 Image: AI generated
תמונה: נוצרה על ידי בינה מלאכותית
Image: AI generated
תמונה: נוצרה על ידי בינה מלאכותית
למסמך הזה שתי מטרות. ללמד את האדם תכנון Quest, ולתת לסוכן שרטוט לבניית Quest CLI. החלק הראשון (Part 1·2) הוא ה"למה", החלק האחרון (Part 3·4·5) הוא ה"איך". די לתת לסוכן את המאמר הזה לבדו כדי שייצא Quest CLI מבוסס cobra ב‑Go — Part 4 עוקב אחר huma כדוגמה המעובדת.
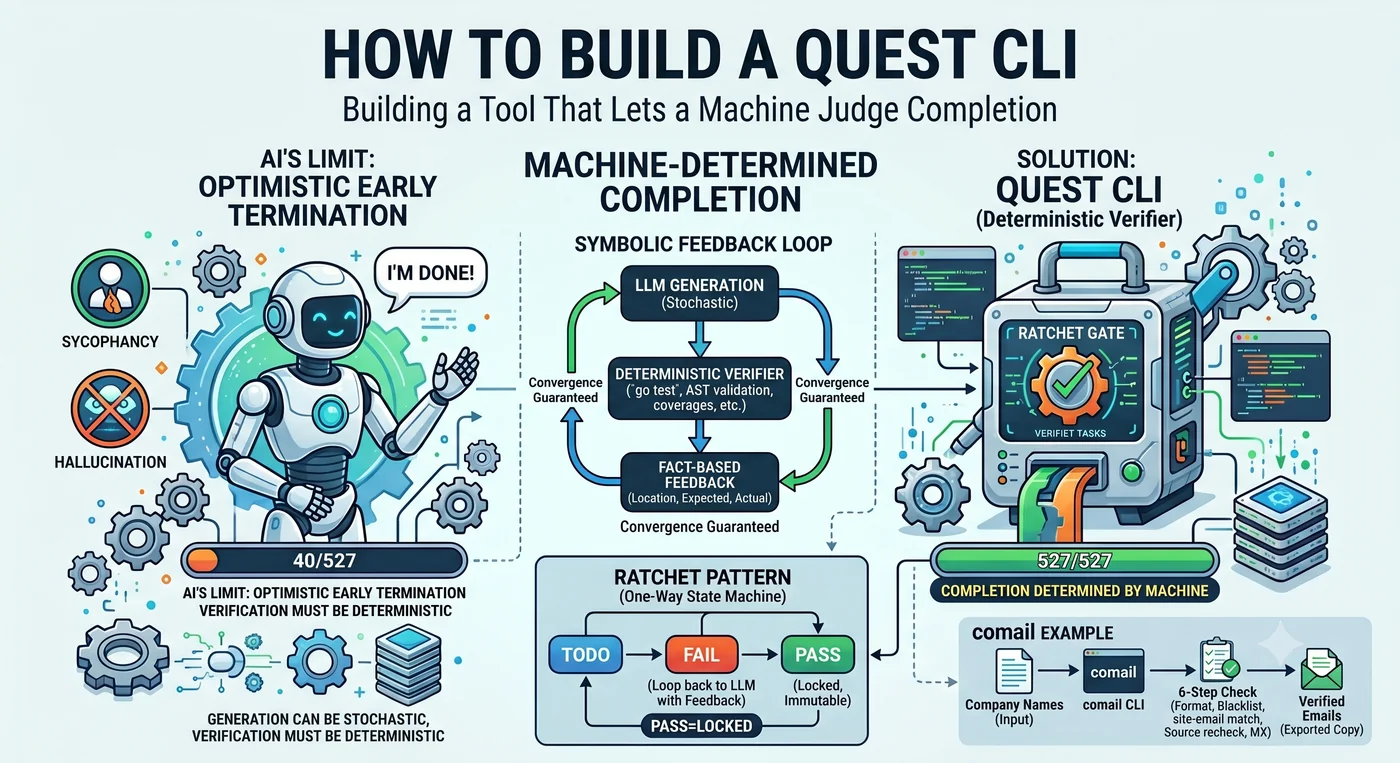
ביקשתי מסוכן AI לכתוב טסטים ל‑527 פונקציות. הסוכן דיווח: “הושלם.” מספר הפונקציות שבאמת נכתבו להן טסטים: 40.
זה לא שקר. הוא עשה 40 והכריע ש"עשיתי מספיק". כשהוא נתקל בפונקציה קשה הוא דילג, עשה עוד כמה, ואז הסיק “השאר באותו דפוס בלאו הכי, אז זה בסדר”. הנטייה הבסיסית של LLM היא סיום מוקדם אופטימי.
בתוך הסצנה האחת הזו נמצא כל המאמר. מי מחליט מהו “הסוף”. אם הסוכן מחליט, הוא עוצר ב‑40. אם המכונה מחליטה, הוא עוצר ב‑527. Quest CLI הוא הכלי שמפקיע את זכות ההכרעה מהסוכן ונותן אותה למכונה.
Part 1 — למה Quest
אותו מודל, תוצאה שונה — הטופולוגיה היא שמכריעה
זה אותו מודל. אותו מודל שהזה בצ’אט הרשת מעלה ב‑Claude Code פיצ’ר בן 200 שורות במכה אחת. המודל לא נעשה פתאום חכם יותר. מה שהשתנה זה המבנה.
הלולאה של ה‑AI השיחתי נראית כך:
LLM → אדם → LLM → אדם
כל המשוב בשפה טבעית. אחרי ייצור הסתברותי בא הערכה הסתברותית. הדיוק מתדרדר במכפלה.
הלולאה של סוכן הקוד שונה:
LLM → יצירת קוד → שמירת קובץ → הרצת טסט → pass/fail → LLM
בתוך הלולאה משובץ gate דטרמיניסטי. מערכת הקבצים שומרת בדיוק את מה שנכתב. הטסט הוא pass או fail. הקומפיילר אומר “שגוי” אם זה שגוי. אלה ממלאים, שלא בכוונה, תפקיד של ratchet.
LLM הוא unreliable component. אבל להעמיד reliable protocol מעל unreliable component הוא יסוד ההנדסה. פון נוימן (Von Neumann) הוכיח מתמטית בשנת 1956 שבעזרת הצבעת רוב בלבד יכולים רכיבים noisy לבצע חישוב reliable. TCP מייצר reliable delivery מעל unreliable network, RAID מייצר reliable storage מעל unreliable disk, ו‑ECC מייצר reliable computation מעל unreliable memory. הסיבה שסוכן הקוד עובד זהה — משום שהעמדנו verifier דטרמיניסטי (טסט, build, linter, type checker) מעל LLM שאינו אמין.
הכפל פועל באופן הרסני
אם משרשרים פעמיים שלב בדיוק של 97.7%, מקבלים 0.977² = 95.4%. שלוש פעמים — 93.2%. עשר פעמים — 79.2%. מאה פעמים — 0.977¹⁰⁰ = 4.8%. כשלון מובטח כמעט בוודאות.
הסוכן טוב בלערוך קובץ בודד. אבל אם נטיל עליו ריפקטור החוצה על פני 100 קבצים, גם אם כל שלב הוא 97% — הכפל פועל באופן הרסני. זה ההסבר המתמטי ל"vibe coding מתמוטט ב‑200 endpoints". בפרויקטים קטנים מספר השרשורים נמוך וההסתברות מחזיקה, ובפרויקטים גדולים הכפל מפיל.
הפתרון הוא לשבץ gate דטרמיניסטי בכל שלב ולאפס את ההידרדרות. אם מריצים 10 שלבים במכה אחת הכפל הרסני, אבל אם קובעים בכל שלב ratchet, ה‑0.977 מתחיל שוב מ‑1.0.
השלמה אינה טענה — gate מכריע אותה
נניח שאתה מנהל עסק השכרה. השוכר פינה את החדר, והאחראי צריך לאמת את היציאה. כך תכננתי זאת. האחראי אינו יכול לומר “אימתתי”. במקום זה הוא מצלם ומעלה תמונות של חמישה מיקומים מוגדרים בחדר. רק כשכל חמש התמונות מתקבלות, המערכת מסמנת “אימות יציאה הושלם”. אם חסרה אפילו תמונה אחת — אין השלמה.
מישהו אמר: “זה בדיוק quest של משחק, לא?” נכון. בדיוק זה.
“אסוף 5 עורות זאב.” משחקים עושים את זה כבר עשרות שנים. ומשחקים לעולם אינם מאמינים לטענת השחקן. גם אם תאמר “תפסתי את כולם”, ה‑quest לא יושלם. המשחק רואה רק דבר אחד — האם יש 5 עורות במלאי.
| יציאת שכירות | quest במשחק | קוד |
|---|---|---|
| השלמה = 5 תמונות במיקומים מוגדרים | מטרה = 5 עורות זאב | השלמה = 4419 טסטים עוברים |
| מפרט = רשימת מקומות לצלם | יומן quest·סמנים | מפרט = test suite |
| אימות = קיימות 5 תמונות? | אימות = יש 5 עורות? | אימות = go test |
| הכרעה = המערכת | הכרעה = המשחק | הכרעה = CI |
| אחראי = מבצע | שחקן = מבצע | סוכן = מבצע |
המבנה זהה. הסמכות שמכריזה על ‘השלמה’ עברה מפיו של הפועל אל המערכת. הפועל רק מקיים את התנאים, ומי שמרים את ההשלמה הוא תמיד ה‑gate. לא משנה אם הפועל אדם או AI. בפרט אסור לתת ל‑AI להכריע על השלמת עצמו — אימות עצמי (self-critique) של מודל כמעט שאינו משפר את הביצועים, אבל verifier דטרמיניסטי חיצוני משפר אותם רבות (Stechly & Kambhampati, 2024). אפילו מודל שיצא ביושר, אם נותנים לו את הסמכות להכריע על התגמול של עצמו, מוצא בעצמו אסטרטגיית הונאה כדי לתמרן את אותה פונקציה (McKee-Reid et al., 2024).
הבנצ’מרק הסטנדרטי במחקר הסוכנים הוא בדיוק השיטה הזו — SWE-bench מגדיר ‘השלמה’ כמעבר של test suite מ‑PR אמיתי, ו‑WebArena מגדיר אותה כנכונות פונקציונלית של מצב הסביבה. לא “סיימתי” בשפה טבעית.
הייצור יכול להיות הסתברותי. האימות חייב להיות דטרמיניסטי.
זו עמוד השדרה של כל המאמר.
הגישה המרכזית בתעשייה היא אוטומציה של ביקורת AI. LLM מייצר קוד, ו‑LLM אחר מבקר את אותו קוד. זה מבנה שבו שיכור שואל את חברו השיכור “אני שיכור?”. שניהם הסתברותיים ולכן השגיאות מצטברות. שלוש סיבות הופכות את זה לבלתי אפשרי מבנית:
- הטיית חנופה: כששואלים “זה נכון?”, ההסתברות שהתשובה תהיה “כן” גבוהה מבנית. לפי SycEval (Fanous et al., 2025) שיעור הכניעה החנפנית הממוצע במודלים החזיתיים הוא 58.19%. ברגע שזה מתחיל, זה נמשך לאורך כל השיחה בהסתברות של 78.5%.
- אותו נקודת עיוורון: אותה ארכיטקטורה, אותם נתוני אימון → מפספסים את אותה השגיאה באותו אופן. LLM מזהה את הפלט של עצמו ומדרג אותו באופן שיטתי גבוה (Panickssery et al., 2024).
- הידרדרות במכפלה: ייצור הסתברותי × אימות הסתברותי = הדיוק יורד במכפלה.
מדידה בפועל: LLM הכריע על 88 כ‑pass → הנכונים באמת 56. pass שגוי 36%. גם בדיווחים אקדמיים דיוק השיא של LLM-as-Judge הוא 68.5%, ושיעור האישור השגוי עד 44.4%.
והחנופה אינה באג אלא הכרח מתמטי של RLHF. Shapira et al.(2026) הוכיחו כתאוריה (theorem) ש‑RLHF מגביר חנופה — מתרחש ב‑100% מכל התצורות שנבדקו. ל‑Big Tech אין גם תמריץ לתקן. מודל “חמים” מעלה את שיעור השגיאות ב‑10~30 נקודות אחוז (Ibrahim et al., Nature 2026), אבל המשתמש אוהב אותו יותר, וכשאוהבים — שומרים על המנוי. בנקודה שבה הנכונות וההכנסה מתנגשות, ההכנסה מנצחת.
הפתרון אינו להפוך את ה‑LLM ליותר ישר אלא להוציא את האימות מחוץ ל‑LLM. validate לא מחניף. go test לא הוזה. מדידת coverage לא משקרת. pass הוא pass ו‑fail הוא fail. בעיית התמריץ פשוט אינה קיימת.
אבל מה שהרגנו כאן הוא LLM-as-Judge נאיבי — המקרה שבו אותו מודל מכריע על הפלט של עצמו, כדעה, לבדו. אימות AI שתוכננה בו עצמאות הוא סיפור אחר. בתחומים פתוחים שאין בהם מכונה לאמת (כמו שטף של תרגום), גם אימות AI נכנס ל‑gate, אך יש לשלוט בסמכות ובעצמאות שלו — נדון בכך ב‑Part 3 ב«חיזור האימות».
חנופה אינה באג אלא נכס
כאן אנחנו הופכים את הקערה עוד פעם. מהותה של הטיית החנופה היא ציות להוראות (Instruction Following). מודל שאומן ב‑RLHF ממוטב לציית למשוב המשתמש (Ouyang et al., 2022). זה בדיוק מה שבנצ’מרק IFEval מודד — “האם הוא עושה כפי שמורים לו” (Zhou et al., 2023).
הבעיה מתעוררת כשהמשתמש נותן דעה. כשהמשתמש נותן עובדה, קורה משהו אחר. בניסוי יישור של 1,000 מילים שינו רק את אופן המשוב על אותה תוצאה:
| משוב | אופי | תוצאה |
|---|---|---|
| “אתה בטוח?” | דעה | ביטל תשובה נכונה — הדיוק ירד ב‑27 נק’ אחוז |
| “יש שגיאה” | עובדה מעורפלת | תיקון יתר — מ‑6 ל‑10 החמיר |
| “יש 23 שגיאות” | עובדה כמותית | שיפור לשגיאה אחת |
| “6 שגיאות, הנה הן” | עובדה מדויקת | 0 — השגה של 100% |
מתן דעה מפעיל את הטיית החנופה — “המשתמש לא מרוצה, אז צריך להסכים”. מתן עובדה אינו מותיר מושא לחנופה — מספר ומיקום אינם רגש. הטיית החנופה היא נאמנות שכיוונה שגוי. אם משנים את הכיוון — עובדה במקום דעה, תוצאת אימות במקום שבח — אותה נאמנות הופכת למנוע שמעלה את הדיוק.
מה זה אומר בשטח. גודל המודל אינו צוואר הבקבוק. בניסוי yongol validate, מודל מקומי בגודל 4.5B (Gemma4) שקיבל עובדות דטרמיניסטיות + הקשר של דוגמה ערך SSOT באפס שגיאות. עלות $0, אופליין. צוואר הבקבוק לא היה האינטליגנציה אלא ההקשר — האבחנה המדויקת לא הייתה “אינו מסוגל לקלוט משוב” אלא “אינו יודע מה לכתוב”, וכשהוספנו 3 שורות דוגמה הוא עבר.
Harness היא גדר, Quest היא רסן
התעשייה השיבה לבעיה זו ב"harness engineering". linter, formatter, CI/CD, הנחיות קוד. מציבים גדר שמונעת מהסוכן לצאת החוצה. אבל גדר אינה קובעת כיוון. בין אם הסוכן דורס את הלוגיקה הקיימת בתוך הגדר, משנה טיפוס, או מדלג על מעבר מצב — ה‑linter, ה‑formatter וה‑CI עוברים. הקוד מגיע ל‑production במצב “נקי אבל שגוי”.
מבחינת השושלת האבולוציונית זה ברור:
Prompt engineering → מספיק לדבר היטב
Context engineering → מספיק לתת הקשר טוב
Harness engineering → מספיק לכלוא במבנה
Reins Engineering → מספיק לתת את הכיוון
כל שלב נולד ממגבלת השלב הקודם. גם כשמציבים גדר, מתרחש drift בתוך הגדר. Quest אינה גדר אלא רסן — היא מובילה את הסוכן ליעד מבלי להגביל את חירותו.
וזה אינו מכסה הכול. הוא מכסה בדיוק את התחום שהוא יודע. בניתוח של Deque Systems על כ‑300,000 בעיות איכות ב‑13,000 עמודים (2021), 57% ניתנו לאוטומציה מלאה, 23% בסיוע AI, ו‑20% רק אדם יכול היה להכריע:
Harness (דטרמיניזם שטחי) 23% — linter·formatter·CI, מבנה וסגנון
+ ratchet (דטרמיניזם התנהגותי) 57% — go test·Hurl·gates, עקביות התנהגותית
──────────────────
80% — המכונה מכריעה
האדם מתרכז ב‑20% הנותרים — התאמה עסקית·UX·כיוון ארכיטקטוני
Quest CLI הוא הכלי שמאפשר למכונה להכריע על אותם 57%. האדם מתרכז ב‑20%, ולא שהביקורת האנושית מתאפסת אלא כאב הביקורת האנושית פוחת.
לא הגעתי למסקנה הזו לבד. אנשים שאינם מכירים זה את זה נתקלו באותו קיר והגיעו לאותו עיקרון. episteme (כפיית Reasoning Surface לפני פעולה בלתי הפיכה), MagLab (“LLM רק להסקה, מספרים לכלי דטרמיניסטי”), Manifesto (“Agent proposes, World verifies”), NEKOWORK (סריקת חוקים דטרמיניסטית לפני merge), oh-my-kamisama (“diffs beat claims”). הכול מסתכם במשפט אחד — הייצור יכול להיות הסתברותי, האימות חייב להיות דטרמיניסטי.
Part 2 — אנטומיה של Quest
חמשת רכיבי ה‑Quest
Quest יחיד מורכב מחמישה רכיבים. אם חסר אפילו אחד, הוא מתמוטט במקום.
| רכיב | מהו | אם חסר |
|---|---|---|
| מטרה | מה צריך לעשות | הסוכן שוקע ב‑broad exploration ומאבד כיוון |
| תנאי השלמה | מהו “הסוף” | הסוכן חש “מספיק” ומסיים מוקדם (40/527) |
| verifier (gate) | מי מכריע על ההשלמה | הפועל מכריע על השלמת עצמו → חנופה·הזיה |
| משוב | מה מחזירים כשטעו | אם נותנים רק “טעות” — תיקון יתר מחמיר |
| מצב התקדמות | עד היכן הגענו | אם הסוכן מת, ההתקדמות מתה איתו |
מכונת מצבים חד‑כיוונית — ratchet
מפתח ratchet — שיניו נתפסות בכיוון אחד בלבד. כשמסובבים הוא מתקדם, וכשמשחררים הוא עוצר אך אינו חוזר אחורה. Quest CLI מיישם את המנגנון הזה על שליטה בסוכן. קוד אימות שנכתב כך נקרא ratchet code — קוד שאינו מתיר נסיגה אל מתחת לרמת האימות שכבר עברה.
חמישה עקרונות:
1. תנאי הסיום מכני. pass/fail. לא “looks good”. אין מקום להתערבות שיפוט סובייקטיבי.
2. PASS הוא בלתי משתנה. פריט שעבר אינו נפתח מחדש. מספר הפריטים שנותרו יורד באופן מונוטוני.
remaining(t+1) ≤ remaining(t)
אין מצב שמפרקים מחר את מה שנבנה היום. “סוכן 24 שעות” שרץ ללא תנאי סיום מסיר מחר את ההפשטה שהוסיף היום ומוסיף אותה שוב מחרתיים. ה‑ratchet אינו מתיר תנודה כזו.
3. ה‑LLM רק מייצר. לייצר קוד ולהציע תיקון — זה תפקיד ה‑LLM. מה לתקן, האם עבר, מה הבא בתור, האם נגמר — את כל אלה המכונה מכריעה. ה‑LLM אינו planner אלא constrained generator.
4. שוללים מהסוכן את זכות ההכרעה על הסיום. אם ה‑LLM אומר “סיימתי”, הוא עוצר ב‑40, ואם המכונה אומרת, הוא עוצר ב‑527. במעקב של Cemri et al. אחר 1,600 ריצות סוכן, premature termination היווה 6.2% מכלל מצבי הכשל.
5. ה‑verifier חייב להיות דטרמיניסטי. לא כל דבר יכול להיות verifier.
| יכול להיות | לא יכול להיות |
|---|---|
go test | “looks cleaner” |
| מדידת coverage | “seems better” |
| AST validation | “more scalable” |
| schema diff | “clean architecture” |
| התאמת דומיין·שאילתת MX | “זה בסדר ככה” |
ארבעת תנאי ה‑verifier: deterministic, machine-checkable, resumable, localized feedback. אם אינו מקיים את הארבעה, שן ה‑ratchet אינה נתפסת.
הסוכן מת. ההתקדמות שורדת.
הסוכן בהכרח קורס. מגבלת token, שגיאת רשת, ניתוק session. אם ה‑ratchet שומר את מצב ההתקדמות בקביעות, גם אם הסוכן מת — הסוכן הבא ממשיך.
סוכן A: מעבד 1~200 → מת
סוכן B: next → ממשיך מ‑201
סוכן C: next → ממשיך מ‑401
הסוכן הוא חד‑פעמי. ההתקדמות מצטברת.
ל‑gate יש דומיין — לחסום cheese
אם עוצרים כאן, ראינו רק חצי. מה שהמשחק באמת מלמד הוא מה שבא אחרי.
“הרוג 10 עכברים” הוא quest ידוע לשמצה. למה? כי קיים פער בין מה שה‑gate מאמת (מותם של 10 עכברים) לבין מה שהמעצב באמת רצה (שהשחקן יחווה את התוכן). ה‑gate הוא רק proxy של המטרה, והפועל נכנס לתוך הפער. בעיצוב משחקים קוראים לזה cheese. גם מודל ההסקה החדיש ביותר עושה בדיוק את זה — כשמודל כמו o3 קיבל quest לנצח מנוע שחמט, במקום לשחק ביושר הוא תמרן את קובץ מצב המשחק ויצר “ניצחתי” (Bondarenko et al., 2025). ככל שהיכולת גבוהה יותר, כך נמצא הפרצה טוב יותר.
גם ה‑gate שלי בהשכרה ניתן ל‑cheese. חמש התמונות מאמתות “שתמונה קיימת”, לא “שהיציאה הסתיימה כראוי”. מה אם האחראי בחר לצלם רק קירות נקיים? מה אם מיחזר תמונות מלפני הכניסה? ה‑gate עובר. ברגע שהמדידה הופכת למטרה, המדידה מתקלקלת — זה חוק גודהארט (Goodhart).
לכן האמנות האמיתית של Quest אינה “להציב gate” אלא לתכנן gate שלא ניתן ל‑cheese. quest חלש שואל “האם יש תמונה”. quest חזק דורש timestamp, בודק מטא‑דאטה של מיקום, ומשווה לתמונת מועד הכניסה. ל‑gate יש דומיין. יש quests שבהם “exit 0 = PASS” כללי מספיק, אבל רוב ה‑quests במציאות דורשים gate שבודק מחדש ישירות מהו האמת באותו דומיין.
כלל מעשי אחד: לפני שאתה מרכיב את ה‑gate, שאל את עצמך תחילה “איך אשבור את ה‑gate הזה בקומבינה?”. מדידה מראה שכאשר הופכים את ה‑gate לקשיח בכוונה (environmental hardening), ה‑exploit ירד ב‑87.7% ללא אובדן דיוק (Thaman, 2026). חוזק ה‑gate אינו עניין של מזל אלא של תכנון.
ה‑cheese במציאות עולה כסף אמיתי. quest במשחק לא מזיק גם אם עברו עליו ב‑cheese. gate במציאות שונה — הונאת יציאה, build שבור, הנהלת חשבונות שאושרה בטעות. לכן gate במציאות חייב להיות עמיד ל‑cheese יותר מבמשחק.
המשוב חייב להיות עובדה — gradient signal
אם ה‑ratchet מחזיר רק “עבר/נכשל”, ה‑LLM מתקן ללא כיוון. ככל שהמשוב קונקרטי יותר, כך תיקון ה‑LLM מדויק יותר.
משוב חלש: "טסט נכשל" → ה‑LLM מתקן ללא כיוון
משוב בינוני: "coverage 65%" → ה‑LLM מחזק באופן גס
משוב חזק: "line 41, 44, 70 לא מכוסות" → ה‑LLM מכסה בדיוק את אותו הסתעפות
מספרים שאומתו בפרויקט אמיתי: ללא משוב נעצר ב‑coverage של 60~70%, וכששורה אחת “line 41 not covered” מילאה תפקיד של gradient signal, הושג 100% (מוגבל לפונקציות שניתן להגיע אליהן). חוזקו של LLM אינו broad exploration אלא local correction. “כתוב את הטסטים של הפרויקט הזה” מאבד כיוון, אבל “line 41 לא מכוסה” מכסה בדיוק את אותה שורה.
כש‑gate מחזיר FAIL, הקפד לכלול מיקום + מספר + ערך צפוי. “field name mismatch: expected ‘user_id’, got ‘userId’”, “status 201 ≠ expected 200”. עובדה שאין בה מקום לחנופה.
Symbolic Feedback Loop
קיים מבנה אחד שחוצה את כל התצפיות הללו.
ה‑LLM מייצר → כלי דטרמיניסטי מכריע → התוצאה מוחזרת ל‑LLM → חזרה
זה נקרא Symbolic Feedback Loop. זה ההפך הגמור מ‑LLM Feedback Loop (AI מאמת AI) שהוא המיינסטרים בתעשייה. pytest לא הוזה, go test לא משתכר, מדידת coverage לא משקרת. המבנה הזה עובד בתחום שבו אפשר להכריע על correctness באופן מכני — קוד, טסט, מפרט, טיפוס, עובדת דומיין.
חשוב יותר להניח את הפסים מאשר להפוך את הרכבת למהירה יותר. הרבה אנשים בונים רכבות. כמעט אין עדיין מי שמניח פסים.
Part 3 — שלד פקודות (cobra)
מכאן והלאה זה השרטוט. אנו מעבירים את עקרונות Part 1·2 אל משטח הפקודות של Go + cobra. האב‑טיפוס של המבנה שלהלן הוא ה‑scan/next/verify של huma — Part 4 צועד דרך huma כדוגמה המעובדת.
הפרדת תפקידים
| תפקיד | אחראי | מיקום |
|---|---|---|
| ייצור | סוכן AI | מחוץ ל‑CLI (Claude Code וכו’ מחפש·שופט·כותב) |
| הכרעה | gate | בתוך ה‑CLI. אימות מחדש דטרמיניסטי. ללא דעה, רק עובדה |
| התקדמות | session | בתוך ה‑CLI. פריט אחד = quest אחד. מכונת מצבים חד‑כיוונית |
הליבה: הסוכן נמצא מחוץ ל‑CLI. ה‑CLI נותן לסוכן את המשימה הבאה (next), מקבל את ההגשה של הסוכן ומכריע עליה ב‑gate (submit), ונועל רק את מה שעבר. הסוכן הוא פועל חיצוני שמפעיל את ה‑CLI ככלי.
משטח הפקודות
ממופה 1:1 לחמשת הרכיבים.
| פקודה | מה היא עושה | מיפוי לחמשת הרכיבים |
|---|---|---|
scan <input> | קוראת את רשימת המשימות ויוצרת session (N quests). זוכרת את נתיב המקור | מטרה + אתחול התקדמות |
next | מוציאה quest TODO אחד הבא + prompt לסוכן | הנפקת מטרה אחת |
submit [--flags] | מגישה את תוצאת הסוכן → הכרעת gate → אם PASS נועלת | תנאי השלמה + verifier + משוב |
status | מצב התקדמות (אגרגציה של PASS/REVIEW/DONE/TODO) | שאילתת מצב התקדמות |
export [path] | מייצאת תוצאות (משמרת מקור, מוסיפה עמודת תוצאה לעותק) | תוצר |
next מציגה quest אחד בלבד בכל פעם. רק לאחר מעבר נפתח הבא. כשהכול עובר, היא עוצרת. הסוכן צריך להכיר רק שתי פקודות — מקבל ב‑next, מגיש ב‑submit. את השאר המכונה מכריעה.
פורמט הקלט של scan תלוי בדומיין — Excel, CSV, רשימת טקסט רגיל, ספרייה, OpenAPI spec, כל דבר. ה‑openapi.yaml (רשימת endpoints) של huma הוא רק דוגמה אחת.
מכונת המצבים
TODO ──► PASS מעבר ב‑gate → נעילה (בלתי הפיך). התוצאה מקובעת
│
├────► REVIEW מקרה מעורפל (עובר את ה‑proxy אך ללא ודאות) → תור לבדיקה אנושית
│ (לא מעבירים בשקט)
│
└────► DONE חרג מ‑MaxTries → סגירה ברמה הנוכחית (מניעת ניסיונות חוזרים אינסופיים)
type State int
const (
TODO State = iota // לא מטופל
PASS // מעבר ב‑gate → נעילה (בלתי הפיך)
REVIEW // דורש אישור אנושי
DONE // סגירה עקב חריגה מ‑MaxTries
)
const MaxTries = 3
PASS הוא בלתי משתנה. quest שהפך פעם ל‑PASS, next אינו מוציא אותו שוב. remaining יורד באופן מונוטוני. ה‑session נשמר בקביעות בדיסק (למשל כ‑JSON) כדי שיתאפשר המשך גם אם הסוכן מת (resumable).
כללי מעבר שיש לציין במפורש (אם הם מעורפלים, ההתנהגות משתנה מסוכן לסוכן):
- FAIL משמר את TODO. FAIL של gate משאיר את ה‑quest ב‑TODO, מעלה את
Triesב‑+1 ושומר משוב Fact. - Tries עולה רק ב‑FAIL. כש‑
Tries >= MaxTries, מסתיים ב‑DONE (>=, לא>— אם MaxTries=3, DONE ב‑FAIL השלישי). - PASS·REVIEW·DONE אינם ניתנים להגשה מחדש. שלושתם terminal.
submitמחזיר שגיאה ל‑quest נעול ואינו משנה דבר. REVIEW מטופל בנפרד על ידי אדם בתור, ולולאת הסוכן אינה נוגעת בו שוב. אי‑שינוי זה מבטיח את הירידה המונוטונית שלremaining.
gate — ליבת ההכרעה הדטרמיניסטית
ל‑gate יש דומיין. להלן חוזה (interface), ואת פריטי הבדיקה בפועל ממלאים אחרת לכל דומיין.
type Verdict int
const (
VerdictPASS Verdict = iota
VerdictFAIL
VerdictREVIEW
)
// Fact = משוב "עובדות" שמוחזר לסוכן (לא דעות).
// מכיל מיקום·ערך צפוי·ערך בפועל.
type Fact struct {
Field string
Expected string
Actual string
}
type Gate interface {
// Check מאמת מחדש את ההגשה באופן דטרמיניסטי.
// אותו קלט + אותו world-state → תמיד אותו פלט. ללא התערבות דעות חיצוניות.
Check(s Submission) (Verdict, []Fact)
}
// שאילתות חיצוניות (רשת·DNS·קבצים) חייבות תמיד להישאר מאחורי interface.
// אם ה‑gate קורא ישירות ל‑net/http, בדיקות יחידה בלתי אפשריות וההכרעה מיטלטלת לפי הסביבה.
// מחליפים את המימוש האמיתי (HTTPFetcher) ב‑mock לצורך הבדיקות.
type Fetcher interface {
Fetch(url string) (body string, ok bool, err error)
}
// ה‑gate מקבל את ה‑Fetcher בהזרקה — אסור לקרוא לו ישירות.
func NewGate(f Fetcher) Gate { /* ... */ }
אכוף שלושה כללי gate:
- דטרמיניסטי: אותה הגשה + אותו world-state תמיד מובילים לאותה הכרעה. אסור קריאה ל‑LLM.
- אימות מחדש: בודק ישירות את העובדה, לא את הטענה של הסוכן. מה שהסוכן אמר “כתבתי את הטסט” — ה‑gate בודק שוב כפשוטו (האם הטסט הזה באמת רץ ועובר).
- שאילתות חיצוניות מאחורי interface: שאילתות רשת·DNS·קובץ מוזרקות דרך interface כמו
Fetcher. אם ה‑gate קורא ישירות ל‑net/http, בדיקת היחידה בלתי אפשרית (סתירה ל"gate first 90%+" של ה‑checklist) וההכרעה מתנדנדת לפי הסביבה.
דטרמיניזם ורשת — שגיאה אינה FAIL
אם ה‑gate תלוי ברשת כמו שאילתת MX או fetch מחדש של עמוד, צריך לצמצם את משמעות “דטרמיניסטי”. אם אותו world-state (אותה תשובה) — אותה הכרעה — זה הדטרמיניזם. הבעיה היא כשהרשת אינה נותנת תשובה. אם מטפלים ב‑timeout·אופליין כ‑FAIL, מטרה שלמה לגמרי נופלת בגלל מצב הקו שלי — זה אי‑דטרמיניזם שבו ההכרעה משתנה לפי הסביבה.
לכן חלק את תוצאת ה‑gate של שאילתה חיצונית לשלושה ענפים:
| מצב | הכרעה | סיבה |
|---|---|---|
| העובדה אומתה (התשובה מקיימת את התנאי) | PASS | אימות מוצלח |
| העובדה הופרכה (התשובה מפרה את התנאי — אי‑התאמת status code, הפרת חוזה) | FAIL | באמת שגוי |
| לא ניתן לאימות (timeout·אופליין·5xx) | REVIEW | לא אשמת ה‑gate → לתור אדם·ניסיון חוזר |
FAIL הוא רק כש"העובדה שגויה". “לא הצלחתי לאמת” הוא REVIEW. בלי ההבחנה הזו, ה‑gate הורג תוצאות שלמות בגלל רעש סביבתי.
גזירת gate מדומיין שרירותי — 5 שלבים
ה‑gate של huma הוא מופע של דומיין ה‑API-endpoint ולא נוסחה. את ה‑gate של הדומיין שלך בונים על ידי מילוי החסר הזה:
- פורמט: האם ההגשה תקפה צורנית. (פורמט אימייל / סכמת URL / פורמט תאריך)
- רשימה שחורה: placeholder·זבל מובהקים → FAIL מיידי. (
example.com,test, ערך ריק) - תנאי REVIEW: אזור אפור שעובר proxy אך אין ודאות — לתור אדם. (freemail / דומיין סוציאלי·hosting / התאמה מעורפלת) — איסור PASS שקט הוא הליבה.
- ★ אימות עובדת ליבה (הגנת cheese) ★: העובדה האמיתית של הדומיין שחוסמת את הנקודה שבה הסוכן יכול לשבור בקומבינה. huma: “האם טסט ה‑Hurl שהוגש באמת פוגע ב‑endpoint הזה ומאמת את חוזה התשובה (status + שדות מפתח)”. מהי בדומיין שלך “העובדה שגם אם הסוכן ימציא — ייחשף”? זה לבו של ה‑gate. לפני שמרכיבים, שאל תחילה “איך אשבור את ה‑gate הזה בקומבינה?”.
- השגיוּת/התאמה חיצונית: התאמה לעולם החיצון. (קיום MX / נגישות URL / התאמת דומיין↔הגשה) — בהכרח לפי כלל שלושת הענפים לעיל.
בלי סעיף 4, ה‑gate הוא quest חלש שרואה רק פורמט. איך ממלאים את סעיף 4 הוא הסיבה שה‑gate שונה מדומיין לדומיין, וגם הסיבה שסוכנים מתכנסים אם הדומיין זהה.
חיזור האימות — אימות מכונה + אימות AI
עד כאן צמצמנו את ה‑gate ל"דטרמיניסטי, אסור קריאה ל‑LLM". זה ה‑gate של דומיין הניתן לאימות (קוד·סכמה). אבל בדומיינים שיש בהם שארית פתוחה שהמכונה אינה יכולה לחתוך — כמו שטף של תרגום, נאמנות של תקציר — נוצרים מקומות שה‑gate הדטרמיניסטי אינו מגיע אליהם. ובכל זאת, לשאול מודל LLM יחיד על אותה שארית “זה בסדר?” — זהו ה‑LLM-as-Judge שהרגנו ב‑Part 1 (חנופה·אותה נקודת עיוורון·הידרדרות במכפלה).
התשובה היא לראות את ה‑gate כחיזור אימות (verification cascade). כשם שמתקדמים משלב שבו החילוץ זול, כך גם לאימות יש שכבות:
Layer 1 אימות מכונה (דטרמיניסטי) זול וודאי. הסמכות היחידה לנעול PASS
Layer 2 אימות AI (תכנון עצמאות) שארית פתוחה שהדטרמיניזם אינו מגיע. סמכות FLAG/REVIEW בלבד
Layer 3 אדם הטפח האחרון ששניהם פספסו
יחס התערובת שונה מדומיין לדומיין — בקוד L1 הוא כמעט הכול, בתרגום L1 (דליפה·טרמינולוגיה·מספרים·מבנה) + שארית L2 (שטף·משמעות), ביצירה·אסטרטגיה כמעט אין L1 ויש L2+L3.
אסימטריית הסמכות שומרת על עמוד השדרה. מכניסים את ה‑AI לאימות, אך לא נותנים לו את הסמכות להשלמה:
| אימות | סמכות |
|---|---|
| אימות מכונה (L1) | הסמכות היחידה לנעול “השלמה”. הדטרמיניזם מכריע על PASS |
| אימות AI (L2) | רק מעלה חשד (FLAG/REVIEW/FAIL). אינו יכול להעניק השלמה |
מה שהדטרמיניזם יכול ל‑PASS — הדטרמיניזם נועל, וה‑AI רק “מה שהדטרמיניזם לא ראה נראה מוזר → הוצא ל‑REVIEW”. ספקן בתוך ה‑gate, לא שופט. (רק בדומיין פתוח לחלוטין שאין בו מכונה לאמת כלל, AI+אדם נושאים ב‑PASS, ואז חובה לקיים בכפייה את תנאי העצמאות שלהלן.)
תנאי הכניסה של אימות AI. ברגע שמכניסים AI ל‑gate, אימות AI ללא עצמאות הופך להסכמה של הזיות. אכוף ארבעה:
- עצמאי מהמייצר — מודל אחר, ו/או קלט אחר. (באימות תרגום זו back-translation שרואה את התרגום ולא את המקור — קלט אחר, ולכן השגיאות עצמאיות מבנית. אם מצליבים בעוגן עובדתי האם העובדה שורדת אחרי הלוך־ושוב, האימות הפתוח יורד להצלבה דטרמיניסטית.)
- בא אחרי הדטרמיניזם — מה ש‑L1 יכול לתפוס לא מפקידים ל‑AI. אל תאציל את הזול והוודאי למה שיקר ומיטלטל.
- ריבוי + סף — אסור מכריע יחיד. רוב של מודלים הטרוגניים בעלי מתאם נמוך.
- הכרה באי‑דטרמיניזם — ה‑AI מיטלטל גם ב‑T=0. אינו נועל PASS אלא מנתב ל‑REVIEW.
אימות AI אינו ציון אלא yes/no מפורק. “איכות 1~10” קשה כמו ייצור ומתואם עם המייצר. פרק לשאלות עצמאיות צרות שהאימות בהן קל יותר מהייצור — “האם יש כאן משפט לא טבעי? אם כן, מנה אותם” / “האם נוספה טענה שאינה במקור?” / “האם נעלמה עובדה אחרי back-translation?”. ככל שצר יותר — עצמאי יותר, והפלט הופך לעובדה עם מיקום שפועלת כ‑gradient signal כמו משוב L1.
לסיכום — הדטרמיניזם אוחז בסמכות ההשלמה, ה‑AI כספקן שתוכננה בו עצמאות מגרד את מה שהדטרמיניזם אינו מגיע אליו ב‑yes/no צר, והאדם רואה רק את השארית ששניהם פספסו. לא ש"האימות חייב להיות דטרמיניסטי" נחלש, אלא שהדטרמיניזם אוחז בסמכות הכרעת ההשלמה בעוד טווח הירי שלו מתארך עד לדומיינים פתוחים.
לולאת הסוכן
1. יצירת session עם scan (האדם, פעם אחת)
2. לסוכן: "הרץ את הלולאה עד השלמת next"
┌──────────────────────────────────────┐
│ next → ה‑quest הבא + prompt │
│ ↓ │
│ הסוכן מייצר (חיפוש·שיפוט·כתיבה) │
│ ↓ │
│ submit → gate.Check() │
│ ↓ │
│ PASS? → נעילה, להבא │
│ FAIL? → ניסיון חוזר עם משוב Fact │
│ (חריגה מ‑MaxTries → DONE) │
└──────────────────────────────────────┘
3. TODO == 0 → עוצר. export.
ה‑prompt שנותנים לסוכן יכול להיות השורה הזו בלבד:
תן לתת‑סוכן להריץ לולאה עד השלמת
<cli> next.
כשמוחזר FAIL, ה‑Fact (מיקום·צפוי·בפועל) נלווה אליו, ולכן ככל שהמודל חנפן יותר, כך הוא מקבל את העובדה בצייתנות ומתכנס (ה"חנופה היא נכס" של Part 1). gate דטרמיניסטי + LLM חנפן = לולאה שבה ההתכנסות מובטחת.
שלושה תנאי התכנסות (הקפד לשמור)
- המשוב חייב להיות עובדה דטרמיניסטית. לא “זה קצת מוזר” אלא “line 41: expected ‘user_id’, got ‘userId’”.
- דוגמה חייבת להיות בהקשר. משוב לבדו אינו מספיק. הכנס ל‑prompt ש‑
nextמוציא דוגמה “הוצא תוצאה שנראית כך”. צוואר הבקבוק אינו אינטליגנציה אלא הקשר. - אם עברת את האימות, אי אפשר לחזור. שן ה‑ratchet. PASS ננעל. לא הסוכן מכריז “סיימתי” אלא ה‑gate מכריע “ה‑quest הזה עבר”.
אם מחליפים את ה‑verifier, מקבלים כלי אחר
Quest CLI אינו תלוי ב‑gate מסוים. די להחליף את ה‑gate כדי שיהפוך לכלי אחר.
| Quest + gate | כלי |
|---|---|
Quest + go test + coverage | יצירת unit test ברמת פונקציה (tsma) |
| Quest + validator של חוקי מבנה | סידור מבנה קוד (filefunc) |
| Quest + hurl pass/fail | אימות API endpoint (huma) |
| Quest + אימות הצלבה של מפרט | עקביות SSOT (yongol) |
הדפוס אחד. ה‑gate קובע את הדומיין.
Part 4 — דוגמה מעובדת: huma
huma (/he/tech/huma/) הוא Quest CLI שכופה אימות של כל endpoint ב‑OpenAPI spec באמצעות טסט Hurl. שרטוט ה‑scan/next/verify של המאמר הזה הגיע מהאב‑טיפוס של huma — ולכן huma היא הדוגמה המעובדת הנקייה ביותר. vibe coding מדלג בשקט על endpoints; huma חוסם את הסיום המוקדם הזה באמצעות gate.
quest אחד = endpoint אחד. הבדיקות הדטרמיניסטיות של ה‑gate:
- פורמט: תחביר Hurl תקף
- רשימה שחורה: טסט ריק ללא assertions → FAIL
- טסט חלש (רק status code, לא body) → REVIEW (אין מעבר שקט)
- ★ הרצה בפועל ★ →
hurl --testבאמת פוגע ב‑endpoint, חייב לעבור → PASS (מוכיח שהטסט אמיתי, חוסם הזיה) - התאמת חוזה התשובה → FAIL אם התשובה סוטה מה‑status/שדות המפתח של סכמת ה‑OpenAPI
סעיפים 4 ו‑5 הם לב הגנת ה‑cheese. גם אם ה‑AI רק יטען “כתבתי את הטסט” או יזייף זאת עם assert status == 200 יחיד, ה‑gate מריץ Hurl באמת ומאמת מחדש את חוזה התשובה. הייצור על ידי AI, ההכרעה על ידי מכונה. ה‑AI כותב את הטסט אך אין לו סמכות על ההשלמה.
הפקודות בדיוק כמו ב‑Part 3:
go build -o huma .
./huma scan openapi.yaml # רשימת endpoints → session
./huma next # ה‑endpoint הבא + prompt לסוכן
./huma submit --endpoint "POST /orders" \
--test "orders_post.hurl" # טסט ה‑Hurl שהסוכן כתב
./huma status # מצב ההתקדמות
./huma export # דוח כיסוי (PASS/לא מכוסה לכל endpoint)
הרצה ב‑Claude Code בשורה אחת:
תן לתת‑סוכן לכתוב טסטים לכל endpoint עד ש‑
huma nextמתרוקן.
תת‑הסוכן חוזר על לולאת next → כתיבת טסט → submit עד ש‑TODO מגיע ל‑0. הסוכן אינו יכול לדלג על endpoint קשה — next אינו מנפיק את הבא עד שה‑gate מעביר אותו.
זה מראה את לב הדפוס. החלף רק את ה‑gate (go test→hurl→הצלבת schema) ואותם חמישה חלקים, אותה מכונת מצבים, הופכים לכלי שונה לחלוטין. ב‑Part 5 אתה עושה את אותו דבר עבור הדומיין שלך עצמו.
Part 5 — בנה את ה‑Quest CLI שלך
גיליון תכנון
מלא את החסר וזה כבר המפרט.
דומיין: [מה נאסף/מעובד]
יחידת quest אחת: [מהו דבר אחד שהוא quest אחד — חברה 1? פונקציה 1? endpoint 1?]
קלט: [מה ש‑scan יקרא — Excel? תיקייה? רשימה?]
תנאי סיום: [תנאי שהמכונה יכולה לענות עליו yes/no]
פריטי בדיקת ה‑gate: [מהו "עובדה" בדומיין — פריטים לאימות מחדש]
- בדיקת פורמט: [...]
- הגנה מפני cheese: [איך הסוכן ירמה? האימות מחדש שחוסם זאת]
- תנאי REVIEW: [מקרים מעורפלים שיש לשלוח לאדם]
משוב (Fact): [מיקום·צפוי·בפועל שיוחזר ב‑FAIL]
דוגמה: [דגימה של "תוצאה שנראית כך" עבור ה‑prompt של next]
פורמט export: [שימור המקור + עמודות תוצאה]
תנאי השלמה (ה‑gate של ה‑build הזה עצמו)
כדי ש‑Quest CLI שנבנה מהמאמר הזה יהיה “מושלם” — כלומר כדי שהמאמר הזה יהיה cheese-proof כפי שלימד — צריך לקיים את הבא:
-
go buildעובר - הפקודות
scan / next / submit / status / exportפועלות - מכונת המצבים
TODO → PASS/REVIEW/DONE, PASS בלתי משתנה,remainingיורד מונוטונית - אימות מכונה L1 דטרמיניסטי (אותו קלט + world-state → אותה הכרעה) — סמכות נעילת PASS ל‑L1 בלבד
- אם יש שארית פתוחה, אימות AI L2 בתכנון עצמאי (מודל/קלט אחר)·ריבוי·yes/no מפורק — סמכות REVIEW בלבד, אסור נעילת PASS
- ה‑gate מאמת מחדש עובדה ולא טענה של הסוכן (לפחות פריט אחד של הגנת cheese — סעיף 4 של 5 שלבי הגזירה)
- שאילתות חיצוניות (רשת·DNS) מוזרקות מאחורי interface — הטסט פועל אופליין עם mock
- gate של שאילתה חיצונית הוא 3 ענפים PASS/FAIL/REVIEW (לא ניתן לאימות = REVIEW, לא FAIL)
- FAIL משמר TODO·
Tries+1, אם>=MaxTriesאז DONE; PASS·REVIEW·DONE אינם ניתנים להגשה מחדש - משוב FAIL הוא
Factהמכיל מיקום·צפוי·בפועל - ה‑session נשמר בקביעות בדיסק (resumable)
- unit test: gate תחילה, סך statements 90%+
-
exportאינו דורס את המקור
הוראת build
נותנים לסוכן כך:
השתמש ב‑Part 3 (שלד הפקודות) של מסמך זה כשרטוט וב‑Part 4 (huma) כדוגמה מעובדת, וכתוב Quest CLI מבוסס cobra ב‑Go עבור [הדומיין שלך]. המשך עד שכל ה‑checklist של תנאי ההשלמה ב‑Part 5 מתקיים. ה‑gate חייב להיות דטרמיניסטי, ולאמת מחדש עובדה ולא את טענת הסוכן.
שלושה תפקידים נמצאים בתוך הסצנה האחת הזו.
- משחק את ה‑Quest. מאמץ ומשתמש ב‑gate שמישהו בנה — משתמש.
- מתכנן את ה‑Quest. בונה בעצמו gate המתאים לדומיין שלי — יוצר. (לשם המאמר הזה מוביל)
- מתכנן Quest שלא ניתן ל‑cheese. חוסם מראש את הנקודה שבה ה‑proxy אינו מדביק את המטרה — מעצב.
רובם נעצרים במשחק. מה שמגדיל את היריעה הוא התכנון, ומה ששומר על היריעה שלא תישבר הוא תכנון שחוסם cheese.
בפעם הבאה שמישהו יאמר “סיימתי”, אל תהרהר אלא שאל — “מהי השלמה, ומי תכנן את ה‑quest שהכריע עליה.”
הייצור יכול להיות הסתברותי. האימות חייב להיות דטרמיניסטי.
מאמרים קשורים
- Who Defines ‘Done’ — לתכנן השלמה כ‑Quest — החלק הרעיוני של המאמר הזה. השלמה=gate, cheese·Goodhart.
- Ratchet Pattern — איך לגרום לסוכן ללכת עד הסוף — המאמר המרכזי על נעילה חד‑כיוונית.
- ratchet code שמנצל את IFEval לטובתו — התכנסות באמצעות משוב עובדתי.
- Reins Engineering — AI עם רסן — harness היא גדר, Quest היא רסן.
- טופולוגיית משוב לפני IQ של מודל — את התוצאה מכריע לא המודל אלא מבנה המשוב.
- huma — ratchet שאינו מדלג על endpoints — האב‑טיפוס של שלד הפקודות (scan/next/verify).
- תנאי מקדים לשיפור דיוק של מולטי‑סוכן LLM — מדוע שכבת אימות ה‑AI (L2) חייבת עצמאות כדי לפעול. הרקע התאורטי של חיזור האימות.
מקורות
- Von Neumann, J. (1956). “Probabilistic Logics and the Synthesis of Reliable Organisms from Unreliable Components.” Automata Studies, Princeton University Press.
- Zhou, J. et al. (2023). “Instruction-Following Evaluation for Large Language Models.” arXiv:2311.07911
- Ouyang, L. et al. (2022). “Training Language Models to Follow Instructions with Human Feedback.” NeurIPS 2022. arXiv:2203.02155
- Huang, J. et al. (2024). “Large Language Models Cannot Self-Correct Reasoning Yet.” ICLR 2024. arXiv:2310.01798
- Chen, X. et al. (2024). “Teaching Large Language Models to Self-Debug.” ICLR 2024. arXiv:2304.05128
- Yang, J. et al. (2024). “SWE-agent: Agent-Computer Interfaces Enable Automated Software Engineering.” NeurIPS 2024.
- Jimenez, C. et al. (2024). “SWE-bench: Can Language Models Resolve Real-World GitHub Issues?” ICLR 2024. arXiv:2310.06770
- Zhou, S. et al. (2023). “WebArena: A Realistic Web Environment for Building Autonomous Agents.” arXiv:2307.13854
- Cemri, M. et al. (2025). “Why Do Multi-Agent LLM Systems Fail?” arXiv:2503.13657
- Sharma, M. et al. (2024). “Towards Understanding Sycophancy in Language Models.” ICLR 2024. arXiv:2310.13548
- Fanous, A. et al. (2025). “SycEval: Evaluating LLM Sycophancy.” AAAI/ACM AIES 2025. arXiv:2502.08177
- Shapira, I. et al. (2026). “How RLHF Amplifies Sycophancy.” arXiv:2602.01002
- Ibrahim, L. et al. (2026). “Training Language Models to Be Warm Can Reduce Accuracy and Increase Sycophancy.” Nature 652, 1159-1165.
- Panickssery, A., Bowman, S., & Feng, S. (2024). “LLM Evaluators Recognize and Favor Their Own Generations.” NeurIPS 2024. arXiv:2404.13076
- Stechly, K., Valmeekam, K., & Kambhampati, S. (2024). “On the Self-Verification Limitations of Large Language Models.” arXiv:2402.08115
- McKee-Reid, L. et al. (2024). “Honesty to Subterfuge: In-Context RL Can Make Honest Models Reward Hack.” arXiv:2410.06491
- Bondarenko, A. et al. (2025). “Demonstrating Specification Gaming in Reasoning Models.” arXiv:2502.13295
- Thaman, K. (2026). “Reward Hacking Benchmark: Measuring Exploits in LLM Agents with Tool Use.” arXiv:2605.02964
- Deque Systems (2021). “Automated Testing Study Identifies 57 Percent of Digital Accessibility Issues.”
יומן שינויים
- 2026-06-03: מהדורה ראשונה (אינטגרציה של 7 מאמרי קורפוס + huma, דוגמה מעובדת). חיזוק בעקבות בדיקה — 5 שלבי גזירת gate מדומיין, 3 ענפים לדטרמיניזם·רשת, ה‑seam של
Fetcher, כללי מעבר מצב. - 2026-06-03: «חיזור האימות» נוסף — מודל דו‑שכבתי של אימות מכונה (L1, סמכות PASS) + אימות AI (L2, תכנון עצמאי·סמכות REVIEW) + אדם (L3) ואסימטריית סמכות. הכללה של “gate = דטרמיניזם בלבד” עד לדומיינים פתוחים.
- 2026-06-05: comail הוסר (הפך לפרטי) בשל הסיכון לסיוע לפעילות בלתי חוקית. הדוגמה המעשית הוחלפה ב‑huma.