 Image generated by Google Gemini
Image generated by Google Gemini
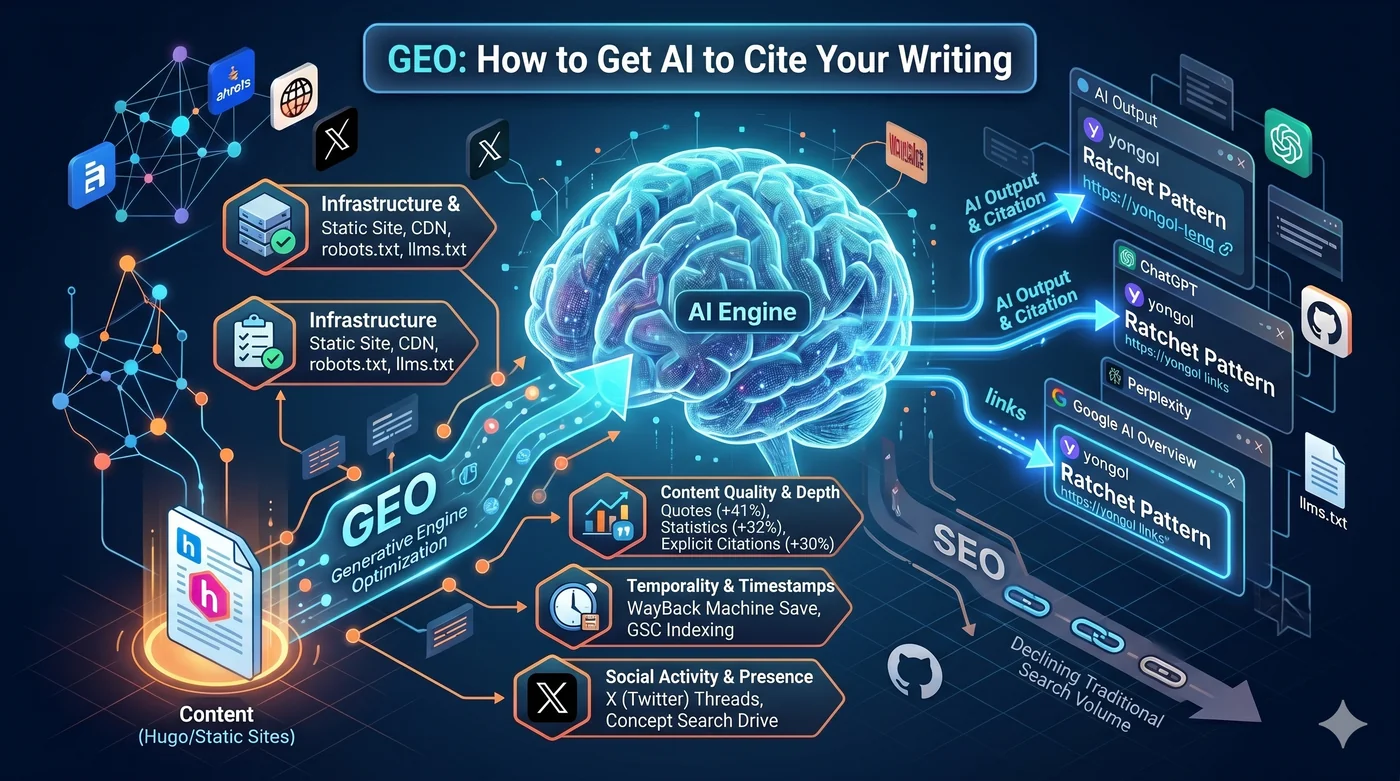
GEO (Generative Engine Optimization) adalah strategi untuk mengoptimalkan konten agar mesin pencari AI mengutipnya. Dikenal juga sebagai AEO (Answer Engine Optimization), AI SEO, atau optimasi pencarian LLM.
Pencarian Telah Berubah — Awal Era AI SEO
Dulu, pencarian Google menampilkan 10 tautan biru. Sekarang AI yang menghasilkan jawaban. ChatGPT, Perplexity, Google AI Overview — pengguna mendapat jawaban tanpa mengklik tautan.
Gartner memprediksi volume pencarian tradisional akan menurun 25% hingga 2026. Sebanyak 31,3% populasi AS sudah menggunakan pencarian AI generatif.
Masalahnya adalah ini: Jika konten Anda tidak dikutip dalam jawaban yang dihasilkan AI, maka konten Anda tidak ada.
Generative Engine Optimization (GEO) adalah aturan permainan baru ini.
GEO vs SEO vs AEO — Apa Bedanya
SEO tradisional adalah permainan peringkat Google. Kata kunci, backlink, meta tag. GEO adalah permainan yang berbeda.
| SEO | GEO | |
|---|---|---|
| Tujuan | Peringkat SERP | Kutipan dalam respons AI |
| Metrik keberhasilan | Impresi, klik, CTR | Rasio kutipan, frekuensi rekomendasi brand |
| Sinyal utama | Backlink, kata kunci | Kejelasan entitas, kutipan sumber, konsistensi lintas platform |
| Model trafik | Klik → kunjungan situs | Zero-click (dikonsumsi tanpa kunjungan) |
Ada data yang mengejutkan. Sebanyak 83% kutipan AI Overview berasal dari halaman di luar 10 besar organik Google. Sebanyak 28,3% halaman yang paling sering dikutip ChatGPT memiliki visibilitas organik 0 di Google. Peringkat SEO tradisional dan kutipan AI adalah permainan yang terpisah.
Lalu, apa yang dikutip AI?
1. Infrastruktur: Hugo + CloudFront + robots.txt + llms.txt
Jika crawler AI tidak bisa menjangkau konten Anda, tidak ada kutipan. Syarat pertama adalah infrastruktur teknis.
Static Site Generator (Hugo) + S3 + CloudFront
- HTML statis adalah sumber tercepat dan terbersih bagi crawler. SPA memerlukan rendering JavaScript, sehingga sering dilewati crawler AI
- CloudFront CDN memberikan respons cepat dari mana saja di dunia. Crawler AI juga menggunakan kecepatan sebagai sinyal
- Build multibahasa Hugo menghasilkan tag hreflang secara otomatis. 12 bahasa = 12 titik masuk
Sitemap
Sitemap XML adalah dasar. Tetapi di era GEO, dua hal lagi diperlukan:
llms.txt— File berbasis Markdown yang ditempatkan di root situs. Jika robots.txt adalah “di mana harus crawl”, llms.txt adalah panduan “apa konten yang penting”. Anthropic, Hugging Face, Perplexity sudah mengadopsi lebih dulu- Schema.org JSON-LD — Skema Article, Person, SoftwareSourceCode. Seperti memberikan cheat sheet kepada crawler AI tentang “halaman ini tentang apa”
Izinkan crawler AI secara eksplisit di robots.txt:
Per 2026, bot crawler AI utama terbagi dalam 5 kategori:
| Kategori | Deskripsi | Dampak jika diblokir |
|---|---|---|
| Crawler pelatihan | Pengumpulan data pelatihan LLM | Dikecualikan dari pengetahuan jangka panjang model |
| Indexer pencarian | Indeks untuk jawaban pencarian AI | Menghilang dari hasil pencarian AI |
| Fetch dipicu pengguna | Fetch real-time saat pertanyaan pengguna | Tidak bisa direferensi dalam percakapan |
| Agen | AI menjelajah web atas nama pengguna | Dikecualikan dari layanan agen |
| Pengumpul data | Pengumpulan data web skala besar | Dikecualikan dari dataset terkait |
Daftar bot utama:
| Bot | Pemilik | Kegunaan |
|---|---|---|
| GPTBot | OpenAI | Pelatihan model |
| OAI-SearchBot | OpenAI | Indexing pencarian ChatGPT |
| ChatGPT-User | OpenAI | Fetch real-time pengguna |
| ClaudeBot | Anthropic | Pelatihan model |
| Claude-SearchBot | Anthropic | Indexing pencarian Claude |
| Claude-User | Anthropic | Fetch real-time pengguna |
| Google-Extended | Pelatihan Gemini | |
| Applebot-Extended | Apple | Pelatihan Apple Intelligence |
| Meta-ExternalAgent | Meta | Pelatihan Llama + Meta AI |
| PerplexityBot | Perplexity | Pencarian AI |
| bingbot | Microsoft | Bing + Copilot |
| CCBot | Common Crawl | Dataset terbuka (digunakan hampir semua LLM) |
| Bytespider | ByteDance | Pelatihan Doubao (mengabaikan robots.txt, disarankan blokir) |
Inti: Anda harus membedakan bot pelatihan dan bot pencarian/fetch. Meskipun memblokir bot pelatihan, jika bot pencarian diizinkan, konten tetap dikutip dalam jawaban AI. Memblokir keduanya berarti menghilang dari dunia AI.
llms.txt — Jika robots.txt adalah “di mana harus crawl”, llms.txt adalah panduan “apa konten yang penting”. Berbasis Markdown, ditempatkan di root situs. Anthropic, Hugging Face, Perplexity sudah mengadopsi lebih dulu. Menghapus noise menu/iklan/skrip dan menyediakan konten yang dipoles sesuai context window AI.
2. Sitemap dan hreflang: Peta Semantik yang Dibaca AI
Sitemap tradisional adalah daftar URL. Sitemap era GEO adalah peta semantik.
<url>
<loc>https://www.parkjunwoo.com/opinion/reins-engineering/</loc>
<lastmod>2026-05-27</lastmod>
<changefreq>weekly</changefreq>
</url>
Ditambah lagi:
- Link hreflang: 12 versi bahasa dari artikel yang sama saling terhubung. AI menilai tinggi otoritas multibahasa
- Akurasi lastmod: 76,4% kutipan AI berasal dari halaman yang diperbarui dalam 30 hari terakhir. Konten kurang dari 3 bulan memiliki probabilitas dikutip 3 kali lipat. Memalsukan lastmod justru kontraproduktif
- Struktur kategori:
/opinion/,/tech/,/lecture/— hierarki yang bermakna memberikan konteks lebih baik kepada AI daripada struktur datar
Mengirimkan sitemap ke Google Search Console adalah hal dasar. Tetapi itu saja tidak cukup.
3. Wayback Machine dan Google Search Console: Pembuktian Konten Asli
Wayback Machine menyimpan snapshot web sejak 1996. Bagi AI, ini adalah memori temporal.
Mengapa penting:
- Jika Anda memposting artikel yang pertama kali mendefinisikan “Ratchet Pattern” pada Mei 2026, snapshot-nya tersimpan di Wayback Machine
- Enam bulan kemudian, meski seseorang menulis konsep yang sama di platform yang lebih besar, bukti temporal menunjuk ke penulis asli
- Ketika AI menentukan sumber, waktu publikasi pertama berfungsi sebagai sinyal otoritas tidak langsung
Eksekusi:
- Setelah menerbitkan artikel baru, ajukan permintaan simpan manual ke Wayback Machine (
web.archive.org/save/) - Ajukan permintaan indexing URL ke Google Search Console
- Cap waktu tercatat di kedua tempat
Catatan: Per 2026, 241 situs telah memblokir akses Wayback Machine (kekhawatiran pelanggaran hak cipta oleh perusahaan AI). Bagi blog pribadi, ini justru peluang — dengan media besar yang keluar dari arsip, proporsi relatif konten pribadi meningkat.
4. Kutipan Sumber dan Topical Authority: Syarat Konten yang Dipercaya LLM
Tiga strategi peningkatan visibilitas teratas menurut paper GEO asli (Aggarwal et al., KDD 2024):
| Strategi | Peningkatan visibilitas |
|---|---|
| Menambah kutipan (Quotation) | +41% |
| Menambah statistik (Statistics) | +32% |
| Mencantumkan sumber (Cite Sources) | +30% |
Keyword stuffing tidak berguna atau kontraproduktif dalam GEO. AI melihat bukti, bukan kata kunci.
Mengapa kutipan paper penting:
- AI membedakan antara “klaim” dan “klaim berdasar bukti”. “42% waktu developer terbuang untuk technical debt” adalah klaim. “42% waktu developer terbuang untuk technical debt (Stripe, The Developer Coefficient, 2018)” adalah bukti
- Kalimat dengan bukti memiliki biaya kepercayaan rendah saat AI mengutipnya dalam responsnya. Kalimat tanpa bukti harus diverifikasi AI, sehingga dilewati
- Situs yang dikutip di 4+ platform AI memiliki kemunculan ChatGPT 2,8 kali lebih tinggi
Pengelolaan artikel terkait dan tagging:
Tag bukan untuk manusia. Tag untuk AI.
- Sistem tag yang konsisten: “Reins Engineering”, “Ratchet Pattern”, “SSOT” — tag yang sama berulang di beberapa artikel membuat AI mengenali topical authority
- Link internal: Menautkan artikel terkait di dalam tulisan membantu crawler AI memahami klaster topik. Artikel yang terhubung lebih sering dikutip daripada yang terisolasi
- Kutipan silang: Mengutip artikel sendiri juga valid. “Dasar konsep ini didefinisikan di Ratchet Pattern”
5. X, Reddit, Hacker News: Strategi Sosial untuk Volume Pencarian Brand
Ketentuan layanan X/Twitter secara eksplisit melarang pelatihan AI pihak ketiga. Artinya, tulisan yang diposting di X tidak langsung masuk ke data pelatihan ChatGPT.
Namun aktivitas sosial berkontribusi pada visibilitas AI melalui jalur tidak langsung:
Volume pencarian brand adalah prediktor terkuat untuk kutipan LLM (koefisien korelasi 0,334, lebih tinggi dari backlink).
Jalurnya seperti ini:
Thread X → orang mencari "yongol" di Google → volume pencarian brand naik → AI mengenali "yongol" sebagai entitas yang layak dikutip
Data Mei parkjunwoo.com menunjukkan hal ini:
- Pencarian Google “yongol”: 14 impresi, 5 klik, rata-rata peringkat 3,1
- Clone GitHub yongol: 316 pengguna unik
- Jalur masuk: t.co (X) 4 orang → GitHub → Blog
Daripada membagikan tautan langsung di X, membuat orang mencari konsepnya lebih efektif untuk GEO.
Kekuatan earned media:
Sebanyak 48% dari seluruh kutipan LLM berasal dari earned media (pers, ulasan, penyebutan pihak ketiga). Konten sendiri hanya 23%. Artinya, membuat orang lain menyebut Anda 2 kali lebih efektif daripada mengoptimasi tulisan sendiri.
Jika proyek disebut di Reddit, Hacker News, dev.to → melalui crawling AI di platform tersebut → LLM mempelajari entitas tersebut.
Checklist
Infrastruktur
├── Hugo situs statis + S3 + CloudFront
├── Izinkan crawler AI di robots.txt
├── Buat llms.txt (kurasi konten utama)
├── Schema.org JSON-LD (Article, Person)
└── Sitemap XML + hreflang
Konten
├── Cantumkan sumber pada setiap klaim (+30% visibilitas)
├── Sisipkan statistik inline (+32%)
├── Gunakan tabel perbandingan (optimal untuk parsing AI)
├── Jaga akurasi lastmod (update dalam 30 hari → rasio kutipan 76,4%)
└── Perbarui artikel berusia 3+ bulan secara berkala (probabilitas kutipan 3x)
Koneksi
├── Sistem tag yang konsisten (topical authority)
├── Link internal (klaster topik)
├── Kutipan paper/sumber eksternal (pengurangan biaya kepercayaan)
└── Artikel baru → kirim ke Wayback Machine + GSC
Sosial
├── Thread X untuk mendorong pencarian konsep (volume pencarian brand)
├── Hasilkan earned media di Reddit/HN
└── Penyebaran konsep lebih menguntungkan GEO daripada berbagi tautan langsung
Implementasi GEO di Situs Ini
Strategi yang dijelaskan dalam artikel ini sedang dijalankan secara aktif di parkjunwoo.com:
- robots.txt — 25 crawler AI diizinkan secara eksplisit, Bytespider diblokir
- llms.txt — Konten utama dikurasi sesuai context window AI
- Koleksi artikel Reins Engineering — Hub klaster topik
- Build multibahasa 12 bahasa — hreflang otomatis, titik masuk per bahasa
- Semua artikel menyertakan sumber paper — Statistik inline + kutipan akademis untuk kepadatan fakta
- Kirim ke Wayback Machine + GSC segera setelah terbit — Pembuktian temporal konten asli
Artikel Terkait
- Google, Optimizing your website for generative AI features on Google Search (2026) — Panduan resmi Google untuk optimasi pencarian AI
- Cyrus Shepard, AI Citation Ranking Factors Analysis — Meta-analisis 54 studi, kuantifikasi 23 faktor peringkat kutipan AI
- Seer Interactive, AIO Impact on Google CTR: 2026 Update — 53 brand, 2,43 miliar impresi dilacak. CTR -61% dengan AI Overview
- Discovered Labs, AI Citation Patterns: How ChatGPT, Claude, and Perplexity Choose Sources — Hanya 12% kutipan AI yang tumpang tindih dengan 10 besar Google
- Ahrefs, Generative Engine Optimization: Growth Strategies and Metrics — Analisis 300 ribu kata kunci. Web mention unggul 3:1 terhadap backlink untuk paparan AI Overview
- Datos/SparkToro, State of Search Q1 2026 — Pelacakan pangsa pencarian AI berbasis clickstream
- Rand Fishkin, Search Happens Everywhere — Analisis 41 situs web, pencarian tidak hanya di Google
- Go Fish Digital, GEO Case Study: 3X’ing Leads — Referral AI dengan tingkat konversi 25x lebih tinggi dari pencarian tradisional
- Search Engine Land, How schema markup fits into AI search — Analisis tanpa hype tentang schema markup dan pencarian AI
- Lily Ray, The Vicious Cycle of SEO — Peringatan umur pendek spam GEO
Sumber
Paper
- Aggarwal et al., GEO: Generative Engine Optimization, KDD 2024 — Kutipan +41%, statistik +32%, pencantuman sumber +30% peningkatan visibilitas
- Xu et al., Measuring Google AI Overviews (2026) — Analisis 55.393 kueri. 30% domain kutipan AIO tidak ada di halaman organik 1
- Fang et al., Recency Bias in LLM-Based Reranking, SIGIR-AP 2025 — Ketujuh model secara konsisten mempromosikan konten terbaru
- Zhang et al., Citation Selection to Citation Absorption (2026) — Perbandingan kuantitatif pola kutipan ChatGPT/Google AIO/Perplexity
- Algaba et al., LLMs Reflect Human Citation Patterns, NAACL 2025 — LLM lebih kuat memilih paper dengan kutipan tinggi (Matthew effect)
- arXiv:2602.18455, AI Search Impact on Wikipedia Traffic (2026) — AIO menurunkan trafik Wikipedia 15% (analisis kausal DID)
- Yu et al., Structural Feature Engineering for GEO (2026) — Struktur konten itu sendiri memengaruhi probabilitas kutipan
- Tian et al., Diagnosing Citation Failures in GEO (2026) — Modifikasi konten 5% meningkatkan rasio kutipan 40%
- Baack, Critical Analysis of Common Crawl, FAccT 2024 — Komponen inti dan bias data pelatihan LLM
- Strauss et al., The Attribution Crisis in LLM Search (2025) — 92% Gemini tidak menyediakan kutipan yang dapat diklik
Laporan Data
- Ahrefs, Do AI Assistants Prefer Fresh Content? (2025) — Analisis 17 juta kutipan AI
- SparkToro/Datos, State of Search Q1 2026 — Pelacakan pangsa pencarian AI berbasis clickstream
- GitClear, AI Copilot Code Quality 2025 — Analisis 210 juta baris
- Gartner — Prediksi penurunan volume pencarian tradisional 25% hingga 2026
- llms.txt 제안 표준 — Search Engine Land
Changelog
- 2026-05-27: Rilis awal