 Image: AI generated
Image: AI generated
直した場所からまた立ち上がる
私はドリフトを閉じるツールを作った。
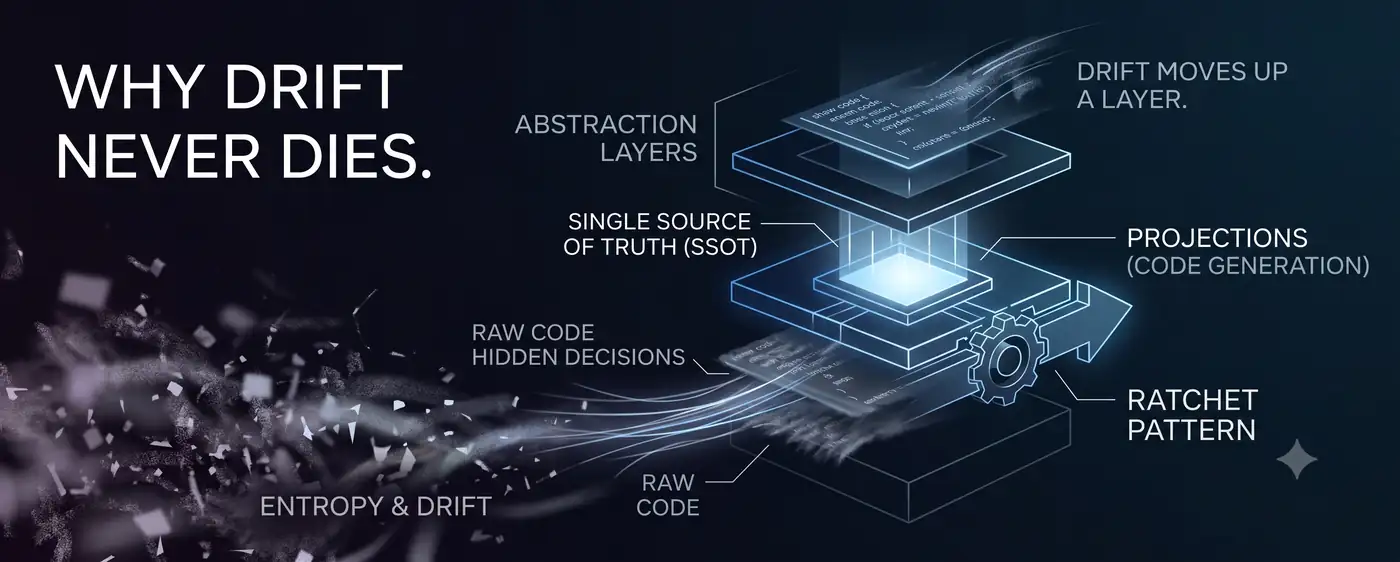
yongolのテーゼはシンプルだ。決定は権威ある単一ソース(SSOT)に置かなければ漂流する。だから決定をSSOTに入れ、コードを毎回の生成で描き直される使い捨ての projection にする。BIGINTと定めたカラムがリファクタ一回でいつの間にかINTに戻るビジネスロジックのドリフトは、こうして閉じられた。
ところが先日、yongolが生成したコードの欠陥群を分析していて奇妙なことに気づいた。欠陥たちが同じ文構造で自らを告白していたのだ。「import 収集が『ハンドラが実際にtimeを使っているか』と分離されている。」「requiredness 推論が『対象APIがこのパラメータを本当に required として要求しているか』と分離されている。」パスパラメータは常に required、import はトークンを実際に使うときだけ。同じ構造的決定がどのSSOTにも記されないまま、生成器コードの中に都合のいいローカルプロキシとして埋め込まれていた。
ドリフトは消えたのではなかった。一層上に移動していた。 ビジネスロジックはSSOTで閉じたが、そのSSOTを読んでコードを出力する生成器自身の構造的決定にはSSOTがなかった。yongolのテーゼがyongol自身にそのまま跳ね返ったのだ。理論が予測したまさにその場所で。
だから問いが変わる。ドリフトがなぜ発生するかは誰でも知っている。本当の問いはこれだ。直してもなぜまた戻ってくるのか。
根源:決定とディテールは別物である
物理から積み直そう。
決定は情報だ。それも低エントロピーの情報だ。「このカラムは64ビットでなければならない」とは、可能な無数の状態から一つを意図的に選び取ったことだ。自然は低エントロピーを嫌う。放っておけば情報は周囲のノイズに拡散して消える。熱力学第二法則は決定にも適用される。
ソフトウェア工学はこの崩壊を長く観察してきた。レーマン(Lehman)のソフトウェア進化法則は、E-type システムの複雑度は減らす明示的な努力がなければ増大すると述べている(1980)。情報物理学はさらに深く降りる。ランダウアー(Landauer)は1ビットを消去するだけでも最小の熱力学コスト(kT ln 2)がかかることを1961年に示した。情報を変え、保持し続けることは原理的にタダではない。決定を定位置に留めるにはエネルギーを使い続けなければならない。
情報が生き延びるには二つが必要だ。権威ある保存(authoritative store)と、そこから絶え間なく再描画する能動的再投影(error correction)。私たちの体のDNAがそうであり、デジタルストレージのパリティビットがそうだ。原本を別に保ち、毎回それを基準に復元する。
ドリフトはこの復元が壊れたときに起きる。メカニズムは一つだ。私はそれをプロキシバインディングと呼ぶ。媒体が決定とディテールを区別して保存できなければ、次の人(あるいは次のエージェント)は決定を権威あるソースから読むことができず、隣にある都合のいい相関信号から再導出する。「このカラムが timestamptz なら、timeを import すればいいだろう」という推測。大抵は合っている。だから危険だ。たまに外れ、外れたとき決定は音もなく消える。
raw コードはまさにそういう媒体だ。コードは「これは決定である」と「これはこの場所でたまたま真である」を区別して表示しない。だからより大きなモデルでも解決しない。媒体自体が決定を担えないのに、読む側が賢くなったところで読むものがない。
この現象に名前がなかったわけではない。ソフトウェアアーキテクチャにおいてペリーとウルフは原則違反を侵食(erosion)、アーキテクチャへの無感覚をドリフト(drift)と分けた(1992)。カニンガムはきちんとできていないコードにつく利子を技術的負債と呼んだ(1992)。分野ごとに症状はよく命名されている。私が付け加えたいのはその下の単一メカニズム(プロキシバインディング)と、そのメカニズムが閉じるほど上層へ再帰するという構造だ。名前ではなく因果を問うている。
なぜ上に移動するのか
ここまでは既知の話だ。新しいのはその先にある。
ドリフトを閉じるには二つが必要だ。決定を権威をもって格納する保存所(SSOT)と、それを読んで成果物を出力する閉じる主体(生成器)。しかし閉じる主体自身も決定を下す。「パスパラメータは required として扱う」といった構造的決定を。その決定が住む媒体——生成器コード——もまた決定とディテールを区別して格納できない。
同じメカニズムが一層上で繰り返される。閉じる行為そのものが一層上に閉じられていない媒体を生む。ドリフトは根絶されたのではなく引っ越したのだ。権威のない層へ。
これを最後まで押し進めると不快な結論が出る。生成器にSSOTを与えたら?そのSSOTを作る何かがまた自らの決定を閉じていない媒体に格納する。層を上げるたびに表面積は減るが、最上部には常に権威のない層が残る。人間であれ、生成器の生成器であれ。ドリフトは漸近的に根絶不可能である。(これは証明というより強い推測だ。ただし、これまで私が閉じたすべての層は、閉じた瞬間に上層を開いた。)
これが「直してもなぜ戻ってくるのか」の答えだ。戻ってくるのではない。私たちが一つの層を閉じると、その閉じるツールが次の層を開くのだ。同じ川がより高い堤から再び漏れ出す。
処方の非対称:宣言できるものと、検証するしかないもの
では上層はどう閉じるか。ここで決定的な非対称が現れる。
ビジネスロジックの決定は大抵値である。カラムは64ビット、アクセスは所有者のみ、ページネーションはカーソル方式。値は宣言できる。DDLに、OpenAPIに、仕様ファイルに書いておけばそれがSSOTになる。宣言で閉じられる。
生成器の構造的決定は異なる。「パスパラメータは required だ」「import は実際のトークン参照に紐づく」「required(キーが存在する)と空でないことは別だ」。これは値ではなくすべての入力にわたる関数の振る舞い特性だ。振る舞い特性は宣言で列挙できない。入力が無限だからだ。YAML の一項目に「この変換はすべての場合にこう振る舞うべきだ」と書く方法はない。
だからこの層の決定は宣言ではなく検証でしか閉じられない。型チェッカー、プロパティテスト、コンパイルゲート。決定をデータとして固めるのではなく、違反を機械が毎回検出する関門として固めるのだ。
私が別の記事で「人間のレビューをコード化せよ」と書いたのがこの場所だ。ある約束は宣言できるからSSOTが守り、ある約束は宣言できないからゲートが守る。生成器が出力したコードがコンパイルできるかどうかはどのSSOTにも書けない。コンパイルを毎回実行してのみ確認される。その関門がなければ、「generate 成功 = ビルド可能」という約束はアーキテクチャの外に浮いたまま、validate が 0/0 で通過しても成果物は壊れる。
宣言できるドリフトはSSOTで閉じ、検証するしかないドリフトはゲートで閉じる。両者を混同すると、宣言で防ごうとして永遠にモグラを叩き続けることになる。
同じ川、異なる堤
この構造はコードの外でも繰り返される。
知識におけるドリフトは出典の喪失だ。ある主張が誰が、いつ、どんな根拠で行ったかを失えば、その主張は「事実」というノイズに拡散する。次の人は権威(元の出典)から読めず周辺状況から再導出する。私がGEULをすべての情報に出典・時点・信頼度を強制的に付与する言語として設計した理由がこれだ。事実はなく主張のみがあるという認識論は、知識層のプロキシバインディングを防ぐための安全装置だ。
法におけるドリフトは判例が元の決定から逸脱することだ。文明はこれを各事件ごとに裁判官の良心に委ねるのではなく、規則を成文化し、違反を定義し、強制メカニズムを付けて閉じた。優れた裁判官はSSOTではなくプロキシだ。成文法がSSOTだ。
同じ川だ。決定が権威ある場所に置かれなければ、媒体が決定とディテールを区別できなければ、それは漂流する。コードであれ、知識であれ、法であれ。
結論:根絶ではなく押し上げ
ドリフトとの戦いは根絶が目標にはなり得ない。根絶は不可能だ。閉じるツールが常に次の層を開くからだ。
目標は別にある。より高い、表面積がより小さい層へドリフトを押し上げ、その層を機械的検証で武装すること。 数万行の raw コードに散らばっていた決定をSSOT一箇所に集めれば、漂流し得る表面は劇的に縮小する。残る表面——生成器の振る舞い不変条件——はゲートで塞ぐ。それでも最上部にはこれ以上委任できない最後の層、人間の判断が残る。そこで私たちは毎回新たに検証し、約束を打ち直す。
これがラチェットだ。一方向にしか回らない。一度上がった歯は滑り落ちない。エントロピーは決定を引きずり下ろそうとし、ラチェットはそのたびに一段ずつ引き上げる。平衡はない。止まれば漂流する。
ドリフトは死なない。だから私たちは止まらない。エントロピーに抗って約束を築くことは、一度の勝利ではなく永久のラチェットだ。
関連記事
合わせて読みたい
- Lehman’s laws of software evolution — ソフトウェアは手を加えなければ複雑化するという経験則の概要。
- Landauer’s principle — 情報を消去するための熱力学コスト。
出典
- Perry, D. E. & Wolf, A. L. (1992). Foundations for the Study of Software Architecture. ACM SIGSOFT Software Engineering Notes, 17(4), 40-52. ACM — 侵食(erosion)とドリフト(drift)の区分。
- De Silva, L. & Balasubramaniam, D. (2012). Controlling software architecture erosion: A survey. Journal of Systems and Software, 85(1), 132-151. ScienceDirect
- Lehman, M. M. (1980). Programs, Life Cycles, and Laws of Software Evolution. Proceedings of the IEEE, 68(9), 1060-1076. IEEE — 複雑度増大法則・持続的変化法則。
- Landauer, R. (1961). Irreversibility and Heat Generation in the Computing Process. IBM Journal of Research and Development, 5(3), 183-191. IBM — 情報消去の最小熱力学コスト。
- Shannon, C. E. (1948). A Mathematical Theory of Communication. Bell System Technical Journal, 27, 379-423. DOI — 情報・エントロピー・error correctionの基盤。
- Cunningham, W. (1992). The WyCash Portfolio Management System. OOPSLA ‘92 Experience Report. c2.com — 技術的負債と「きちんとできていないコードの利子」。