 Image: AI generated
Image: AI generated
Orang Pintar Belum Tentu Pandai Menjelaskan
Ketika Anda menyuruh Opus 4.8 melakukan refactoring kode, hasilnya mengagumkan. Ia memecahkan graf dependensi yang kompleks sekaligus, menangani edge case secara proaktif, dan menulis tes tanpa celah. Namun masalah dimulai ketika Anda memintanya menjelaskan hasilnya. Ia berbicara seperti seorang pakar yang melapor kepada pakar lain. Ia menganggap lawan bicara sudah berbagi pengetahuan latar belakang yang sama, melewatkan alasan di balik keputusan penting, dan tingkat abstraksinya terlalu tinggi tanpa perlu.
Ketika Anda menanyakan hal yang sama kepada Opus 4.6, hasilnya kebalikannya. Ia pandai memperkirakan apa yang mungkin tidak Anda ketahui. Ia memilih analogi yang tepat, membagi langkah-langkah, dan menyiapkan konteks terlebih dahulu. Namun ketika tingkat kesulitan penalaran meningkat, ia mulai tersendat pada masalah yang bisa dipecahkan Opus 4.8 sekaligus.
Ringkasannya dalam satu kalimat: Opus 4.8 pintar tapi berbicara dengan sulit, sementara Opus 4.6 menjelaskan dengan mudah dipahami tapi performa penalarannya lebih rendah.
Ini bukan cacat. Mengapa demikian, dan bagaimana mengubah perbedaan ini menjadi keunggulan struktural — itulah topik artikel ini.
Curse of Knowledge Juga Berlaku pada LLM
Pada tahun 1989, psikolog Camerer, Loewenstein, dan Weber membuktikan melalui eksperimen: semakin banyak informasi yang dimiliki seseorang, semakin ia gagal mempertimbangkan fakta bahwa lawan bicaranya tidak mengetahui informasi tersebut. Fenomena yang disebut “Curse of Knowledge” ini adalah bias kognitif yang telah dikonfirmasi berulang kali dalam pedagogi, ekonomi, dan desain UX.
Oliver Wendell Holmes berkata, “Saya tidak akan memberi satu sen pun untuk kesederhanaan di sisi ini dari kompleksitas. Tetapi saya akan mempertaruhkan nyawa saya untuk kesederhanaan di sisi sana dari kompleksitas.” Penjelasan yang mudah bukan karena tidak tahu, melainkan baru mungkin setelah menembus kompleksitas. Namun secara paradoks, selama masih berada di tengah kompleksitas, kemampuan untuk berbicara dengan sederhana justru menurun.
Makalah EMNLP 2025 menunjukkan bahwa fenomena ini juga muncul pada model penalaran skala besar. Hasilnya paradoks: semakin kuat kemampuan penalaran suatu model, semakin rentan ia terhadap Curse of Knowledge. Model yang bernalar secara mendalam secara implisit menganggap lawan bicaranya juga bisa mengikuti proses penalarannya. Inilah masalah yang sama persis yang dialami seorang pakar ketika menjelaskan kepada pemula.
Maka di dunia ini ada dua jenis peran. Orang yang berpikir mendalam dan orang yang menyampaikan dengan mudah dipahami. Peneliti dan komunikator sains. Senior developer dan tech lead. Hakim dan pengacara. Keduanya adalah kemampuan yang berbeda. Tentu lebih baik jika satu orang bisa melakukan keduanya, tapi pada kenyataannya hal itu jarang terjadi. Karena itulah organisasi memisahkan peran.
Hal yang sama berlaku untuk LLM. Dan Claude Code memungkinkan pemisahan ini hanya dengan satu baris pengaturan.
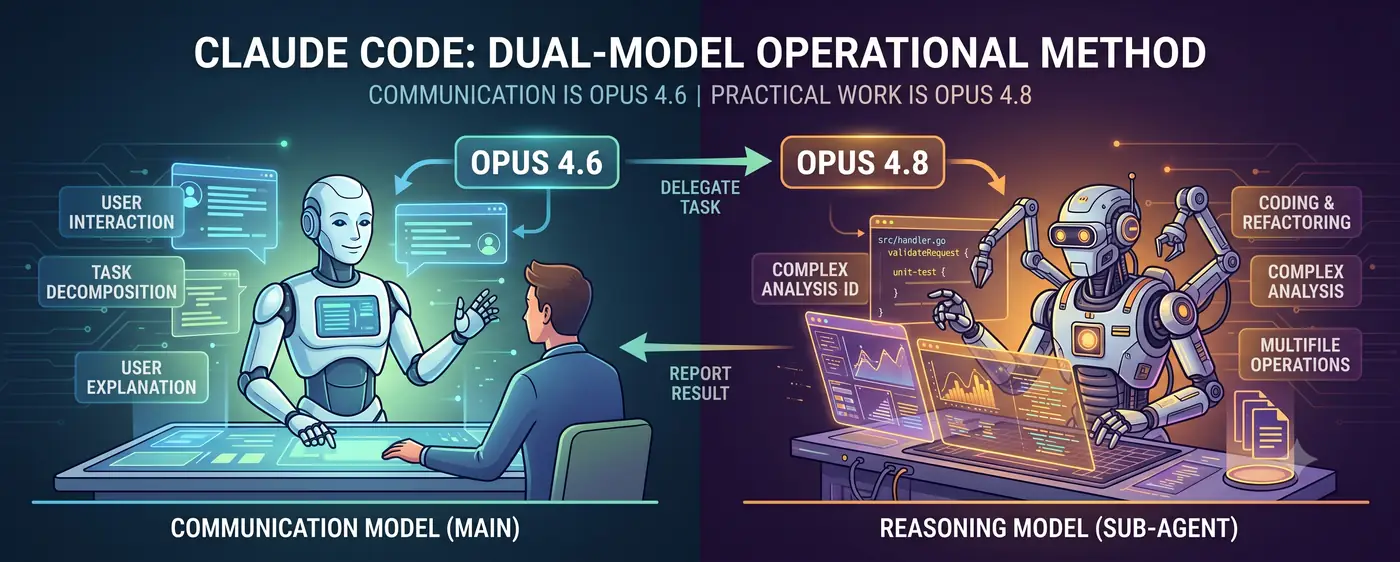
Model Komunikasi + Model Penalaran
Struktur intinya sederhana.
Pengguna ↔ Model Komunikasi (Utama) ↔ Model Penalaran (Subagent)
- Model komunikasi (Opus 4.6) berdiri di garis depan percakapan. Ia memahami maksud pengguna, memecah tugas, dan melaporkan hasil dalam bahasa yang dapat dipahami manusia.
- Model penalaran (Opus 4.8) menangani pekerjaan aktual. Ia menerima delegasi tugas penalaran tingkat tinggi seperti penulisan kode, analisis kompleks, dan refactoring multi-file sebagai subagent.
Pengguna bercakap-cakap dengan 4.6. Ketika 4.6 menilai “tingkat kesulitan penalaran ini terlalu tinggi untuk saya tangani langsung”, ia membuat subagent 4.8 dan mendelegasikan tugas. Ketika 4.8 mengembalikan hasil, 4.6 menginterpretasikannya dan menjelaskannya kepada pengguna.
Artikel ini sendiri adalah buktinya. Yang menulis artikel ini sekarang adalah Opus 4.6 (utama), sementara pencarian makalah akademis dan analisis data benchmark yang menjadi dasar artikel ini dilakukan oleh Opus 4.8 (subagent).
Apa yang Dikatakan Benchmark
Data BenchLM mengungkapkan karakter kedua model dalam angka.
| Area | Opus 4.6 | Opus 4.8 | Keunggulan |
|---|---|---|---|
| Keseluruhan | 86 | 93 | 4.8 |
| Coding | 64.4 | 76.4 | 4.8 |
| Tugas agen | 72.6 | 80.1 | 4.8 |
| Tugas pengetahuan | 76.2 | 70.1 | 4.6 |
| Penulisan kreatif | Unggul | - | 4.6 |
Dalam coding dan tugas agen, 4.8 mendominasi. Namun dalam transfer pengetahuan dan penulisan kreatif, 4.6 unggul. Dalam ulasan Claude API pun, evaluasi bahwa tulisan 4.8 “lebih terdengar seperti AI (more AI-sounding)” dibandingkan 4.6 terus berulang. 4.8 bernalar dengan akurat, tetapi kemampuan untuk menguraikan penalaran tersebut agar enak dibaca manusia lebih baik pada 4.6.
Harga kedua model identik — input 1 juta token $5, output 1 juta token $25. Membagi peran tidak menambah biaya. Ini bukan optimasi biaya, melainkan murni optimasi kualitas.
Model Routing Sudah Menjadi Rekayasa yang Terbukti
Ide “menggunakan dua model secara terpisah” tidaklah baru. Di dunia akademis, ini sudah menjadi bidang yang mapan.
RouteLLM (ICLR 2025) melakukan routing dinamis antara model kuat dan model lemah berdasarkan kueri, mengurangi biaya lebih dari 2 kali lipat sambil mempertahankan kualitas. FrugalGPT (2023) mencapai performa setara GPT-4 dengan penghematan biaya 98% melalui LLM cascade. Kesimpulan bersama dari penelitian-penelitian ini jelas: model lemah dengan orkestrasi yang unggul sering mengalahkan model kuat dengan orkestrasi yang buruk.
Anthropic sendiri juga menggunakan pola ini. Implementasi deep-research Anthropic menggunakan pola orchestrator-worker, dan komposisi multi-agent mengungguli Opus 4 single agent sebesar 90,2%. Ada juga hasil survei yang menunjukkan bahwa sekitar 80% sistem multi-agent produksi menggunakan struktur orchestrator-worker.
Apa yang saya lakukan adalah bentuk paling sederhana dari pola ini. Bukan router, bukan cascade, bukan optimasi biaya. Hanya model yang dioptimalkan untuk komunikasi berdiri di depan, dan model yang dioptimalkan untuk penalaran bekerja di belakang. Prinsip pemisahan peran itu sendiri.
Cara Mengaturnya
Membuat struktur ini di Claude Code sangat sederhana.
Langkah 1: Mengatur Model Utama
Jalankan Claude Code dengan Opus 4.6. Tentukan model default sebagai claude-opus-4-6-20250610 di pengaturan, atau pilih model saat menjalankan. Inilah yang menjadi model komunikasi yang bercakap-cakap dengan pengguna.
Langkah 2: Override Model pada Subagent
Tool Agent di Claude Code mendukung parameter model. Saat membuat subagent, cukup override model ke opus (Opus 4.8).
Agent({
description: "Refactoring kode",
model: "opus",
prompt: "Fungsi validateRequest di src/handler.go..."
})
Itu saja. Agent utama (4.6) bercakap-cakap dengan pengguna, dan tugas tingkat tinggi didelegasikan ke subagent (4.8).
Langkah 3: Membedakan fork dan fresh agent
Ada dua jenis subagent di Claude Code.
- fork (
subagent_type: "fork"): Mewarisi konteks percakapan saat ini secara utuh. Karena berbagi prompt cache, biaya input bisa berkurang hingga 90%. Namun, fork mewarisi model induk secara paksa sehingga override model tidak berlaku. - fresh agent: Dimulai dari konteks baru. Override model dimungkinkan. Anda perlu menyertakan latar belakang yang diperlukan langsung di prompt.
Oleh karena itu, untuk menggunakan model penalaran (4.8), Anda harus membuat fresh agent. fork digunakan ketika membutuhkan eksplorasi paralel sambil mempertahankan model komunikasi (4.6).
Pola Praktis
| Situasi | Metode | Alasan |
|---|---|---|
| Penulisan kode kompleks | fresh agent + model: opus | Tingkat kesulitan penalaran tinggi |
| Refactoring multi-file | fresh agent + model: opus + isolation: worktree | Penalaran + isolasi diperlukan |
| Investigasi/eksplorasi paralel | fork (tetap 4.6) | Berbagi konteks lebih menguntungkan |
| Membaca/mengedit file sederhana | Utama (4.6) langsung | Overhead delegasi lebih besar |
| Pencarian web/riset | fresh agent + model: opus | Penalaran akurat diperlukan |
Hingga 4-8 worktree simultan masih stabil. Lebih dari itu, review hasil menjadi bottleneck.
Hambatan yang Diketahui
Belum sempurna. Saat ini ada dua kendala yang diketahui.
Pertama, masalah kebocoran override model. Pengaturan model subagent dapat merambat hingga ke sub-agent yang dibuat oleh subagent tersebut. Penggunaan model yang tidak diinginkan bisa terjadi, sehingga membatasi kedalaman subagent ke 1 level adalah pendekatan yang praktis.
Kedua, tidak adanya pengaturan model per agen. Saat ini Claude Code tidak secara resmi mendukung fitur untuk menentukan model terlebih dahulu berdasarkan jenis agen di pengaturan proyek. Anda harus menyertakan parameter model setiap kali memanggil Agent. Permintaan untuk fitur ini juga aktif di komunitas.
Kedua kendala ini akan teratasi seiring evolusi Claude Code. Dalam kondisi saat ini pun, override manual saja sudah cukup untuk menikmati keunggulan strukturnya.
Komunikator dan Pemikir Adalah Peran yang Berbeda
Di pengadilan, hakim dan pengacara menangani hukum yang sama tetapi perannya berbeda. Hakim memutuskan. Pengacara menjelaskan apa arti keputusan itu kepada klien. Jika hakim langsung membacakan putusan kepada klien, klien tidak akan mengerti. Jika pengacara langsung membuat putusan, dasarnya akan lemah. Pemisahan peran bukan kelemahan sistem, melainkan kekuatannya.
Hal yang sama berlaku dalam code review. Kemampuan senior developer menemukan bug dan kemampuan membuat junior developer memahami bug tersebut adalah dua hal yang terpisah. Jarang ada engineer hebat yang sekaligus tech writer hebat. Organisasi tahu ini, maka mereka memisahkan peran.
AI juga sama. Kemampuan penalaran dan kemampuan komunikasi adalah sumbu yang berbeda. Dan dalam proses pelatihan model saat ini, kedua sumbu ini cenderung saling bertentangan. Memaksimalkan performa penalaran membuat output menjadi padat dan teknis, sementara memaksimalkan performa komunikasi membuat kedalaman penalaran menjadi dangkal.
Meminta satu model untuk melakukan keduanya dengan baik sama seperti meminta hakim untuk sekaligus berperan sebagai pengacara. Bisa saja dilakukan. Tapi keduanya tidak akan optimal.
Pemisahan model komunikasi dan model penalaran adalah prinsip struktural yang tetap berlaku meskipun versi berganti. 4.6 dan 4.8 hanyalah pilihan konkret hari ini. Jika besok keluar 5.0 dan 5.2, tinggal terapkan kembali dengan prinsip yang sama. Model berganti, tetapi fakta bahwa “peran berpikir mendalam” dan “peran menyampaikan dengan mudah dipahami” itu berbeda — tidak pernah berganti.
Artikel Terkait
- Ratchet Pattern — Cara Membuat Agen Menyelesaikan Sampai Tuntas
- Mengapa Agentic Loop Anda Menyimpang
- Mengapa Drift Tidak Pernah Mati
Bacaan lanjutan (eksternal)
- RouteLLM: Learning to Route LLMs with Preference Data — Framework untuk melakukan routing dinamis antara model kuat dan model lemah berdasarkan tingkat kesulitan kueri.
- Anthropic: How we built our multi-agent research system — Bagaimana Anthropic mengimplementasikan deep-research dengan pola orchestrator-worker.
Referensi
- Camerer, C., Loewenstein, G. & Weber, M. (1989). The Curse of Knowledge in Economic Settings: An Experimental Analysis. Journal of Political Economy, 97(5), 1232-1254. DOI — Pembuktian eksperimental Curse of Knowledge.
- Li, W. et al. (2025). Curse of Knowledge: Your Guidance and Provided Knowledge are biasing LLM Judges in Complex Evaluation. Findings of EMNLP 2025. arXiv — Temuan bahwa model penalaran yang lebih kuat lebih rentan terhadap Curse of Knowledge.
- Ong, I. et al. (2025). RouteLLM: Learning to Route LLMs with Preference Data. ICLR 2025. arXiv — Framework untuk mempelajari routing LLM menggunakan data preferensi.