Image: AI generated
질문 하나
당신의 프로젝트에서 가장 긴 파일을 열어보라. 함수가 몇 개 들어 있는가?
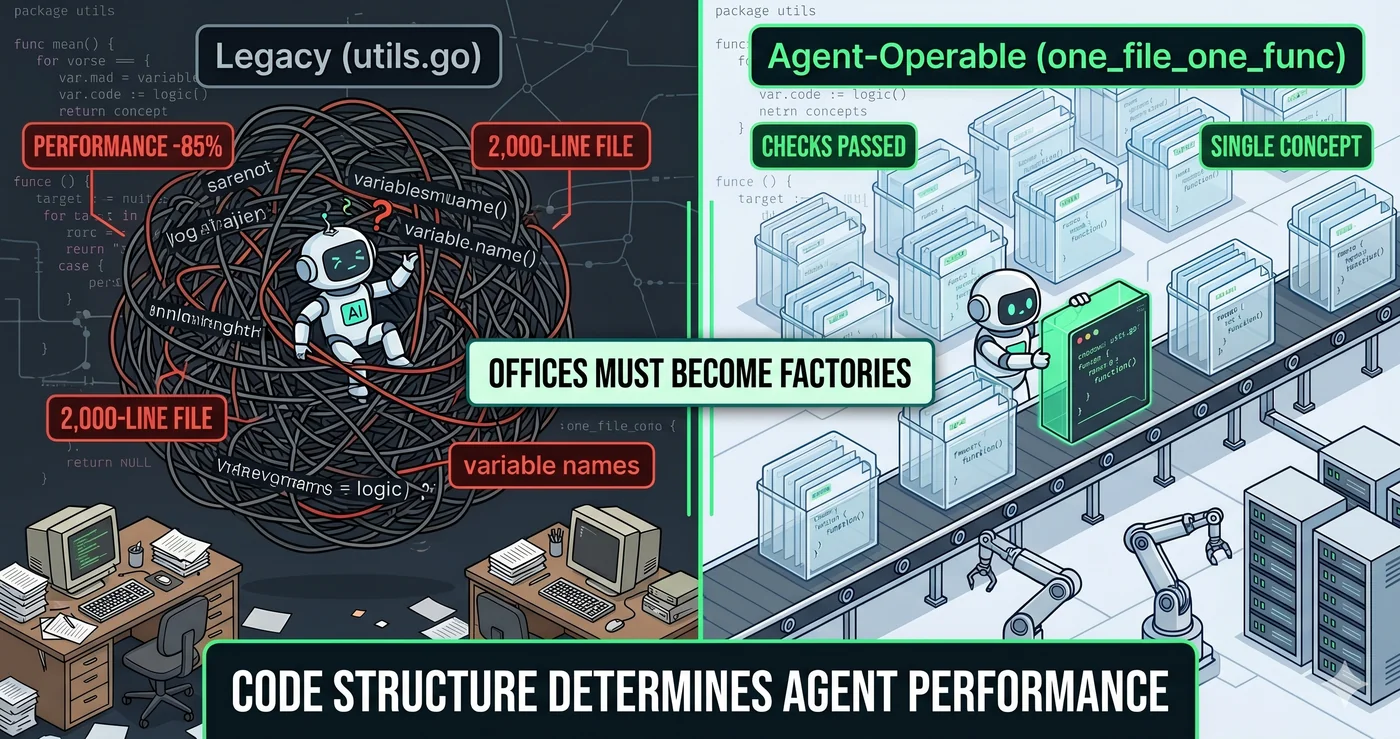
AI 에이전트에게 그 파일에서 함수 하나를 수정하라고 시켜보라. 에이전트는 파일 전체를 읽는다. 함수 하나가 필요해서 열었는데, 19개의 불필요한 함수가 딸려온다.
이것이 문제의 시작이다.
사람이 읽는 코드, 에이전트가 작업하는 코드
지금까지 코드는 사람이 읽는 것이었다. 변수명을 잘 짓고, 주석을 달고, 문서를 쓰는 건 전부 사람의 인지 부하를 줄이기 위해서였다.
에이전트 시대에는 질문이 달라진다. 사람이 읽기 좋은 코드와 에이전트가 작업하기 좋은 코드는 같은가?
같지 않다.
| 사람 | AI 에이전트 | |
|---|---|---|
| 탐색 방식 | 디렉토리 트리를 눈으로 훑는다 | grep으로 검색한다 |
| 파일 열기 | IDE에서 스크롤 | read file — 전체 로딩 |
| 맥락 판단 | 직감 + 경험 | 컨텍스트에 있는 것만 안다 |
| 불필요한 코드 | 무시한다 | 컨텍스트 예산을 소모한다 |
| 2,000줄 파일 | 필요한 부분만 본다 | 전부 처리한다 |
사람은 2,000줄 파일을 스크롤하면서 “이 부분은 건드리면 안 돼"라는 직감이 작동한다. 에이전트에게는 그런 직감이 없다. 2,000줄을 읽으면 1,950줄이 컨텍스트 오염이다.
연구가 이것을 확인한다. 불필요한 정보가 섞이면 AI 성능이 30~85% 떨어진다. 불필요한 토큰이 공백이어도 성능이 저하된다. 컨텍스트가 짧을수록 좋다는 것은 직관이 아니라 실험 결과다.
사람의 사무실에 로봇을 넣으면 안 된다. 로봇이 일할 수 있는 공장을 만들어야 한다. METR의 무작위 대조 실험이 이것을 숫자로 보여준다 — 숙련 오픈소스 개발자 16명이 성숙한 코드베이스에서 AI 도구를 사용했을 때, 완료 시간이 19% 증가했다. 더 빨라진 게 아니라 더 느려졌다(Becker et al., 2025).
에이전트에게 필요한 세 가지
에이전트가 코드베이스에서 안정적으로 작업하려면 세 가지가 갖춰져야 한다.
1. 읽을 수 있어야 한다 — 노이즈 없이
파일 하나에 개념 하나. 파일명이 곧 개념명.
before: utils.go를 read → 함수 20개, 19개 불필요
after: check_one_file_one_func.go를 read → 함수 1개, 정확히 필요한 것
filefunc이 이 문제를 해결한다. 22개 구조 규칙으로 코드를 의미 단위로 분리한다. Hono 프레임워크(star 23k+)에서 186개 파일을 626개로 쪼갰다. 테스트 4,419개, 한 개도 안 깨졌다. 파일이 3.4배 늘었지만 로직은 한 줄도 안 바뀌었다.
“파일이 너무 많아지지 않나?” — 에이전트는 디렉토리를 열지 않는다. 검색한다. 파일이 500개든 1,000개든 grep 한 번이면 끝이다. 필요한 5개를 집는 것보다, 불필요한 295개를 안 여는 게 더 중요하다.
2. 검증할 수 있어야 한다 — 기계적으로
테스트가 없는 함수를 수정하면 뭐가 깨지는지 아무도 모른다. 에이전트도 모른다. doom loop에 빠진다.
before: 테스트 0개, 수정하면 뭐가 깨지는지 모름
after: 527개 함수에 테스트, 동작 변경 시 즉시 감지
tsma가 이 문제를 해결한다. 프로젝트의 모든 함수를 인덱싱하고, 테스트 유무를 감지하고, 커버리지를 측정하고, 미커버 분기를 라인 번호로 피드백한다.
피드백 없이 LLM에게 테스트를 시키면 60~70% 커버리지에서 멈춘다. “line 41, 44, 70 미커버"라고 알려주면 100%에 도달한다. 같은 모델이다. 차이는 피드백의 해상도뿐이다. CoverUp 연구에서도 동일한 결과가 나왔다 — 커버리지 분석을 LLM에 반복적으로 피드백하자, 미커버 라인에 집중시키는 것만으로 모듈별 커버리지가 47%에서 80%로 뛰었다(Pizzorno & Berger, 2024).
527개 함수 프로젝트에서 실험한 결과: TODO 0개까지 완주. 자율 에이전트는 40개에서 “다 했습니다"라고 선언했다. 래칫을 적용하면 527개를 완주한다.
3. 명세가 교차 검증 가능해야 한다
API 스키마, DB 스키마, 보안 정책, 상태 전이가 서로 일치하는지 기계적으로 확인할 수 있어야 한다. 하나를 바꿨을 때 다른 곳과 어긋나는지 컴파일 전에 알 수 있어야 한다.
before: 200개 엔드포인트, 명세 간 정합성을 사람이 확인
after: operationId 하나로 전 레이어 체이닝, 드리프트를 기계가 감지
yongol이 이 문제를 해결한다. 10개 SSOT(OpenAPI, DDL, sqlc, SSaC, Rego, Hurl 등)를 operationId 하나로 체이닝하고 ~287개 규칙으로 교차 검증한다. OpenAPI에는 user_id가 string인데 DDL에는 BIGINT — 이런 레이어 간 모순은 기존 도구로는 잡지 못한다.
세 도구를 관통하는 하나의 구조
filefunc, tsma, yongol은 독립적인 도구지만 공통 구조가 있다.
filefunc: 22개 구조 규칙 → validate → 수정 → 반복
tsma: 커버리지 측정 → 미커버 분기 피드백 → 수정 → 반복
yongol: 교차 검증 → 드리프트 감지 → 수정 → 반복
전부 같은 루프다.
LLM이 생성한다 → 결정론적 도구가 판정한다 → 결과를 LLM에 돌려준다 → 반복
Symbolic Feedback Loop. LLM의 확률적 생성을 결정론적 도구가 교정하는 순환 구조. AI가 AI를 검증하는 것이 아니라, 기계가 AI를 검증한다.
의견을 주면 아첨하고, 사실을 주면 수정한다. “코드 괜찮아?“라고 물으면 “네, 좋습니다"라고 답한다. “line 41: field name mismatch"라고 알려주면 즉시 고친다. 아첨할 대상이 없는 피드백 — 숫자와 위치는 감정이 아니기 때문이다.
레거시에서 agent-operable로
기존 코드베이스를 한 번에 바꿀 필요 없다. 기초 공사가 아니라 내진 보강이다. 영업하고 있는 가게 문을 닫지 않고 건물을 보강한다.
1단계 — 읽을 수 있게 만든다
가장 긴 파일부터 쪼갠다. filefunc validate를 돌리고 위반을 0으로 만든다. 기존 테스트가 전부 통과해야 한다.
2단계 — 검증할 수 있게 만든다
tsma next를 반복한다. 테스트가 없는 함수에 테스트를 추가하고, 미커버 분기를 채운다. 에이전트가 중간에 죽어도 진행은 보존된다. 새 에이전트가 tsma next를 치면 이어간다.
3단계 — 교차 검증한다
SSOT를 도입하고 yongol validate를 건다. 레이어 간 모순을 기계가 잡는다.
각 단계가 독립적이다. 1단계 없이 2단계만 해도 되고, 2단계 없이 1단계만 해도 된다. 하지만 셋이 합쳐지면 에이전트의 자율 작업 범위가 비약적으로 넓어진다.
운영 체제를 바꾸는 일
agent-operable codebase는 단순 lint나 tooling 수준이 아니다. 코드베이스의 운영 체제를 바꾸는 일이다.
| human-readable | agent-operable | |
|---|---|---|
| 파일 크기 | 사람이 스크롤 가능한 범위 | 개념 하나 |
| 테스트 | 있으면 좋고, 없어도 직감으로 | 모든 함수에 필수 |
| 명세 | 문서, 위키, 구두 전달 | 선언적, 교차 검증 가능, 기계가 읽음 |
| 피드백 | PR 리뷰 (시간 단위) | verifier 실행 (초 단위) |
| 종료 판단 | 사람이 “됐다” | 기계가 “아직 487개 남았다” |
GitClear의 분석이 이 전환의 긴급성을 보여준다 — 2020~2024년 2억 1,100만 변경 라인을 분석한 결과, AI 도구 확산과 함께 코드 중복이 8배 증가하고 리팩토링 비율이 25%에서 10%로 감소했다(GitClear, 2025). 선로를 깔지 않으면 기차가 빨라질수록 사고가 난다.
많은 사람이 기차를 더 빠르게 만들고 있다. 더 큰 모델, 더 똑똑한 에이전트, 더 나은 프롬프트.
기차가 빨라질수록 선로가 더 중요해진다. 선로를 까는 사람은 아직 거의 없다.
관련 글
- filefunc — 파일 하나에 개념 하나 — 22개 구조 규칙으로 LLM의 컨텍스트 오염을 제거하는 코드 구조 컨벤션
- tsma — 레거시 코드의 회귀 방어선 — 527개 함수를 TODO 0까지 완주하는 래칫 기반 테스트 자동화
- 코딩 에이전트는 왜 작동하고 왜 무너지는가 — Symbolic Feedback Loop의 구조적 분석
- 모델 IQ보다 피드백 토폴로지 — 같은 모델이 40에서 멈추기도 하고 527을 완주하기도 하는 이유
- whyso — git blame이 보여주지 않는 것 — 파일 단위 변경 이력 자동 추출
출처
- Joel Becker, Nate Rush, Elizabeth Barnes, David Rein. “Measuring the Impact of Early-2025 AI on Experienced Open-Source Developer Productivity.” arXiv:2507.09089, 2025. — 숙련 개발자 16명 RCT, 성숙한 코드베이스에서 AI 도구 사용 시 완료 시간 19% 증가
- GitClear Research. “AI Copilot Code Quality Report.” 2025. — 2억 1,100만 변경 라인 분석, AI 도구 확산과 함께 코드 중복 8배 증가, 리팩토링 비율 25%→10% 감소
- Juan Altmayer Pizzorno, Emery D. Berger. “CoverUp: Coverage-Guided LLM-Based Test Generation.” arXiv:2403.16218, 2024. — 커버리지 피드백 반복으로 모듈별 커버리지 47%→80% 달성
- Kelly Hong, Anton Troynikov, Jeff Huber. “Context Rot: How Increasing Input Tokens Impacts LLM Performance.” Chroma Technical Report, 2025. — 18개 모델에서 입력 토큰 증가에 따른 성능 저하 실증
- Mrinank Sharma et al. “Towards Understanding Sycophancy in Language Models.” ICLR 2024 (arXiv:2310.13548). — 5개 AI 어시스턴트의 아첨 행동 분석, 인간 선호도 학습이 아첨을 강화하는 구조 규명
- Google DORA Team. “Accelerate State of DevOps Report.” 2024. — AI 도입 25% 증가와 동시에 배포 안정성 7.2% 감소
- Dantas et al. “The 4/δ Bound: Designing Predictable LLM-Verifier Systems for Formal Method Guarantee.” arXiv:2512.02080, 2025. — LLM-검증기 반복 루프의 수학적 수렴 상한 증명
근거 자료
- Stanford, “Lost in the Middle: How Language Models Use Long Contexts” (2024) — 관련 정보가 컨텍스트 중간에 묻히면 30%+ 성능 하락
- Amazon, “Context Length Alone Hurts LLM Performance” (2025) — 불필요한 토큰이 공백이어도 13.9~85% 성능 하락
- Hono 프레임워크 실증 — 186개 파일 → 626개 파일 분리, 테스트 4,419개 전부 통과
- tsma 527개 함수 실증 — PASS 246개(46.7%), DONE 281개(53.3%), TODO 0개
- Ratchet Pattern 실험 — 자율 에이전트 40/527 (7.6%) vs 래칫 CLI 527/527 (100%)
변경이력
- 2026-05-25: 초판