 Image generated by Google Gemini
Image generated by Google Gemini
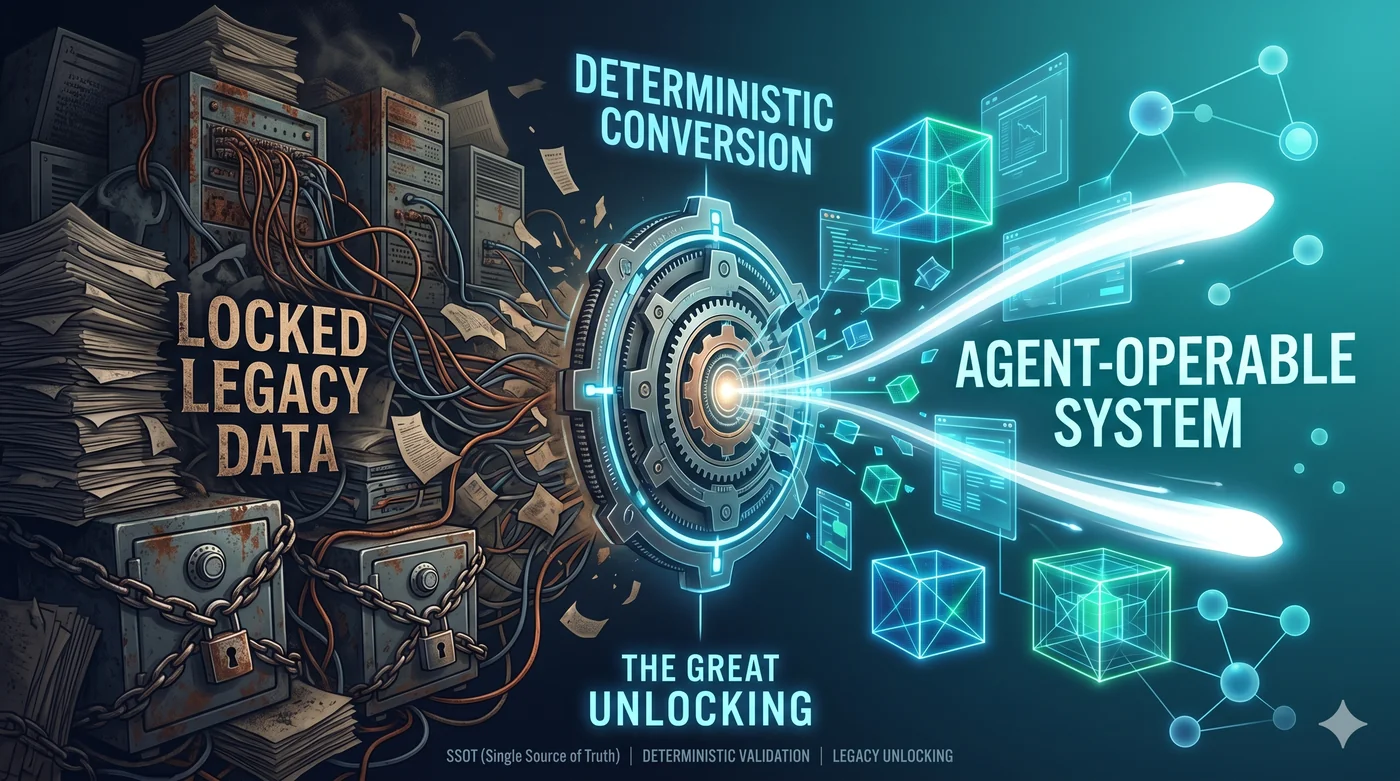
AI 에이전트에게 리팩토링을 시켰더니 앱이 망가졌다면, 레거시 시스템을 AI가 작업할 수 있는 환경으로 전환하고 싶다면, Fortune 500의 레거시 유지보수 예산을 전환 예산으로 바꾸고 싶다면 — 이 글이 그 로드맵이다.
잠긴 기억
IT 버블 시대에 기업들은 디지털 자산을 쌓기 시작했다. 코드, 데이터베이스, 명세, 문서, API — 수십 년에 걸쳐 축적된 기업의 기억이다.
그 기억들은 잠겨 있었다. 탐색할 수 없고, 검증할 수 없고, 도달할 수 없는(unreachable) 상태. 사람이 직접 읽고, 직접 이해하고, 직접 수정하는 것 외에는 방법이 없었다. 그래서 Fortune 500 IT 예산의 60~80%가 이 잠긴 기억을 유지하는 데 쓰인다. 열지 못하니까 지키기만 한다.
지금 우리는 AI 버블이라 불리는 시기 한가운데를 지나고 있다. 이 시기의 진짜 의미는 모델이 똑똑해지는 것이 아니다. 기업의 오랜 레거시 기억들이 도달 가능한(reachable) 상태로 바뀌기 시작한다는 것이다.
하지만 아직은 아니다. 2026년, AI 에이전트가 코드를 쓴다. 68분 동안 수백만 토큰을 태우고 리팩토링을 끝냈다. 앱이 완전히 망가졌다. 매일 X에 올라오는 이야기다.
왜 이런 일이 반복되는가?
에이전트가 멍청해서가 아니다. 에이전트가 작업할 수 있는 환경이 아니기 때문이다. 사람이 일하는 사무실에 로봇을 넣으면 안 된다. 로봇이 일할 수 있는 공장을 만들어야 한다.
잠긴 기억을 열려면, 먼저 기억이 열릴 수 있는 형태로 바뀌어야 한다. 코드만의 문제가 아니다. 데이터베이스, 명세, 문서, API — 기업의 디지털 자산 전체가 에이전트에게 불투명하다.
Agent-Operable이란 무엇인가
에이전트가 자율적으로 작업하려면 세 가지 조건이 필요하다:
1. 읽을 수 있어야 한다 — 노이즈 없이
2,000줄 파일에서 함수 하나를 찾으려면 1,950줄이 노이즈다. 정규화되지 않은 DB에서 고객 정보를 찾으려면 세 테이블을 조인해야 한다. 엑셀 시트에 숨겨진 비즈니스 규칙은 에이전트가 발견할 수 없다.
읽을 수 있다는 건 사람이 읽을 수 있다는 뜻이 아니다. 기계가 구조적으로 파싱할 수 있다는 뜻이다.
2. 검증할 수 있어야 한다 — 기계적으로
에이전트가 수정한 뒤 뭐가 깨졌는지 알 수 없으면 doom loop에 빠진다. 코드에는 테스트가, DB에는 제약 조건이, API에는 스키마 검증이, 명세에는 교차 검증이 필요하다.
LLM이 LLM을 검증하는 건 술 취한 친구에게 “나 취했어?” 묻는 거다. go test는 환각하지 않는다. CHECK 제약조건은 거짓말하지 않는다. JSON Schema는 표류하지 않는다.
3. 상태가 영속해야 한다 — 에이전트가 죽어도
에이전트는 반드시 뻗는다. 토큰 한도, 네트워크 에러, 세션 끊김. 진행 상태가 저장되지 않으면 매번 처음부터 다시 시작한다.
에이전트 A가 200번 함수까지 처리하고 죽으면, 에이전트 B가 201번부터 이어가야 한다. 에이전트는 일회용이지만 진행은 누적되어야 한다.
0단계: 버그를 박제하라
세 조건은 목적지다. 출발점은 다르다. 문서도 없고, 테스트도 없고, 2,000줄짜리 파일이 300개인 레거시가 출발점이다.
이 상태에서 에이전트에게 “리팩토링해"라고 하면 뭐가 일어나는가? 10년 된 버그를 “고친다”. 문제는, 그 버그가 버그가 아니라는 거다.
Hyrum’s Law: 충분히 오래된 API의 모든 관찰 가능한 행동에 누군가가 의존한다. 10년간 방치된 소수점 반올림 오류에 VIP 고객의 결제 로직이 묶여 있다. 날짜 파싱 버그에 맞춰 만들어진 엑셀 매크로가 경리팀 전체를 지탱한다. 오래된 버그는 암묵적 비즈니스 명세다.
에이전트의 첫 번째 임무는 코드를 고치는 것이 아니다. 현재 동작을 박제하는 것이다.
API를 찔러본다. 응답을 기록한다. 그 응답을 Hurl 테스트로 고정한다. 기괴한 버그든, 의도된 동작이든, 구분하지 않는다. 있는 그대로 박제한다. 이것이 래칫의 첫 번째 톱니다 — 에이전트가 멋대로 “개선"하지 못하게 잠근다.
변경은 오직 명세를 쥔 사람이 결정한다. 에이전트는 실행자다. 판단자가 아니다.
박제가 끝나면 비로소 세 조건 — 읽기, 검증, 영속 — 을 향한 전환이 시작된다.
코드만이 아니다
“agent-operable codebase"는 출발점이다. 기업의 디지털 자산은 코드만이 아니다.
| 자산 | 현재 상태 | Agent-Operable 상태 |
|---|---|---|
| 코드 | 2,000줄 파일, 테스트 없음 | 파일 하나에 개념 하나, 모든 함수에 테스트 |
| 데이터베이스 | 정규화 안 됨, 문서 없음 | DDL 선언적 관리, 마이그레이션 자동 생성 |
| 명세 | 위키, 구두 전달, 드리프트 | 9개 SSOT 교차 검증, 단일 식별자로 체이닝 |
| 문서 | PDF, 엑셀에 숨겨진 규칙 | 스키마 추출, 기계 판독 가능 |
| API | undocumented, 암묵적 계약 | OpenAPI 캡처, 스키마 검증 |
각각 따로 보면 “정리 잘 해야지"다. 합쳐서 보면 시스템이다.
Symbolic Feedback Loop
이 전환을 가능하게 하는 공통 구조가 있다.
LLM이 생성한다 → 결정론적 도구가 판정한다 → 결과를 LLM에 돌려준다 → 반복
코드에서, 테스트에서, 명세에서, 데이터에서 — 같은 루프가 작동한다:
코드 구조: filefunc validate → 위반 피드백 → LLM 수정 → 반복
테스트: go test + coverage → 미커버 라인 피드백 → LLM 보강 → 반복
명세 정합성: yongol check → 드리프트 피드백 → LLM 수정 → 반복
사용자 규칙: rulecat evaluate → 위반 피드백 → LLM 수정 → 반복
LLM이 관여하는 건 “생성"뿐이다. 뭘 수정할지, 통과인지, 다음은 뭔지, 끝났는지 — 전부 기계가 결정한다. LLM에게 판단권을 주지 않는다.
이것은 발명이 아니다. C. elegans는 302개 뉴런 중 60개(20%)를 감각에 투자했다. 생성이 아니라 검증에. 5억 년 진화가 내린 결론이다: 뉴런을 늘리는 것보다 피드백 품질을 높이는 게 생존에 유리하다.
업계는 기차(모델)를 더 빠르게 만들고 있다. 더 큰 모델, 더 똑똑한 에이전트, 더 나은 프롬프트. 하지만 기차가 빨라질수록 선로가 더 중요해진다.
80/20
최종 상태에서 시스템은 두 층으로 나뉜다.
SSOT (80~90%)
├── OpenAPI, DDL, SSaC, FuncSpec, Rego, Hurl, React TSX, Mermaid, manifest
└── 명세에서 생성. 드리프트 원천 차단. 에이전트 자유 수정 가능.
Custom (10~20%)
├── 비즈니스 규칙, 도메인 로직, 법적/정책 계산
└── filefunc으로 구조화, tsma로 테스트 확보. 사람이 확인.
사람이 진짜 신경 써야 하는 코드가 10~20%로 압축된다. 나머지는 에이전트가 명세를 보고 생성하고, 기계가 검증한다.
Fortune 500의 60%
기업 IT 예산의 60~80%가 레거시 유지에 소비된다. 개발자 시간의 42%가 기술 부채 처리에 들어간다. 디지털 전환 프로젝트의 70%가 목표를 달성하지 못한다.
이 예산은 이미 쓰이고 있다. 새 예산을 만들 필요가 없다. 방향만 바꾸면 된다. 유지보수 예산을 전환 예산으로.
레거시를 통째로 넣으면 agent-operable 시스템이 나온다. 그것이 Building Agent-Operable Systems의 약속이다.
왜 빅테크는 이걸 안 하는가
Anthropic과 OpenAI는 범용 모델을 만든다. 모델을 10% 개선하면 모든 고객에게 적용된다. 하지만 Go 테스트 피드백 루프를 만들면 Go 개발자한테만 적용된다. Python 커버리지 도구를 만들면 Python 프로젝트한테만 적용된다.
심볼릭 검증은 본질적으로 도메인 특화다. 언어마다, 프레임워크마다, 명세마다 다른 검증기가 필요하다. 범용성이 없으니까 빅테크의 ROI에 맞지 않는다.
그래서 이 자리가 비어 있다. 기차를 만드는 사람과 선로를 까는 사람은 경쟁이 아니라 보완이다.
질문
당신의 에이전트는 코드를 쓴다. 그런데 그 코드가 맞는지 누가 확인하는가?
다른 에이전트? 아니면 go test?
당신의 LLM은 100,000줄을 전부 읽는가?
아니면 읽는 척하는가?
에이전트 시대에 필요한 건 더 똑똑한 에이전트가 아니다. 에이전트가 일할 수 있는 시스템이다.
출처
- Gartner, “IT Budget and Cost Optimization” — 기업 IT 예산의 60~80%가 레거시 유지에 소비
- Stripe & Harris Poll, The Developer Coefficient (2018) — 개발자 시간의 42%가 기술 부채 처리에 소모
- McKinsey & Company, Why do most transformations fail? (2019) — 디지털 전환 프로젝트의 약 70%가 목표 미달
- Hyrum Wright, Hyrum’s Law — “충분한 수의 사용자가 있으면, 계약에서 무엇을 약속했든 시스템의 모든 관찰 가능한 행동에 누군가가 의존한다”
- Winters, Manshreck, Wright, Software Engineering at Google (O’Reilly, 2020) — Hyrum’s Law의 공식 서적 출처
- White et al., “The structure of the nervous system of C. elegans”, Phil. Trans. R. Soc. Lond. B 314 (1986) — 302개 뉴런 커넥톰
- Inglis et al., The sensory cilia of C. elegans, WormBook (2007) — 60개 감각 뉴런 (전체의 ~20%)
- METR, Early-2025 AI Developer Productivity Study (2025) — AI 도구 사용 시 숙련 개발자 작업 완료에 19% 더 소요, 그러나 개발자는 24% 빨라졌다고 인식
- GitClear, AI Copilot Code Quality 2025 (2025) — 2.1억 줄 분석, 리팩토링 60% 감소, 복사-붙여넣기 코드 48% 증가
- Mehtiyev & Assuncao, Beyond Resolution Rates (2026) — 19개 에이전트 9,374 궤적 분석, 전체 컴퓨트의 12.4%가 수익률 제로 태스크에 소모
변경이력
- 2026-05-27: 초판