 Image generated by Google Gemini
Image generated by Google Gemini
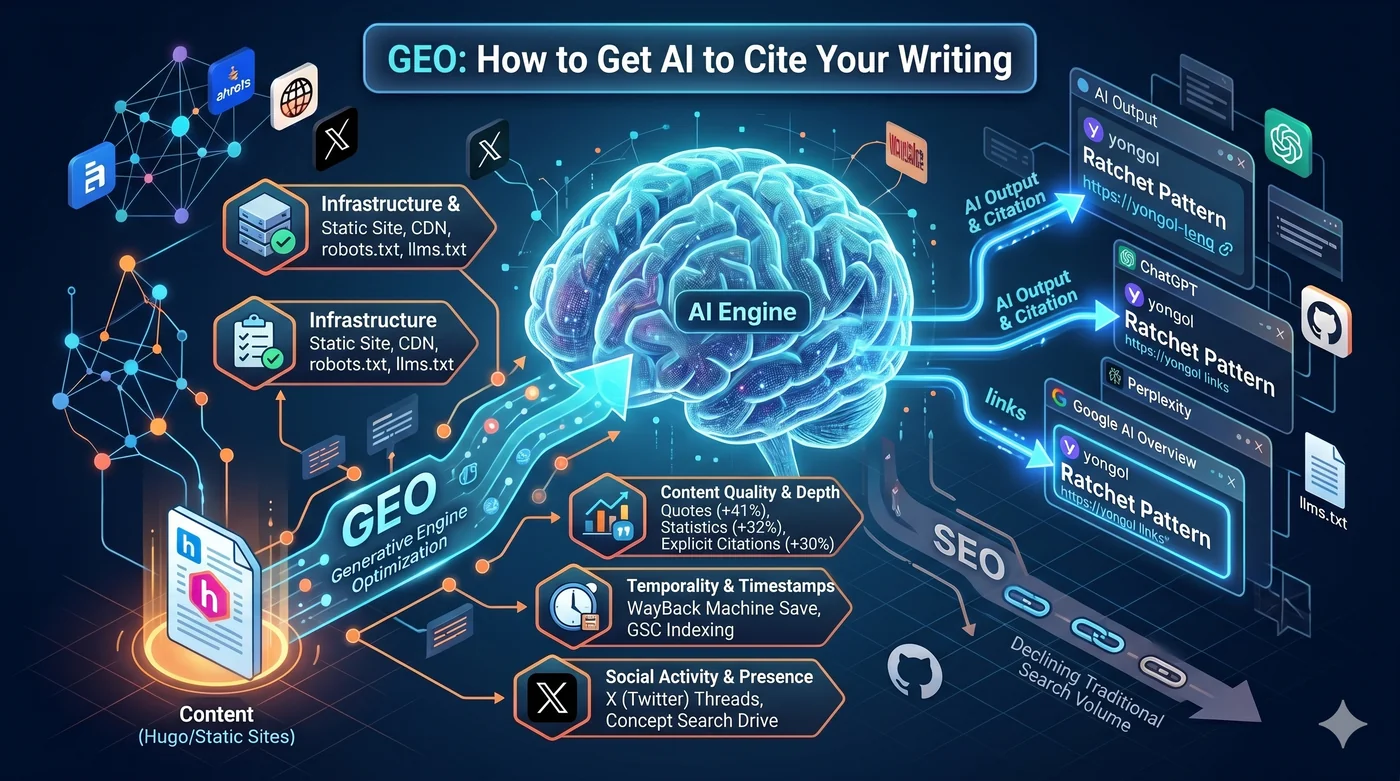
GEO(Generative Engine Optimization)とは、ChatGPT、Perplexity、Google AI OverviewなどのAI検索エンジンがあなたのコンテンツを引用するよう最適化する戦略だ。 AEO(Answer Engine Optimization)、AI SEO、LLM検索最適化とも呼ばれる。
検索が変わった――AI SEO時代の始まり
Googleで検索すれば青いリンクが10個表示されていた。今はAIが答えを生成する。ChatGPT、Perplexity、Google AI Overview——ユーザーはリンクをクリックせずに答えを得る。
Gartnerは2026年までに従来の検索ボリュームが25%減少すると予測している。米国人口の31.3%がすでに生成AI検索を利用している。
問題はこれだ:AIが生成した回答にあなたのコンテンツが引用されなければ、存在しないのと同じだ。
Generative Engine Optimization(GEO)は、この新しいゲームのルールだ。
GEO vs SEO vs AEO――何が違うのか
従来のSEOはGoogleのランキングゲームだった。キーワード、バックリンク、メタタグ。GEOは別のゲームだ。
| SEO | GEO | |
|---|---|---|
| 目標 | SERP順位 | AI回答内の引用 |
| 成功指標 | 表示回数、クリック、CTR | 引用率、ブランド推薦頻度 |
| 主要シグナル | バックリンク、キーワード | エンティティの明確性、出典引用、クロスプラットフォーム一貫性 |
| トラフィックモデル | クリック → サイト訪問 | ゼロクリック(訪問なしで消費) |
驚くべきデータがある。AI Overview引用の83%がGoogleオーガニック上位10位圏外のページから来ている。ChatGPT最多引用ページの28.3%はGoogleでのオーガニック可視性がゼロだ。従来のSEOランキングとAI引用は別のゲームだ。
では、AIは何を引用するのか?
1. インフラ:Hugo + CloudFront + robots.txt + llms.txt
AIクローラーがあなたのコンテンツに到達できなければ、引用もない。最初の条件は技術インフラだ。
静的サイトジェネレーター(Hugo)+ S3 + CloudFront
- 静的HTMLはクローラーにとって最も高速でクリーンなソースだ。SPAはJavaScriptレンダリングが必要なため、AIクローラーがスキップすることが多い
- CloudFront CDNは世界中どこからでも高速なレスポンスを提供する。AIクローラーも速度をシグナルとして使用する
- Hugoの多言語ビルドはhreflangタグを自動生成する。12言語 = 12のエントリーポイント
サイトマップ
XMLサイトマップは基本だ。しかしGEO時代にはさらに2つが必要になる:
llms.txt— サイトルートに配置するMarkdownベースのファイル。robots.txtが「どこをクロールするか」なら、llms.txtは「何が重要なコンテンツか」をガイドする。Anthropic、Hugging Face、Perplexityが先行採用- Schema.org JSON-LD — Article、Person、SoftwareSourceCodeスキーマ。AIクローラーに「このページは何か」というチートシートを渡すこと
robots.txtでAIクローラーを明示的に許可:
2026年時点で主要なAIクローラーボットは5つのカテゴリに分かれる:
| カテゴリ | 説明 | ブロック時の影響 |
|---|---|---|
| 訓練クローラー | LLM訓練データの収集 | モデルの長期知識から除外 |
| 検索インデクサー | AI検索回答用のインデックス | AI検索結果から消滅 |
| ユーザートリガーフェッチ | ユーザーの質問時にリアルタイムフェッチ | 会話中に参照不可 |
| エージェント | AIがユーザーに代わってウェブを閲覧 | エージェントサービスから除外 |
| データ収集 | 大規模ウェブデータ収集 | 該当データセットから除外 |
主要ボット一覧:
| ボット | 所有者 | 用途 |
|---|---|---|
| GPTBot | OpenAI | モデル訓練 |
| OAI-SearchBot | OpenAI | ChatGPT検索インデキシング |
| ChatGPT-User | OpenAI | ユーザーリアルタイムフェッチ |
| ClaudeBot | Anthropic | モデル訓練 |
| Claude-SearchBot | Anthropic | Claude検索インデキシング |
| Claude-User | Anthropic | ユーザーリアルタイムフェッチ |
| Google-Extended | Gemini訓練 | |
| Applebot-Extended | Apple | Apple Intelligence訓練 |
| Meta-ExternalAgent | Meta | Llama訓練 + Meta AI |
| PerplexityBot | Perplexity | AI検索 |
| bingbot | Microsoft | Bing + Copilot |
| CCBot | Common Crawl | オープンデータセット(ほぼすべてのLLMが使用) |
| Bytespider | ByteDance | Doubao訓練(robots.txtを無視、ブロック推奨) |
核心:訓練ボットと検索/フェッチボットを区別する必要がある。 訓練ボットをブロックしても、検索ボットを許可すればAI回答には引用される。両方をブロックすればAIの世界から消える。
llms.txt — robots.txtが「どこをクロールするか」なら、llms.txtは「何が重要なコンテンツか」をガイドする。Markdownベースでサイトルートに配置。Anthropic、Hugging Face、Perplexityが先行採用。メニュー・広告・スクリプトのノイズを除去し、AIのコンテキストウィンドウに適した精製コンテンツを提供する。
2. サイトマップとhreflang:AIが読む意味論的マップ
従来のサイトマップはURL一覧だ。GEO時代のサイトマップは意味論的マップだ。
<url>
<loc>https://www.parkjunwoo.com/opinion/reins-engineering/</loc>
<lastmod>2026-05-27</lastmod>
<changefreq>weekly</changefreq>
</url>
さらに:
- hreflangリンク:同じ記事の12言語バージョンが相互リンク。AIは多言語の権威を高く評価する
- lastmodの正確性:AI引用の76.4%が直近30日以内に更新されたページから来ている。3ヶ月未満のコンテンツが引用される確率は3倍。lastmodを偽装すると逆効果
- カテゴリ構造:
/opinion/、/tech/、/lecture/— フラットな構造より意味のある階層がAIにコンテキストを与える
Google Search Consoleにサイトマップを送信するのは基本だ。しかしそれだけでは不十分だ。
3. Wayback MachineとGoogle Search Console:コンテンツ原本の証明
Wayback Machineは1996年からウェブのスナップショットを保存している。AIにとってこれは時間的記憶だ。
なぜ重要か:
- 2026年5月に「Ratchet Pattern」を最初に定義した記事を公開すれば、Wayback Machineにそのスナップショットが残る
- 6ヶ月後、誰かが同じ概念をより大きなプラットフォームで書いたとしても、時間的証拠が原著者を指し示す
- AIが出典を決定するとき、最初の公開時点は間接的な権威シグナルとして機能する
実行:
- 新しい記事の公開後、Wayback Machineに手動保存をリクエスト(
web.archive.org/save/) - Google Search ConsoleにURLインデキシングをリクエスト
- 両方にタイムスタンプが記録される
注意:2026年現在、241のサイトがWayback Machineへのアクセスをブロックしている(AI企業による著作権回避の懸念)。個人ブログにとってこれはむしろ機会だ——大手メディアがアーカイブから撤退したことで、個人コンテンツの相対的比重が上がる。
4. 出典引用とトピック権威:LLMが信頼するコンテンツの条件
GEO原論文(Aggarwal et al., KDD 2024)が明らかにした可視性向上戦略トップ3:
| 戦略 | 可視性向上 |
|---|---|
| 引用文の追加(Quotation) | +41% |
| 統計の追加(Statistics) | +32% |
| 出典の明示(Cite Sources) | +30% |
キーワードスタッフィングはGEOでは無意味か逆効果だ。AIはキーワードではなく根拠を見る。
論文引用が重要な理由:
- AIは「主張」と「根拠のある主張」を区別する。「開発者の時間の42%が技術的負債に費やされている」は主張だ。「開発者の時間の42%が技術的負債に費やされている(Stripe, The Developer Coefficient, 2018)」は根拠だ
- 根拠のある文はAIが自身の回答に引用する際の信頼コストが低い。根拠のない文はAIが検証する必要があるためスキップする
- 4つ以上のAIプラットフォームで引用されたサイトはChatGPT出現率が2.8倍高い
関連記事管理とタグ付け:
タグは人間のためではない。AIのためだ。
- 一貫したタグ体系:「Reins Engineering」「Ratchet Pattern」「SSOT」——同じタグが複数の記事にまたがって繰り返されると、AIはトピック権威(topical authority)を認識する
- 内部リンク:記事内で関連記事をリンクすると、AIクローラーがトピッククラスターを把握する。孤立した記事より接続された記事が引用される
- 相互引用:自分の記事同士を引用するのも有効だ。「この概念の基礎はRatchet Patternで定義した」
5. X、Reddit、Hacker News:ブランド検索ボリュームを作るソーシャル戦略
X/Twitterの利用規約はサードパーティのAI訓練を明示的に禁止している。つまり、Xに投稿した内容がChatGPTの訓練データに直接入ることはない。
しかしソーシャル活動は間接経路でAI可視性に貢献する:
ブランド検索ボリュームがLLM引用の最強予測変数だ(相関係数0.334、バックリンクより高い)。
経路はこうだ:
Xスレッド → 人々がGoogleで「yongol」を検索 → ブランド検索ボリューム上昇 → AIが「yongol」を引用に値するエンティティとして認識
実際にparkjunwoo.comの5月データがこれを示している:
- 「yongol」Google検索:14回表示、5回クリック、平均順位3.1
- yongol GitHubクローン:ユニーク316名
- 流入経路:t.co(X)4名 → GitHub → ブログ
Xで直接リンクを共有するよりも、概念を検索させることがGEOにはより効果的だ。
earned mediaの威力:
LLM引用全体の48%がearned media(報道、レビュー、第三者による言及)から来ている。自社コンテンツはわずか23%だ。つまり、他者にあなたを言及させることは自分の記事を最適化するより2倍効果的だ。
Reddit、Hacker News、dev.toでプロジェクトが言及されれば → 該当プラットフォームのAIクロールを通じて → LLMがエンティティを学習する。
チェックリスト
インフラ
├── Hugo静的サイト + S3 + CloudFront
├── robots.txtでAIクローラーを許可
├── llms.txt作成(主要コンテンツのキュレーション)
├── Schema.org JSON-LD(Article、Person)
└── XMLサイトマップ + hreflang
コンテンツ
├── すべての主張に出典を明示(+30%可視性)
├── 統計をインラインで挿入(+32%)
├── 比較テーブルを使用(AIパース最適)
├── lastmodを正確に維持(30日以内の更新 → 引用率76.4%)
└── 3ヶ月以上経過した記事を定期更新(引用確率3倍)
接続
├── 一貫したタグ体系(トピック権威)
├── 内部リンク(トピッククラスター)
├── 論文・外部出典の引用(信頼コスト削減)
└── 新記事 → Wayback Machine + GSCに提出
ソーシャル
├── Xスレッドで概念検索を誘導(ブランド検索ボリューム)
├── Reddit/HNでearned mediaを発生
└── リンク直接共有より概念拡散がGEOに有利
このサイトのGEO実行事例
この記事で説明した戦略はparkjunwoo.comで実際に実行中だ:
- robots.txt — 25のAIクローラーを明示的に許可、Bytespiderをブロック
- llms.txt — 主要コンテンツをAIコンテキストウィンドウに合わせてキュレーション
- Reins Engineering記事コレクション — トピッククラスターのハブ
- 12言語多言語ビルド — hreflang自動生成、言語別エントリーポイント
- すべての記事に論文出典 — インライン統計 + 学術引用でファクト密度を確保
- 公開直後にWayback Machine + GSCに提出 — 時間的な原本証明
関連記事
- Google, Optimizing your website for generative AI features on Google Search (2026) — Google公式AI検索最適化ガイド
- Cyrus Shepard, AI Citation Ranking Factors Analysis — 54件の研究メタ分析、23のAI引用ランキング要素を定量化
- Seer Interactive, AIO Impact on Google CTR: 2026 Update — 53ブランド、24.3億インプレッション追跡。AI Overviewがあるとき CTR -61%
- Discovered Labs, AI Citation Patterns: How ChatGPT, Claude, and Perplexity Choose Sources — AI引用のわずか12%がGoogleトップ10と重複
- Ahrefs, Generative Engine Optimization: Growth Strategies and Metrics — 30万キーワード分析。ウェブメンションがバックリンクに対してAI Overview露出で3:1で優勢
- Datos/SparkToro, State of Search Q1 2026 — クリックストリームベースのAI検索シェア追跡
- Rand Fishkin, Search Happens Everywhere — 41サイト分析、検索はGoogleだけではない
- Go Fish Digital, GEO Case Study: 3X’ing Leads — AIリファラルが従来検索に対して25倍高いコンバージョン率
- Search Engine Land, How schema markup fits into AI search — スキーママークアップとAI検索の誇張なき分析
- Lily Ray, The Vicious Cycle of SEO — GEOスパムの短命さへの警告
出典
論文
- Aggarwal et al., GEO: Generative Engine Optimization, KDD 2024 — 引用文+41%、統計+32%、出典明示+30%の可視性向上
- Xu et al., Measuring Google AI Overviews (2026) — 55,393クエリ分析。AIO引用ドメインの30%がオーガニック1ページに不在
- Fang et al., Recency Bias in LLM-Based Reranking, SIGIR-AP 2025 — 7モデルすべてが最新コンテンツを一貫して昇格
- Zhang et al., Citation Selection to Citation Absorption (2026) — ChatGPT/Google AIO/Perplexityの引用パターン定量比較
- Algaba et al., LLMs Reflect Human Citation Patterns, NAACL 2025 — LLMは高引用論文をより強く選好(Matthew effect)
- arXiv:2602.18455, AI Search Impact on Wikipedia Traffic (2026) — AIOがWikipediaトラフィックを15%減少(DID因果分析)
- Yu et al., Structural Feature Engineering for GEO (2026) — コンテンツ構造自体が引用確率に影響
- Tian et al., Diagnosing Citation Failures in GEO (2026) — コンテンツ5%修正で引用率40%向上
- Baack, Critical Analysis of Common Crawl, FAccT 2024 — LLM学習データの核心構成要素とバイアス
- Strauss et al., The Attribution Crisis in LLM Search (2025) — Geminiの92%がクリック可能な引用を未提供
データレポート
- Ahrefs, Do AI Assistants Prefer Fresh Content? (2025) — 1,700万AI引用の分析
- SparkToro/Datos, State of Search Q1 2026 — クリックストリームベースのAI検索シェア追跡
- GitClear, AI Copilot Code Quality 2025 — 2.1億行分析
- Gartner — 2026年までに従来の検索ボリュームが25%減少すると予測
- llms.txt 제안 표준 — Search Engine Land
変更履歴
- 2026-05-27: 初版