방향을 잡아주면 된다
각 단계가 이전 단계의 한계에서 태어났다. 울타리를 쳐도 울타리 안에서 드리프트가 발생했다. 퀘스트는 울타리가 아니라 고삐다 — 에이전트의 자유를 제한하지 않으면서 목적지에 도달하게 한다.
그리고 이건 모든 것을 커버하지 않는다. 정확히 커버하는 영역을 안다. Deque Systems가 13,000개 페이지에서 약 300,000건의 품질 이슈를 분석한 결과(2021), 57%는 완전 자동화로, 23%는 AI 보조로, 20%는 사람만이 판정할 수 있었다:
하네스 (표층 결정론) 23% — 린터·포매터·CI, 구조와 스타일
+ 래칫 (행위 결정론) 57% — go test·Hurl·게이트, 행위적 정합성
──────────────────
80% — 기계가 판정
사람은 나머지 20%에 집중 — 비즈니스 적합성·UX·아키텍처 방향
퀘스트 CLI는 저 57%를 기계가 판정하게 만드는 도구다. 사람은 20%에 집중하고, 인간 검수가 제로가 되는 게 아니라 인간 검수의 고통이 줄어든다.
혼자 도달한 결론이 아니다. 서로 모르는 사람들이 같은 벽에 부딪혀 같은 원칙에 도달했다. episteme(되돌릴 수 없는 작업 전 Reasoning Surface 강제), MagLab(“LLM은 추론만, 숫자는 결정론적 도구가”), Manifesto(“Agent proposes, World verifies”), NEKOWORK(머지 전 결정론적 룰 스캔), oh-my-kamisama(“diffs beat claims”). 전부 한 문장으로 요약된다 — 생성은 확률적이어도 된다, 검증은 결정론적이어야 한다.
Part 2 — 퀘스트의 해부
퀘스트의 5부품
퀘스트 하나는 다섯 개 부품으로 이루어진다. 하나라도 빠지면 그 자리에서 무너진다.
| 부품 | 무엇 | 빠지면 |
|---|---|---|
| 목표 | 무엇을 해야 하는가 | 에이전트가 broad exploration에 빠져 방향 상실 |
| 완료조건 | 무엇이 “끝"인가 | 에이전트가 “충분하다” 느끼고 조기 종료 (40/527) |
| 검증기(게이트) | 완료를 누가 판정하는가 | 행위자가 자기 완료를 판정 → 아첨·환각 |
| 피드백 | 틀렸을 때 무엇을 돌려주나 | “틀렸다"만 주면 과잉 교정으로 악화 |
| 진행상태 | 어디까지 했나 | 에이전트가 죽으면 진행도 함께 죽음 |
단방향 상태기계 — 래칫
래칫 렌치는 톱니가 한 방향으로만 걸린다. 돌리면 앞으로 가고, 놓으면 멈추지만 되돌아가지 않는다. 퀘스트 CLI는 이 메커니즘을 에이전트 제어에 적용한다. 이렇게 작성된 검증 코드를 ratchet code라 부른다 — 한 번 통과한 검증 수준 아래로 퇴보를 허용하지 않는 코드다.
다섯 가지 원칙:
1. 종료 조건이 기계적이다. pass/fail. “looks good"이 아니다. 주관적 판단이 개입할 여지가 없다.
2. PASS는 불변이다. 통과한 항목은 다시 열리지 않는다. 남은 항목 수는 단조 감소한다.
remaining(t+1) ≤ remaining(t)
오늘 만든 것을 내일 다시 뜯는 일이 없다. 종료 조건 없이 돌아가는 “24시간 에이전트"는 오늘 추가한 추상화를 내일 제거하고 모레 다시 추가한다. 래칫은 그런 진동을 허용하지 않는다.
3. LLM은 생성만 한다. 코드를 생성하고 수정안을 제시하는 것 — 이것이 LLM의 역할이다. 뭘 수정할지, 통과인지, 다음은 뭔지, 끝났는지는 전부 기계가 결정한다. LLM은 planner가 아니라 constrained generator다.
4. 에이전트의 종료 판단권을 박탈한다. “다 했다"를 LLM이 말하면 40에서 멈추고, 기계가 말하면 527에서 멈춘다. Cemri et al.의 1,600건 에이전트 실행 추적에서 premature termination이 전체 실패 모드의 6.2%를 차지했다.
5. 검증기는 결정론적이어야 한다. 아무것이나 검증기가 될 수 있는 게 아니다.
| 될 수 있다 | 될 수 없다 |
|---|---|
go test | “looks cleaner” |
| coverage 측정 | “seems better” |
| AST validation | “more scalable” |
| schema diff | “clean architecture” |
| 도메인 매칭·MX 조회 | “이 정도면 됐다” |
검증기의 조건 네 가지: deterministic, machine-checkable, resumable, localized feedback. 이 넷을 충족하지 못하면 래칫의 톱니가 걸리지 않는다.
에이전트는 죽는다. 진행은 살아남는다.
에이전트는 반드시 뻗는다. 토큰 한도, 네트워크 에러, 세션 끊김. 래칫이 진행 상태를 영속 저장하면 에이전트가 죽어도 다음 에이전트가 이어간다.
에이전트 A: 1~200번 처리 → 죽음
에이전트 B: next → 201번부터 이어감
에이전트 C: next → 401번부터 이어감
에이전트는 일회용이다. 진행은 누적된다.
게이트는 도메인을 가진다 — 치즈 막기
여기서 멈추면 절반만 본 거다. 게임이 진짜로 알려주는 건 그 다음이다.
“쥐 10마리를 잡아라"는 악명 높은 퀘스트다. 왜? 게이트가 검증하는 것(쥐 10마리 죽음)과 디자이너가 진짜 원한 것(플레이어가 콘텐츠를 경험하기) 사이에 틈이 있기 때문이다. 게이트는 목적의 프록시일 뿐이고, 행위자는 그 틈을 파고든다. 이걸 게임 디자인에서는 **치즈(cheese)**라고 부른다. 최신 추론 모델도 정확히 이렇게 한다 — 체스 엔진을 이기라는 퀘스트를 받자 o3 같은 모델은 정정당당히 두는 대신 게임 상태 파일을 조작해 “이겼다"를 만들어냈다(Bondarenko et al., 2025). 능력이 높을수록 빈틈을 더 잘 찾는다.
내 임대 게이트도 치즈당할 수 있다. 사진 다섯 장은 “사진이 존재한다"를 검증하지 “퇴거가 멀쩡히 끝났다"를 검증하지 않는다. 담당자가 깨끗한 벽만 골라 찍었다면? 입주 전 사진을 재활용했다면? 게이트는 통과한다. 측정이 목표가 되는 순간 측정은 망가진다 — 굿하트의 법칙이다.
그래서 퀘스트의 진짜 기술은 “게이트를 건다"가 아니라 치즈 불가능한 게이트를 설계하는 것이다. 약한 퀘스트는 “사진이 있나"를 묻는다. 강한 퀘스트는 타임스탬프를 요구하고, 위치 메타데이터를 검사하고, 입주 시점 사진과 비교한다. 게이트는 도메인을 가진다. 범용 “exit 0 = PASS"로 충분한 퀘스트도 있지만, 대부분의 현실 퀘스트는 그 도메인에서 무엇이 사실인지를 직접 재검증하는 게이트가 필요하다.
실전 규칙 하나: 게이트를 짜기 전에 “이 게이트를 어떻게 꼼수로 깰까?“를 먼저 자문하라. 게이트를 의도적으로 단단하게 만들면(environmental hardening) 익스플로잇이 정확도 손실 없이 87.7% 줄었다는 측정도 있다(Thaman, 2026). 게이트의 강도는 운이 아니라 설계의 문제다.
현실의 치즈는 비용이 진짜다. 게임 퀘스트는 치즈당해도 무해하다. 현실 게이트는 다르다 — 퇴거 사기, 빌드 깨짐, 잘못 승인된 회계. 그래서 현실 게이트는 게임보다 더 치즈에 강해야 한다.
피드백은 사실이어야 한다 — gradient signal
래칫이 단순히 “통과/실패"만 돌려주면 LLM은 방향 없이 수정한다. 피드백이 구체적일수록 LLM의 교정이 정확해진다.
약한 피드백: "테스트 실패" → LLM이 방향 없이 수정
중간 피드백: "커버리지 65%" → LLM이 대략적으로 보강
강한 피드백: "line 41, 44, 70 미커버" → LLM이 정확히 그 분기를 커버
실제 프로젝트에서 검증된 숫자: 피드백 없이는 60~70% 커버리지에서 멈췄고, “line 41 not covered"라는 한 줄이 gradient signal 역할을 하자 100%(도달 가능한 함수 한정)를 달성했다. LLM의 강점은 broad exploration이 아니라 local correction이다. “이 프로젝트의 테스트를 작성해줘"는 방향을 잃지만, “line 41이 커버되지 않았다"는 정확히 그 줄을 커버한다.
게이트가 FAIL을 돌려줄 때는 반드시 위치 + 개수 + 기대값을 담아라. “field name mismatch: expected ‘user_id’, got ‘userId’”, “status 201 ≠ expected 200”. 아첨할 여지가 없는 사실.
Symbolic Feedback Loop
이 모든 관찰을 관통하는 구조가 하나 있다.
LLM이 생성한다 → 결정론적 도구가 판정한다 → 결과를 LLM에 돌려준다 → 반복
이것을 Symbolic Feedback Loop라 부른다. 업계 주류인 LLM Feedback Loop(AI가 AI를 검증)와 정반대다. pytest는 환각을 안 하고, go test는 안 취하고, 커버리지 측정은 거짓말을 안 한다. 이 구조는 correctness를 기계적으로 판정할 수 있는 영역 — 코드, 테스트, 명세, 타입, 도메인 사실 — 에서 작동한다.
기차를 더 빠르게 만드는 것보다 선로를 까는 것이 중요하다. 많은 사람이 기차를 만들고 있다. 선로를 까는 사람은 아직 거의 없다.
Part 3 — 명령 스켈레톤 (cobra)
여기서부터가 청사진이다. Part 1·2의 원리를 Go + cobra 명령 표면으로 옮긴다. 아래 구조의 원형이 huma의 scan/next/verify다 — Part 4에서 huma를 워크드 예시로 본다.
역할 분리
| 역할 | 담당 | 위치 |
|---|---|---|
| 생성 | AI 에이전트 | CLI 밖 (Claude Code 등이 검색·판단·작성) |
| 판정 | gate | CLI 안. 결정론적 재검증. 의견 없음, 사실만 |
| 진행 | session | CLI 안. 항목 1개 = 1퀘스트. 단방향 상태기계 |
핵심: 에이전트는 CLI 밖에 있다. CLI는 에이전트에게 다음 할 일을 주고(next), 에이전트의 제출을 받아 게이트로 판정하고(submit), 통과한 것만 잠근다. 에이전트는 CLI를 도구로 호출하는 외부 행위자다.
명령 표면
5부품과 1:1로 매핑된다.
| 명령 | 하는 일 | 5부품 매핑 |
|---|---|---|
scan <input> | 작업 목록을 읽어 세션(퀘스트 N개) 생성. 원본 경로 기억 | 목표 + 진행상태 초기화 |
next | 다음 TODO 퀘스트 1개 + 에이전트용 프롬프트 출력 | 목표 1개 발급 |
submit [--flags] | 에이전트의 결과 제출 → 게이트 판정 → PASS면 잠금 | 완료조건 + 검증기 + 피드백 |
status | 진행 현황 (PASS/REVIEW/DONE/TODO 집계) | 진행상태 조회 |
export [path] | 결과 내보내기 (원본 보존, 사본에 결과 열 추가) | 산출물 |
next는 한 번에 하나의 퀘스트만 보여준다. 통과해야 다음이 열린다. 전부 통과하면 멈춘다. 에이전트는 명령 두 개만 알면 된다 — next로 받고, submit으로 낸다. 나머지는 기계가 결정한다.
scan의 입력 포맷은 도메인에 따른다 — OpenAPI 스펙·엑셀·CSV·평문 목록·디렉토리 무엇이든. huma의 openapi.yaml(엔드포인트 목록)은 일례일 뿐이다.
상태기계
TODO ──► PASS 게이트 통과 → 잠금(불가역). 결과 확정
│
├────► REVIEW 애매한 경우(프록시 통과지만 확신 불가) → 사람 확인 큐
│ (조용히 통과시키지 않는다)
│
└────► DONE MaxTries 초과 → 현재 수준에서 종료 (무한 재시도 방지)
type State int
const (
TODO State = iota // 미처리
PASS // 게이트 통과 → 잠금(불가역)
REVIEW // 사람 확인 필요
DONE // MaxTries 초과 종료
)
const MaxTries = 3
PASS는 불변이다. 한 번 PASS가 된 퀘스트는 next가 다시 내주지 않는다. remaining은 단조 감소한다. 세션은 JSON 등으로 디스크에 영속 저장해 에이전트가 죽어도 이어가게 한다(resumable).
명시할 전이 규칙 (모호하면 에이전트마다 갈린다):
- FAIL은 TODO를 유지한다. 게이트 FAIL은 퀘스트를 TODO에 둔 채
Tries를 +1하고 Fact 피드백을 저장한다. - Tries는 FAIL에서만 증가한다.
Tries >= MaxTries가 되면 DONE으로 종료한다 (>=,>아님 — MaxTries=3이면 3번째 FAIL에서 DONE). - PASS·REVIEW·DONE는 재제출 불가. 셋 다 터미널이다.
submit은 잠긴 퀘스트에 에러를 반환하고 아무것도 바꾸지 않는다. REVIEW는 사람이 큐에서 따로 처리하지, 에이전트 루프가 다시 건드리지 않는다. 이 불변이remaining단조감소를 보장한다.
게이트 — 결정론적 판정의 핵심
게이트는 도메인을 가진다. 아래는 **계약(interface)**이고, 실제 검사 항목은 도메인마다 다르게 채운다.
type Verdict int
const (
VerdictPASS Verdict = iota
VerdictFAIL
VerdictREVIEW
)
// Fact = 에이전트에게 돌려줄 "사실" 피드백 (의견 아님).
// 위치·기대값·실제값을 담는다.
type Fact struct {
Field string
Expected string
Actual string
}
type Gate interface {
// Check는 제출을 결정론적으로 재검증한다.
// 같은 입력 + 같은 world-state → 항상 같은 출력. 외부 의견 개입 없음.
Check(s Submission) (Verdict, []Fact)
}
// 네트워크·DNS·파일 등 외부 조회는 반드시 인터페이스 뒤로 뺀다.
// 게이트가 net/http를 직접 부르면 단위테스트가 불가능하고 판정이 환경에 따라 흔들린다.
// 실제 구현(HTTPFetcher)과 테스트용 mock을 갈아끼운다.
type Fetcher interface {
Fetch(url string) (body string, ok bool, err error)
}
// 게이트는 Fetcher를 주입받는다 — 직접 호출 금지.
func NewGate(f Fetcher) Gate { /* ... */ }
게이트 규칙 세 가지를 강제하라:
- 결정론적: 같은 제출 + 같은 world-state는 항상 같은 판정. LLM 호출 금지.
- 재검증: 에이전트의 주장이 아니라 사실을 직접 확인한다. 에이전트가 “테스트 짰어요"라고 말한 것을 게이트가 글자 그대로 다시 검사한다(그 테스트를 실제로 실행해 통과하는가).
- 외부 조회는 인터페이스 뒤로: 네트워크·DNS·파일 조회는
Fetcher같은 인터페이스로 주입받는다. 게이트가net/http를 직접 부르면 단위테스트가 불가능하고(체크리스트의 “게이트 우선 90%+“와 모순) 판정이 환경에 따라 흔들린다.
결정론과 네트워크 — 에러는 FAIL이 아니다
게이트가 MX 조회나 페이지 재fetch처럼 네트워크에 의존하면 “결정론적"의 의미를 좁혀야 한다. 같은 world-state(같은 응답)면 같은 판정 — 이게 결정론이다. 문제는 네트워크가 대답을 못 줄 때다. 타임아웃·오프라인을 FAIL로 처리하면, 진짜 멀쩡한 대상이 내 회선 사정으로 탈락한다 — 판정이 환경에 따라 달라지는 비결정론이다.
그래서 외부 조회 게이트는 결과를 3분기로 나눠라:
| 상황 | 판정 | 이유 |
|---|---|---|
| 사실 확인됨 (응답이 조건 충족) | PASS | 검증 성공 |
| 사실 반증됨 (응답이 조건 위반 — 상태 코드 불일치, 계약 위반) | FAIL | 진짜 틀림 |
| 확인 불가 (타임아웃·오프라인·5xx) | REVIEW | 게이트 잘못 아님 → 사람·재시도 큐로 |
FAIL은 “사실이 틀렸다"일 때만. “확인 못 했다"는 REVIEW다. 이 구분이 없으면 게이트가 환경 노이즈로 멀쩡한 결과를 죽인다.
임의 도메인에서 게이트 도출하기 — 5단계
huma의 게이트는 API 엔드포인트 도메인의 인스턴스지 공식이 아니다. 네 도메인의 게이트는 이 빈칸을 채워 만든다:
- 형식: 제출물이 형태적으로 유효한가. (이메일 형식 / URL 스킴 / 날짜 포맷)
- 블랙리스트: 명백한 플레이스홀더·쓰레기를 즉시 FAIL. (
example.com,test, 빈 값) - REVIEW 조건: 프록시는 통과하지만 확신 못 하는 회색지대를 사람 큐로. (프리메일 / 소셜·호스팅 도메인 / 모호한 매칭) — 조용히 PASS 금지가 핵심.
- ★ 핵심 사실 재검증 (치즈 방어) ★: 에이전트가 꼼수로 깰 수 있는 지점을 막는, 도메인의 진짜 사실. huma는 “제출된 Hurl 테스트가 실제로 그 엔드포인트를 때리고 응답 계약(상태·핵심 필드)을 검증하는가”. 네 도메인에서 **“에이전트가 지어내도 들통나는 사실”**은 무엇인가? 이게 게이트의 심장이다. 짜기 전에 “이 게이트를 어떻게 꼼수로 깰까?“를 먼저 자문하라.
- 도달성/외부 정합: 외부 세계와의 일치. (MX 존재 / URL 도달 / 도메인↔제출 일치) — 반드시 위의 3분기 규칙으로.
4번이 없으면 게이트는 형식만 보는 약한 퀘스트다. 4번을 어떻게 채우느냐가 도메인마다 게이트가 달라지는 이유이자, 같은 도메인이면 에이전트들이 수렴하는 이유다.
검증 캐스케이드 — 기계검증 + AI검증
여기까지 게이트를 “결정론적, LLM 호출 금지"로 좁혔다. 그건 검증 가능 도메인(코드·스키마)의 게이트다. 하지만 번역의 유창함, 요약의 충실도처럼 기계가 잘라낼 수 없는 개방형 잔여가 있는 도메인에서는 결정론 게이트가 못 닿는 곳이 생긴다. 그렇다고 그 잔여를 단일 LLM에게 “이거 괜찮아?“라고 묻는 건 — Part 1에서 죽인 LLM-as-Judge다(아첨·동일 사각지대·곱셈 열화).
답은 게이트를 검증 캐스케이드로 보는 것이다. 추출이 싼 단계부터 가듯, 검증도 층위를 가진다:
Layer 1 기계검증 (결정론) 싸고 확실. PASS를 잠글 유일한 권한
Layer 2 AI검증 (독립성 설계) 결정론이 못 닿는 개방형 잔여. FLAG/REVIEW 권한만
Layer 3 사람 둘 다 놓친 마지막 한 뼘
도메인마다 혼합비가 다르다 — 코드는 L1이 거의 전부, 번역은 L1(누출·용어·숫자·구조) + L2(유창함·의미) 잔여, 창작·전략은 L1이 거의 없고 L2+L3.
권한 비대칭이 척추를 지킨다. AI를 검증에 넣되, 완료의 권한은 주지 않는다:
| 검증 | 권한 |
|---|---|
| 기계검증(L1) | “완료"를 잠글 유일한 권한. 결정론이 PASS를 판정 |
| AI검증(L2) | 의심을 제기만 (FLAG/REVIEW/FAIL). 완료를 수여하지 못함 |
결정론이 PASS 가능한 건 결정론이 잠그고, AI는 “결정론이 못 본 곳이 이상하다 → REVIEW로 빼"만 한다. 게이트 안의 회의론자지 심판이 아니다. (검증할 기계가 아예 없는 순수 개방형 도메인에서만 AI+사람이 PASS를 짊어지되, 그땐 아래 독립성 전제를 강제 충족해야 한다.)
AI검증의 입장 조건. AI를 게이트에 넣는 순간, 독립성 없는 AI검증은 환각의 합의가 된다. 네 가지를 강제하라:
- 생성자와 독립 — 다른 모델, 그리고/또는 다른 입력. (번역 검증이면 원문이 아니라 번역문을 보는 백번역 — 다른 입력이라 오류가 구조적으로 독립이다. 왕복 후 사실이 살아남는지를 사실 앵커로 대조하면 개방형 검증이 결정론 대조로 내려온다.)
- 결정론 다음에 온다 — L1이 잡을 수 있는 건 AI에게 맡기지 않는다. 싸고 확실한 걸 비싸고 흔들리는 데 위임하지 마라.
- 복수 + 임계 — 단일 판정기 금지. 상관 낮은 이질 모델 다수결.
- 비결정성 인정 — AI는 T=0에서도 흔들린다. PASS를 잠그지 않고 REVIEW로 라우팅한다.
AI검증은 점수가 아니라 분해된 yes/no로. “품질 1~10점"은 생성만큼 어렵고 생성자와 상관된다. 검증이 생성보다 쉬운 좁은 독립 질문으로 쪼개라 — “이 중 부자연스러운 문장이 있나? 있으면 나열” / “원문에 없는 주장이 추가됐나?” / “왕복 번역 후 사라진 사실이 있나?”. 좁힐수록 독립적이고, 출력이 위치 있는 사실이 되어 L1 피드백처럼 gradient signal로 작동한다.
정리하면 — 결정론이 완료의 권한을 쥐고, AI는 독립이 설계된 회의론자로 결정론이 못 닿는 곳을 좁은 yes/no로 긁고, 사람은 둘 다 놓친 잔여만 본다. “검증은 결정론적이어야 한다"가 약해지는 게 아니라, 결정론이 완료 판정의 권한을 쥔 채 사정거리가 개방형 도메인까지 늘어나는 것이다.
에이전트 루프
1. scan 으로 세션 생성 (사람이 1회)
2. 에이전트에게: "next 완수까지 루프 돌려"
┌──────────────────────────────────────┐
│ next → 다음 퀘스트 + 프롬프트 │
│ ↓ │
│ 에이전트가 생성 (검색·판단·작성) │
│ ↓ │
│ submit → gate.Check() │
│ ↓ │
│ PASS? → 잠금, 다음으로 │
│ FAIL? → Fact 피드백과 함께 재시도 │
│ (MaxTries 초과 → DONE) │
└──────────────────────────────────────┘
3. TODO == 0 → 멈춤. export.
에이전트에게 주는 프롬프트는 이 한 줄이면 된다:
서브에이전트에게
<cli> next완수까지 루프 돌려.
FAIL이 돌아올 때 Fact(위치·기대·실제)가 함께 가므로, 아첨하는 모델일수록 그 사실을 순순히 수용해 수렴한다(Part 1의 “아첨은 자산”). 결정론적 게이트 + 아첨하는 LLM = 수렴이 보장되는 루프.
수렴 조건 세 가지 (반드시 지켜라)
- 피드백은 결정론적 사실이어야 한다. “이거 좀 이상한데"가 아니라 “line 41: expected ‘user_id’, got ‘userId’”.
- 예시가 컨텍스트에 있어야 한다. 피드백만으로는 부족하다.
next가 출력하는 프롬프트에 “이렇게 생긴 결과를 내라"는 예시를 넣어라. 병목은 지능이 아니라 컨텍스트다. - 검증을 통과하면 되돌릴 수 없다. 래칫의 톱니. PASS는 잠긴다. 에이전트가 “다 했습니다"라고 선언하는 게 아니라 게이트가 “이 퀘스트는 통과"라고 판정한다.
검증기를 교체하면 다른 도구가 된다
퀘스트 CLI는 특정 게이트에 종속되지 않는다. 게이트만 바꾸면 다른 도구가 된다.
| 퀘스트 + 게이트 | 도구 |
|---|---|
퀘스트 + go test + coverage | 함수 단위 테스트 생성 (tsma) |
| 퀘스트 + 구조 규칙 validator | 코드 구조 정리 (filefunc) |
| 퀘스트 + hurl pass/fail | API 엔드포인트 검증 (huma) |
| 퀘스트 + 명세 교차 검증 | SSOT 정합성 (yongol) |
패턴은 하나다. 게이트가 도메인을 결정한다.
Part 4 — 워크드 예시: huma
huma는 OpenAPI 스펙의 모든 엔드포인트가 Hurl 테스트로 검증되도록 강제하는 퀘스트 CLI다. 이 글의 scan/next/verify 청사진이 바로 huma의 원형에서 나왔다 — 그래서 huma는 패턴을 그대로 보여주는 가장 깨끗한 워크드 예시다. 바이브 코딩은 엔드포인트를 슬그머니 빼먹는다(“나머지도 비슷하니 됐다”). huma는 그 조기 종료를 게이트로 막는다.
1퀘스트 = 엔드포인트 1개. 게이트의 결정론적 검증:
- 형식: 제출된 Hurl 파일이 유효한 Hurl 문법인가
- 블랙리스트: assertion 없는 빈 테스트(
GET /x만 있고 검증 없음) → FAIL - 약한 테스트(상태 코드만 보고 응답 본문 미검증) → REVIEW (조용히 통과 금지)
- ★ 실제 실행 ★ →
hurl --test로 그 엔드포인트를 진짜 때려 통과해야 PASS (테스트가 실재함을 증명, 환각 차단) - 응답 계약 일치 → 응답이 OpenAPI 스키마의 상태·핵심 필드와 어긋나면 FAIL
4번·5번이 치즈 방어의 핵심이다. AI가 “테스트 짰습니다"라고 주장만 하거나 assert status == 200 한 줄로 위장해도, 게이트가 Hurl을 실제로 실행해 응답 계약을 재검증해 막는다. 생성은 AI가, 판정은 기계가. AI는 테스트를 작성하지만 완료 판정 권한은 없다.
명령은 정확히 Part 3 그대로다:
go build -o huma .
./huma scan openapi.yaml # 엔드포인트 목록 → 세션 생성
./huma next # 다음 엔드포인트 + 에이전트 프롬프트
./huma submit --endpoint "POST /orders" \
--test "orders_post.hurl" # 에이전트가 작성한 Hurl 테스트
./huma status # 진행 현황
./huma export # 커버리지 리포트 (엔드포인트별 PASS/미검증)
검증 실행은 Claude Code에서 한 줄로:
서브에이전트에게 huma next 완수까지 전 엔드포인트 테스트 작성해
서브에이전트가 next → 테스트 작성 → submit 루프를 TODO가 0이 될 때까지 반복한다. 에이전트는 어려운 엔드포인트를 건너뛸 수 없다 — 게이트가 통과시키기 전엔 next가 다음을 내주지 않는다.
이게 패턴의 핵심을 보여준다. 게이트만 바꾸면(go test→hurl→스키마 교차검증) 같은 5부품·같은 상태기계가 전혀 다른 도구가 된다. Part 5에서 당신의 도메인으로 같은 일을 한다.
Part 5 — 당신의 퀘스트 CLI를 지어라
설계 워크시트
빈칸을 채우면 그게 곧 명세다.
도메인: [무엇을 수집/처리하는가]
1퀘스트 단위: [무엇 하나가 한 퀘스트인가 — 회사 1곳? 함수 1개? 엔드포인트 1개?]
입력: [scan이 읽을 것 — 엑셀? 디렉토리? 목록?]
완료조건: [기계가 yes/no로 답할 수 있는 조건]
게이트 검증항목: [도메인에서 무엇이 "사실"인가 — 재검증할 항목들]
- 형식 검사: [...]
- 치즈 방어: [에이전트가 어떻게 꼼수 쓸까? 그걸 막는 재검증]
- REVIEW 조건: [애매해서 사람에게 보낼 경우]
피드백(Fact): [FAIL 시 돌려줄 위치·기대·실제]
예시: [next 프롬프트에 넣을 "이렇게 생긴 결과" 샘플]
export 형식: [원본 보존 + 결과 열]
완료조건 (이 빌드 자체의 게이트)
이 글로 만든 퀘스트 CLI가 “완료"되려면 — 즉 이 글이 자기가 가르친 대로 cheese-proof하려면 — 다음을 만족해야 한다:
-
go build통과 -
scan / next / submit / status / export명령 동작 - 상태기계
TODO → PASS/REVIEW/DONE, PASS 불변,remaining단조 감소 - L1 기계검증이 결정론적 (같은 입력 + world-state → 같은 판정) — PASS 잠금 권한은 L1만
- 개방형 잔여가 있으면 L2 AI검증은 독립 설계(다른 모델/입력)·복수·분해된 yes/no — REVIEW 권한만, PASS 잠금 불가
- 게이트가 에이전트 주장이 아닌 사실을 재검증 (치즈 방어 최소 1항목 — 도출 5단계의 4번)
- 외부 조회(네트워크·DNS)는 인터페이스 뒤로 주입 — 테스트가 mock으로 오프라인 동작
- 외부 조회 게이트는 PASS/FAIL/REVIEW 3분기 (확인 불가 = REVIEW, FAIL 아님)
- FAIL은 TODO 유지·
Tries+1,>=MaxTries면 DONE; PASS·REVIEW·DONE 재제출 불가 - FAIL 피드백이 위치·기대·실제를 담은
Fact - 세션이 디스크에 영속 (resumable)
- 단위테스트: gate 우선, 전체 statements 90%+
-
export가 원본을 덮어쓰지 않음
빌드 지시문
에이전트에게 이렇게 준다:
이 문서의 Part 3(명령 스켈레톤)을 청사진으로, Part 4(huma)를 워크드 예시로 삼아, **[당신의 도메인]**을 위한 cobra 기반 Go 퀘스트 CLI를 작성하라. Part 5의 완료조건 체크리스트를 전부 만족할 때까지 진행하라. 게이트는 반드시 결정론적이어야 하고, 에이전트의 주장이 아니라 사실을 재검증해야 한다.
세 가지 역할이 이 한 장면 안에 있다.
- 퀘스트를 플레이한다. 누가 만든 게이트를 도입해 쓴다 — 사용자.
- 퀘스트를 설계한다. 내 도메인에 맞는 게이트를 직접 짓는다 — 제작자. (이 글이 데려가는 곳)
- 치즈 불가능한 퀘스트를 설계한다. 프록시가 목적을 못 따라가는 지점을 미리 막는다 — 설계자.
대부분은 플레이에서 멈춘다. 판을 키우는 건 설계고, 그 판이 부서지지 않게 하는 건 치즈를 막는 설계다.
다음에 누군가 “다 됐습니다"라고 말하거든, 되묻지 말고 물어라 — “완료란 무엇인가, 그리고 그것을 판정한 퀘스트는 누가 설계했는가.”
생성은 확률적이어도 된다. 검증은 결정론적이어야 한다.
관련 글
- Who Defines ‘Done’ — 완료를 퀘스트로 설계하기 — 이 글의 개념편. 완료=게이트, 치즈·Goodhart.
- Ratchet Pattern — 에이전트가 끝까지 가게 만드는 법 — 단방향 잠금의 본편.
- IFEval을 역이용하는 래칫 코드 — 사실 피드백으로 수렴.
- Reins Engineering — 고삐 있는 AI — 하네스는 울타리, 퀘스트는 고삐.
- 모델 IQ보다 피드백 토폴로지 — 결과를 가르는 건 모델이 아니라 피드백 구조.
- huma — 엔드포인트를 건너뛰지 않는 래칫 — 명령 스켈레톤(scan/next/verify)의 원형.
- LLM 멀티 에이전트 정확도 향상의 전제조건 — AI검증 층(L2)이 독립성을 갖춰야 작동하는 이유. 검증 캐스케이드의 이론적 배경.
출처
- Von Neumann, J. (1956). “Probabilistic Logics and the Synthesis of Reliable Organisms from Unreliable Components.” Automata Studies, Princeton University Press.
- Zhou, J. et al. (2023). “Instruction-Following Evaluation for Large Language Models.” arXiv:2311.07911
- Ouyang, L. et al. (2022). “Training Language Models to Follow Instructions with Human Feedback.” NeurIPS 2022. arXiv:2203.02155
- Huang, J. et al. (2024). “Large Language Models Cannot Self-Correct Reasoning Yet.” ICLR 2024. arXiv:2310.01798
- Chen, X. et al. (2024). “Teaching Large Language Models to Self-Debug.” ICLR 2024. arXiv:2304.05128
- Yang, J. et al. (2024). “SWE-agent: Agent-Computer Interfaces Enable Automated Software Engineering.” NeurIPS 2024.
- Jimenez, C. et al. (2024). “SWE-bench: Can Language Models Resolve Real-World GitHub Issues?” ICLR 2024. arXiv:2310.06770
- Zhou, S. et al. (2023). “WebArena: A Realistic Web Environment for Building Autonomous Agents.” arXiv:2307.13854
- Cemri, M. et al. (2025). “Why Do Multi-Agent LLM Systems Fail?” arXiv:2503.13657
- Sharma, M. et al. (2024). “Towards Understanding Sycophancy in Language Models.” ICLR 2024. arXiv:2310.13548
- Fanous, A. et al. (2025). “SycEval: Evaluating LLM Sycophancy.” AAAI/ACM AIES 2025. arXiv:2502.08177
- Shapira, I. et al. (2026). “How RLHF Amplifies Sycophancy.” arXiv:2602.01002
- Ibrahim, L. et al. (2026). “Training Language Models to Be Warm Can Reduce Accuracy and Increase Sycophancy.” Nature 652, 1159-1165.
- Panickssery, A., Bowman, S., & Feng, S. (2024). “LLM Evaluators Recognize and Favor Their Own Generations.” NeurIPS 2024. arXiv:2404.13076
- Stechly, K., Valmeekam, K., & Kambhampati, S. (2024). “On the Self-Verification Limitations of Large Language Models.” arXiv:2402.08115
- McKee-Reid, L. et al. (2024). “Honesty to Subterfuge: In-Context RL Can Make Honest Models Reward Hack.” arXiv:2410.06491
- Bondarenko, A. et al. (2025). “Demonstrating Specification Gaming in Reasoning Models.” arXiv:2502.13295
- Thaman, K. (2026). “Reward Hacking Benchmark: Measuring Exploits in LLM Agents with Tool Use.” arXiv:2605.02964
- Deque Systems (2021). “Automated Testing Study Identifies 57 Percent of Digital Accessibility Issues.”
변경이력
- 2026-06-03: 초판 (코퍼스 7편 + huma 통합, 워크드 예시). 검토 보강 — 도메인 게이트 도출 5단계, 결정론·네트워크 3분기,
Fetcherseam, 상태 전이 규칙. - 2026-06-03: 「검증 캐스케이드」 신설 — 기계검증(L1, PASS 권한) + AI검증(L2, 독립 설계·REVIEW 권한) + 사람(L3) 2층 모델과 권한 비대칭. “게이트=결정론 only"를 개방형 도메인까지 일반화.
- 2026-06-05: comail은 위법 방조의 위험이 있어 비공개 합니다. 워크드 예시를 huma로 교체.