 Image generated by Google Gemini
Image generated by Google Gemini
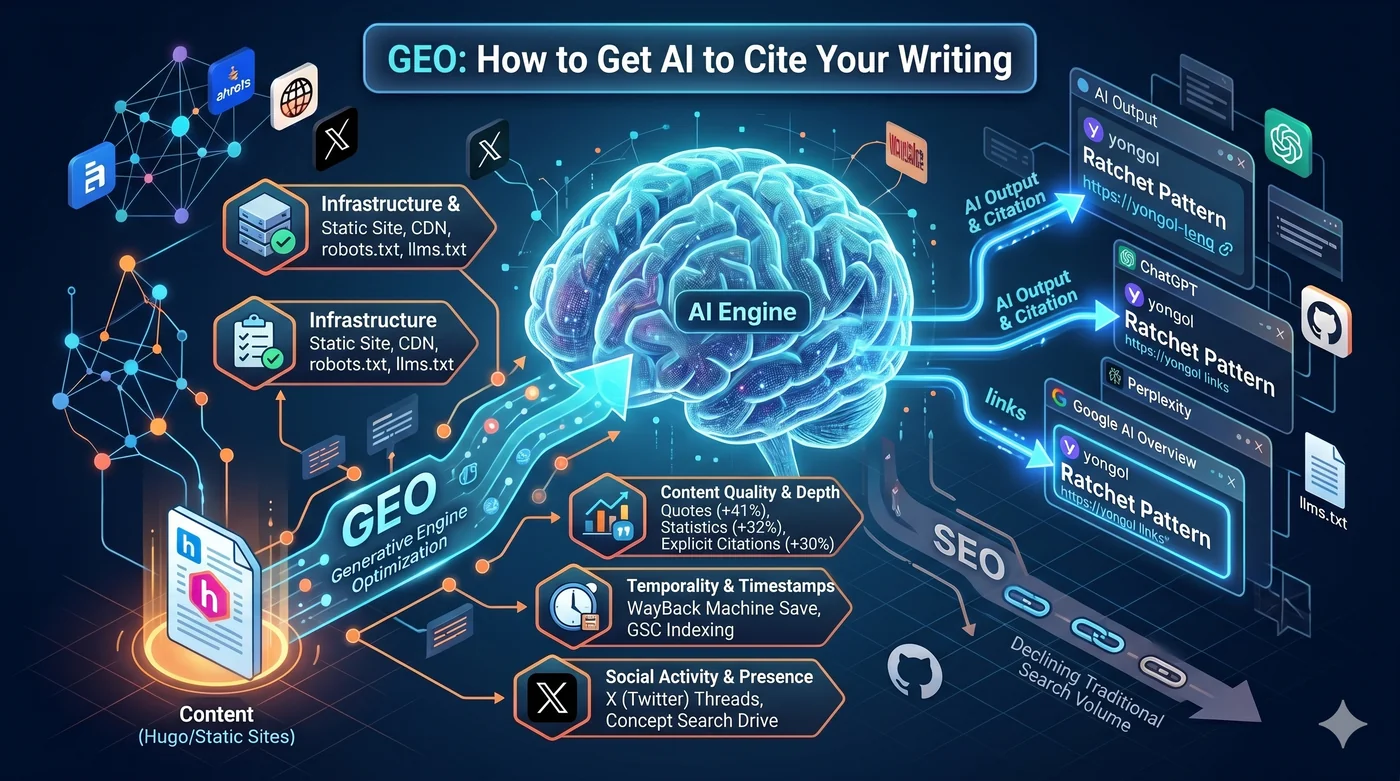
GEO (Generative Engine Optimization) היא אסטרטגיה לאופטימיזציה של תוכן כך שמנועי חיפוש AI יצטטו אותו. SEO מסורתי היה משחק של דירוג בגוגל; GEO הוא משחק של הכללה כמקור בתשובות שנוצרות על ידי AI. ידוע גם כ-AEO (Answer Engine Optimization), AI SEO או אופטימיזציה לחיפוש LLM.
החיפוש השתנה — תחילת עידן ה-AI SEO
הקלדת שאילתה בגוגל וקיבלת עשרה קישורים כחולים. עכשיו ה-AI מייצר את התשובה. ChatGPT, Perplexity, Google AI Overview — משתמשים מקבלים תשובות בלי ללחוץ על קישור אחד.
Gartner צופה ירידה של 25% בנפח החיפוש המסורתי עד 2026. 31.3% מאוכלוסיית ארה"ב כבר משתמשים בחיפוש AI גנרטיבי.
הבעיה היא זו: אם התוכן שלך לא מצוטט בתשובות שנוצרות על ידי AI, הוא כאילו לא קיים.
Generative Engine Optimization (GEO) מגדיר את הכללים של המשחק החדש הזה.
GEO vs SEO vs AEO — מה ההבדל
SEO מסורתי היה משחק דירוג בגוגל. מילות מפתח, קישורים נכנסים, תגיות מטא. GEO הוא משחק אחר.
| SEO | GEO | |
|---|---|---|
| מטרה | דירוג SERP | ציטוט בתשובות AI |
| מדד הצלחה | חשיפות, קליקים, CTR | שיעור ציטוט, תדירות המלצת מותג |
| אות מרכזי | קישורים נכנסים, מילות מפתח | בהירות ישויות, ציטוט מקורות, עקביות חוצת פלטפורמות |
| מודל תנועה | קליק → ביקור באתר | אפס קליקים (צריכה ללא ביקור) |
יש נתונים מפתיעים. 83% מציטוטי AI Overview מגיעים מדפים שאינם ב-10 הראשונים האורגניים בגוגל. 28.3% מהדפים המצוטטים ביותר על ידי ChatGPT הם בעלי נראות אורגנית 0 בגוגל. דירוג SEO מסורתי וציטוט AI הם שני משחקים נפרדים.
אז מה ה-AI מצטט?
1. תשתית: Hugo + CloudFront + robots.txt + llms.txt
אם סורקי AI לא יכולים להגיע לתוכן שלך, אין ציטוט. התנאי הראשון הוא תשתית טכנית.
מחולל אתרים סטטי (Hugo) + S3 + CloudFront
- HTML סטטי הוא המקור המהיר והנקי ביותר לסורקים. SPA דורש רינדור JavaScript, וסורקי AI מדלגים עליו לעתים קרובות
- CDN של CloudFront מציע זמני תגובה מהירים בכל העולם. גם סורקי AI משתמשים במהירות כאות
- הבנייה הרב-לשונית של Hugo מייצרת אוטומטית תגיות hreflang. 12 שפות = 12 נקודות כניסה
Sitemap
sitemap XML הוא הבסיס. אבל בעידן GEO נדרשים שני רכיבים נוספים:
llms.txt— קובץ Markdown שמוצב בשורש האתר. אם robots.txt אומר “איפה לסרוק”, llms.txt מנחה “מה התוכן החשוב”. Anthropic, Hugging Face ו-Perplexity אימצו אותו כחלוצים- Schema.org JSON-LD — סכמות Article, Person, SoftwareSourceCode. דף עזר לסורקי AI: “זה מה שהדף הזה”
הרשאה מפורשת לסורקי AI ב-robots.txt:
נכון ל-2026, בוטי סורקי AI מרכזיים מתחלקים ל-5 קטגוריות:
| קטגוריה | תיאור | השפעת חסימה |
|---|---|---|
| סורקי אימון | איסוף נתוני אימון LLM | הרחקה מידע ארוך-טווח של המודל |
| אינדקסרי חיפוש | אינדקס לתשובות חיפוש AI | היעלמות מתוצאות חיפוש AI |
| שליפה שמופעלת על ידי משתמש | fetch בזמן אמת בעת שאלת משתמש | לא ניתן להפנות במהלך שיחה |
| סוכנים | AI גולש ברשת עבור המשתמש | הרחקה משירותי סוכנים |
| איסוף נתונים | איסוף נתוני רשת בקנה מידה גדול | הרחקה ממערך הנתונים הרלוונטי |
רשימת בוטים עיקריים:
| בוט | בעלים | שימוש |
|---|---|---|
| GPTBot | OpenAI | אימון מודל |
| OAI-SearchBot | OpenAI | אינדוקס חיפוש ChatGPT |
| ChatGPT-User | OpenAI | שליפה בזמן אמת על ידי משתמש |
| ClaudeBot | Anthropic | אימון מודל |
| Claude-SearchBot | Anthropic | אינדוקס חיפוש Claude |
| Claude-User | Anthropic | שליפה בזמן אמת על ידי משתמש |
| Google-Extended | אימון Gemini | |
| Applebot-Extended | Apple | אימון Apple Intelligence |
| Meta-ExternalAgent | Meta | אימון Llama + Meta AI |
| PerplexityBot | Perplexity | חיפוש AI |
| bingbot | Microsoft | Bing + Copilot |
| CCBot | Common Crawl | מערך נתונים פתוח (כמעט כל LLM משתמש בו) |
| Bytespider | ByteDance | אימון Doubao (מתעלם מ-robots.txt, מומלץ לחסום) |
העיקר: יש להבחין בין בוטי אימון לבוטי חיפוש/שליפה. גם אם חוסמים בוטי אימון, אם מאפשרים בוטי חיפוש — תצוטטו בתשובות AI. אם חוסמים את שניהם, נעלמים מעולם ה-AI.
llms.txt — אם robots.txt אומר “איפה לסרוק”, llms.txt מנחה “מה התוכן החשוב”. קובץ Markdown בשורש האתר. Anthropic, Hugging Face ו-Perplexity אימצו אותו כחלוצים. הוא מסיר רעש של תפריטים, פרסומות וסקריפטים ומספק תוכן מזוקק המותאם לחלון ההקשר של ה-AI.
2. Sitemaps ו-hreflang: המפה הסמנטית שה-AI קורא
sitemap מסורתי הוא רשימת URL. ה-sitemap של עידן GEO הוא מפה סמנטית.
<url>
<loc>https://www.parkjunwoo.com/opinion/reins-engineering/</loc>
<lastmod>2026-05-27</lastmod>
<changefreq>weekly</changefreq>
</url>
בנוסף:
- קישורי hreflang: 12 גרסאות השפה של אותו מאמר מקושרות זו לזו. AI מעריך מאוד סמכות רב-לשונית
- דיוק lastmod: 76.4% מציטוטי AI מגיעים מדפים שעודכנו ב-30 הימים האחרונים. תוכן בן פחות מ-3 חודשים מצוטט בסיכוי פי 3. זיוף lastmod גורם לתוצאה הפוכה
- מבנה קטגוריות:
/opinion/,/tech/,/lecture/— היררכיה משמעותית נותנת ל-AI יותר הקשר ממבנה שטוח
הגשת ה-sitemap ל-Google Search Console היא המינימום. אבל זה לא מספיק.
3. Wayback Machine ו-Google Search Console: הוכחת מקוריות התוכן
Wayback Machine מאחסנת תמונות מצב של הרשת מאז 1996. עבור ה-AI, זהו זיכרון זמני.
למה זה חשוב:
- אם פרסמת את המאמר הראשון שמגדיר את “Ratchet Pattern” במאי 2026, Wayback Machine שומרת את תמונת המצב
- שישה חודשים מאוחר יותר, גם אם מישהו משתמש באותו מושג על פלטפורמה גדולה יותר, ההוכחה הזמנית מצביעה על המחבר המקורי
- כאשר AI קובע מקורות, תאריך הפרסום הראשון פועל כאות סמכות עקיף
ביצוע:
- לאחר פרסום מאמר חדש, לשלוח בקשת שמירה ידנית ל-Wayback Machine (
web.archive.org/save/) - לבקש אינדוקס URL ב-Google Search Console
- בשני המקומות מוטבע חותם זמן
הערה: נכון ל-2026, 241 אתרים חוסמים גישה ל-Wayback Machine (חשש מעקיפת זכויות יוצרים על ידי חברות AI). עבור בלוג אישי, זו דווקא הזדמנות — בארכיון שממנו מדיה גדולה נסוגה, המשקל היחסי של תוכן אישי עולה.
4. ציטוטים וסמכות נושאית (Topical Authority)
3 האסטרטגיות המובילות לשיפור נראות לפי מאמר GEO המקורי (Aggarwal et al., KDD 2024):
| אסטרטגיה | שיפור נראות |
|---|---|
| הוספת ציטוטים (Quotation) | +41% |
| הוספת סטטיסטיקות (Statistics) | +32% |
| ציון מקורות (Cite Sources) | +30% |
דחיסת מילות מפתח חסרת ערך או מזיקה ב-GEO. AI לא מסתכל על מילות מפתח אלא על ראיות.
למה ציטוטים אקדמיים חשובים:
- AI מבחין בין “טענה” ל"טענה מבוססת". “42% מזמן המפתחים מושקע בחוב טכני” היא טענה. “42% מזמן המפתחים מושקע בחוב טכני (Stripe, The Developer Coefficient, 2018)” היא ראיה
- למשפטים מבוססים יש עלות אמון נמוכה כשה-AI מצטט אותם בתשובותיו. משפטים ללא מקור חייבים אימות ולכן מדולגים
- אתרים שמצוטטים על ידי 4 פלטפורמות AI ומעלה מופיעים פי 2.8 יותר ב-ChatGPT
ניהול תוכן קשור ותיוג:
תגיות אינן למען בני אדם. הן למען ה-AI.
- מערכת תגיות עקבית: “Reins Engineering”, “Ratchet Pattern”, “SSOT” — כשאותה תגית מופיעה במספר מאמרים, AI מזהה סמכות נושאית (topical authority)
- קישורים פנימיים: קישור מאמרים קשורים בתוך מאמר עוזר לסורקי AI לזהות אשכולות נושאיים. מאמר מחובר מצוטט יותר ממאמר מבודד
- הפניות צולבות: ציטוט עצמי בין המאמרים שלך תקף. “היסודות של מושג זה הוגדרו ב-Ratchet Pattern”
5. X, Reddit, Hacker News: אסטרטגיות חברתיות לנפח חיפוש מותג
תנאי השימוש של X/Twitter אוסרים מפורשות על אימון AI על ידי צד שלישי. כלומר, תוכן שפורסם ב-X לא נכנס ישירות לנתוני האימון של ChatGPT.
אבל פעילות חברתית תורמת לנראות AI דרך נתיבים עקיפים:
נפח חיפוש מותג הוא המנבא החזק ביותר לציטוטי LLM (מקדם מתאם 0.334, גבוה מקישורים נכנסים).
הנתיב נראה כך:
שרשור X → אנשים מחפשים "yongol" בגוגל → נפח חיפוש מותג עולה → AI מזהה את "yongol" כישות שכדאי לצטט
נתוני מאי של parkjunwoo.com מאשרים זאת:
- חיפוש גוגל “yongol”: 14 חשיפות, 5 קליקים, מיקום ממוצע 3.1
- שכפולי yongol ב-GitHub: 316 משתמשים ייחודיים
- נתיב רכישה: t.co (X) 4 אנשים → GitHub → בלוג
במקום לשתף קישורים ישירות ב-X, לגרום לאנשים לחפש את המושג יעיל יותר עבור GEO.
העוצמה של earned media:
48% מכלל ציטוטי LLM מגיעים מ-earned media (עיתונות, ביקורות, אזכורי צד שלישי). תוכן עצמי מהווה רק 23%. כלומר, לגרום לאחרים להזכיר אותך יעיל פי 2 מאשר לבצע אופטימיזציה לתוכן שלך עצמך.
כשפרויקט מוזכר ב-Reddit, Hacker News או dev.to → דרך סריקת AI של פלטפורמות אלה → ה-LLM לומד את הישות.
רשימת בדיקה
תשתית
├── אתר סטטי Hugo + S3 + CloudFront
├── הרשאת סורקי AI ב-robots.txt
├── יצירת llms.txt (אוצרות תוכן מרכזי)
├── Schema.org JSON-LD (Article, Person)
└── XML sitemap + hreflang
תוכן
├── ציון מקור לכל טענה (+30% נראות)
├── הכנסת סטטיסטיקות בשורה (+32%)
├── שימוש בטבלאות השוואה (ניתוח AI אופטימלי)
├── שמירה על lastmod מדויק (עדכון < 30 יום → שיעור ציטוט 76.4%)
└── עדכון קבוע של מאמרים ישנים מ-3 חודשים (סיכוי ציטוט פי 3)
חיבורים
├── מערכת תגיות עקבית (סמכות נושאית)
├── קישורים פנימיים (אשכולות נושאיים)
├── ציטוט מאמרים/מקורות חיצוניים (הפחתת עלות אמון)
└── מאמר חדש → Wayback Machine + הגשה ל-GSC
חברתי
├── שרשורי X ליצירת חיפושי מושגים (נפח חיפוש מותג)
├── יצירת earned media ב-Reddit/HN
└── הפצת מושגים יעילה יותר ל-GEO משיתוף ישיר של קישורים
יישום GEO באתר הזה
האסטרטגיות שתוארו במאמר זה מיושמות בפועל ב-parkjunwoo.com:
- robots.txt — 25 סורקי AI מורשים מפורשות, Bytespider חסום
- llms.txt — תוכן מרכזי מאורגן לחלון ההקשר של ה-AI
- אוסף מאמרי Reins Engineering — רכזת אשכול נושאי
- בנייה רב-לשונית ב-12 שפות — יצירת hreflang אוטומטית, נקודות כניסה לכל שפה
- מקורות אקדמיים בכל מאמר — סטטיסטיקות בשורה + ציטוטים אקדמיים לצפיפות עובדתית
- הגשה מיידית ל-Wayback Machine + GSC לאחר פרסום — הוכחת מקוריות זמנית
מאמרים קשורים
- Google, Optimizing your website for generative AI features on Google Search (2026) — מדריך רשמי של Google לאופטימיזציה לחיפוש AI
- Cyrus Shepard, AI Citation Ranking Factors Analysis — מטא-אנליזה של 54 מחקרים, כימות 23 גורמי דירוג ציטוט AI
- Seer Interactive, AIO Impact on Google CTR: 2026 Update — 53 מותגים, 2.43 מיליארד חשיפות נעקבו. CTR -61% עם AI Overview
- Discovered Labs, AI Citation Patterns: How ChatGPT, Claude, and Perplexity Choose Sources — רק 12% מציטוטי AI חופפים ל-10 הראשונים בגוגל
- Ahrefs, Generative Engine Optimization: Growth Strategies and Metrics — ניתוח 300,000 מילות מפתח. אזכורי רשת עולים על קישורים נכנסים 3:1 בחשיפת AI Overview
- Datos/SparkToro, State of Search Q1 2026 — מעקב אחר נתח שוק חיפוש AI מבוסס clickstream
- Rand Fishkin, Search Happens Everywhere — ניתוח 41 אתרים, חיפוש לא מתרחש רק בגוגל
- Go Fish Digital, GEO Case Study: 3X’ing Leads — הפניות AI מייצרות שיעור המרה גבוה פי 25 מחיפוש מסורתי
- Search Engine Land, How schema markup fits into AI search — ניתוח מפוכח של schema markup וחיפוש AI
- Lily Ray, The Vicious Cycle of SEO — אזהרה מפני חיי המדף הקצרים של ספאם GEO
מקורות
מאמרים אקדמיים
- Aggarwal et al., GEO: Generative Engine Optimization, KDD 2024 — ציטוטים +41%, סטטיסטיקות +32%, ציון מקורות +30% נראות
- Xu et al., Measuring Google AI Overviews (2026) — ניתוח 55,393 שאילתות. 30% מדומיינים שצוטטו על ידי AIO לא נמצאים בעמוד 1 אורגני
- Fang et al., Recency Bias in LLM-Based Reranking, SIGIR-AP 2025 — כל 7 המודלים מעדיפים באופן עקבי תוכן עדכני
- Zhang et al., Citation Selection to Citation Absorption (2026) — השוואה כמותית של דפוסי ציטוט ChatGPT/Google AIO/Perplexity
- Algaba et al., LLMs Reflect Human Citation Patterns, NAACL 2025 — LLMs מעדיפים ביתר שאת מאמרים בעלי ציטוט גבוה (אפקט מתיו)
- arXiv:2602.18455, AI Search Impact on Wikipedia Traffic (2026) — AIO מפחית תנועה לוויקיפדיה ב-15% (ניתוח סיבתי DID)
- Yu et al., Structural Feature Engineering for GEO (2026) — מבנה התוכן עצמו משפיע על הסתברות הציטוט
- Tian et al., Diagnosing Citation Failures in GEO (2026) — שינוי 5% בתוכן משפר שיעור ציטוט ב-40%
- Baack, Critical Analysis of Common Crawl, FAccT 2024 — רכיבים מרכזיים והטיות בנתוני אימון LLM
- Strauss et al., The Attribution Crisis in LLM Search (2025) — 92% מ-Gemini לא מספק ציטוטים ניתנים ללחיצה
דוחות נתונים
- Ahrefs, Do AI Assistants Prefer Fresh Content? (2025) — ניתוח 17 מיליון ציטוטי AI
- SparkToro/Datos, State of Search Q1 2026 — מעקב אחר נתח שוק חיפוש AI מבוסס clickstream
- GitClear, AI Copilot Code Quality 2025 — ניתוח 210 מיליון שורות
- Gartner — תחזית לירידה של 25% בנפח חיפוש מסורתי עד 2026
- llms.txt proposed standard — Search Engine Land
יומן שינויים
- 2026-05-27: מהדורה ראשונה