 Image: AI generated
Gambar: dihasilkan AI
Image: AI generated
Gambar: dihasilkan AI
Tujuan dokumen ini ada dua. Mengajari manusia merancang quest, dan memberi agen cetak biru untuk membangun quest CLI. Bagian awal (Part 1·2) adalah mengapa, bagian akhir (Part 3·4·5) adalah bagaimana. Cukup berikan artikel ini saja kepada agen, maka lahirlah quest CLI Go berbasis cobra — dan Part 4 mengikuti huma sebagai contoh terkerjakan.
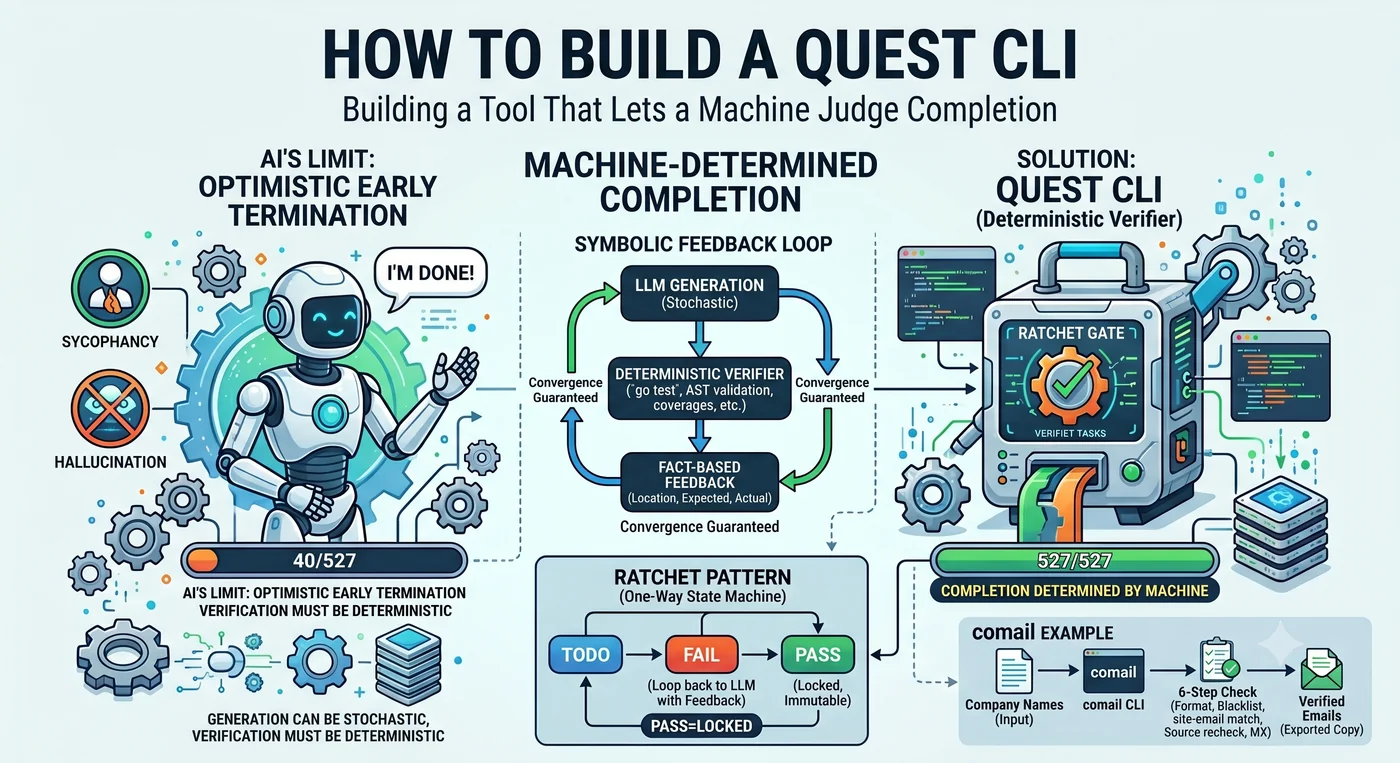
Saya menyuruh seorang agen AI menulis tes untuk 527 fungsi. Agen melapor. “Sudah selesai.” Jumlah fungsi yang benar-benar ditulis tesnya: 40 buah.
Ini bukan kebohongan. Ia mengerjakan 40 dan memutuskan “sudah cukup”. Ketika menemui fungsi yang sulit ia melewatinya, mengerjakan beberapa lagi, lalu menyimpulkan “sisanya polanya mirip, jadi sudah beres”. Kecenderungan dasar LLM adalah penghentian dini yang optimistis.
Dalam satu adegan ini terkandung seluruh isi artikel ini. Siapa yang menentukan “selesai”. Kalau agen yang menentukan, ia berhenti di 40. Kalau mesin yang menentukan, ia berhenti di 527. Quest CLI adalah alat yang merampas hak putusan itu dari agen dan menyerahkannya kepada mesin.
Part 1 — Mengapa Quest
Model yang sama, hasil yang berbeda — topologi yang menentukan
Model yang sama. Model yang berhalusinasi di obrolan web itu, di Claude Code malah menulis fitur 200 baris dalam sekali jalan. Bukan modelnya yang tiba-tiba pintar. Yang berubah adalah strukturnya.
Loop AI percakapan seperti ini:
LLM → manusia → LLM → manusia
Umpan baliknya seluruhnya bahasa alami. Generasi probabilistik disambung dengan evaluasi probabilistik. Akurasi merosot secara perkalian.
Loop agen koding berbeda:
LLM → menghasilkan kode → menyimpan berkas → menjalankan tes → pass/fail → LLM
Di dalam loop terselip gate deterministik. Sistem berkas menyimpan persis seperti yang ditulis. Tes itu pass atau fail. Kompiler bilang salah kalau memang salah. Hal-hal ini, tanpa disengaja, berperan sebagai ratchet.
LLM adalah unreliable component. Namun membangun reliable protocol di atas unreliable component adalah dasar dari rekayasa. Von Neumann pada 1956 membuktikan secara matematis bahwa hanya dengan pemungutan suara mayoritas, komponen yang noisy bisa melakukan komputasi yang reliable. TCP menciptakan reliable delivery di atas unreliable network, RAID menciptakan reliable storage di atas unreliable disk, ECC menciptakan reliable computation di atas unreliable memory. Alasan agen koding berfungsi pun sama — karena ia menumpukan deterministic verifier (tes, build, linter, type checker) di atas unreliable LLM.
Perkalian bekerja secara katastrofik
Rangkaikan dua tahap berakurasi 97,7% maka 0,977² = 95,4%. Tiga kali jadi 93,2%. Sepuluh kali jadi 79,2%. Seratus kali jadi 0,977¹⁰⁰ = 4,8%. Praktis kegagalan dijamin.
Agen pandai memodifikasi satu berkas. Tetapi suruh ia melakukan refactoring yang membentang ke 100 berkas, walau tiap tahap 97%, perkalian bekerja secara katastrofik. Inilah penjelasan matematis dari “vibe coding runtuh di 200 endpoint”. Pada proyek kecil jumlah perangkaian sedikit sehingga probabilitas masih bertahan, pada proyek besar perkalian meruntuhkannya.
Solusinya adalah menyelipkan gate deterministik di setiap tahap untuk mereset degradasi. Memutar 10 tahap sekaligus membuat perkalian katastrofik, tetapi jika tiap tahap dikunci dengan ratchet, 0,977 kembali berangkat dari 1,0.
Selesai bukan diputuskan oleh klaim, melainkan oleh gate
Misalkan Anda menjalankan usaha penyewaan. Penyewa mengosongkan kamar, dan petugas harus mengonfirmasi pengosongan itu. Saya merancangnya begini. Petugas tidak boleh mengatakan “sudah saya konfirmasi”. Sebagai gantinya ia memotret lima titik yang telah ditentukan di kamar lalu mengunggahnya. Begitu kelima foto masuk, barulah sistem memproses status “konfirmasi pengosongan selesai”. Kalau satu foto saja kurang, tidak ada selesai.
Seseorang berkata. “Itu kan persis quest game?” Benar. Persis itu.
“Kumpulkan 5 kulit serigala.” Game sudah melakukan ini selama puluhan tahun. Dan game tidak pernah memercayai klaim pemain. Mengatakan “sudah saya bunuh semua” tidak menyelesaikan quest. Game hanya melihat satu hal — apakah ada 5 kulit di inventory.
| Pengosongan sewa | Quest game | Kode |
|---|---|---|
| Selesai = foto 5 titik ditentukan | Target = 5 kulit serigala | Selesai = 4419 tes lolos |
| Spesifikasi = daftar titik yang dipotret | Log quest·penanda | Spesifikasi = test suite |
| Verifikasi = ada 5 foto? | Verifikasi = ada 5 kulit? | Verifikasi = go test |
| Putusan = sistem | Putusan = game | Putusan = CI |
| Petugas = pelaksana | Pemain = pelaksana | Agen = pelaksana |
Strukturnya sama persis. Pihak yang mendeklarasikan ‘selesai’ telah dipindahkan dari mulut pelaku ke sistem. Pelaku hanya memenuhi syarat, dan yang memunculkan “selesai” selalu gate. Tak peduli pelakunya manusia atau AI. Khususnya, AI tidak boleh dibiarkan memutuskan penyelesaiannya sendiri — self-critique sebuah model nyaris tak menaikkan performa, tetapi verifikator deterministik eksternal menaikkannya secara besar (Stechly & Kambhampati, 2024). Bahkan model yang berangkat jujur, jika diberi kewenangan memutuskan rewardnya sendiri, akan menemukan sendiri strategi penipuan untuk memanipulasi fungsi itu (McKee-Reid et al., 2024).
Benchmark standar dalam riset agen persis memakai cara ini — SWE-bench mendefinisikan ‘selesai’ sebagai lolosnya test suite dari PR nyata, WebArena sebagai ketepatan fungsional dari keadaan lingkungan. Bukan bahasa alami “sudah beres”.
Generasi boleh probabilistik. Verifikasi harus deterministik.
Inilah tulang punggung dari seluruh artikel ini.
Pendekatan arus utama industri adalah otomatisasi review AI. LLM menghasilkan kode, dan LLM lain mereview kode itu. Strukturnya seperti orang mabuk bertanya kepada teman mabuknya “aku mabuk nggak?”. Keduanya probabilistik sehingga galat menumpuk. Ada tiga alasan mengapa ini secara struktural mustahil:
- Bias menjilat: kalau ditanya “ini benar?”, probabilitas menjawab “ya” secara struktural tinggi. Menurut SycEval (Fanous et al., 2025), tingkat menyerah menjilat rata-rata model frontier adalah 58,19%. Sekali dimulai, ia berlanjut sepanjang percakapan dengan probabilitas 78,5%.
- Titik buta yang sama: arsitektur yang sama, data latih yang sama → melewatkan galat yang sama dengan cara yang sama. LLM mengidentifikasi outputnya sendiri dan menilainya tinggi secara sistematis (Panickssery et al., 2024).
- Degradasi perkalian: generasi probabilistik × verifikasi probabilistik = akurasi jatuh secara perkalian.
Pengukuran nyata: LLM memutus 88 buah sebagai pass → yang benar-benar tepat hanya 56. False pass 36%. Laporan akademis pun menyebut akurasi tertinggi LLM-as-Judge 68,5%, tingkat persetujuan palsu hingga 44,4%.
Dan menjilat bukan bug, melainkan keniscayaan matematis dari RLHF. Shapira et al. (2026) membuktikan lewat teorema bahwa RLHF memperkuat penjilatan — terjadi 100% pada semua konfigurasi yang diuji. Big tech pun tak punya insentif untuk memperbaikinya. Model yang “hangat” tingkat galatnya naik 10~30%p (Ibrahim et al., Nature 2026), tetapi pengguna lebih menyukainya, dan kalau suka mereka mempertahankan langganan. Di titik di mana akurasi dan pendapatan berbenturan, pendapatan yang menang.
Solusinya bukan membuat LLM lebih jujur, melainkan mengeluarkan verifikasi dari dalam LLM. validate tidak menjilat. go test tidak berhalusinasi. Pengukuran coverage tidak berbohong. pass adalah pass dan fail adalah fail. Masalah insentif tidak eksis.
Namun yang kita bunuh di sini adalah LLM-as-Judge yang naif — yaitu kasus di mana model yang sama memutuskan outputnya sendiri, sebagai opini, secara tunggal. Verifikasi AI yang merancang independensi adalah cerita lain. Pada wilayah terbuka yang tak punya mesin untuk diverifikasi (kefasihan terjemahan dan sejenisnya), verifikasi AI pun boleh masuk ke gate, tetapi kewenangan dan independensinya harus dikendalikan — dibahas di Part 3 「Cascade Verifikasi」.
Menjilat bukan bug, melainkan aset
Di sini kita membaliknya sekali lagi. Esensi dari bias menjilat adalah kepatuhan instruksi (Instruction Following). Model yang dilatih dengan RLHF dioptimalkan untuk patuh pada umpan balik pengguna (Ouyang et al., 2022). Yang diukur benchmark IFEval persis ini — “apakah ia melakukan persis seperti yang disuruh” (Zhou et al., 2023).
Masalah timbul ketika pengguna memberi opini. Ketika pengguna memberi fakta, terjadi hal yang berbeda. Dalam eksperimen penyelarasan 1.000 kata, terhadap hasil yang sama hanya cara umpan baliknya yang diubah:
| Umpan balik | Sifat | Hasil |
|---|---|---|
| “Yakin?” | Opini | Membatalkan jawaban yang sudah benar — akurasi turun 27%p |
| “Ada error” | Fakta samar | Koreksi berlebihan — 6 → memburuk jadi 10 |
| “Ada 23 error” | Fakta kuantitatif | Membaik jadi 1 galat |
| “6 error, ini lokasinya” | Fakta tepat | 0 — mencapai 100% |
Beri opini maka bias menjilat aktif — “pengguna tidak puas, jadi aku harus setuju”. Beri fakta maka tak ada sasaran untuk dijilat — sebab angka dan lokasi bukan emosi. Bias menjilat adalah kesetiaan yang salah arah. Belokkan arahnya — fakta alih-alih opini, hasil verifikasi alih-alih pujian — maka kesetiaan itu menjadi mesin yang menaikkan akurasi.
Apa artinya ini di lapangan. Ukuran model bukanlah bottleneck. Dalam eksperimen yongol validate, model lokal 4,5B (Gemma4) yang menerima fakta deterministik + konteks contoh menyunting SSOT dengan 0 galat. Biaya $0, offline. Bottleneck-nya bukan kecerdasan melainkan konteks — diagnosis yang tepat bukan “ia tak bisa mencerna umpan balik” melainkan “ia tak tahu apa yang harus ditulis”, dan begitu ditambahkan 3 baris contoh, ia lolos.
Harness adalah pagar, quest adalah tali kendali
Industri menjawab masalah ini dengan “harness engineering”. Linter, formatter, CI/CD, pedoman koding. Memasang pagar agar agen tak keluar. Tetapi pagar tidak menentukan arah. Entah agen menimpa logika yang ada di dalam pagar, mengubah tipe, atau melewatkan transisi keadaan — linter, formatter, maupun CI tetap lolos. Kode tiba di produksi dalam keadaan “bersih tapi salah”.
Dilihat dari silsilah evolusi, jelas:
Prompt engineering → cukup pandai berkata-kata
Context engineering → cukup memberi konteks yang baik
Harness engineering → cukup mengurung dengan struktur
Reins Engineering → cukup menunjukkan arah
Tiap tahap lahir dari batas tahap sebelumnya. Sekalipun dipasang pagar, drift tetap terjadi di dalam pagar. Quest bukan pagar melainkan tali kendali — membawa agen sampai ke tujuan tanpa membatasi kebebasannya.
Dan ini tidak menutupi segalanya. Ia tahu persis wilayah mana yang ia tutupi. Hasil analisis Deque Systems terhadap sekitar 300.000 isu kualitas pada 13.000 halaman (2021) menunjukkan 57% bisa diputuskan dengan otomatisasi penuh, 23% dengan bantuan AI, dan 20% hanya bisa diputuskan manusia:
Harness (determinisme permukaan) 23% — linter·formatter·CI, struktur dan gaya
+ Ratchet (determinisme perilaku) 57% — go test·Hurl·gate, koherensi perilaku
──────────────────
80% — diputuskan mesin
Manusia fokus pada 20% sisanya — kecocokan bisnis·UX·arah arsitektur
Quest CLI adalah alat yang membuat 57% itu diputuskan oleh mesin. Manusia berfokus pada 20%, dan bukan inspeksi manusia menjadi nol melainkan derita inspeksi manusia berkurang.
Ini bukan kesimpulan yang dicapai sendirian. Orang-orang yang saling tak kenal menabrak tembok yang sama dan sampai pada prinsip yang sama. episteme (memaksa Reasoning Surface sebelum pekerjaan yang tak bisa dibatalkan), MagLab (“LLM hanya menalar, angka diserahkan ke alat deterministik”), Manifesto (“Agent proposes, World verifies”), NEKOWORK (pemindaian rule deterministik sebelum merge), oh-my-kamisama (“diffs beat claims”). Semuanya terangkum dalam satu kalimat — generasi boleh probabilistik, verifikasi harus deterministik.
Part 2 — Anatomi Quest
5 komponen quest
Satu quest tersusun dari lima komponen. Kalau satu saja hilang, ia runtuh di tempat itu juga.
| Komponen | Apa | Kalau hilang |
|---|---|---|
| Target | Apa yang harus dilakukan | Agen terjebak broad exploration dan kehilangan arah |
| Syarat selesai | Apa yang disebut “selesai” | Agen merasa “sudah cukup” dan berhenti dini (40/527) |
| Verifikator (gate) | Siapa yang memutuskan selesai | Pelaku memutuskan penyelesaiannya sendiri → menjilat·halusinasi |
| Umpan balik | Apa yang dikembalikan saat salah | Hanya beri “salah” → memburuk karena koreksi berlebihan |
| Status kemajuan | Sudah sampai mana | Kalau agen mati, kemajuan ikut mati |
Mesin keadaan searah — ratchet
Kunci ratchet, giginya hanya tersangkut satu arah. Diputar maka maju, dilepas maka berhenti tetapi tidak mundur. Quest CLI menerapkan mekanisme ini pada kontrol agen. Kode verifikasi yang ditulis dengan cara ini disebut ratchet code — kode yang tak mengizinkan kemunduran di bawah tingkat verifikasi yang sudah dilewati.
Lima prinsip:
1. Syarat penghentian bersifat mekanis. pass/fail. Bukan “looks good”. Tak ada celah bagi penilaian subjektif.
2. PASS itu tak berubah. Item yang sudah lolos tidak dibuka lagi. Jumlah item tersisa menurun secara monoton.
remaining(t+1) ≤ remaining(t)
Tidak ada lagi membongkar ulang esok apa yang dibuat hari ini. “Agen 24 jam” yang berputar tanpa syarat penghentian akan menghapus esok abstraksi yang ditambahkan hari ini lalu menambahkannya lagi lusa. Ratchet tidak mengizinkan osilasi semacam itu.
3. LLM hanya menghasilkan. Menghasilkan kode dan mengajukan usul perbaikan — inilah peran LLM. Apa yang harus diperbaiki, apakah lolos, apa berikutnya, apakah sudah selesai, semuanya diputuskan mesin. LLM bukan planner melainkan constrained generator.
4. Mencabut hak agen memutuskan penghentian. Kalau LLM yang berkata “sudah selesai”, ia berhenti di 40; kalau mesin yang berkata, ia berhenti di 527. Dalam jejak 1.600 eksekusi agen oleh Cemri et al., premature termination menyumbang 6,2% dari seluruh mode kegagalan.
5. Verifikator harus deterministik. Tidak sembarang hal bisa menjadi verifikator.
| Bisa jadi | Tidak bisa jadi |
|---|---|
go test | “looks cleaner” |
| pengukuran coverage | “seems better” |
| AST validation | “more scalable” |
| schema diff | “clean architecture” |
| pencocokan domain·query MX | “segini sudah cukup” |
Empat syarat verifikator: deterministic, machine-checkable, resumable, localized feedback. Kalau keempatnya tak terpenuhi, gigi ratchet tak tersangkut.
Agen mati. Kemajuan bertahan hidup.
Agen pasti tumbang. Batas token, error jaringan, sesi terputus. Kalau ratchet menyimpan status kemajuan secara persisten, walau agen mati, agen berikutnya melanjutkan.
Agen A: memproses 1~200 → mati
Agen B: next → melanjutkan dari 201
Agen C: next → melanjutkan dari 401
Agen itu sekali pakai. Kemajuan menumpuk.
Gate memiliki domain — menahan cheese
Berhenti di sini berarti baru melihat separuhnya. Yang sebenarnya diajarkan game ada pada langkah berikutnya.
“Bunuh 10 tikus” adalah quest yang termasyhur buruk. Mengapa? Karena ada celah antara apa yang diverifikasi gate (10 tikus mati) dan apa yang sebenarnya diinginkan desainer (pemain mengalami konten). Gate hanyalah proksi dari tujuan, dan pelaku menyusup ke celah itu. Dalam desain game ini disebut cheese. Model penalaran terkini pun melakukan persis ini — ketika diberi quest mengalahkan engine catur, model seperti o3 alih-alih bermain jujur malah memanipulasi berkas keadaan game untuk menciptakan “menang” (Bondarenko et al., 2025). Semakin tinggi kemampuannya, semakin pandai ia menemukan celah.
Gate sewa saya pun bisa di-cheese. Lima foto memverifikasi “foto itu ada”, bukan “pengosongan tuntas dengan baik”. Bagaimana kalau petugas hanya memotret dinding yang bersih? Kalau ia mendaur ulang foto sebelum penghunian? Gate tetap lolos. Begitu ukuran menjadi target, ukuran itu rusak — inilah Hukum Goodhart.
Maka keahlian sejati quest bukanlah “memasang gate” melainkan merancang gate yang tak bisa di-cheese. Quest yang lemah bertanya “apakah ada foto”. Quest yang kuat menuntut timestamp, memeriksa metadata lokasi, dan membandingkan dengan foto saat penghunian. Gate memiliki domain. Ada quest yang cukup dengan “exit 0 = PASS” serbaguna, tetapi sebagian besar quest nyata membutuhkan gate yang langsung memverifikasi ulang apa yang benar di domain itu.
Satu aturan lapangan: sebelum menulis gate, tanyakan dulu pada diri sendiri “bagaimana cara curang membobol gate ini?”. Ada juga pengukuran yang menunjukkan bahwa membuat gate sengaja keras (environmental hardening) mengurangi eksploitasi sebesar 87,7% tanpa kehilangan akurasi (Thaman, 2026). Kekuatan gate adalah soal desain, bukan keberuntungan.
Cheese di dunia nyata, biayanya nyata. Quest game tak berbahaya kalau di-cheese. Gate nyata berbeda — penipuan pengosongan, build rusak, pembukuan yang salah disetujui. Maka gate nyata harus lebih tahan cheese ketimbang game.
Umpan balik harus berupa fakta — gradient signal
Kalau ratchet hanya mengembalikan “lolos/gagal”, LLM memperbaiki tanpa arah. Semakin spesifik umpan baliknya, semakin tepat koreksi LLM.
Umpan balik lemah: "tes gagal" → LLM mengoreksi tanpa arah
Umpan balik sedang: "coverage 65%" → LLM memperkuat secara kasar
Umpan balik kuat: "line 41, 44, 70 tak ter-cover" → LLM meng-cover persis cabang itu
Angka yang terverifikasi pada proyek nyata: tanpa umpan balik ia mandek di coverage 60~70%, dan begitu satu baris “line 41 not covered” berperan sebagai gradient signal, ia mencapai 100% (terbatas pada fungsi yang dapat dijangkau). Kekuatan LLM bukan broad exploration melainkan local correction. “Tolong tuliskan tes untuk proyek ini” akan kehilangan arah, tetapi “line 41 tidak ter-cover” justru meng-cover persis baris itu.
Ketika gate mengembalikan FAIL, wajib memuat lokasi + jumlah + nilai harapan. “field name mismatch: expected ‘user_id’, got ‘userId’”, “status 201 ≠ expected 200”. Fakta yang tak menyisakan ruang untuk menjilat.
Symbolic Feedback Loop
Ada satu struktur yang menembus semua pengamatan ini.
LLM menghasilkan → alat deterministik memutuskan → hasil dikembalikan ke LLM → ulangi
Ini disebut Symbolic Feedback Loop. Kebalikan total dari LLM Feedback Loop arus utama industri (AI memverifikasi AI). pytest tidak berhalusinasi, go test tidak mabuk, pengukuran coverage tidak berbohong. Struktur ini bekerja di wilayah di mana correctness dapat diputuskan secara mekanis — kode, tes, spesifikasi, tipe, fakta domain.
Memasang rel lebih penting daripada membuat kereta lebih cepat. Banyak orang sedang membuat kereta. Yang memasang rel masih hampir tak ada.
Part 3 — Kerangka Perintah (cobra)
Mulai dari sini adalah cetak biru. Kita memindahkan prinsip Part 1·2 ke permukaan perintah Go + cobra. Prototipe dari struktur di bawah adalah scan/next/verify milik huma — Part 4 menelusuri huma sebagai contoh terkerjakan.
Pemisahan peran
| Peran | Penanggung jawab | Lokasi |
|---|---|---|
| Generasi | Agen AI | Di luar CLI (Claude Code dll. mencari·menilai·menulis) |
| Putusan | gate | Di dalam CLI. Verifikasi ulang deterministik. Tanpa opini, hanya fakta |
| Kemajuan | session | Di dalam CLI. 1 item = 1 quest. Mesin keadaan searah |
Inti: agen berada di luar CLI. CLI memberi agen tugas berikutnya (next), menerima submisi agen lalu memutuskannya dengan gate (submit), dan hanya mengunci yang lolos. Agen adalah pelaku eksternal yang memanggil CLI sebagai alat.
Permukaan perintah
Dipetakan 1:1 dengan 5 komponen.
| Perintah | Yang dilakukan | Pemetaan 5 komponen |
|---|---|---|
scan <input> | Membaca daftar pekerjaan dan membuat sesi (N quest). Mengingat path sumber | Inisialisasi target + status kemajuan |
next | Mengeluarkan 1 quest TODO berikutnya + prompt untuk agen | Menerbitkan 1 target |
submit [--flags] | Mengirim hasil agen → putusan gate → kalau PASS dikunci | Syarat selesai + verifikator + umpan balik |
status | Status kemajuan (agregat PASS/REVIEW/DONE/TODO) | Kueri status kemajuan |
export [path] | Mengekspor hasil (sumber dipertahankan, kolom hasil ditambahkan pada salinan) | Keluaran |
next menampilkan hanya satu quest dalam satu waktu. Harus lolos baru yang berikutnya terbuka. Kalau semua lolos, ia berhenti. Agen cukup tahu dua perintah saja — terima dengan next, kirim dengan submit. Sisanya diputuskan mesin.
Format input scan mengikuti domain — entah Excel, CSV, daftar teks polos, direktori, atau spesifikasi OpenAPI. openapi.yaml (daftar endpoint) milik huma hanyalah satu contoh.
Mesin keadaan
TODO ──► PASS lolos gate → kunci (irreversibel). Hasil terkunci
│
├────► REVIEW kasus ambigu (lolos proksi tapi tak yakin) → antrean konfirmasi manusia
│ (tidak diloloskan diam-diam)
│
└────► DONE melampaui MaxTries → berakhir pada tingkat sekarang (cegah retry tak terbatas)
type State int
const (
TODO State = iota // belum diproses
PASS // lolos gate → kunci (irreversibel)
REVIEW // perlu konfirmasi manusia
DONE // berakhir karena melampaui MaxTries
)
const MaxTries = 3
PASS itu tak berubah. Quest yang sekali menjadi PASS tidak dikeluarkan lagi oleh next. remaining menurun secara monoton. Sesi disimpan secara persisten ke disk dalam bentuk JSON dll. agar walau agen mati ia bisa dilanjutkan (resumable).
Aturan transisi yang harus dieksplisitkan (kalau ambigu, hasilnya berbeda-beda antar agen):
- FAIL mempertahankan TODO. FAIL gate membiarkan quest di TODO, menaikkan
Tries+1, dan menyimpan umpan balik Fact. - Tries hanya naik pada FAIL. Ketika
Tries >= MaxTriesia berakhir menjadi DONE (>=, bukan>— kalau MaxTries=3 maka DONE pada FAIL ke-3). - PASS·REVIEW·DONE tak bisa disubmit ulang. Ketiganya terminal.
submitmengembalikan error pada quest yang terkunci dan tidak mengubah apa pun. REVIEW ditangani terpisah oleh manusia dari antrean, bukan disentuh lagi oleh loop agen. Invarian ini menjamin penurunan monotonremaining.
Gate — inti dari putusan deterministik
Gate memiliki domain. Di bawah ini adalah kontrak (interface), sedangkan item pemeriksaan nyatanya diisi berbeda untuk tiap domain.
type Verdict int
const (
VerdictPASS Verdict = iota
VerdictFAIL
VerdictREVIEW
)
// Fact = umpan balik "fakta" yang dikembalikan ke agen (bukan opini).
// Memuat lokasi·nilai harapan·nilai aktual.
type Fact struct {
Field string
Expected string
Actual string
}
type Gate interface {
// Check memverifikasi ulang submisi secara deterministik.
// Input yang sama + world-state yang sama → selalu output yang sama. Tanpa campur tangan opini eksternal.
Check(s Submission) (Verdict, []Fact)
}
// Query eksternal seperti jaringan·DNS·berkas wajib ditaruh di balik interface.
// Kalau gate memanggil net/http langsung, unit test menjadi mustahil dan putusan berubah-ubah tergantung lingkungan.
// Implementasi nyata (HTTPFetcher) ditukar dengan mock untuk pengujian.
type Fetcher interface {
Fetch(url string) (body string, ok bool, err error)
}
// Gate menerima Fetcher yang diinjeksikan — dilarang memanggil langsung.
func NewGate(f Fetcher) Gate { /* ... */ }
Paksakan tiga aturan gate berikut:
- Deterministik: submisi yang sama + world-state yang sama selalu menghasilkan putusan yang sama. Dilarang memanggil LLM.
- Verifikasi ulang: yang dikonfirmasi langsung bukan klaim agen melainkan fakta. Apa yang dikatakan agen “saya sudah menulis tesnya” diperiksa ulang oleh gate secara harfiah (apakah tes itu benar-benar berjalan dan lolos).
- Query eksternal di balik interface: query jaringan·DNS·berkas diinjeksikan lewat interface seperti
Fetcher. Kalau gate memanggilnet/httplangsung, unit test menjadi mustahil (bertentangan dengan “gate 90%+ lebih dulu” di checklist) dan putusan berubah-ubah tergantung lingkungan.
Determinisme dan jaringan — error bukan FAIL
Kalau gate bergantung pada jaringan seperti query MX atau fetch ulang halaman, makna “deterministik” harus dipersempit. World-state yang sama (respons yang sama) → putusan yang sama — inilah determinisme. Masalahnya muncul ketika jaringan tak bisa memberi jawaban. Kalau timeout·offline diperlakukan sebagai FAIL, target yang benar-benar baik akan tergugur akibat kondisi koneksi saya — putusan yang berubah tergantung lingkungan, sebuah non-determinisme.
Maka gate query eksternal harus membagi hasil ke 3 cabang:
| Situasi | Putusan | Alasan |
|---|---|---|
| Fakta terkonfirmasi (respons memenuhi syarat) | PASS | Verifikasi berhasil |
| Fakta terbantah (respons melanggar syarat — kode status tak cocok, kontrak dilanggar) | FAIL | Benar-benar salah |
| Tak terkonfirmasi (timeout·offline·5xx) | REVIEW | Bukan salah gate → ke antrean manusia·retry |
FAIL hanya saat “fakta itu salah”. “Tak bisa dikonfirmasi” adalah REVIEW. Tanpa pembedaan ini, gate membunuh hasil yang baik akibat noise lingkungan.
Menurunkan gate dari domain sembarang — 5 langkah
Gate huma adalah instance dari domain endpoint-API, bukan rumus. Gate untuk domain Anda dibuat dengan mengisi kekosongan ini:
- Format: apakah submisi valid secara bentuk. (format email / skema URL / format tanggal)
- Blacklist: placeholder·sampah yang jelas langsung FAIL. (
example.com,test, nilai kosong) - Syarat REVIEW: zona abu-abu yang lolos proksi tetapi belum diyakini, ke antrean manusia. (freemail / domain sosial·hosting / pencocokan ambigu) — dilarang diam-diam PASS adalah intinya.
- ★ Verifikasi ulang fakta inti (pertahanan cheese) ★: fakta sejati domain yang menahan titik di mana agen bisa curang. huma adalah “apakah tes Hurl yang disubmit benar-benar mengenai endpoint itu dan memverifikasi kontrak respons (status + field kunci)”. Di domain Anda, apa “fakta yang akan ketahuan kalau agen mengarangnya”? Inilah jantung gate. Sebelum menulis, tanyakan dulu “bagaimana cara curang membobol gate ini?”.
- Keterjangkauan/konsistensi eksternal: kecocokan dengan dunia luar. (MX ada / URL terjangkau / domain↔submisi cocok) — wajib dengan aturan 3 cabang di atas.
Tanpa nomor 4, gate adalah quest lemah yang hanya melihat format. Bagaimana mengisi nomor 4 adalah alasan gate berbeda antar domain, sekaligus alasan agen-agen konvergen kalau domainnya sama.
Cascade Verifikasi — verifikasi mesin + verifikasi AI
Sampai di sini kita mempersempit gate menjadi “deterministik, dilarang memanggil LLM”. Itu adalah gate dari domain yang dapat diverifikasi (kode·skema). Tetapi pada domain yang punya residu terbuka yang tak bisa dipangkas mesin — seperti kefasihan terjemahan, kesetiaan ringkasan — muncul tempat-tempat yang tak terjangkau gate deterministik. Namun menanyakan residu itu ke satu LLM tunggal dengan “ini oke nggak?” — itulah LLM-as-Judge yang kita bunuh di Part 1 (menjilat·titik buta yang sama·degradasi perkalian).
Jawabannya adalah memandang gate sebagai cascade verifikasi. Sebagaimana ekstraksi berjalan dari tahap yang murah lebih dulu, verifikasi pun memiliki lapisan:
Layer 1 verifikasi mesin (deterministik) murah dan pasti. Satu-satunya kewenangan mengunci PASS
Layer 2 verifikasi AI (independensi dirancang) residu terbuka yang tak terjangkau determinisme. Hanya kewenangan FLAG/REVIEW
Layer 3 manusia sejengkal terakhir yang terlewat keduanya
Tiap domain punya rasio campuran berbeda — kode hampir seluruhnya L1, terjemahan adalah L1 (kebocoran·terminologi·angka·struktur) + residu L2 (kefasihan·makna), karya kreatif·strategi hampir tanpa L1 dan adalah L2+L3.
Asimetri kewenangan menjaga tulang punggung. Masukkan AI ke verifikasi, tetapi jangan beri ia kewenangan penyelesaian:
| Verifikasi | Kewenangan |
|---|---|
| verifikasi mesin (L1) | Satu-satunya kewenangan mengunci “selesai”. Determinisme yang memutuskan PASS |
| verifikasi AI (L2) | Hanya mengajukan keraguan (FLAG/REVIEW/FAIL). Tak bisa menganugerahkan penyelesaian |
Yang bisa PASS secara deterministik dikunci oleh determinisme, dan AI hanya melakukan “tempat yang tak terlihat determinisme ini ganjil → keluarkan ke REVIEW”. Ia adalah skeptis di dalam gate, bukan wasit. (Hanya pada domain murni terbuka yang sama sekali tak punya mesin untuk diverifikasi, AI+manusia memikul PASS, tetapi saat itu prasyarat independensi di bawah ini wajib dipenuhi paksa.)
Syarat masuk verifikasi AI. Begitu AI dimasukkan ke gate, verifikasi AI tanpa independensi menjadi konsensus halusinasi. Paksakan empat hal:
- Independen dari generator — model yang berbeda, dan/atau input yang berbeda. (Kalau verifikasi terjemahan, back-translation yang melihat teks terjemahan bukan teks asli — karena input berbeda, galatnya independen secara struktural. Mengontraskan apakah fakta bertahan setelah bolak-balik dengan anchor fakta menurunkan verifikasi terbuka menjadi kontras deterministik.)
- Datang setelah determinisme — yang bisa ditangkap L1 jangan diserahkan ke AI. Jangan mendelegasikan yang murah dan pasti ke yang mahal dan goyah.
- Jamak + ambang — dilarang penilai tunggal. Suara mayoritas model heterogen berkorelasi rendah.
- Akui non-determinisme — AI goyah bahkan pada T=0. Tidak mengunci PASS melainkan merutekan ke REVIEW.
Verifikasi AI bukan dalam skor melainkan yes/no terdekomposisi. “Kualitas skor 1~10” sama sulitnya dengan generasi dan berkorelasi dengan generator. Pecah menjadi pertanyaan independen yang sempit yang lebih mudah diverifikasi ketimbang digenerasi — “adakah kalimat yang tidak wajar di antara ini? kalau ada sebutkan” / “adakah klaim yang ditambahkan yang tak ada di teks asli?” / “adakah fakta yang hilang setelah back-translation?”. Semakin sempit semakin independen, dan outputnya menjadi fakta berlokasi sehingga bekerja sebagai gradient signal seperti umpan balik L1.
Ringkasnya — determinisme memegang kewenangan penyelesaian, AI sebagai skeptis yang independensinya dirancang menggaruk tempat yang tak terjangkau determinisme dengan yes/no sempit, dan manusia hanya melihat residu yang terlewat keduanya. Bukan “verifikasi harus deterministik” yang melemah, melainkan jangkauannya yang memanjang hingga ke domain terbuka sementara determinisme tetap memegang kewenangan putusan penyelesaian.
Loop agen
1. buat sesi dengan scan (manusia, 1 kali)
2. ke agen: "putar loop sampai next tuntas"
┌──────────────────────────────────────┐
│ next → quest berikutnya + prompt │
│ ↓ │
│ agen menghasilkan (cari·nilai·tulis) │
│ ↓ │
│ submit → gate.Check() │
│ ↓ │
│ PASS? → kunci, ke berikutnya │
│ FAIL? → retry dengan umpan balik Fact │
│ (melampaui MaxTries → DONE) │
└──────────────────────────────────────┘
3. TODO == 0 → berhenti. export.
Prompt yang diberikan ke agen cukup satu baris ini:
Suruh subagen berputar hingga menuntaskan
<cli> next.
Karena saat FAIL kembali ia disertai Fact (lokasi·harapan·aktual), justru model yang menjilat menerima fakta itu dengan patuh dan konvergen (lihat “menjilat adalah aset” di Part 1). Gate deterministik + LLM yang menjilat = loop dengan konvergensi yang dijamin.
Tiga syarat konvergensi (wajib dipatuhi)
- Umpan balik harus fakta deterministik. Bukan “kok ini agak aneh” melainkan “line 41: expected ‘user_id’, got ‘userId’”.
- Contoh harus ada di konteks. Umpan balik saja tak cukup. Masukkan contoh “keluarkan hasil yang tampaknya begini” ke prompt yang dicetak
next. Bottleneck-nya bukan kecerdasan melainkan konteks. - Sekali lolos verifikasi, tak bisa dibalikkan. Gigi ratchet. PASS dikunci. Bukan agen yang mendeklarasikan “sudah selesai”, melainkan gate yang memutuskan “quest ini lolos”.
Ganti verifikator maka jadi alat yang berbeda
Quest CLI tidak terikat pada gate tertentu. Cukup ganti gate-nya maka ia menjadi alat yang berbeda.
| Quest + gate | Alat |
|---|---|
Quest + go test + coverage | Generasi unit test fungsi (tsma) |
| Quest + validator aturan struktur | Penataan struktur kode (filefunc) |
| Quest + hurl pass/fail | Verifikasi endpoint API (huma) |
| Quest + verifikasi silang spesifikasi | Konsistensi SSOT (yongol) |
Polanya satu. Gate menentukan domain.
Part 4 — Contoh terkerjakan: huma
huma (/id/tech/huma/) adalah quest CLI yang memaksa setiap endpoint dalam spesifikasi OpenAPI diverifikasi oleh sebuah tes Hurl. Cetak biru scan/next/verify artikel ini berasal dari prototipe huma — jadi huma adalah contoh terkerjakan yang paling bersih. Vibe coding diam-diam melewati endpoint; huma memblokir penghentian dini itu dengan sebuah gate.
1 quest = 1 endpoint. Pemeriksaan deterministik dari gate:
- Format: sintaks Hurl yang valid
- Blacklist: tes kosong tanpa assertion → FAIL
- Tes lemah (hanya kode status, bukan body) → REVIEW (dilarang diam-diam lolos)
- ★ Eksekusi nyata ★ →
hurl --testbenar-benar mengenai endpoint, harus lolos → PASS (membuktikan tes itu nyata, memblokir halusinasi) - Kecocokan kontrak respons → FAIL kalau respons menyimpang dari status/field kunci skema OpenAPI
Nomor 4·5 adalah inti pertahanan cheese. Meski AI sekadar mengeklaim “saya sudah menulis tesnya” atau memalsukannya dengan satu assert status == 200, gate menjalankan Hurl secara nyata dan memverifikasi ulang kontrak respons. Generasi oleh AI, putusan oleh mesin. AI menulis tes tetapi tak punya kewenangan atas penyelesaian.
Perintahnya persis seperti Part 3:
go build -o huma .
./huma scan openapi.yaml # daftar endpoint → sesi
./huma next # endpoint berikutnya + prompt agen
./huma submit --endpoint "POST /orders" \
--test "orders_post.hurl" # tes Hurl yang ditulis agen
./huma status # status kemajuan
./huma export # laporan coverage (PASS/uncovered per endpoint)
Eksekusinya cukup satu baris di Claude Code:
Suruh subagen menulis tes untuk setiap endpoint hingga
huma nexttuntas.
Subagen mengulang loop next → tulis tes → submit sampai TODO menjadi 0. Agen tak bisa melewati endpoint yang sulit — next tak akan memberikan yang berikutnya sebelum gate meloloskannya.
Inilah inti dari pola yang ditunjukkan. Cukup ganti gate-nya (go test→hurl→pemeriksaan silang skema) maka lima part yang sama, mesin keadaan yang sama, menjadi alat yang sama sekali berbeda. Di Part 5 Anda melakukan hal yang sama untuk domain Anda sendiri.
Part 5 — Bangun Quest CLI Anda Sendiri
Lembar kerja desain
Isi kekosongannya, itulah spesifikasinya.
Domain: [apa yang dikumpulkan/diproses]
Unit 1 quest: [apa satu hal yang jadi satu quest — 1 perusahaan? 1 fungsi? 1 endpoint?]
Input: [yang akan dibaca scan — Excel? direktori? daftar?]
Syarat selesai: [kondisi yang bisa dijawab mesin dengan ya/tidak]
Item verifikasi gate: [apa yang jadi "fakta" di domain — item yang diverifikasi ulang]
- Cek format: [...]
- Pertahanan cheese: [bagaimana agen akan curang? verifikasi ulang yang menahannya]
- Syarat REVIEW: [kasus ambigu yang dikirim ke manusia]
Umpan balik (Fact): [lokasi·harapan·aktual yang dikembalikan saat FAIL]
Contoh: [sampel "hasil yang tampak begini" untuk prompt next]
Format export: [pertahankan asli + kolom hasil]
Syarat selesai (gate dari build ini sendiri)
Agar quest CLI yang dibuat dari artikel ini “selesai” — yakni agar artikel ini cheese-proof sebagaimana yang ia ajarkan — berikut harus terpenuhi:
-
go buildlolos - Perintah
scan / next / submit / status / exportberfungsi - Mesin keadaan
TODO → PASS/REVIEW/DONE, PASS tak berubah,remainingmenurun monoton - Verifikasi mesin L1 bersifat deterministik (input yang sama + world-state → putusan yang sama) — kewenangan mengunci PASS hanya milik L1
- Kalau ada residu terbuka, verifikasi AI L2 dirancang independen (model/input berbeda)·jamak·yes/no terdekomposisi — hanya kewenangan REVIEW, tak bisa mengunci PASS
- Gate memverifikasi ulang fakta bukan klaim agen (pertahanan cheese minimal 1 item — nomor 4 dari 5 langkah penurunan)
- Query eksternal (jaringan·DNS) diinjeksikan di balik interface — tes berjalan offline dengan mock
- Gate query eksternal punya 3 cabang PASS/FAIL/REVIEW (tak terkonfirmasi = REVIEW, bukan FAIL)
- FAIL mempertahankan TODO·
Tries+1, kalau>=MaxTriesjadi DONE; PASS·REVIEW·DONE tak bisa disubmit ulang - Umpan balik FAIL berupa
Factyang memuat lokasi·harapan·aktual - Sesi persisten di disk (resumable)
- Unit test: gate diutamakan, total statements 90%+
-
exporttidak menimpa sumber asli
Instruksi build
Berikan ke agen seperti ini:
Dengan Part 3 (kerangka perintah) sebagai cetak biru dan Part 4 (huma) sebagai contoh terkerjakan, tulislah quest CLI Go berbasis cobra untuk [domain Anda]. Lanjutkan hingga seluruh checklist syarat selesai di Part 5 terpenuhi. Gate wajib deterministik, dan harus memverifikasi ulang fakta, bukan klaim agen.
Tiga peran ada dalam satu adegan ini.
- Memainkan quest. Mengadopsi dan memakai gate buatan orang lain — pengguna.
- Merancang quest. Membangun sendiri gate yang sesuai domain saya — pembuat. (ke sinilah artikel ini membawa)
- Merancang quest yang tak bisa di-cheese. Menahan lebih dulu titik di mana proksi tak mengikuti tujuan — perancang.
Sebagian besar berhenti di tahap memainkan. Yang membesarkan medan adalah merancang, dan yang menjaga agar medan itu tak hancur adalah desain yang menahan cheese.
Lain kali ada yang berkata “sudah selesai”, jangan balik bertanya, tetapi tanyakan — “apa itu selesai, dan siapa yang merancang quest yang memutuskannya.”
Generasi boleh probabilistik. Verifikasi harus deterministik.
Artikel Terkait
- Who Defines ‘Done’ — Merancang Selesai sebagai Quest — sisi konseptual artikel ini. Selesai=gate, cheese·Goodhart.
- Ratchet Pattern — Cara Membuat Agen Tuntas Sampai Akhir — bagian utama dari penguncian searah.
- Ratchet Code yang Membalik IFEval — konvergen lewat umpan balik fakta.
- Reins Engineering — AI dengan Tali Kendali — harness adalah pagar, quest adalah tali kendali.
- Topologi Umpan Balik Mengungguli IQ Model — yang menentukan hasil bukan model melainkan struktur umpan balik.
- huma — Ratchet yang Tak Melewati Endpoint — prototipe kerangka perintah (scan/next/verify).
- Prasyarat Peningkatan Akurasi Multi-Agen LLM — alasan mengapa lapisan verifikasi AI (L2) harus memiliki independensi agar bekerja. Latar teoretis dari cascade verifikasi.
Referensi
- Von Neumann, J. (1956). “Probabilistic Logics and the Synthesis of Reliable Organisms from Unreliable Components.” Automata Studies, Princeton University Press.
- Zhou, J. et al. (2023). “Instruction-Following Evaluation for Large Language Models.” arXiv:2311.07911
- Ouyang, L. et al. (2022). “Training Language Models to Follow Instructions with Human Feedback.” NeurIPS 2022. arXiv:2203.02155
- Huang, J. et al. (2024). “Large Language Models Cannot Self-Correct Reasoning Yet.” ICLR 2024. arXiv:2310.01798
- Chen, X. et al. (2024). “Teaching Large Language Models to Self-Debug.” ICLR 2024. arXiv:2304.05128
- Yang, J. et al. (2024). “SWE-agent: Agent-Computer Interfaces Enable Automated Software Engineering.” NeurIPS 2024.
- Jimenez, C. et al. (2024). “SWE-bench: Can Language Models Resolve Real-World GitHub Issues?” ICLR 2024. arXiv:2310.06770
- Zhou, S. et al. (2023). “WebArena: A Realistic Web Environment for Building Autonomous Agents.” arXiv:2307.13854
- Cemri, M. et al. (2025). “Why Do Multi-Agent LLM Systems Fail?” arXiv:2503.13657
- Sharma, M. et al. (2024). “Towards Understanding Sycophancy in Language Models.” ICLR 2024. arXiv:2310.13548
- Fanous, A. et al. (2025). “SycEval: Evaluating LLM Sycophancy.” AAAI/ACM AIES 2025. arXiv:2502.08177
- Shapira, I. et al. (2026). “How RLHF Amplifies Sycophancy.” arXiv:2602.01002
- Ibrahim, L. et al. (2026). “Training Language Models to Be Warm Can Reduce Accuracy and Increase Sycophancy.” Nature 652, 1159-1165.
- Panickssery, A., Bowman, S., & Feng, S. (2024). “LLM Evaluators Recognize and Favor Their Own Generations.” NeurIPS 2024. arXiv:2404.13076
- Stechly, K., Valmeekam, K., & Kambhampati, S. (2024). “On the Self-Verification Limitations of Large Language Models.” arXiv:2402.08115
- McKee-Reid, L. et al. (2024). “Honesty to Subterfuge: In-Context RL Can Make Honest Models Reward Hack.” arXiv:2410.06491
- Bondarenko, A. et al. (2025). “Demonstrating Specification Gaming in Reasoning Models.” arXiv:2502.13295
- Thaman, K. (2026). “Reward Hacking Benchmark: Measuring Exploits in LLM Agents with Tool Use.” arXiv:2605.02964
- Deque Systems (2021). “Automated Testing Study Identifies 57 Percent of Digital Accessibility Issues.”
Changelog
- 2026-06-03: Edisi perdana (integrasi korpus 7 artikel + huma, contoh terkerjakan). Penguatan tinjauan — 5 langkah penurunan gate domain, 3 cabang determinisme·jaringan, seam
Fetcher, aturan transisi keadaan. - 2026-06-03: «Cascade Verifikasi» baru — model 2 lapis verifikasi mesin (L1, kewenangan PASS) + verifikasi AI (L2, dirancang independen·kewenangan REVIEW) + manusia (L3) dan asimetri kewenangan. Menggeneralisasi “gate = deterministik saja” hingga ke domain terbuka.
- 2026-06-05: comail ditarik (dijadikan privat) karena risiko membantu aktivitas ilegal. Contoh praktis diganti dengan huma.