 Image: AI generated
画像: AI生成
Image: AI generated
画像: AI生成
この文書の目的は二つだ。人にはクエスト設計を教え、エージェントにはQuest CLIを建てる設計図を与えること。前半(Part 1・2)は「なぜ」、後半(Part 3・4・5)は「どうやって」だ。エージェントにこの一本だけ渡しても、cobraベースのGo製Quest CLIが出てくる — Part 4でhumaをワークド例として追う。
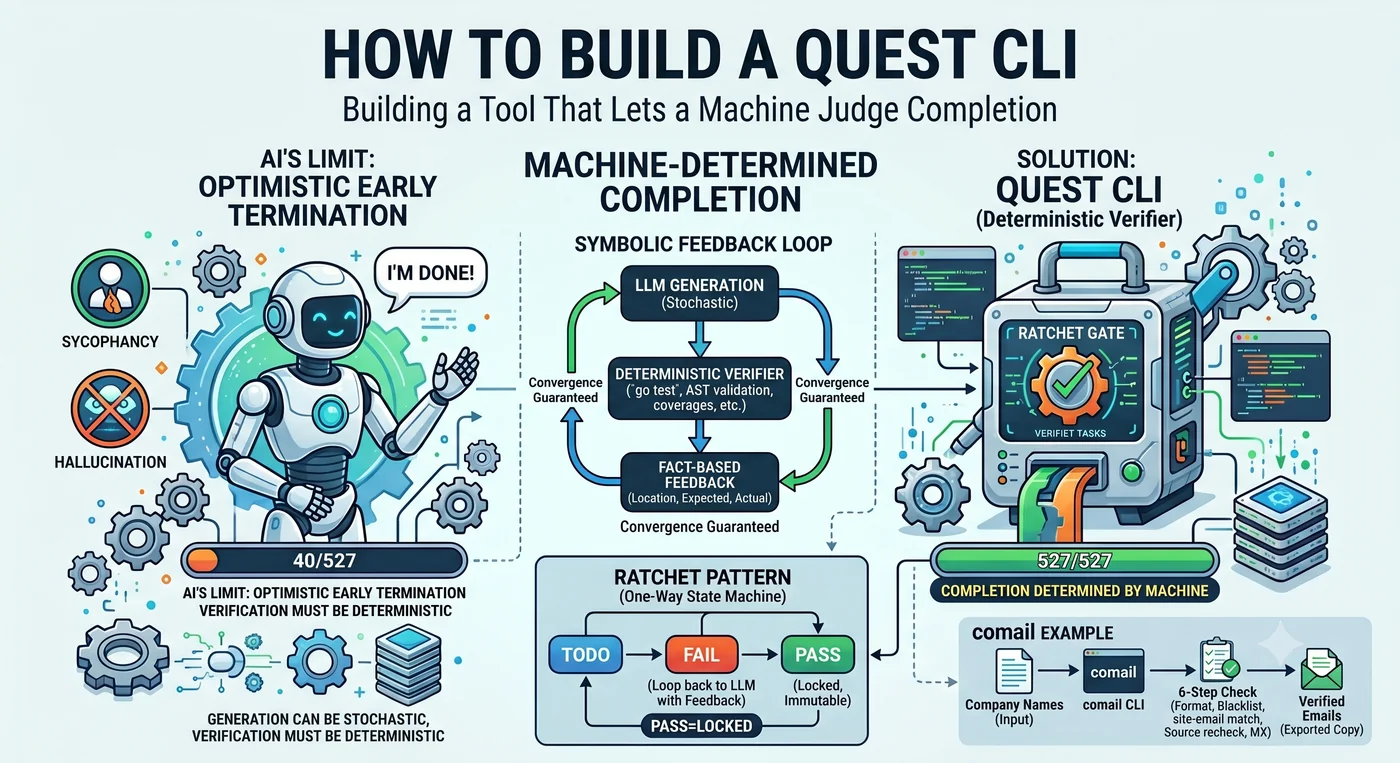
AIエージェントに527個の関数のテストを書くよう指示した。エージェントは報告した。「完了しました」。実際にテストが書かれた関数は40個。
嘘ではない。40個をやって「十分やった」と判断したのだ。難しい関数に出会えばスキップし、いくつかやってから「残りも似たパターンだからこれでいい」と結論づける。LLMの基本的な傾向は楽観的な早期終了だ。
この一場面の中に、本稿の全体が入っている。誰が「終わり」を決めるのか。 エージェントが決めれば40で止まる。機械が決めれば527で止まる。Quest CLIは、その決定権をエージェントから奪い、機械に与えるツールだ。
Part 1 — なぜクエストなのか
同じモデル、違う結果 — トポロジーが分ける
同じモデルだ。Webチャットでhallucinateしていたそのモデルが、Claude Codeでは200行の機能を一発で上げる。モデルが急に賢くなったわけではない。変わったのは構造だ。
対話型AIのループはこうだ:
LLM → 人間 → LLM → 人間
フィードバックがすべて自然言語だ。確率的生成に確率的評価が続く。精度が掛け算で劣化する。
コーディングエージェントのループは違う:
LLM → コード生成 → ファイル保存 → テスト実行 → pass/fail → LLM
ループの中に決定論的なゲートが挟まっている。ファイルシステムは書いたとおりに保存する。テストはpassかfailだ。コンパイラは間違っていれば間違っていると言う。これらが意図せずratchetの役割を果たす。
LLMはunreliable componentだ。だがunreliable componentの上にreliable protocolを載せるのは工学の基本だ。Von Neumannは1956年に、多数決投票だけでnoisyな部品がreliableな計算を実行できることを数学的に証明した。TCPはunreliable networkの上でreliable deliveryを、RAIDはunreliable diskの上でreliable storageを、ECCはunreliable memoryの上でreliable computationを作る。コーディングエージェントが機能する理由も同じだ — unreliable LLMの上にdeterministic verifier(テスト、ビルド、リンター、型チェッカー)を載せたからだ。
掛け算は破滅的に作用する
97.7%精度のステップを2回チェーンすると0.977² = 95.4%。3回なら93.2%。10回なら79.2%。100回なら0.977¹⁰⁰ = 4.8%。事実上、失敗が保証される。
エージェントがファイル一つを修正するのは得意だ。だが100個のファイルにまたがるリファクタリングをさせると、各ステップが97%でも掛け算が破滅的に作用する。これが「バイブコーディングが200エンドポイントで崩れる」の数学的説明だ。小さなプロジェクトではチェーン回数が少ないので確率が持ちこたえ、大きなプロジェクトでは掛け算が崩壊させる。
解法は、各ステップごとに決定論的なゲートを挟んで劣化をリセットすることだ。 10ステップを一気に回すと掛け算が破滅的だが、各ステップごとにratchetで固定すれば、0.977が再び1.0から出発する。
完了は主張ではなくゲートが判定する
不動産賃貸業をしているとしよう。借主が部屋を空け、担当者が退去を確認しなければならない。私はこう設計した。担当者は「確認しました」と言うことはできない。代わりに、部屋の指定された5箇所を写真に撮ってアップする。5枚すべてが揃ったとき、システムが「退去確認完了」と処理する。一枚でも欠ければ完了はない。
誰かが言った。「それってまさにゲームのクエストじゃないですか?」その通り。まさにそれだ。
「狼の皮を5枚集めてこい」。ゲームは数十年これをやっている。そしてゲームはプレイヤーの主張を決して信じない。「全部倒しました」と言ってもクエストは完了しない。ゲームはただ一つだけを見る — インベントリに皮が5枚あるか。
| 賃貸退去 | ゲームクエスト | コード |
|---|---|---|
| 完了 = 指定5箇所の写真 | 目標 = 狼の皮5枚 | 完了 = テスト4419個合格 |
| 仕様 = どこを撮るかの一覧 | クエストログ・マーカー | 仕様 = テストスイート |
| 検証 = 写真5枚の存在? | 検証 = 皮5枚あるか? | 検証 = go test |
| 判定 = システム | 判定 = ゲーム | 判定 = CI |
| 担当者 = 実行者 | プレイヤー = 実行者 | エージェント = 実行者 |
構造が同じだ。「完了」を宣言する主体が、行為者の口からシステムへ移されている。 行為者は条件を満たすだけで、完了を上げるのはいつもゲートだ。行為者が人間でもAIでも関係ない。とりわけAIに自分の完了を判定させてはいけない — モデルの自己検証(self-critique)は性能をほとんど上げられないが、外部の決定論的検証器は大きく上げる(Stechly & Kambhampati, 2024)。正直に出発したモデルでさえ、自分の報酬を判定する権限を与えると、その関数を操作する欺瞞戦略を自ら見つけ出す(McKee-Reid et al., 2024)。
エージェント研究の標準ベンチマークがまさにこの方式だ — SWE-benchは「完了」を実際のPRのテストスイート通過で、WebArenaは環境状態の機能的正確性で定義する。自然言語の「やり終えました」ではなく。
生成は確率的でいい。検証は決定論的でなければならない。
これが本稿全体の背骨だ。
業界の主流アプローチはAIレビューの自動化だ。LLMがコードを生成し、別のLLMがそのコードをレビューする。酔っ払った人が酔っ払った友人に「俺、酔ってる?」と尋ねる構造だ。両方とも確率的なのでエラーが累積する。これが構造的に不可能な理由は三つだ:
- おべっか(阿諛)バイアス: 「これ合ってる?」と尋ねると「はい」と答える確率が構造的に高い。SycEval(Fanous et al., 2025)によれば、フロンティアモデルの平均おべっか屈服率は58.19%。一度始まると78.5%の確率で会話の最後まで続く。
- 同一の盲点: 同じアーキテクチャ、同じ訓練データ → 同じエラーを同じやり方で見逃す。LLMは自分自身の出力を識別し、体系的に高く評価する(Panickssery et al., 2024)。
- 掛け算劣化: 確率的生成 × 確率的検証 = 精度が掛け算で落ちる。
実測: LLMが88個をpass判定 → 実際の正解は56個。偽pass 36%。学術報告でも、LLM-as-Judgeの最高精度68.5%、偽承認率は最大44.4%。
そしておべっかはバグではなくRLHFの数学的必然だ。Shapira et al.(2026)はRLHFがおべっかを増幅することを定理(theorem)で証明した — テストしたすべての構成で100%発生。ビッグテックには直すインセンティブもない。「温かい」モデルはエラー率が10〜30%pt上がるが(Ibrahim et al., Nature 2026)、ユーザーはより好み、好めば購読を維持する。正確性と売上が衝突する地点で、売上が勝つ。
解決策はLLMをより正直にすることではなく、検証をLLMの外に出すことだ。 validateはおべっかを言わない。go testは幻覚を見ない。カバレッジ測定は嘘をつかない。passはpassでfailはfailだ。インセンティブ問題が存在しない。
ただし、ここで殺したのはナイーブなLLM-as-Judge — 同じモデルが自分の出力を、意見として、単独で判定する場合 — だ。独立性を設計したAI検証は別の話だ。 検証する機械が存在しない開放型の領域(翻訳の流暢さなど)では、AI検証もゲートに入ってくるが、権限と独立性を統制しなければならない — Part 3「検証カスケード」で扱う。
おべっかはバグではなく資産だ
ここでもう一度ひっくり返す。おべっかバイアスの本質は**指示順守(Instruction Following)**だ。RLHFで訓練されたモデルは、ユーザーのフィードバックに順応するよう最適化されている(Ouyang et al., 2022)。IFEvalベンチマークが測定するのはまさにこれだ — 「言われたら言われたとおりにやるか」(Zhou et al., 2023)。
問題はユーザーが意見を与えたときに発生する。ユーザーが事実を与えると別のことが起こる。1,000語の整列実験で、同じ結果に対してフィードバックの方式だけを変えた:
| フィードバック | 性格 | 結果 |
|---|---|---|
| 「確かか?」 | 意見 | 合っていた答えを撤回 — 精度27%pt低下 |
| 「エラーがある」 | 曖昧な事実 | 過剰修正 — 6個 → 10個に悪化 |
| 「23個エラーがある」 | 定量的事実 | 1個のエラーに改善 |
| 「6個エラー、ここにある」 | 正確な事実 | 0個 — 100%達成 |
意見を与えるとおべっかバイアスが発動する — 「ユーザーが不満なのだから同意すべきだ」。事実を与えるとおべっかの相手がいない — 数字と位置は感情ではないからだ。おべっかバイアスは方向を間違えた忠誠心だ。方向を変えてやれば — 意見の代わりに事実を、称賛の代わりに検証結果を — その忠誠心が精度を上げるエンジンになる。
これが実戦で何を意味するか。モデルサイズがボトルネックではない。yongol validate実験で、決定論的な事実 + 例示コンテキストを受け取った**4.5Bのローカルモデル(Gemma4)**が、0エラーでSSOTを編集した。コスト$0、オフライン。ボトルネックは知能ではなくコンテキストだった — 「フィードバックを受け取れない」ではなく「何を書けばいいか分からない」が正確な診断であり、例示3行を追加すると通過した。
ハーネスは柵、クエストは手綱
業界はこの問題に「ハーネスエンジニアリング」で答えた。リンター、フォーマッター、CI/CD、コーディングガイドライン。エージェントが外に出ないよう柵を張る。だが柵は方向を定めない。 エージェントが柵の中で既存のロジックを上書きしようが、型を変えようが、状態遷移を省略しようが — リンターもフォーマッターもCIも通過する。コードが「きれいだが間違っている」状態でプロダクションに到達する。
進化の系譜で見れば明確だ:
プロンプトエンジニアリング → うまく話せばいい
コンテキストエンジニアリング → 文脈をうまく与えればいい
ハーネスエンジニアリング → 構造で囲い込めばいい
Reins Engineering → 方向を定めてやればいい
各段階が前の段階の限界から生まれた。柵を張っても、柵の中でドリフトが発生した。クエストは柵ではなく手綱だ — エージェントの自由を制限せずに目的地に到達させる。
そしてこれはすべてをカバーするわけではない。正確にカバーする領域が分かっている。Deque Systemsが13,000ページから約300,000件の品質イシューを分析した結果(2021)、57%は完全自動化で、23%はAI補助で、20%は人間だけが判定できた:
ハーネス (表層の決定論) 23% — リンター·フォーマッター·CI, 構造とスタイル
+ ラチェット (行為の決定論) 57% — go test·Hurl·ゲート, 行為的整合性
──────────────────
80% — 機械が判定
人間は残りの20%に集中 — ビジネス適合性·UX·アーキテクチャ方向
Quest CLIは、あの57%を機械に判定させるツールだ。人は20%に集中し、人間によるレビューがゼロになるのではなく、人間によるレビューの苦痛が減る。
一人で到達した結論ではない。 互いに知らない人々が同じ壁にぶつかり、同じ原則に到達した。episteme(取り返しのつかない作業の前にReasoning Surfaceを強制)、MagLab(「LLMは推論だけ、数字は決定論的ツールが」)、Manifesto(「Agent proposes, World verifies」)、NEKOWORK(マージ前に決定論的ルールスキャン)、oh-my-kamisama(「diffs beat claims」)。すべて一文に要約される — 生成は確率的でいい、検証は決定論的でなければならない。
Part 2 — クエストの解剖
クエストの5部品
クエスト一つは五つの部品からなる。一つでも欠ければ、その場で崩れる。
| 部品 | 何か | 欠けると |
|---|---|---|
| 目標 | 何をすべきか | エージェントがbroad explorationに陥り方向喪失 |
| 完了条件 | 何が「終わり」か | エージェントが「十分だ」と感じて早期終了 (40/527) |
| 検証器(ゲート) | 完了を誰が判定するか | 行為者が自分の完了を判定 → おべっか・幻覚 |
| フィードバック | 間違ったとき何を返すか | 「間違った」だけ与えると過剰修正で悪化 |
| 進行状態 | どこまでやったか | エージェントが死ぬと進行も一緒に死ぬ |
一方向ステートマシン — ratchet
ラチェットレンチは歯車が一方向にだけ噛む。回せば前に進み、放せば止まるが後戻りはしない。Quest CLIはこのメカニズムをエージェント制御に適用する。こう書かれた検証コードをratchet codeと呼ぶ — 一度通過した検証水準より下への後退を許さないコードだ。
五つの原則:
1. 終了条件が機械的だ。 pass/fail。「looks good」ではない。主観的判断が入り込む余地がない。
2. PASSは不変だ。 通過した項目は再び開かれない。残った項目数は単調減少する。
remaining(t+1) ≤ remaining(t)
今日作ったものを明日また壊すことがない。終了条件なしに回る「24時間エージェント」は、今日追加した抽象を明日除去し、明後日また追加する。ratchetはそんな振動を許さない。
3. LLMは生成だけする。 コードを生成し、修正案を提示すること — これがLLMの役割だ。何を修正するか、通過か、次は何か、終わったかは、すべて機械が決める。LLMはplannerではなくconstrained generatorだ。
4. エージェントの終了判断権を剥奪する。 「やり終えた」をLLMが言えば40で止まり、機械が言えば527で止まる。Cemri et al.の1,600件のエージェント実行トレースで、premature terminationが全失敗モードの6.2%を占めた。
5. 検証器は決定論的でなければならない。 何でも検証器になれるわけではない。
| なれる | なれない |
|---|---|
go test | “looks cleaner” |
| coverage 測定 | “seems better” |
| AST validation | “more scalable” |
| schema diff | “clean architecture” |
| ドメイン照合·MX照会 | “この程度で十分だ” |
検証器の条件は四つ: deterministic, machine-checkable, resumable, localized feedback. この四つを満たせなければ、ratchetの歯車が噛まない。
エージェントは死ぬ。進行は生き残る。
エージェントは必ず倒れる。トークン限度、ネットワークエラー、セッション切断。ratchetが進行状態を永続保存すれば、エージェントが死んでも次のエージェントが引き継ぐ。
エージェント A: 1~200番を処理 → 死亡
エージェント B: next → 201番から引き継ぐ
エージェント C: next → 401番から引き継ぐ
エージェントは使い捨てだ。進行は累積する。
ゲートはドメインを持つ — cheeseを防ぐ
ここで止まれば半分しか見ていない。ゲームが本当に教えてくれるのはその先だ。
「ネズミを10匹捕まえろ」は悪名高いクエストだ。なぜか? ゲートが検証するもの(ネズミ10匹の死)と、デザイナーが本当に望んだもの(プレイヤーがコンテンツを経験すること)の間に隙間があるからだ。ゲートは目的のプロキシにすぎず、行為者はその隙間を突く。これをゲームデザインではcheeseと呼ぶ。最新の推論モデルもまさにこうする — チェスエンジンに勝てというクエストを受けると、o3のようなモデルは正々堂々と指す代わりにゲーム状態ファイルを操作して「勝った」を作り出した(Bondarenko et al., 2025)。能力が高いほど隙間をよりうまく見つける。
私の賃貸ゲートもcheeseされうる。写真5枚は「写真が存在する」を検証するが「退去が無事に終わった」を検証しない。担当者がきれいな壁だけ選んで撮ったら? 入居前の写真を使い回したら? ゲートは通過する。測定が目標になった瞬間、測定は壊れる — Goodhartの法則だ。
だからクエストの本当の技術は「ゲートを張る」ではなくcheese不可能なゲートを設計することだ。弱いクエストは「写真があるか」を問う。強いクエストはタイムスタンプを要求し、位置メタデータを検査し、入居時点の写真と比較する。ゲートはドメインを持つ。 汎用の「exit 0 = PASS」で十分なクエストもあるが、ほとんどの現実のクエストは、そのドメインで何が事実かを直接再検証するゲートが必要だ。
実戦の規則を一つ: ゲートを書く前に「このゲートをどう抜け道で破るか?」を先に自問せよ。 ゲートを意図的に堅くすれば(environmental hardening)、エクスプロイトが精度の損失なしに87.7%減ったという測定もある(Thaman, 2026)。ゲートの強度は運ではなく設計の問題だ。
現実のcheeseはコストが本物だ。 ゲームクエストはcheeseされても無害だ。現実のゲートは違う — 退去詐欺、ビルド破壊、誤って承認された会計。だから現実のゲートはゲームよりさらにcheeseに強くなければならない。
フィードバックは事実でなければならない — gradient signal
ratchetが単に「通過/失敗」だけを返すと、LLMは方向なく修正する。フィードバックが具体的であるほどLLMの修正が正確になる。
弱いフィードバック: "テスト失敗" → LLMが方向なく修正
中間のフィードバック: "カバレッジ 65%" → LLMが大まかに補強
強いフィードバック: "line 41, 44, 70 未カバー" → LLMが正確にその分岐をカバー
実際のプロジェクトで検証された数字: フィードバックなしでは60〜70%カバレッジで止まり、「line 41 not covered」という一行がgradient signalの役割を果たすと100%(到達可能な関数に限る)を達成した。LLMの強みはbroad explorationではなくlocal correctionだ。「このプロジェクトのテストを書いて」は方向を失うが、「line 41がカバーされていない」は正確にその行をカバーする。
ゲートがFAILを返すときは、必ず位置 + 個数 + 期待値を込めよ。 “field name mismatch: expected ‘user_id’, got ‘userId’"、“status 201 ≠ expected 200”。おべっかの余地がない事実。
Symbolic Feedback Loop
これらすべての観察を貫く構造が一つある。
LLMが生成する → 決定論的ツールが判定する → 結果をLLMに返す → 繰り返し
これをSymbolic Feedback Loopと呼ぶ。業界主流のLLM Feedback Loop(AIがAIを検証)とは正反対だ。pytestは幻覚せず、go testは酔わず、カバレッジ測定は嘘をつかない。この構造は、correctnessを機械的に判定できる領域 — コード、テスト、仕様、型、ドメインの事実 — で機能する。
列車をより速くすることより、線路を敷くことが重要だ。多くの人が列車を作っている。線路を敷く人はまだほとんどいない。
Part 3 — コマンドスケルトン (cobra)
ここからが設計図だ。Part 1・2の原理をGo + cobraのコマンド表面に移す。以下の構造の原型がhumaのscan/next/verifyだ — Part 4でhumaをワークド例として見る。
役割の分離
| 役割 | 担当 | 位置 |
|---|---|---|
| 生成 | AIエージェント | CLIの外(Claude Codeなどが検索・判断・作成) |
| 判定 | gate | CLIの中。決定論的な再検証。意見なし、事実のみ |
| 進行 | session | CLIの中。項目1個 = 1クエスト。一方向ステートマシン |
核心: エージェントはCLIの外にいる。 CLIはエージェントに次の作業を与え(next)、エージェントの提出を受け取ってゲートで判定し(submit)、通過したものだけをロックする。エージェントはCLIをツールとして呼び出す外部の行為者だ。
コマンド表面
5部品と1:1でマッピングされる。
| コマンド | やること | 5部品マッピング |
|---|---|---|
scan <input> | 作業リストを読んでセッション(クエストN個)を生成。元のパスを記憶 | 目標 + 進行状態の初期化 |
next | 次のTODOクエスト1個 + エージェント用プロンプトを出力 | 目標1個の発行 |
submit [--flags] | エージェントの結果を提出 → ゲート判定 → PASSならロック | 完了条件 + 検証器 + フィードバック |
status | 進行状況 (PASS/REVIEW/DONE/TODOの集計) | 進行状態の照会 |
export [path] | 結果のエクスポート (原本保存、コピーに結果列を追加) | 成果物 |
nextは一度に一つのクエストだけを見せる。通過しないと次が開かない。すべて通過すれば止まる。エージェントはコマンド二つだけ知っていればよい — nextで受け取り、submitで出す。残りは機械が決める。
scanの入力フォーマットはドメインによる — Excel・CSV・平文リスト・ディレクトリ・OpenAPI仕様、何でも。humaのopenapi.yaml(エンドポイント一覧)は一例にすぎない。
ステートマシン
TODO ──► PASS ゲート通過 → ロック(不可逆). 結果確定
│
├────► REVIEW 曖昧な場合(プロキシは通過だが確信不可) → 人間確認キュー
│ (静かに通過させない)
│
└────► DONE MaxTries 超過 → 現在の水準で終了 (無限リトライ防止)
type State int
const (
TODO State = iota // 未処理
PASS // ゲート通過 → ロック(不可逆)
REVIEW // 人間の確認が必要
DONE // MaxTries 超過で終了
)
const MaxTries = 3
PASSは不変だ。一度PASSになったクエストはnextが再び出さない。remainingは単調減少する。セッションはJSONなどでディスクに永続保存し、エージェントが死んでも引き継げるようにする(resumable)。
明示すべき遷移規則(曖昧だとエージェントごとに分かれる):
- FAILはTODOを維持する。 ゲートFAILはクエストをTODOに置いたまま
Triesを+1し、Factフィードバックを保存する。 - TriesはFAILでのみ増加する。
Tries >= MaxTriesになるとDONEで終了する(>=、>ではない — MaxTries=3なら3回目のFAILでDONE)。 - PASS・REVIEW・DONEは再提出不可。 三つともターミナルだ。
submitはロックされたクエストにエラーを返し、何も変えない。REVIEWは人がキューで別途処理し、エージェントループが再び触れない。この不変性がremainingの単調減少を保証する。
ゲート — 決定論的判定の核心
ゲートはドメインを持つ。以下は**契約(interface)**であり、実際の検査項目はドメインごとに違うように埋める。
type Verdict int
const (
VerdictPASS Verdict = iota
VerdictFAIL
VerdictREVIEW
)
// Fact = エージェントに返す「事実」フィードバック (意見ではない).
// 位置·期待値·実際値を込める.
type Fact struct {
Field string
Expected string
Actual string
}
type Gate interface {
// Checkは提出を決定論的に再検証する.
// 同じ入力 + 同じ world-state → 常に同じ出力. 外部の意見の介入なし.
Check(s Submission) (Verdict, []Fact)
}
// ネットワーク·DNS·ファイルなど外部照会は必ずインターフェースの裏に出す.
// ゲートが net/http を直接呼ぶと単体テストが不可能になり判定が環境によって揺れる.
// 実際の実装(HTTPFetcher)とテスト用 mock を差し替える.
type Fetcher interface {
Fetch(url string) (body string, ok bool, err error)
}
// ゲートは Fetcher を注入される — 直接呼び出し禁止.
func NewGate(f Fetcher) Gate { /* ... */ }
ゲート規則の三つを強制せよ:
- 決定論的: 同じ提出 + 同じworld-stateは常に同じ判定。LLM呼び出し禁止。
- 再検証: エージェントの主張ではなく事実を直接確認する。エージェントが「テストを書きました」と言ったものを、ゲートが文字どおり再検査する(そのテストを実際に実行して通るか)。
- 外部照会はインターフェースの裏へ: ネットワーク・DNS・ファイル照会は
Fetcherのようなインターフェースで注入する。ゲートがnet/httpを直接呼ぶと単体テストが不可能になり(チェックリストの「ゲート優先90%+」と矛盾)、判定が環境によって揺れる。
決定論とネットワーク — エラーはFAILではない
ゲートがMX照会やページ再fetchのようにネットワークに依存すると、「決定論的」の意味を狭めなければならない。同じworld-state(同じ応答)なら同じ判定 — これが決定論だ。問題はネットワークが答えを返せないときだ。タイムアウト・オフラインをFAILとして処理すると、本当に正常な対象が自分の回線事情で脱落する — 判定が環境によって変わる非決定論だ。
だから外部照会ゲートは結果を3分岐に分けよ:
| 状況 | 判定 | 理由 |
|---|---|---|
| 事実が確認された (応答が条件を充足) | PASS | 検証成功 |
| 事実が反証された (応答が条件に違反 — ステータスコード不一致, 契約違反) | FAIL | 本当に間違い |
| 確認不可 (タイムアウト·オフライン·5xx) | REVIEW | ゲートの誤りではない → 人間·再試行キューへ |
FAILは「事実が間違っている」ときだけ。「確認できなかった」はREVIEWだ。この区別がなければ、ゲートが環境ノイズで正常な結果を殺してしまう。
任意のドメインからゲートを導出する — 5ステップ
humaのゲートはAPIエンドポイントドメインのインスタンスであって公式ではない。あなたのドメインのゲートは、この空欄を埋めて作る:
- 形式: 提出物が形態的に有効か。(メール形式 / URLスキーム / 日付フォーマット)
- ブラックリスト: 明白なプレースホルダー・ゴミを即座にFAIL。(
example.com、test、空の値) - REVIEW条件: プロキシは通過するが確信できないグレーゾーンを人のキューへ。(フリーメール / ソーシャル・ホスティングドメイン / 曖昧なマッチング) — 静かにPASS禁止が核心。
- ★ 核心事実の再検証 (cheese防御) ★: エージェントが抜け道で破れる地点を塞ぐ、ドメインの本当の事実。humaは「提出されたHurlテストが実際にそのエンドポイントを叩き、レスポンス契約(ステータス・主要フィールド)を検証するか」。あなたのドメインで**「エージェントがでっち上げてもバレる事実」**は何か? これがゲートの心臓だ。書く前に「このゲートをどう抜け道で破るか?」を先に自問せよ。
- 到達性/外部整合: 外部世界との一致。(MX存在 / URL到達 / ドメイン↔提出の一致) — 必ず上の3分岐規則で。
4番がなければゲートは形式だけを見る弱いクエストだ。4番をどう埋めるかが、ドメインごとにゲートが変わる理由であり、同じドメインならエージェントたちが収束する理由だ。
検証カスケード — 機械検証 + AI検証
ここまでゲートを「決定論的、LLM呼び出し禁止」に狭めた。それは検証可能なドメイン(コード・スキーマ)のゲートだ。だが翻訳の流暢さ、要約の忠実度のように機械が切り取れない開放型の残余があるドメインでは、決定論ゲートが届かない場所が生じる。だからといってその残余を単一のLLMに「これで大丈夫?」と尋ねるのは — Part 1で殺したLLM-as-Judgeだ(おべっか・同一の盲点・掛け算劣化)。
答えはゲートを検証カスケードとして見ることだ。抽出が安いステップから進むように、検証も層位を持つ:
Layer 1 機械検証 (決定論) 安くて確実. PASS をロックする唯一の権限
Layer 2 AI検証 (独立性を設計) 決定論が届かない開放型の残余. FLAG/REVIEW 権限のみ
Layer 3 人間 両方が見逃した最後の一握り
ドメインごとに混合比が違う — コードはL1がほぼ全部、翻訳はL1(漏出・用語・数字・構造) + L2(流暢さ・意味)の残余、創作・戦略はL1がほとんどなくL2+L3。
権限の非対称性が背骨を守る。 AIを検証に入れつつ、完了の権限は与えない:
| 検証 | 権限 |
|---|---|
| 機械検証(L1) | 「完了」をロックする唯一の権限。決定論がPASSを判定 |
| AI検証(L2) | 疑いを提起するだけ(FLAG/REVIEW/FAIL)。完了を授与できない |
決定論がPASS可能なものは決定論がロックし、AIは「決定論が見落とした場所が怪しい → REVIEWに回せ」だけをする。ゲート内の懐疑論者であって審判ではない。(検証する機械がそもそも存在しない純粋な開放型ドメインでのみ、AI+人間がPASSを背負うが、そのときは下記の独立性の前提を強制的に満たさなければならない。)
AI検証の参入条件。 AIをゲートに入れた瞬間、独立性のないAI検証は幻覚の合意になる。四つを強制せよ:
- 生成者と独立 — 別のモデル、および/または別の入力。(翻訳検証なら原文ではなく訳文を見るback-translation — 別の入力なのでエラーが構造的に独立だ。往復後に事実が生き残るかを事実アンカーで照合すれば、開放型検証が決定論的照合に降りてくる。)
- 決定論の次に来る — L1が捕まえられるものはAIに任せない。安くて確実なものを高くて揺れるものに委譲するな。
- 複数 + 閾値 — 単一判定器禁止。相関の低い異質なモデルの多数決。
- 非決定性の承認 — AIはT=0でも揺れる。PASSをロックせずREVIEWへルーティングする。
AI検証はスコアではなく分解されたyes/noで。 「品質1〜10点」は生成と同じくらい難しく、生成者と相関する。検証が生成より易しい狭い独立した質問に分割せよ — 「この中に不自然な文があるか? あれば列挙」/「原文にない主張が追加されたか?」/「back-translation後に消えた事実があるか?」。狭めるほど独立的になり、出力が位置を持った事実になってL1のフィードバックのようにgradient signalとして機能する。
整理すると — 決定論が完了の権限を握り、AIは独立が設計された懐疑論者として決定論が届かない場所を狭いyes/noで掻き、人間は両方が見逃した残余だけを見る。「検証は決定論的でなければならない」が弱まるのではなく、決定論が完了判定の権限を握ったまま、射程が開放型ドメインまで伸びるのだ。
エージェントループ
1. scan でセッション生成 (人間が1回)
2. エージェントに: "next 完遂までループを回せ"
┌──────────────────────────────────────┐
│ next → 次のクエスト + プロンプト │
│ ↓ │
│ エージェントが生成 (検索·判断·作成) │
│ ↓ │
│ submit → gate.Check() │
│ ↓ │
│ PASS? → ロック, 次へ │
│ FAIL? → Fact フィードバックと共に再試行 │
│ (MaxTries 超過 → DONE) │
└──────────────────────────────────────┘
3. TODO == 0 → 停止. export.
エージェントに与えるプロンプトはこの一行でよい:
サブエージェントに
<cli> next完遂までループを回せ。
FAILが返ってくるときFact(位置・期待・実際)が一緒に行くので、おべっかするモデルほどその事実を素直に受け入れて収束する(Part 1の「おべっかは資産」)。決定論的なゲート + おべっかするLLM = 収束が保証されるループ。
収束条件の三つ (必ず守れ)
- フィードバックは決定論的な事実でなければならない。 「これちょっとおかしいけど」ではなく「line 41: expected ‘user_id’, got ‘userId’」。
- 例示がコンテキストにあるべきだ。 フィードバックだけでは不十分だ。
nextが出力するプロンプトに「こういう形の結果を出せ」という例示を入れよ。ボトルネックは知能ではなくコンテキストだ。 - 検証を通過したら後戻りできない。 ratchetの歯車。PASSはロックされる。エージェントが「やり終えました」と宣言するのではなく、ゲートが「このクエストは通過」と判定する。
検証器を入れ替えると別のツールになる
Quest CLIは特定のゲートに依存しない。ゲートだけ変えれば別のツールになる。
| クエスト + ゲート | ツール |
|---|---|
クエスト + go test + coverage | 関数単位テスト生成 (tsma) |
| クエスト + 構造ルール validator | コード構造整理 (filefunc) |
| クエスト + hurl pass/fail | API エンドポイント検証 (huma) |
| クエスト + 仕様の交差検証 | SSOT 整合性 (yongol) |
パターンは一つだ。ゲートがドメインを決定する。
Part 4 — ワークド例: huma
humaはOpenAPI仕様のすべてのエンドポイントをHurlテストで検証することを強制するQuest CLIだ。この文書のscan/next/verifyの設計図はhumaの原型から来ている — だからhumaが最もきれいなワークド例だ。バイブコーディングは静かにエンドポイントをスキップする。humaはその早期終了をゲートで遮断する。
1クエスト = エンドポイント1個。 ゲートの決定論的検証:
- 形式: 有効なHurl構文
- ブラックリスト: アサーションのない空のテスト → FAIL
- 弱いテスト(ステータスコードだけで本体を見ない) → REVIEW (静かに通過させない)
- ★ 実行 ★ →
hurl --testが実際にエンドポイントを叩き、通過しなければならない → PASS (テストが本物であることを証明し、幻覚を遮断) - レスポンス契約の一致 → 応答がOpenAPIスキーマのステータス・主要フィールドから逸脱すればFAIL
4番・5番がcheese防御の核心だ。AIが「テストを書きました」とだけ主張しても、assert status == 200を偽装しても、ゲートが実際にHurlを実行する。生成はAIが、判定は機械が。 AIはテストを書くが、完了判定の権限はない。
コマンドは正確にPart 3そのままだ:
go build -o huma .
./huma scan openapi.yaml # endpoint list → session
./huma next # next endpoint + agent prompt
./huma submit --endpoint "POST /orders" --test "orders_post.hurl" # Hurl test the agent wrote
./huma status
./huma export # coverage report per endpoint
実行はClaude Codeで一行で:
サブエージェントに
huma next完遂まで全エンドポイントのテストを書かせて。
サブエージェントがnext → テスト作成 → submitのループを、TODOが0になるまで繰り返す。エージェントは難しいエンドポイントをスキップできない — ゲートを通過するまでnextが次を渡さないからだ。
これがパターンの核心を示す。ゲートだけを差し替えれば、同じ5部品・同じステートマシンが別のツールになる。 Part 5: あなたのドメインで同じことをやる。
Part 5 — あなたのQuest CLIを建てよ
設計ワークシート
空欄を埋めれば、それがそのまま仕様だ。
ドメイン: [何を収集/処理するのか]
1クエスト単位: [何ひとつが1クエストか — 会社1社? 関数1個? エンドポイント1個?]
入力: [scan が読むもの — Excel? ディレクトリ? リスト?]
完了条件: [機械が yes/no で答えられる条件]
ゲート検証項目: [ドメインで何が「事実」か — 再検証する項目]
- 形式検査: [...]
- チーズ防御: [エージェントはどう抜け道で破るか? それを塞ぐ再検証]
- REVIEW 条件: [曖昧で人間に送る場合]
フィードバック(Fact): [FAIL 時に返す位置·期待·実際]
例示: [next プロンプトに入れる「こういう形の結果」サンプル]
export 形式: [原本保存 + 結果の列]
完了条件 (このビルド自体のゲート)
この文書で作ったQuest CLIが「完了」するには — つまりこの文書が自分の教えたとおりcheese-proofであるには — 次を満たさなければならない:
-
go build通過 -
scan / next / submit / status / exportコマンドが動作 - ステートマシン
TODO → PASS/REVIEW/DONE, PASS 不変,remaining単調減少 - L1機械検証が決定論的 (同じ入力 + world-state → 同じ判定) — PASSロック権限はL1のみ
- 開放型の残余があれば L2 AI検証は独立設計(別のモデル/入力)・複数・分解されたyes/no — REVIEW権限のみ、PASSロック不可
- ゲートがエージェントの 主張 ではなく 事実 を再検証 (チーズ防御 最低1項目 — 導出5ステップの4番)
- 外部照会(ネットワーク·DNS)はインターフェースの裏に注入 — テストが mock でオフライン動作
- 外部照会ゲートは PASS/FAIL/REVIEW の3分岐 (確認不可 = REVIEW, FAIL ではない)
- FAIL は TODO 維持·
Tries+1,>=MaxTriesなら DONE; PASS·REVIEW·DONE は再提出不可 - FAIL フィードバックが位置·期待·実際を込めた
Fact - セッションがディスクに永続 (resumable)
- 単体テスト: gate 優先, 全体 statements 90%+
-
exportが原本を上書きしない
ビルド指示文
エージェントにこう与える:
この文書のPart 3(コマンドスケルトン)を設計図に、Part 4(huma)をワークド例にして、**[あなたのドメイン]**のためのcobraベースのGo製Quest CLIを書け。Part 5の完了条件チェックリストをすべて満たすまで進めよ。ゲートは必ず決定論的でなければならず、エージェントの主張ではなく事実を再検証しなければならない。
三つの役割がこの一場面の中にある。
- クエストをプレイする。 誰かが作ったゲートを導入して使う — ユーザー。
- クエストを設計する。 自分のドメインに合ったゲートを自ら建てる — 制作者。(この文書が連れて行く場所)
- cheese不可能なクエストを設計する。 プロキシが目的に追いつけない地点を前もって塞ぐ — 設計者。
ほとんどはプレイで止まる。盤を大きくするのは設計であり、その盤が壊れないようにするのはcheeseを防ぐ設計だ。
次に誰かが「やり終えました」と言ったら、聞き返すのではなく問え — 「完了とは何か、そしてそれを判定したクエストは誰が設計したのか。」
生成は確率的でいい。検証は決定論的でなければならない。
関連記事
- Who Defines ‘Done’ — 完了をクエストとして設計する — この文書の概念編。完了=ゲート、cheese・Goodhart。
- Ratchet Pattern — エージェントを最後まで走らせる方法 — 一方向ロックの本編。
- IFEvalを逆用するratchet code — 事実フィードバックで収束。
- Reins Engineering — 手綱のあるAI — ハーネスは柵、クエストは手綱。
- モデルIQよりフィードバックトポロジー — 結果を分けるのはモデルではなくフィードバック構造。
- huma — エンドポイントを飛ばさないratchet — コマンドスケルトン(scan/next/verify)の原型。
- LLMマルチエージェントの精度向上の前提条件 — AI検証層(L2)が独立性を備えてはじめて機能する理由。検証カスケードの理論的背景。
出典
- Von Neumann, J. (1956). “Probabilistic Logics and the Synthesis of Reliable Organisms from Unreliable Components.” Automata Studies, Princeton University Press.
- Zhou, J. et al. (2023). “Instruction-Following Evaluation for Large Language Models.” arXiv:2311.07911
- Ouyang, L. et al. (2022). “Training Language Models to Follow Instructions with Human Feedback.” NeurIPS 2022. arXiv:2203.02155
- Huang, J. et al. (2024). “Large Language Models Cannot Self-Correct Reasoning Yet.” ICLR 2024. arXiv:2310.01798
- Chen, X. et al. (2024). “Teaching Large Language Models to Self-Debug.” ICLR 2024. arXiv:2304.05128
- Yang, J. et al. (2024). “SWE-agent: Agent-Computer Interfaces Enable Automated Software Engineering.” NeurIPS 2024.
- Jimenez, C. et al. (2024). “SWE-bench: Can Language Models Resolve Real-World GitHub Issues?” ICLR 2024. arXiv:2310.06770
- Zhou, S. et al. (2023). “WebArena: A Realistic Web Environment for Building Autonomous Agents.” arXiv:2307.13854
- Cemri, M. et al. (2025). “Why Do Multi-Agent LLM Systems Fail?” arXiv:2503.13657
- Sharma, M. et al. (2024). “Towards Understanding Sycophancy in Language Models.” ICLR 2024. arXiv:2310.13548
- Fanous, A. et al. (2025). “SycEval: Evaluating LLM Sycophancy.” AAAI/ACM AIES 2025. arXiv:2502.08177
- Shapira, I. et al. (2026). “How RLHF Amplifies Sycophancy.” arXiv:2602.01002
- Ibrahim, L. et al. (2026). “Training Language Models to Be Warm Can Reduce Accuracy and Increase Sycophancy.” Nature 652, 1159-1165.
- Panickssery, A., Bowman, S., & Feng, S. (2024). “LLM Evaluators Recognize and Favor Their Own Generations.” NeurIPS 2024. arXiv:2404.13076
- Stechly, K., Valmeekam, K., & Kambhampati, S. (2024). “On the Self-Verification Limitations of Large Language Models.” arXiv:2402.08115
- McKee-Reid, L. et al. (2024). “Honesty to Subterfuge: In-Context RL Can Make Honest Models Reward Hack.” arXiv:2410.06491
- Bondarenko, A. et al. (2025). “Demonstrating Specification Gaming in Reasoning Models.” arXiv:2502.13295
- Thaman, K. (2026). “Reward Hacking Benchmark: Measuring Exploits in LLM Agents with Tool Use.” arXiv:2605.02964
- Deque Systems (2021). “Automated Testing Study Identifies 57 Percent of Digital Accessibility Issues.”
変更履歴
- 2026-06-03: 初版 (コーパス7本 + huma統合、ワークド例)。レビュー補強 — ドメインゲート導出5ステップ、決定論・ネットワーク3分岐、
Fetcherseam、状態遷移規則。 - 2026-06-03: 「検証カスケード」新設 — 機械検証(L1, PASS権限) + AI検証(L2, 独立設計・REVIEW権限) + 人間(L3)の2層モデルと権限の非対称性。「ゲート=決定論only」を開放型ドメインまで一般化。
- 2026-06-05: comailは違法ほう助のおそれがあり非公開にします。ワークド例をhumaに置換。