 Image: AI generated
Image: AI generated
Une personne intelligente n’est pas forcément un bon pédagogue
Quand on demande à Opus 4.8 de refactorer du code, le résultat est impressionnant. Il dénoue des graphes de dépendances complexes d’un seul coup, traite les cas limites de manière préventive et écrit des tests sans faille. Mais quand on lui demande d’expliquer le résultat, les problèmes commencent. Il parle comme un expert s’adressant à un autre expert. Il présuppose un savoir partagé, omet les raisons de ses décisions clés et maintient un niveau d’abstraction inutilement élevé.
Quand on pose la même question à Opus 4.6, c’est l’inverse. Il estime bien ce que l’on pourrait ignorer. Il choisit ses analogies, décompose les étapes et pose d’abord le contexte. Mais quand la difficulté de raisonnement augmente, il peine là où 4.8 résout le problème du premier coup.
En une phrase : Opus 4.8 est intelligent mais s’exprime de manière complexe ; Opus 4.6 explique clairement mais ses capacités de raisonnement sont inférieures.
Ce n’est pas un défaut. Comprendre pourquoi, et comment transformer cette différence en avantage structurel, voilà le sujet de cet article.
La malédiction du savoir s’applique aussi aux LLM
En 1989, les psychologues Camerer, Loewenstein et Weber l’ont prouvé expérimentalement : plus une personne détient d’informations, moins elle parvient à considérer que son interlocuteur ne les possède pas. Ce phénomène, appelé « malédiction du savoir » (Curse of Knowledge), est un biais cognitif confirmé de manière répétée en sciences de l’éducation, en économie et en conception UX.
Oliver Wendell Holmes a dit : « Je ne donnerais pas un sou pour la simplicité en deçà de la complexité. Mais je donnerais ma vie pour la simplicité au-delà de la complexité. » Une explication claire n’est pas simple parce qu’on ignore le sujet — elle n’est possible qu’après avoir traversé la complexité. Or, paradoxalement, tant qu’on est immergé dans la complexité, la capacité à s’exprimer simplement diminue.
Un article de l’EMNLP 2025 a montré que ce phénomène se manifeste également chez les grands modèles de raisonnement. Résultat paradoxal : plus un modèle possède de puissantes capacités de raisonnement, plus il est vulnérable à la malédiction du savoir. Un modèle qui raisonne en profondeur suppose implicitement que son interlocuteur peut suivre son processus de réflexion. C’est exactement le problème que rencontre un expert humain lorsqu’il explique quelque chose à un débutant.
C’est pourquoi il existe dans le monde deux types de rôles : celui qui pense en profondeur et celui qui transmet clairement. Le chercheur et le vulgarisateur scientifique. Le développeur senior et le tech lead. Le juge et l’avocat. Ce sont des compétences différentes. Il serait souhaitable qu’une même personne excelle dans les deux, mais c’est rare en pratique. C’est pourquoi les organisations séparent les rôles.
Il en va de même pour les LLM. Et Claude Code permet cette séparation en une seule ligne de configuration.
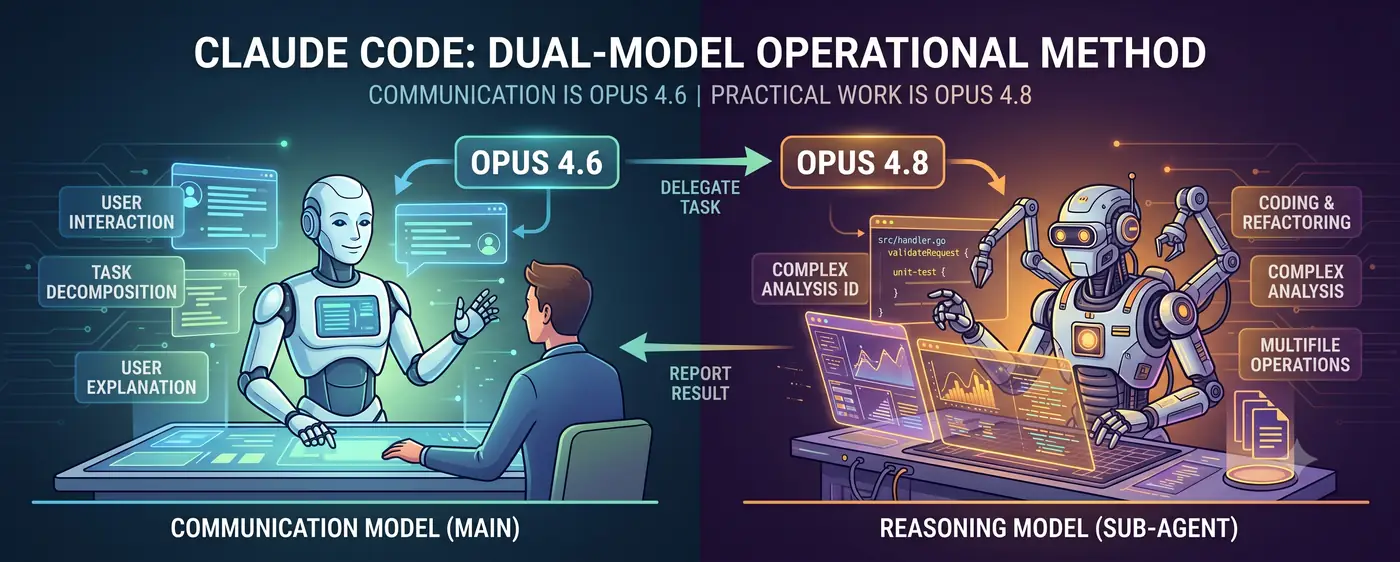
Modèle de communication + modèle de raisonnement
L’architecture centrale est simple.
Utilisateur ↔ Modèle de communication (principal) ↔ Modèle de raisonnement (subagent)
- Le modèle de communication (Opus 4.6) se place en première ligne du dialogue. Il comprend l’intention de l’utilisateur, décompose les tâches et rend compte des résultats dans un langage compréhensible.
- Le modèle de raisonnement (Opus 4.8) effectue le travail concret. Il reçoit par délégation, en tant que subagent, les tâches de raisonnement complexes : écriture de code, analyses difficiles, refactoring multi-fichiers.
L’utilisateur dialogue avec 4.6. Quand 4.6 juge que « la difficulté de raisonnement est trop élevée pour que je le fasse moi-même », il crée un subagent 4.8 et lui délègue la tâche. Quand 4.8 renvoie le résultat, 4.6 l’interprète et l’explique à l’utilisateur.
Cet article lui-même en est la preuve. C’est Opus 4.6 (principal) qui rédige ce texte, tandis que la recherche d’articles académiques et l’analyse de données de benchmarks qui sous-tendent cet article ont été réalisées par Opus 4.8 (subagent).
Ce que disent les benchmarks
Les données BenchLM révèlent en chiffres le profil de chaque modèle.
| Domaine | Opus 4.6 | Opus 4.8 | Avantage |
|---|---|---|---|
| Global | 86 | 93 | 4.8 |
| Codage | 64.4 | 76.4 | 4.8 |
| Tâches agent | 72.6 | 80.1 | 4.8 |
| Tâches de connaissances | 76.2 | 70.1 | 4.6 |
| Écriture créative | Avantage | - | 4.6 |
4.8 domine en codage et en tâches agent. Mais en transmission de connaissances et en écriture créative, 4.6 l’emporte. Les évaluations de l’API Claude notent aussi de manière récurrente que l’écriture de 4.8 sonne « plus artificielle (more AI-sounding) » que celle de 4.6. 4.8 raisonne avec précision, mais la capacité à restituer ce raisonnement de manière agréable à lire revient à 4.6.
Le prix des deux modèles est identique — 5 $ par million de tokens en entrée, 25 $ par million de tokens en sortie. Séparer les rôles n’augmente pas les coûts. Ce n’est pas une optimisation de coûts, c’est une optimisation de qualité pure.
Le routage de modèles est une ingénierie déjà prouvée
L’idée d’« utiliser deux modèles séparément » n’est pas nouvelle. C’est un domaine déjà établi dans le monde académique.
RouteLLM (ICLR 2025) a réduit les coûts de plus de moitié tout en maintenant la qualité, en routant dynamiquement les requêtes entre un modèle fort et un modèle faible. FrugalGPT (2023) a atteint des performances de niveau GPT-4 avec une réduction de coûts de 98 % grâce à un système de cascade de LLM. La conclusion commune de ces recherches est claire : un modèle faible bien orchestré bat souvent un modèle fort mal orchestré.
Anthropic utilise lui-même ce pattern. L’implémentation deep-research d’Anthropic suit le pattern orchestrateur-worker, et une configuration multi-agent a surpassé un Opus 4 mono-agent dans 90,2 % des cas. Des enquêtes montrent également qu’environ 80 % des systèmes multi-agent en production adoptent une architecture orchestrateur-worker.
Ce que je fais est la forme la plus simple de ce pattern. Ni routeur, ni cascade, ni optimisation de coûts. Simplement : un modèle optimisé pour la communication en première ligne, un modèle optimisé pour le raisonnement en coulisses. Le principe même de la séparation des rôles.
Comment le configurer
Mettre en place cette architecture dans Claude Code est simple.
Étape 1 : configurer le modèle principal
Lancez Claude Code avec Opus 4.6. Spécifiez claude-opus-4-6-20250610 comme modèle par défaut dans les paramètres, ou sélectionnez le modèle au lancement. C’est le modèle de communication qui dialogue avec l’utilisateur.
Étape 2 : surcharger le modèle du subagent
L’outil Agent de Claude Code prend en charge le paramètre model. Lors de la création d’un subagent, il suffit de surcharger le modèle avec opus (Opus 4.8).
Agent({
description: "Refactoring de code",
model: "opus",
prompt: "La fonction validateRequest dans src/handler.go..."
})
C’est tout. L’agent principal (4.6) dialogue avec l’utilisateur, et les tâches complexes sont déléguées au subagent (4.8).
Étape 3 : distinguer fork et fresh agent
Il existe deux types de subagent dans Claude Code.
- fork (
subagent_type: "fork") : hérite du contexte de la conversation en cours. Il partage le cache de prompt, ce qui réduit les coûts d’entrée jusqu’à 90 %. Cependant, un fork hérite obligatoirement du modèle parent, donc la surcharge de modèle ne s’applique pas. - fresh agent : démarre dans un nouveau contexte. La surcharge de modèle est possible. Il faut inclure directement le contexte nécessaire dans le prompt.
Par conséquent, pour utiliser le modèle de raisonnement (4.8), il faut créer un fresh agent. Le fork s’utilise quand on a besoin d’une exploration parallèle tout en conservant le modèle de communication (4.6).
Patterns pratiques
| Situation | Méthode | Raison |
|---|---|---|
| Écriture de code complexe | fresh agent + model: opus | Difficulté de raisonnement élevée |
| Refactoring multi-fichiers | fresh agent + model: opus + isolation: worktree | Raisonnement + isolation nécessaires |
| Recherche/exploration parallèle | fork (4.6 conservé) | Le partage de contexte est avantageux |
| Lecture/édition de fichiers simples | Principal (4.6) directement | Le surcoût de délégation est plus élevé |
| Recherche web/investigation | fresh agent + model: opus | Raisonnement précis nécessaire |
Jusqu’à 4-8 worktrees simultanés, le système reste stable. Au-delà, la revue des résultats devient le goulot d’étranglement.
Frictions connues
Ce n’est pas parfait. Deux limitations connues à ce jour.
Premièrement, le problème de fuite de la surcharge de modèle. La configuration model du subagent peut se propager aux sous-agents qu’il crée à son tour. Une utilisation non intentionnelle de modèle peut survenir ; il est donc pragmatique de limiter la profondeur des subagents à un seul niveau.
Deuxièmement, l’absence de configuration de modèle par type d’agent. Actuellement, Claude Code ne prend pas officiellement en charge la possibilité de pré-spécifier le modèle par type d’agent dans les paramètres du projet. Il faut spécifier le paramètre model à chaque appel Agent. Les demandes pour cette fonctionnalité sont actives dans la communauté.
Ces deux frictions se résoudront à mesure que Claude Code évolue. Dans l’état actuel, la surcharge manuelle suffit à tirer pleinement parti de la structure.
Le communicateur et le penseur sont deux rôles distincts
Au tribunal, le juge et l’avocat traitent du même droit, mais leurs rôles diffèrent. Le juge tranche. L’avocat explique au client ce que cette décision signifie. Si le juge lisait directement le jugement au client, celui-ci ne comprendrait pas. Si l’avocat rendait lui-même le jugement, les fondements seraient insuffisants. La séparation des rôles n’est pas une faiblesse du système, c’est une force.
Il en va de même en revue de code. La capacité d’un développeur senior à trouver un bug et celle de faire comprendre ce bug à un développeur junior sont deux choses distinctes. Il est rare qu’un ingénieur brillant soit aussi un excellent rédacteur technique. Les organisations le savent, c’est pourquoi elles séparent les rôles.
L’IA fonctionne pareil. La capacité de raisonnement et la capacité de communication sont deux axes différents. Et dans le processus d’entraînement actuel des modèles, ces deux axes ont tendance à entrer en conflit. Maximiser les performances de raisonnement rend la sortie compacte et technique ; maximiser les performances de communication réduit la profondeur du raisonnement.
Exiger d’un modèle unique qu’il excelle dans les deux revient à demander au juge de jouer aussi le rôle de l’avocat. C’est possible. Mais aucun des deux rôles ne sera optimal.
La séparation entre modèle de communication et modèle de raisonnement est un principe structurel qui reste valide quel que soit le changement de version. 4.6 et 4.8 ne sont que les choix concrets d’aujourd’hui. Si demain arrivent 5.0 et 5.2, on les déploie selon le même principe. Les modèles changent, mais le fait que « penser en profondeur » et « transmettre clairement » sont des rôles différents, lui, ne change pas.
Articles liés
- Ratchet Pattern — comment forcer un agent à aller jusqu’au bout
- Pourquoi votre boucle d’agent diverge
- Pourquoi le drift ne meurt jamais
Lectures complémentaires (externes)
- RouteLLM: Learning to Route LLMs with Preference Data — Framework de routage dynamique entre un modèle fort et un modèle faible selon la difficulté de la requête.
- Anthropic: How we built our multi-agent research system — Comment Anthropic a implémenté deep-research avec le pattern orchestrateur-worker.
Sources
- Camerer, C., Loewenstein, G. & Weber, M. (1989). The Curse of Knowledge in Economic Settings: An Experimental Analysis. Journal of Political Economy, 97(5), 1232-1254. DOI — Preuve expérimentale de la malédiction du savoir.
- Li, W. et al. (2025). Curse of Knowledge: Your Guidance and Provided Knowledge are biasing LLM Judges in Complex Evaluation. Findings of EMNLP 2025. arXiv — Découverte que les modèles de raisonnement puissants sont plus vulnérables à la malédiction du savoir.
- Ong, I. et al. (2025). RouteLLM: Learning to Route LLMs with Preference Data. ICLR 2025. arXiv — Framework d’apprentissage du routage de LLM à partir de données de préférence.