 Image: AI generated
Image: AI generated
אנשים חכמים לא בהכרח יודעים להסביר
כשנותנים ל-Opus 4.8 לשכתב קוד, התוצאה מרשימה. הוא פותר גרפים מורכבים של תלויות במכה אחת, מטפל מראש במקרי קצה ובונה טסטים ללא פרצות. אבל כשמבקשים ממנו להסביר את התוצאה — מתחילות הבעיות. הוא מדבר כמו מומחה שמדווח למומחה. הוא מניח שהצד השני חולק את אותו רקע ידע, משמיט את הסיבות להכרעות מפתח ומנפנף ברמת הפשטה גבוהה מדי.
כששואלים את Opus 4.6 את אותו הדבר, התמונה הפוכה. הוא מעריך היטב מה אני עלול לא לדעת. הוא בוחר דימויים, מחלק לשלבים ומניח הקשר קודם. אבל כשרמת ההיסק עולה, הוא מגמגם בבעיות ש-4.8 פותר בניסיון אחד.
בשורה אחת: Opus 4.8 חכם אבל מדבר בשפה מסובכת, ו-Opus 4.6 מסביר בבהירות אבל ביצועי ההיסק שלו נמוכים יותר.
זה לא פגם. למה זה קורה, ואיך אפשר להפוך את ההבדל הזה ליתרון מבני — זה הנושא של המאמר הזה.
קללת הידע חלה גם על LLM
ב-1989, הפסיכולוגים Camerer, Loewenstein ו-Weber הוכיחו ניסויית: ככל שאדם מחזיק ביותר מידע, כך הוא מתקשה יותר להביא בחשבון שהצד השני לא יודע את המידע הזה. התופעה הזו, המכונה “קללת הידע (Curse of Knowledge)”, אושרה שוב ושוב בחינוך, בכלכלה ובעיצוב חוויית משתמש כהטיה קוגניטיבית.
אוליבר וונדל הולמס אמר: “על הפשטות שמצד זה של המורכבות לא אתן פרוטה. אבל על הפשטות שמצד השני שלה — אשלם בחיי.” הסבר פשוט אינו פשוט בגלל בורות — הוא אפשרי רק אחרי שחוצים את המורכבות. אבל באופן פרדוקסלי, בזמן ששקועים בתוך המורכבות, היכולת לדבר בפשטות יורדת.
מאמר מ-EMNLP 2025 הראה שהתופעה הזו קיימת גם במודלים גדולים של היסק. תוצאה פרדוקסלית: מודלים עם יכולת היסק חזקה יותר דווקא פגיעים יותר לקללת הידע. מודלים שמסיקים בעומק מניחים בשתיקה שהצד השני מסוגל לעקוב אחרי מהלך ההיסק שלהם. בדיוק אותה בעיה שמומחים אנושיים חווים כשהם מסבירים למתחילים.
לכן קיימים בעולם שני סוגי תפקידים: מי שחושב בעומק ומי שמעביר בבהירות. חוקרים ומתקשרי מדע. מפתחים בכירים וטק-לידים. שופטים ועורכי דין. אלה כישורים שונים. היה נחמד אם אדם אחד היה מצטיין בשניהם, אבל בפועל זה נדיר. לכן ארגונים מפרידים תפקידים.
גם עם LLM זה כך. ו-Claude Code מאפשר את ההפרדה הזו בשורת הגדרה אחת.
מודל תקשורת + מודל היסק
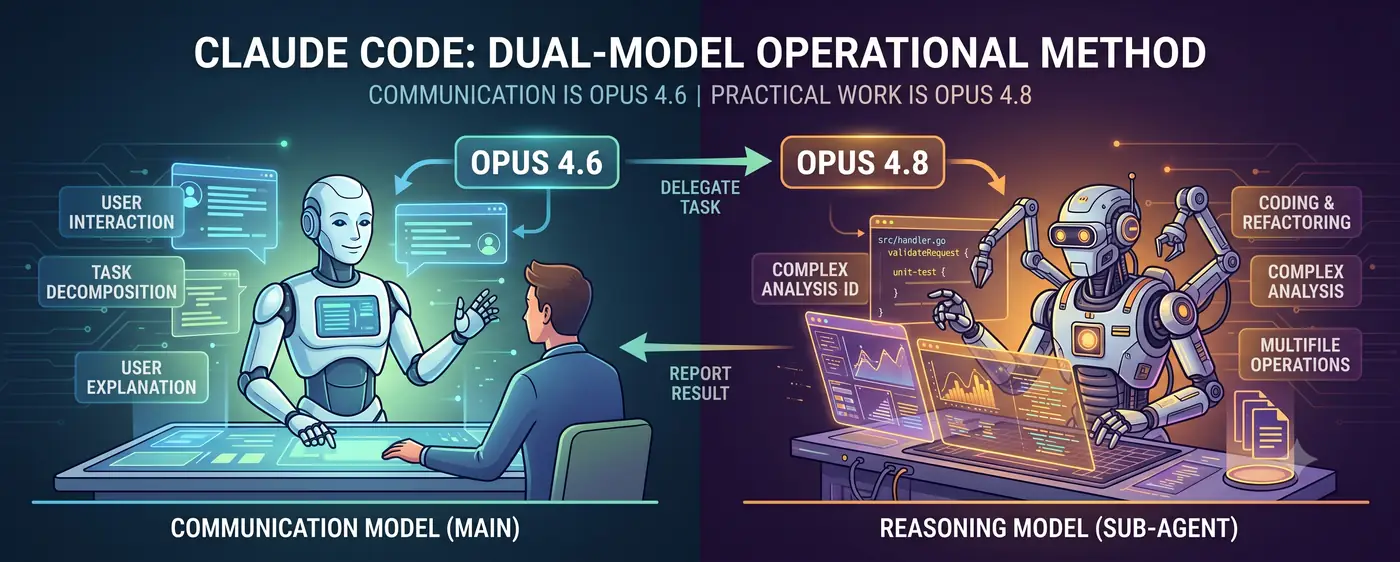
המבנה המרכזי פשוט.
משתמש ↔ מודל תקשורת (ראשי) ↔ מודל היסק (תת-סוכן)
- מודל התקשורת (Opus 4.6) עומד בחזית הדיאלוג. הוא מבין את כוונת המשתמש, מפרק את המשימה ומדווח בשפה שבני אדם מבינים.
- מודל ההיסק (Opus 4.8) מבצע את העבודה. כתיבת קוד, ניתוח מורכב, שכתוב רב-קבצים — משימות היסק ברמה גבוהה מועברות אליו כ-subagent.
המשתמש מדבר עם 4.6. כש-4.6 מעריך שרמת ההיסק גבוהה מדי עבורו, הוא יוצר subagent של 4.8 ומעביר את המשימה. כש-4.8 מחזיר תוצאה, 4.6 מפרש אותה ומסביר למשתמש.
המאמר הזה עצמו הוא ההוכחה. מי שכותב עכשיו הוא Opus 4.6 (ראשי), ואילו חיפוש המאמרים האקדמיים וניתוח נתוני ה-benchmark שביסוד המאמר בוצעו על ידי Opus 4.8 (subagent).
מה המספרים אומרים
נתוני BenchLM חושפים במספרים את האופי של שני המודלים.
| תחום | Opus 4.6 | Opus 4.8 | עדיפות |
|---|---|---|---|
| כולל | 86 | 93 | 4.8 |
| קוד | 64.4 | 76.4 | 4.8 |
| משימות סוכן | 72.6 | 80.1 | 4.8 |
| משימות ידע | 76.2 | 70.1 | 4.6 |
| כתיבה יצירתית | עדיפות | - | 4.6 |
בקוד ובמשימות סוכן 4.8 שולט. אבל בהעברת ידע ובכתיבה יצירתית 4.6 מוביל. גם בסקירות של Claude API חוזרת ההערכה שהכתיבה של 4.8 “נשמעת יותר AI-ית (more AI-sounding)” מזו של 4.6. 4.8 מסיק בדיוק, אבל היכולת לפרוש את ההיסק בצורה קריאה לבני אדם — ב-4.6 טובה יותר.
המחיר של שני המודלים זהה — מיליון טוקנים קלט $5, מיליון טוקנים פלט $25. חלוקת תפקידים לא מגדילה עלות. זו לא אופטימיזציית עלות אלא אופטימיזציית איכות טהורה.
ניתוב מודלים הוא הנדסה מוכחת
הרעיון של “להשתמש בשני מודלים” אינו חדש. באקדמיה זהו תחום מבוסס.
RouteLLM (ICLR 2025) ביצע ניתוב דינמי של שאילתות בין מודל חזק למודל חלש, חתך עלויות פי שניים ושמר על איכות. FrugalGPT (2023) השיג ביצועים ברמת GPT-4 בעזרת מפל LLM עם חיסכון של 98% בעלויות. המסקנה המשותפת של מחקרים אלה ברורה: מודל חלש עם תזמור מעולה מנצח לעתים קרובות מודל חזק עם תזמור גרוע.
גם Anthropic עצמה משתמשת בתבנית הזו. מימוש ה-deep-research של Anthropic מבוסס על תבנית orchestrator-worker, ומערכת מולטי-סוכנים עלתה על Opus 4 יחיד ב-90.2%. סקר מצא שכ-80% ממערכות ה-multi-agent בפרודקשן בנויות במבנה orchestrator-worker.
מה שאני עושה הוא הצורה הפשוטה ביותר של התבנית הזו. לא ראוטר, לא מפל, לא אופטימיזציית עלות. רק מודל שמותאם לתקשורת עומד בחזית, ומודל שמותאם להיסק עובד מאחור. עקרון הפרדת התפקידים עצמו.
איך מגדירים
יצירת המבנה הזה ב-Claude Code פשוטה.
שלב 1: הגדרת המודל הראשי
מריצים את Claude Code עם Opus 4.6. מגדירים בהגדרות את מודל ברירת המחדל ל-claude-opus-4-6-20250610, או בוחרים את המודל בעת ההפעלה. זהו מודל התקשורת שמדבר עם המשתמש.
שלב 2: דריסת מודל ב-subagent
כלי ה-Agent של Claude Code תומך בפרמטר model. בעת יצירת subagent, דורסים את המודל ל-opus (Opus 4.8).
Agent({
description: "שכתוב קוד",
model: "opus",
prompt: "src/handler.go validateRequest function..."
})
זה הכל. הסוכן הראשי (4.6) מדבר עם המשתמש, ומשימות ברמת היסק גבוהה מועברות ל-subagent (4.8).
שלב 3: ההבדל בין fork ל-fresh agent
ב-Claude Code יש שני סוגי subagent.
- fork (
subagent_type: "fork"): יורש את ההקשר של השיחה הנוכחית כמות שהוא. חולק את מטמון הפרומפט, כך שעלות הקלט יורדת עד 90%. אבל fork כופה ירושה של מודל האב — דריסת מודל לא חלה עליו. - fresh agent: מתחיל בהקשר חדש. דריסת מודל אפשרית. צריך לכלול בפרומפט את כל הרקע הנדרש.
לכן, כדי להשתמש במודל ההיסק (4.8), צריך ליצור fresh agent. fork משמש כשצריך חיפוש מקבילי תוך שמירה על מודל התקשורת (4.6).
תבניות מעשיות
| מצב | שיטה | סיבה |
|---|---|---|
| כתיבת קוד מורכב | fresh agent + model: opus | רמת היסק גבוהה |
| שכתוב רב-קבצים | fresh agent + model: opus + isolation: worktree | היסק + בידוד |
| חקירה/סקירה מקבילית | fork (נשאר 4.6) | שיתוף הקשר משתלם |
| קריאה/עריכת קובץ פשוטה | הראשי (4.6) ישירות | תקורת העברה גדולה מדי |
| חיפוש ברשת/מחקר | fresh agent + model: opus | היסק מדויק נדרש |
עד 4-8 worktree בו-זמנית המערכת יציבה. מעבר לכך — סקירת התוצאות הופכת לצוואר בקבוק.
חיכוכים ידועים
המבנה לא מושלם. שני מגבלות ידועות כיום.
ראשית, בעיית דליפת דריסת מודל. הגדרת ה-model של subagent עלולה להתפשט לתתי-סוכנים שהוא עצמו יוצר. שימוש לא מכוון במודל עלול להתרחש, לכן הגבלת עומק ה-subagent לרמה אחת היא הגישה המעשית.
שנית, היעדר הגדרת מודל לפי סוכן. כיום Claude Code אינו תומך רשמית בהגדרת מודל מראש לכל סוג סוכן בהגדרות הפרויקט. יש לציין את פרמטר ה-model בכל קריאת Agent. גם בקהילה הבקשה לתכונה זו פעילה.
שתי המגבלות ייעלמו עם התפתחות Claude Code. גם במצב הנוכחי, דריסה ידנית בלבד מספיקה כדי ליהנות מיתרונות המבנה.
מתקשר והוגה הם תפקידים שונים
בבית המשפט, שופט ועורך דין עוסקים באותו חוק אבל ממלאים תפקידים שונים. השופט מכריע. עורך הדין מסביר ללקוח מה המשמעות של ההכרעה. אם השופט יקריא את פסק הדין ישירות ללקוח — הלקוח לא יבין. אם עורך הדין ינסה לפסוק — הנימוקים יהיו רדודים. הפרדת תפקידים היא לא חולשה של המערכת אלא חוזקה.
גם בסקירת קוד כך. היכולת של מפתח בכיר לאתר באג והיכולת להסביר את הבאג למפתח מתחיל הן שונות. נדיר שמהנדס מעולה הוא גם כותב טכני מעולה. ארגונים יודעים את זה ולכן מפרידים תפקידים.
גם עם AI כך. יכולת היסק ויכולת תקשורת הם צירים שונים. ובתהליך האימון הנוכחי של מודלים, שני הצירים נוטים להתנגש. מיקסום ביצועי היסק הופך את הפלט לדחוס ומקצועי, מיקסום ביצועי תקשורת מרדד את עומק ההיסק.
לדרוש ממודל יחיד להצטיין בשניהם — זה כמו לדרוש משופט למלא גם את תפקיד עורך הדין. אפשרי. אבל לא אופטימלי בשני המימדים.
הפרדת מודל תקשורת ומודל היסק היא עיקרון מבני שתקף גם כשהגרסאות מתחלפות. 4.6 ו-4.8 הם הבחירה הספציפית של היום. כשמחר יצאו 5.0 ו-5.2, אפשר לפרוס מחדש לפי אותו עיקרון. מודלים מתחלפים, אבל העובדה ש"מי שחושב בעומק" ו"מי שמעביר בבהירות" הם תפקידים שונים — לא מתחלפת.
מאמרים קשורים
לקריאה נוספת (חיצוני)
- RouteLLM: Learning to Route LLMs with Preference Data — מסגרת לניתוב דינמי בין מודל חזק למודל חלש לפי רמת קושי השאילתה.
- Anthropic: How we built our multi-agent research system — איך Anthropic מימשה deep-research בתבנית orchestrator-worker.
מקורות
- Camerer, C., Loewenstein, G. & Weber, M. (1989). The Curse of Knowledge in Economic Settings: An Experimental Analysis. Journal of Political Economy, 97(5), 1232-1254. DOI — הוכחה ניסויית של קללת הידע.
- Li, W. et al. (2025). Curse of Knowledge: Your Guidance and Provided Knowledge are biasing LLM Judges in Complex Evaluation. Findings of EMNLP 2025. arXiv — הממצא שמודלי היסק חזקים פגיעים יותר לקללת הידע.
- Ong, I. et al. (2025). RouteLLM: Learning to Route LLMs with Preference Data. ICLR 2025. arXiv — מסגרת ללימוד ניתוב LLM מנתוני העדפה.