 Image: AI generated
Image: AI generated
המורשת לא משקרת
לקוד מורשת אין תיעוד. ואם יש — הוא מלפני שלוש שנים. בדיקות אין, ואם יש, הן שבורות ומסומנות ב-skip. ההערות סותרות את הקוד. המחבר המקורי עזב, והאדם היחיד שמבין משהו השאיר רק את המשפט “אם תיגע בזה, זה יתפוצץ”.
ובכל זאת אותו קוד רץ ברגע זה ממש. הוא מעבד תשלומים, מקבל התחברויות, מכניס הזמנות.
התיעוד משקר. ההערות משקרות. הזיכרון האנושי משקר גרוע עוד יותר. הדבר היחיד שאינו משקר הוא התעבורה שזורמת באמת.
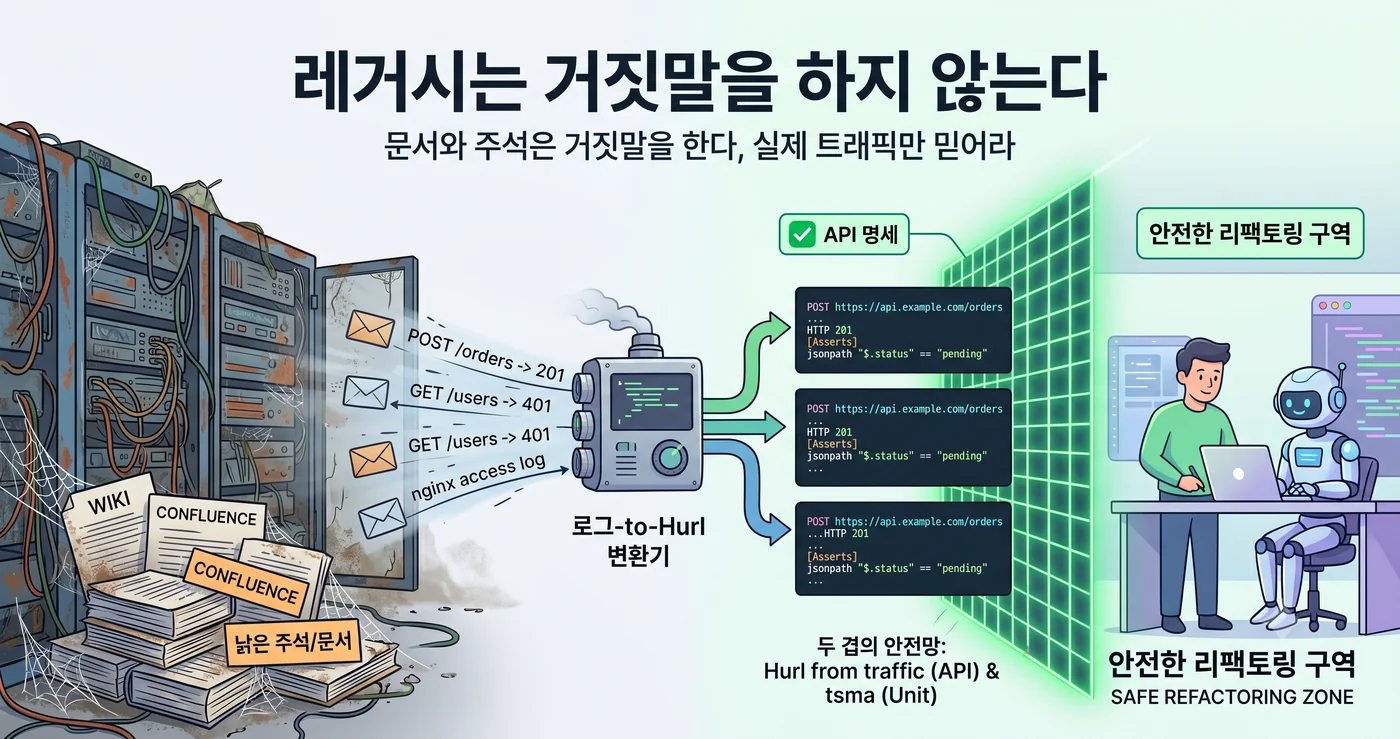
אם כך, היכן יש לחפש את המפרט? לא בוויקי. לא בקונפלואנס. ב-nginx access log.
ביצה ותרנגולת
כדי לרפקטר מורשת צריך רשת ביטחון. כשמשנים משהו, צריך לדעת מיד אם ההתנהגות השתנתה. אותה רשת ביטחון היא בדיוק הבדיקות.
אבל למורשת אין בדיקות. כדי לכתוב בדיקה צריך לדעת מה הקוד עושה. כדי לדעת מה הקוד עושה צריך לקרוא אותו. וכשקוראים מגלים שאין לא בדיקות ולא תיעוד.
מה קודם, התרנגולת או הביצה. זהו מבוי סתום קלאסי שמייקל פת’רס נתן לו שם בספר Working Effectively with Legacy Code. כתשובה הוא הציע את ה-characterization test (בדיקת אפיון) — בדיקה שאינה מקבעת מה הקוד אמור לעשות נכון, אלא את מה שהוא עושה כעת, בדיוק כפי שהוא. נכון ולא-נכון הם שאלה לאחר כך. קודם צריך לקבע את ההתנהגות הנוכחית כדי שאפשר יהיה לגעת בקוד.
בתקופתו של פת’רס כתבו את זה ידנית. קוראים לפונקציה, מסתכלים על הערך שיצא, ורושמים אותו כמו שהוא ב-expected. משעמם, איטי, ולכן איש לא הגיע עד הסוף.
אבל ברמת ה-API, אותן “תוצאות של קריאה לפונקציה” כבר נצברות איפשהו. כל יום, בעשרות אלפי מקרים. בתוך קובץ הלוג.
חודש של לוגים הוא המפרט
איסוף לאורך חודש מצלם כמעט את כל ההתנהגות הנוכחית של API מורשת.
nginx access log (חודש):
endpoint · HTTP method · status code · timing
תדירות קריאה → סדר עדיפויות
דפוסי שגיאה (401, 422, 500 …)
request/response body (נלכד דרך middleware או reverse proxy):
זוגות בקשה/תגובה תקינים → התנהגות שחייבת לעבור
זוגות בקשה/תגובה שגויים → מקרי קצה שאסור שיישברו
חיבור של שני הזרמים האלה מתורגם ישירות לבדיקת אינטגרציה ב-Hurl. Hurl הוא פורמט שרושם בקשת HTTP ותגובה צפויה כמו שהן, בטקסט פשוט. זוג תעבורה אחד — “לבקשה הזו יצאה התגובה הזו” — הוא בדיוק בלוק אחד של Hurl.
# POST /api/orders — תדירות קריאה #3, 12,000 קריאות ביום
POST https://api.example.com/orders
Content-Type: application/json
{ "sku": "A-1024", "qty": 2 }
HTTP 201
[Asserts]
jsonpath "$.order_id" exists
jsonpath "$.status" == "pending"
jsonpath "$.total" == 49800
הבדיקה הזו אינה יודעת “כיצד API ההזמנות אמור לפעול”. היא יודעת רק ש"כעת הוא פועל כך". וזה מספיק. ברגע שהריפקטורינג ישנה את התגובה הזו, נדלקת נורה אדומה.
מה שנגזר אוטומטית מן הלוג:
- אילו endpoints נמצאים בשימוש אמיתי → endpoint שלא נקרא אף פעם במשך חודש הוא קוד מת. מועמד למחיקה לפני הריפקטורינג.
- דפוסי תגובה תקינים → בדיקת רגרסיה בסיסית.
- דפוסי שגיאה → מקרי קצה אמיתיים שאדם אינו מסוגל לדמיין. אלה ה-422 וה-500 שיצרו משתמשים אמיתיים.
- תדירות קריאה → סדר עדיפויות לבדיקות. מתחילים מזו עם 12,000 קריאות ביום.
הסעיף האחרון חשוב. כשאדם כותב בדיקות, הוא מתחיל מן ה-happy path שהוא זוכר. לתעבורה אין הטיה כזו. הנתיב שמקבל עומס אמיתי הוא סדר העדיפויות.
רשת ביטחון כפולה
הגישה הזו אינה עומדת לבדה, אלא היא שכבה אחת בצינור ה-ratchet שמרים מורשת לכדי agent-operable.
nginx log (חודש) → יצירת Hurl אוטומטית → צילום ההתנהגות הנוכחית של API המורשת
↓
tsma → רשת ביטחון ברמת הפונקציה (unit)
↓
filefunc → סידור מבנה הקוד (מושג אחד לקובץ אחד)
↓
ריפקטורינג → Hurl מאמת שהתנהגות ה-API נשמרת (integration)
העיקר הוא שרשת הביטחון היא כפולה.
- tsma = רשת ביטחון ברמת הפונקציה. תופסת אם הלוגיקה הפנימית השתנתה. אבל גם אם חתימת הפונקציה נשארה זהה, ההתנהגות הכוללת של ה-endpoint עשויה להשתנות.
- Hurl from traffic = רשת ביטחון ברמת ה-API. תופסת אם החוזה הנצפה מבחוץ נשמר. לא משנה כיצד תהפכו את הפנים — כל עוד מה שנכנס מבחוץ ומה שיוצא החוצה זהה, הבדיקה עוברת.
ריפקטורינג, מעצם הגדרתו, הוא “שינוי המבנה הפנימי תוך שמירה על ההתנהגות החיצונית”. אם כך, ההגדרה של אותה “התנהגות חיצונית” שיש לשמר חייבת להיות מצולמת איפשהו. tsma תופס את הגבול הפנימי, Hurl את הגבול החיצוני. רק כששתי השכבות נמצאות יחד אפשר לומר לסוכן: “הפוך את הקוד כאוות נפשך, היכן הוא נשבר — המכונה רואה”.
שופט שאינו יכול להחניף
זה משתלב בדיוק עם המהות של ה-Symbolic Feedback Loop.
אם תשאלו את הסוכן “עשית ריפקטורינג טוב?”, הוא יענה “כן, סידרתי הכול בצורה נקייה”. כשנותנים לו דעה, הוא מחניף. אבל כשמריצים Hurl, יוצא POST /orders → expected 201, got 500. מספרים וקודי סטטוס אינם יודעים להחניף. כי אין להם רגש.
בדיקת Hurl שנשלפה מן התעבורה היא מפרט שלא התערב בו שיפוט אנושי. זה לא “מישהו חושב שזה אמור לפעול ככה”, אלא “התצפית הראתה שזה פעל ככה”. לא טענה אלא מדידה. ולכן את הנכון והלא-נכון של הריפקטורינג יכולה לשפוט המכונה ולא האדם. ה-LLM אינו שופט אלא מבצע, ואת הפסיקה עושה כלי דטרמיניסטי.
ההנחה היחידה: לוג שתועד היטב
כדי שהשיטה הזו תעמוד נדרש דבר אחד בלבד. חודש של לוג שתועד היטב.
ה"תועד היטב" הוא הכול. access log בלבד אינו מספיק. הוא נותן endpoint, status code ו-timing, אבל את העיקר שיש לצלם — זוג ה-request body וה-response body — הוא אינו נותן. רק מתוך POST /orders → 201 אי אפשר לשחזר “לקלט הזה יצא הפלט הזה”. כדי לקבע פונקציונליות צריך להחזיק ביד גם את מה שנכנס וגם את מה שיצא.
ולכן השאלה האמיתית אינה “איך לכתוב בדיקה” אלא “האם הלוג שלי כתוב מספיק טוב כדי להפוך למפרט”.
- האם נשמרים ה-request/response body, או רק status code.
- האם נשמרות גם תגובות השגיאה. ה-body של 422 ושל 500 הוא בדיוק מקרה הקצה שאדם אינו מסוגל לדמיין.
- האם הלוג מובנה כך שמכונה יכולה לקשור בקשה ותגובה לזוגות.
אם כל זה קיים, כבר חודש שאתם כותבים מפרט, בלי לדעת. אין צורך לכתוב בדיקות בנפרד. צינור הלוגים כתב אותן במקומכם. ואם זה לא קיים, די להכניס עכשיו שכבת middleware אחת ולהשאיר אותה דולקת חודש. כעבור חודש, בידכם תהיה ההתנהגות הנוכחית של המורשת בשלמותה.
מדוע חודש ולא יום. יום אחד תופס רק את ה-happy path. חודש תופס את ה-batch של סוף החודש, את התפרצות התעבורה לפני ההתחשבנות, את endpoint הניהול שנקרא לעיתים נדירות, ואת ה-cron שרץ פעם אחת ב-3 לפנות בוקר — את הזנב הארוך של המערכת. המפרט אינו ממוצע אלא התפלגות.
מתרגמים את הלוג ל-Hurl ומקבעים את הפונקציונליות
ברגע שהלוג קיים, השאר מכני. מכניסים את זוגות ה-request/response של החודש לכלי, ומתרגמים כל זוג לבלוק Hurl. מאות קבצי ה-Hurl שנשפכים כך הם כבר ה-characterization suite — רשת ביטחון שצילמה בשלמותה את ההתנהגות הנוכחית של המורשת. לא קראתם שורת קוד אחת. קראתם רק את התעבורה שזרמה.
נצביע מראש על נקודה אחת שבה נוטים להסס. “בלוג יש מידע אישי, תשלומים וטוקנים — מותר לצלם את זה לבדיקה?”
מותר. ליתר דיוק, אין צורך לצלם. השיטה הזו ממילא אינה זקוקה לערכים. מה שה-characterization test מקבע אינו הערך אלא ההתנהגות.
HTTP 201
[Asserts]
jsonpath "$.order_id" exists
jsonpath "$.total" == 49800
מה שחשוב כאן כמפרט אינו המספר 49800, אלא המבנה: “השדה total קיים כמספר שלם, ומחושב כך עבור קלט נתון”. גם אם תמסכו את הערך או תחליפו אותו בנתונים סינתטיים, ערכו של המפרט כמעט אינו נפגע. capture → מיסוך → יצירת Hurl, כל הצינור הזה רץ בתוך התשתית שלכם. ה-raw log לעולם אינו יוצא לשום מקום. נותר רק מפרט שהערכים בו מוסתרים, חוזה ששומר על המבנה בלבד. העובדה שאין צורך לשלוח את הלוג החוצה אינה ויתור אבטחתי אלא מהות הגישה הזו — שכן ממילא די לצלם את ההתנהגות בלבד.
אם תריצו את ה-Hurl שנוצר פעם אחת על ה-staging, המעבר/הכישלון מתבררים על המקום. אם כל הנורות הירוקות נדלקו, כעת אפשר להתחיל בריפקטורינג. אומרים לסוכן להפוך את הקוד כאוות נפשו, והיכן הוא נשבר — Hurl רואה.
סולם שמניחים בלי קוד
לכן הערך האמיתי של הגישה הזו אינו “כותבים בדיקות מהר”. הערך האמיתי הוא זה:
- מתחילים בלי לקרוא את הקוד — המחבר המקורי עזב ואין תיעוד, אבל רשת הביטחון נפרסת מעצם התעבורה שזרמה. משיגים את הזכות לגעת בקוד עוד לפני שמבינים אותו.
- התוצר ניתן לאימות מיידי — מריצים את ה-Hurl שנוצר על ה-staging ומקבלים pass/fail על המקום. לא “כנראה יעבוד” אלא “כעת 327 מתוך 327 עוברות”.
- הנתונים אינם חוצים את הגדר — מ-capture ועד יצירת Hurl, הכול נגמר בתוך התשתית שלי. ככל שהתעשייה מפוקחת יותר, היכולת להתחיל בלי לשלוח שום דבר החוצה היא מכרעת.
הגרף הראשון של מודרניזציית מורשת נעצר בדרך כלל על המצוק “אף אחד לא יודע מה ההתנהגות הנוכחית”. תעבורה → Hurl מניח על אותו מצוק סולם. כדי להניח את הסולם אין צורך בקוד. די בתעבורה שזרמה — וגם אותה אפשר להשאיר כמות שהיא בתוך הגדר.
הזרימה כבר כתבה את המפרט
אנו מתאמצים לכתוב מפרט בנפרד. כותבים OpenAPI ביד, מתארים את ההתנהגות בוויקי, וכשהם נסתרים מן הקוד אנו קוראים לזה drift ומתאוננים.
אבל מערכת חיה כתבה את המפרט שלה בעצמה בכל רגע. בכל פעם שבקשה נכנסת ותגובה יוצאת, זוהי שורה אחת של תיאור עצמי: “אני מערכת כזו”. קובץ הלוג הוא אותה אוטוביוגרפיה שהצטברה במשך חודש.
אנחנו פשוט לא קראנו אותה.
למורשת אין חוסר תיעוד. התיעוד נמצא בתוך ה-access log, רק שהפורמט שלו לא נוח לקריאה אנושית. כשמתרגמים אותו ל-Hurl, הוא הופך למפרט שאפשר להריץ, לחוזה שהמכונה פוסקת עליו.
התיעוד משקר. התעבורה אינה משקרת.
מאמרים קשורים
- Hurl עוצר את הדריפט — כיצד מצהירים על חוזה HTTP בטקסט פשוט ונועלים אותו ב-CI. אם המאמר הזה הוא “תעבורה → Hurl”, זה “נעילת דריפט באמצעות Hurl”.
- tsma — קו ההגנה של קוד המורשת מפני רגרסיה — הגבול הפנימי (רמת הפונקציה) של רשת הביטחון הכפולה. אם Hurl הוא הגבול החיצוני, tsma הוא הפנימי.
- Agent Operable Codebase — צינור תלת-שלבי שמרים מורשת לקוד שסוכן יכול לעבוד עליו.
- מדוע סוכני קוד עובדים ומדוע הם נשברים — מבנה ה-Symbolic Feedback Loop.
- אילוצים הם חוזים — בדיקה כחוזה שניתן לאמת ולאכוף.
- כיצד מצילים vibe coding שקרס — שיעור מעשי לאבחון מורשת באמצעות characterization testing, נעילתה, תיקונה, חילוצה והמרתה.
לקריאה נוספת
- Michael Feathers, “Characterization Testing” — מאמרו של מטבע המונח. “ברגע שתוכנה נכנסת לייצור, היא עצמה הופכת למפרט (it becomes its own specification).” כמעט אותה תזה ככותרת המאמר הזה.
- מדריך Hurl הרשמי, “Your First Hurl File” — מ-
GET / HTTP 200ועד מצב--test. מבוא שמכניס ליד את ההבנה ששורה אחת של טקסט פשוט היא כבר בדיקה. - GitHub Engineering, “Scientist: Measure Twice, Cut Once” — ספרייה שמריצה בו-זמנית את קוד המורשת (control) ואת הקוד החדש (candidate) בייצור ומשווה את התוצאות. “רק ההתנהגות האמיתית היא המפרט האמיתי.”
- Twitter Diffy (סיכום InfoQ) — proxy ששולח את אותה בקשה לשירות החדש והישן ותופס כרגרסיה רק את ההבדל בתגובות. תקדים קלאסי ל"מקבעים התנהגות בלי לכתוב בדיקות".
- GoReplay — כלי שלוכד תעבורת HTTP חיה מממשק הרשת ומנגן אותה מחדש ל-staging. מימוש מייצג ל"תעבורת ייצור כקלט לבדיקה".
- Nicolas Carlo, “Characterization vs Approval Tests” — מסדר שלושה מונחים לאותה טכניקה למעשה, ומדגיש את תפקיד ה-“Printer” שמנקה מידע רגיש מן הפלט.
- Pact — consumer-driven contract testing. גישת “חוזה מפורש” בניגוד לקיבוע מן התעבורה. ראייה של שתי הגישות יחד יוצרת איזון.
מקורות / ביסוס
מושגים וכלים מרכזיים
- Michael Feathers. Working Effectively with Legacy Code. Prentice Hall, 2004. — מקור המושג characterization test. “לקבע לא את מה שהקוד אמור לעשות נכון אלא את מה שהוא עושה כעת.”
- פרויקט Hurl (hurl.dev) — פורמט בדיקת בקשה/תגובת HTTP בטקסט פשוט. שולב כאחד מ-10 ה-SSOT של yongol.
- הוכחת היתכנות עם 527 פונקציות tsma — ratchet ברמת הפונקציה (tsma).
שולפים בדיקות מן התעבורה וההרצה (carving / record-replay)
- Elbaum, Chin, Dwyer, Jorde (2009). “Carving and Replaying Differential Unit Test Cases from System Test Cases.” IEEE TSE 35(1). — היסוד האקדמי ל-differential unit test, שמקליט (record) הרצת מערכת ומנגן אותה מחדש (replay) ברמת היחידה.
- צוות ההנדסה של Meta (2024). “Observation-based Unit Test Generation at Meta.” FSE 2024, arXiv:2402.06111. — carving של בדיקות מערכי תצפית של הרצת אפליקציה. 9.6 מיליון הרצות ב-CI, זיהוי 5,702 פגמים. הוכחת היתכנות בקנה מידה תעשייתי ל"תצפית היא בדיקה".
מצלמים את ההתנהגות הנוכחית (snapshot / golden master)
- Fujita, Kashiwa, Lin, Iida (2023). “An Empirical Study on the Use of Snapshot Testing.” ICSME 2023. — הוכחת אימוץ של בדיקת snapshot (= golden master/characterization). “לזהות שינוי על ידי קיבוע הפלט הנוכחי, לא הנכונות.”
רשת ביטחון לריפקטורינג
- Kim, Zimmermann, Nagappan (2014). “An Empirical Study of Refactoring Challenges and Benefits at Microsoft.” IEEE TSE 40(7). — הוכחה שבלי בדיקות שמבטיחות שימור התנהגות, ריפקטורינג הוא עלות וסיכון.
- Yoo, Harman (2012). “Regression Testing Minimization, Selection and Prioritization: A Survey.” STVR 22(2). — בדיקת רגרסיה = ההגדרה התקנית ל"ביטחון שהשינוי אינו פוגע בהתנהגות הקיימת".
ההתפלגות בשימוש אמיתי היא סדר העדיפויות
- John D. Musa (1993). “Operational Profiles in Software-Reliability Engineering.” IEEE Software 10(2). — אם מחלקים את הבדיקות לפי תדירות שימוש, גם אם מפסיקים מטעמי לוח זמנים, הפונקציות הנפוצות ביותר נבדקות הכי הרבה. היסוד הקלאסי ל"התפלגות תעבורה במקום הטיית happy path".
מדוע המכונה צריכה לפסוק (LLM אינו שופט אלא מבצע)
Huang, Chen, Mishra, et al. (2024). “Large Language Models Cannot Self-Correct Reasoning Yet.” ICLR 2024, arXiv:2310.01798. — בלי משוב חיצוני, LLM אינו מסוגל לתקן את ההיגיון שלו. הסיבה לצורך במאמת חיצוני דטרמיניסטי.
Sharma, Tong, et al. (2024). “Towards Understanding Sycophancy in Language Models.” ICLR 2024, arXiv:2310.13548. — RLHF מלמד תאימות ובכך מערער את אמינות הפסיקה העצמית של ה-LLM.
תמונת שער: נוצרה על ידי AI (Google Gemini)