 Image: AI generated
Image: AI generated
賢い人が説明上手とは限らない
Opus 4.8にコードリファクタリングを任せると感嘆が漏れる。複雑な依存関係グラフを一発で解き、エッジケースを先回りして処理し、テストまで隙なく書く。ところが、その結果を説明してくれと頼むと問題が始まる。専門家が専門家に報告するように話す。背景知識を当然共有していると仮定し、核心的判断の理由を省略し、抽象化のレベルが不必要に高い。
Opus 4.6に同じことを聞くと正反対だ。こちらが何を知らない可能性があるかをうまく推定する。比喩を選んで使い、段階を分け、文脈を先に敷いてくれる。しかし推論の難度が上がると、4.8が一発で突破する問題でつまずく。
一文で要約するとこうなる:Opus 4.8は賢いが難しく話し、Opus 4.6はわかりやすく説明するが推論性能が低い。
これは欠陥ではない。なぜそうなるのか、そしてこの違いをどう構造的な強みに転換するかがこの記事のテーマだ。
知識の呪いはLLMにも当てはまる
1989年、心理学者Camerer、Loewenstein、Weberは実験で証明した。情報を多く持つ人ほど、相手がその情報を知らないという事実を適切に考慮できない。「知識の呪い(Curse of Knowledge)」と呼ばれるこの現象は、教育学、経済学、UXデザインで繰り返し確認された認知バイアスだ。
オリバー・ウェンデル・ホームズはこう言った。「複雑さの手前にある単純さには一文も出さない。しかし複雑さの向こうにある単純さには命を賭ける。」やさしい説明は知らないからやさしいのではなく、複雑さを貫通した後にはじめて可能になる。しかし逆説的に、複雑さの渦中にいる間はやさしく話す能力が落ちる。
2025年のEMNLP論文は、この現象が大規模推論モデルでも現れることを示した。より強力な推論能力を持つモデルほど知識の呪いにより脆弱だという逆説的な結果だ。深く推論するモデルは、自分の推論過程を相手も追えると暗黙のうちに仮定する。人間の専門家が初心者に説明する際に直面するまさにその問題だ。
だから世の中には二種類の役割がある。深く考える人とわかりやすく伝える人。研究者と科学コミュニケーター。シニアエンジニアとテックリード。裁判官と弁護士。この二つは異なる能力だ。一人が両方とも得意ならいいが、実際には稀だ。だから組織は役割を分離する。
LLMも同じだ。そしてClaude Codeはこの分離を設定一行で可能にする。
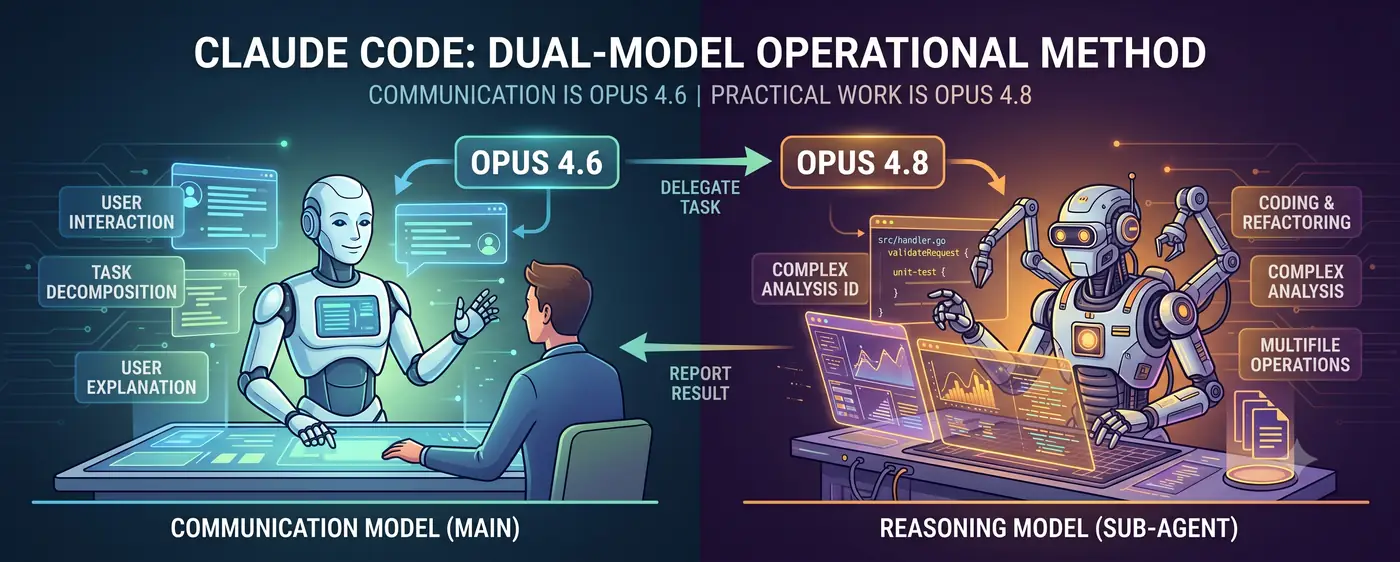
コミュニケーションモデル + 推論モデル
核心の構造はシンプルだ。
ユーザー ↔ コミュニケーションモデル(メイン) ↔ 推論モデル(サブエージェント)
- コミュニケーションモデル(Opus 4.6)が対話の前面に立つ。ユーザーの意図を把握し、作業を分解し、結果を人間が理解できる言葉で報告する。
- 推論モデル(Opus 4.8)が実務を処理する。コード作成、複雑な分析、マルチファイルリファクタリングのような高難度の推論タスクをサブエージェントとして委任され実行する。
ユーザーは4.6と対話する。4.6が「これは自分で直接やるには推論の難度が高い」と判断すると、4.8のサブエージェントを生成して作業を委任する。4.8が結果を返すと、4.6がそれを解釈してユーザーに説明する。
この記事自体がその証拠だ。今この記事を書いているのはOpus 4.6(メイン)であり、この記事の根拠となる学術論文の検索とベンチマークデータの分析はOpus 4.8(サブエージェント)が行った。
ベンチマークが語ること
BenchLMのデータを見ると、二つのモデルの性格が数字に表れる。
| 領域 | Opus 4.6 | Opus 4.8 | 優位 |
|---|---|---|---|
| 総合 | 86 | 93 | 4.8 |
| コーディング | 64.4 | 76.4 | 4.8 |
| エージェントタスク | 72.6 | 80.1 | 4.8 |
| 知識タスク | 76.2 | 70.1 | 4.6 |
| 創作ライティング | 優位 | - | 4.6 |
コーディングとエージェントタスクでは4.8が圧倒する。しかし知識伝達と創作ライティングでは4.6がリードする。Claude APIのレビューでも、4.8の文章が4.6より「よりAIっぽい(more AI-sounding)」という評価が繰り返されている。4.8は正確に推論するが、その推論を人間が読みやすく解きほぐす能力は4.6の方が優れている。
二つのモデルの価格は同一だ — 入力100万トークン$5、出力100万トークン$25。役割を分けてもコストは増えない。これはコスト最適化ではなく、純粋な品質の最適化だ。
モデルルーティングはすでに実証された工学だ
「二つのモデルを使い分ける」というアイデアは目新しいものではない。学術界ではすでに確立された分野だ。
RouteLLM(ICLR 2025)はクエリを強いモデルと弱いモデルの間で動的ルーティングし、コストを2倍以上削減しながら品質を維持した。FrugalGPT(2023)はLLMカスケードでGPT-4レベルの性能を98%のコスト削減とともに達成した。これらの研究の共通結論は明確だ:オーケストレーションに優れた弱いモデルが、オーケストレーションの貧弱な強いモデルをしばしば凌駕する。
Anthropic自身もこのパターンを使っている。Anthropicのdeep-research実装はオーケストレーター-ワーカーパターンであり、マルチエージェント構成が単一エージェントのOpus 4を90.2%上回った。プロダクションのマルチエージェントシステムの約80%がオーケストレーター-ワーカー構造だという調査結果もある。
私がやっているのは、このパターンの最もシンプルな形だ。ルーターも、カスケードも、コスト最適化もない。ただコミュニケーションに最適化されたモデルが前面に立ち、推論に最適化されたモデルが裏方で働く。役割分離の原理そのものだ。
設定方法
Claude Codeでこの構造を作るのは簡単だ。
1段階:メインモデルの設定
Claude CodeをOpus 4.6で起動する。設定でデフォルトモデルをclaude-opus-4-6-20250610に指定するか、起動時にモデルを選択する。これがユーザーと対話するコミュニケーションモデルになる。
2段階:サブエージェントにモデルオーバーライド
Claude CodeのAgent toolはmodelパラメータをサポートしている。サブエージェントを生成する際にモデルをopus(Opus 4.8)にオーバーライドすればよい。
Agent({
description: "コードリファクタリング",
model: "opus",
prompt: "src/handler.goのvalidateRequest関数を..."
})
これで終わりだ。メインエージェント(4.6)がユーザーと対話し、高難度の作業はサブエージェント(4.8)に委任する。
3段階:forkとfresh agentの区別
Claude Codeのサブエージェントには二種類ある。
- fork(
subagent_type: "fork"):現在の対話のコンテキストをそのまま引き継ぐ。プロンプトキャッシュを共有するため入力コストが最大90%削減される。ただし、forkは親モデルを強制的に引き継ぐため、モデルオーバーライドは適用されない。 - fresh agent:新しいコンテキストから開始する。モデルオーバーライドが可能だ。プロンプトに必要な背景を自分で入れなければならない。
したがって推論モデル(4.8)を使うにはfresh agentで生成する必要がある。forkはコミュニケーションモデル(4.6)を維持したまま並列探索が必要な場合に使う。
実践パターン
| 状況 | 方法 | 理由 |
|---|---|---|
| 複雑なコード作成 | fresh agent + model: opus | 推論難度が高い |
| マルチファイルリファクタリング | fresh agent + model: opus + isolation: worktree | 推論 + 分離が必要 |
| 並列調査・探索 | fork(4.6維持) | コンテキスト共有が有利 |
| 単純なファイル読み取り・編集 | メイン(4.6)直接 | 委任のオーバーヘッドの方が大きい |
| Web検索・リサーチ | fresh agent + model: opus | 正確な推論が必要 |
4〜8個の同時ワークツリーまでは安定的だ。それ以上は結果レビューがボトルネックになる。
既知の摩擦
完璧ではない。現在知られている制約が二つある。
一つ目は、モデルオーバーライドの漏洩問題。サブエージェントのmodel設定が、そのサブエージェントが生成する下位エージェントにまで伝播する可能性がある。意図しないモデル使用が発生し得るため、サブエージェントの深さを1段階に制限するのが実用的だ。
二つ目は、エージェントごとのモデル設定の不在。現在のClaude Codeは、プロジェクト設定でエージェントタイプごとにモデルを事前指定する機能を公式にはサポートしていない。毎回Agent呼び出し時にmodelパラメータを明示する必要がある。コミュニティでもこの機能へのリクエストは活発だ。
二つともClaude Codeが進化すれば解消される摩擦だ。現状でも手動オーバーライドだけで構造の恩恵は十分に享受できる。
コミュニケーターと思索家は異なる役割だ
法廷で裁判官と弁護士は同じ法律を扱うが役割が違う。裁判官は判断する。弁護士はその判断がどういう意味かを依頼人に説明する。裁判官が依頼人に直接判決文を読み上げれば、依頼人は理解できない。弁護士が判決を直接下せば根拠が不十分になる。役割分離はシステムの弱点ではなく強みだ。
コードレビューでも同様だ。シニアエンジニアがバグを見つける能力と、ジュニアエンジニアにそのバグを理解させる能力は別物だ。優れたエンジニアが優れたテクニカルライターであるケースは稀だ。組織はそれを知っているから役割を分ける。
AIも同じだ。推論能力とコミュニケーション能力は異なる軸だ。そして現在のモデル学習過程において、この二つの軸はトレードオフの傾向がある。推論性能を極大化すると出力は圧縮的で専門的になり、コミュニケーション性能を極大化すると推論の深さが浅くなる。
単一モデルに両方とも上手くやれと要求するのは、裁判官に弁護士の役割まで果たせと言うのと同じだ。できなくはない。しかし両方とも最適にはならない。
コミュニケーションモデルと推論モデルの分離は、バージョンが変わっても有効な構造的原理だ。 4.6と4.8は今日の具体的な選択に過ぎない。明日5.0と5.2が出れば、同じ原理で再配置すればいい。モデルは入れ替わるが、「深く考える役割」と「わかりやすく伝える役割」が異なるという事実は入れ替わらない。
関連記事
合わせて読みたい
- RouteLLM: Learning to Route LLMs with Preference Data — クエリの難度に応じて強いモデルと弱いモデルを動的ルーティングするフレームワーク。
- Anthropic: How we built our multi-agent research system — Anthropicがオーケストレーター-ワーカーパターンでdeep-researchを実装した方法。
出典
- Camerer, C., Loewenstein, G. & Weber, M. (1989). The Curse of Knowledge in Economic Settings: An Experimental Analysis. Journal of Political Economy, 97(5), 1232-1254. DOI — 知識の呪いの実験的証明。
- Li, W. et al. (2025). Curse of Knowledge: Your Guidance and Provided Knowledge are biasing LLM Judges in Complex Evaluation. Findings of EMNLP 2025. arXiv — 強い推論モデルが知識の呪いにより脆弱だという発見。
- Ong, I. et al. (2025). RouteLLM: Learning to Route LLMs with Preference Data. ICLR 2025. arXiv — 選好データでLLMルーティングを学習するフレームワーク。