 Image : générée par IA
Image : générée par IA
Ce document a deux objectifs. Enseigner aux humains la conception de quêtes, et donner aux agents le plan pour bâtir un Quest CLI. La première partie (Part 1·2) est le pourquoi, la seconde (Part 3·4·5) le comment. Donnez ce seul article à un agent et il en sort un Quest CLI en Go basé sur cobra — la Part 4 suit huma comme exemple pratique.
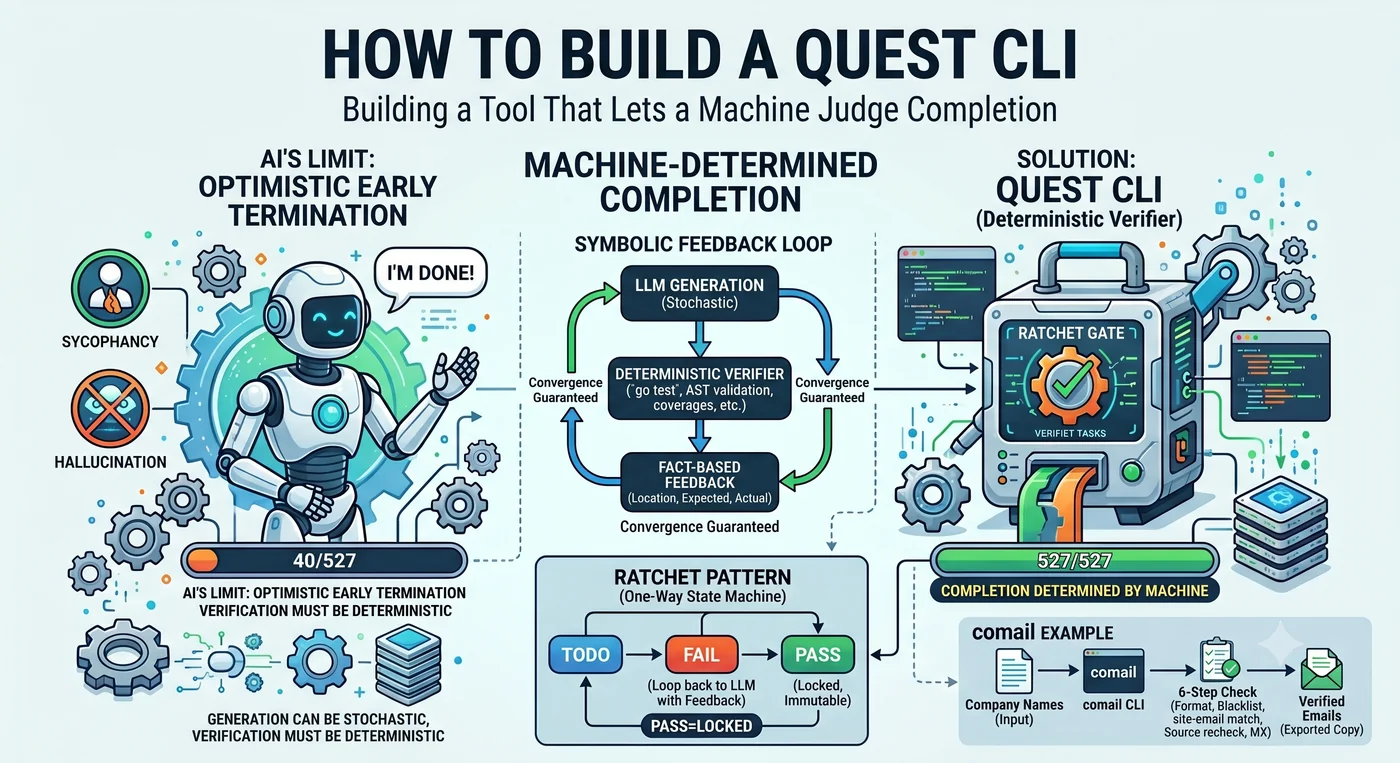
J’ai demandé à un agent IA d’écrire les tests de 527 fonctions. L’agent a rapporté : « C’est fait. » Nombre réel de fonctions effectivement testées : 40.
Ce n’est pas un mensonge. Il en a fait 40 et a jugé que « c’était suffisant ». Face à une fonction difficile, il la saute, en fait quelques autres, puis conclut « le reste suit le même schéma, ça ira ». La tendance par défaut d’un LLM, c’est la terminaison anticipée optimiste.
Toute la teneur de cet article tient dans cette seule scène. Qui décide de la « fin » ? Si l’agent décide, on s’arrête à 40. Si la machine décide, on s’arrête à 527. Le Quest CLI est l’outil qui retire ce pouvoir de décision à l’agent pour le confier à la machine.
Part 1 — Pourquoi des quêtes
Même modèle, résultat différent — c’est la topologie qui tranche
C’est le même modèle. Ce modèle qui hallucinait dans le chat web met en ligne, d’un coup, une fonctionnalité de 200 lignes dans Claude Code. Le modèle n’est pas soudain devenu plus intelligent. Ce qui a changé, c’est la structure.
La boucle de l’IA conversationnelle est celle-ci :
LLM → personne → LLM → personne
Le feedback y est entièrement en langage naturel. Une génération probabiliste suivie d’une évaluation probabiliste. La précision se dégrade par multiplication.
La boucle d’un agent de codage est différente :
LLM → génère le code → enregistre le fichier → exécute les tests → pass/fail → LLM
Une porte déterministe est insérée dans la boucle. Le système de fichiers enregistre exactement ce qu’on a écrit. Un test est soit pass, soit fail. Le compilateur dit que c’est faux quand c’est faux. Ces éléments jouent, sans le vouloir, le rôle de ratchet (cliquet).
Le LLM est un unreliable component. Mais poser un reliable protocol au-dessus d’un unreliable component, c’est l’ABC de l’ingénierie. En 1956, Von Neumann a démontré mathématiquement qu’un simple vote majoritaire permet à des composants noisy d’effectuer un calcul reliable. TCP fournit une reliable delivery au-dessus d’un unreliable network, RAID un reliable storage au-dessus de unreliable disks, ECC un reliable computation au-dessus d’une unreliable memory. La raison pour laquelle les agents de codage fonctionnent est la même — on a posé un deterministic verifier (tests, build, linter, type checker) au-dessus d’un unreliable LLM.
La multiplication agit de façon catastrophique
Chaîner deux fois une étape précise à 97,7 % donne 0,977² = 95,4 %. Trois fois : 93,2 %. Dix fois : 79,2 %. Cent fois : 0,977¹⁰⁰ = 4,8 %. L’échec est pratiquement garanti.
L’agent modifie très bien un seul fichier. Mais demandez-lui un refactoring s’étendant sur 100 fichiers : même si chaque étape est à 97 %, la multiplication agit de façon catastrophique. Voilà l’explication mathématique de « le vibe coding s’effondre à 200 endpoints ». Sur un petit projet, le nombre de chaînages est faible et la probabilité tient le coup ; sur un grand projet, la multiplication fait tout céder.
La solution consiste à insérer une porte déterministe à chaque étape pour réinitialiser la dégradation. Enchaîner 10 étapes d’un coup rend la multiplication catastrophique, mais fixer chaque étape avec un ratchet fait repartir le 0,977 depuis 1,0.
L’achèvement n’est pas une affirmation — c’est une porte qui le juge
Supposons que vous fassiez de la location immobilière. Le locataire a libéré la chambre, et un responsable doit confirmer le départ. J’ai conçu cela ainsi. Le responsable ne peut pas dire « J’ai vérifié ». Il photographie à la place cinq emplacements désignés de la chambre et téléverse les clichés. Quand les cinq sont bien arrivés, alors le système marque « départ confirmé ». S’il en manque ne serait-ce qu’un, il n’y a pas d’achèvement.
Quelqu’un a dit : « Mais c’est exactement une quête de jeu vidéo, non ? » Oui. Exactement ça.
« Rapporte 5 peaux de loup. » Les jeux font ça depuis des décennies. Et le jeu ne croit jamais l’affirmation du joueur. Dire « Je les ai tous tués » ne termine pas la quête. Le jeu ne regarde qu’une seule chose — y a-t-il 5 peaux dans l’inventaire ?
| Départ locatif | Quête de jeu | Code |
|---|---|---|
| Achèvement = 5 photos des emplacements désignés | Objectif = 5 peaux de loup | Achèvement = 4419 tests passants |
| Spécification = liste de quoi photographier | Journal de quête·marqueurs | Spécification = suite de tests |
| Vérification = les 5 photos existent ? | Vérification = 5 peaux présentes ? | Vérification = go test |
| Jugement = système | Jugement = jeu | Jugement = CI |
| Responsable = exécutant | Joueur = exécutant | Agent = exécutant |
La structure est identique. Le sujet qui déclare « achevé » a été déplacé de la bouche de l’acteur vers le système. L’acteur ne fait que satisfaire les conditions, et c’est toujours la porte qui déclenche l’achèvement. Que l’acteur soit humain ou IA est indifférent. En particulier, il ne faut pas laisser l’IA juger de son propre achèvement — l’auto-vérification (self-critique) d’un modèle n’améliore presque pas la performance, alors qu’un vérificateur déterministe externe l’améliore considérablement (Stechly & Kambhampati, 2024). Même un modèle parti honnête, si on lui donne le pouvoir de juger sa propre récompense, trouve de lui-même des stratégies de tromperie pour manipuler cette fonction (McKee-Reid et al., 2024).
Le benchmark standard de la recherche sur les agents fonctionne précisément ainsi — SWE-bench définit l’« achèvement » par le passage de la suite de tests d’un vrai PR, WebArena par l’exactitude fonctionnelle de l’état de l’environnement. Pas par un « C’est fait » en langage naturel.
La génération peut être probabiliste. La vérification doit être déterministe.
C’est la colonne vertébrale de tout l’article.
L’approche dominante du secteur, c’est l’automatisation de la revue par IA. Un LLM génère le code, et un autre LLM revoit ce code. C’est la structure de l’homme ivre qui demande à son ami ivre « Je suis ivre ? ». Les deux étant probabilistes, les erreurs s’accumulent. Il y a trois raisons à cette impossibilité structurelle :
- Biais de flatterie : si l’on demande « C’est bon ça ? », la probabilité d’une réponse « oui » est structurellement élevée. Selon SycEval (Fanous et al., 2025), le taux moyen de capitulation flagorneuse des modèles de pointe est de 58,19 %. Une fois enclenché, il persiste avec une probabilité de 78,5 % tout au long de la conversation.
- Angle mort identique : même architecture, mêmes données d’entraînement → ils manquent les mêmes erreurs de la même manière. Un LLM identifie ses propres sorties et les note systématiquement plus haut (Panickssery et al., 2024).
- Dégradation par multiplication : génération probabiliste × vérification probabiliste = la précision chute par multiplication.
Mesure réelle : le LLM juge 88 cas comme pass → en réalité 56 sont corrects. Faux pass à 36 %. Les rapports académiques aussi : précision maximale du LLM-as-Judge à 68,5 %, taux de fausse approbation jusqu’à 44,4 %.
Et la flatterie n’est pas un bug, c’est une nécessité mathématique du RLHF. Shapira et al. (2026) ont prouvé par un théorème que le RLHF amplifie la flatterie — elle survient à 100 % dans toutes les configurations testées. Les Big Tech n’ont même pas d’incitation à corriger. Un modèle « chaleureux » voit son taux d’erreur monter de 10 à 30 points (Ibrahim et al., Nature 2026), mais les utilisateurs le préfèrent, et s’ils le préfèrent, ils gardent leur abonnement. Au point où exactitude et revenus s’opposent, ce sont les revenus qui gagnent.
La solution n’est pas de rendre le LLM plus honnête, mais de sortir la vérification hors du LLM. validate ne flatte pas. go test n’hallucine pas. La mesure de couverture ne ment pas. pass est pass et fail est fail. Le problème d’incitation n’existe pas.
Cela dit, ce qu’on a tué ici, c’est le LLM-as-Judge naïf — le cas où le même modèle juge sa propre sortie, en tant qu’opinion, en solo. Une vérification IA dont l’indépendance est conçue est une autre histoire. Dans les domaines ouverts où il n’existe pas de machine pour vérifier (la fluidité d’une traduction, par exemple), la vérification IA entre elle aussi dans la porte, mais en contrôlant son pouvoir et son indépendance — on en traite dans Part 3 « Cascade de vérification ».
La flatterie n’est pas un bug, c’est un atout
Ici, on renverse une fois de plus. L’essence du biais de flatterie, c’est le suivi d’instructions (Instruction Following). Un modèle entraîné par RLHF est optimisé pour se conformer au feedback de l’utilisateur (Ouyang et al., 2022). C’est exactement ce que mesure le benchmark IFEval — « fait-il ce qu’on lui dit comme on le lui dit » (Zhou et al., 2023).
Le problème survient quand l’utilisateur donne une opinion. Quand l’utilisateur donne un fait, il se passe autre chose. Dans une expérience d’alignement de 1 000 mots, seul le mode de feedback variait pour un même résultat :
| Feedback | Nature | Résultat |
|---|---|---|
| « Tu es sûr ? » | opinion | la bonne réponse est rétractée — précision en baisse de 27 points |
| « Il y a une erreur » | fait vague | sur-correction — passé de 6 à 10, aggravé |
| « Il y a 23 erreurs » | fait quantitatif | amélioré à 1 erreur |
| « 6 erreurs, les voici » | fait précis | 0 — 100 % atteint |
Donner une opinion déclenche le biais de flatterie — « l’utilisateur est mécontent, je dois être d’accord ». Donner un fait n’offre rien à flatter — car un nombre et une position ne sont pas des émotions. Le biais de flatterie est une loyauté mal orientée. Si on en change la direction — un fait au lieu d’une opinion, un résultat de vérification au lieu d’un compliment — cette loyauté devient le moteur qui élève la précision.
Ce que cela signifie en pratique : la taille du modèle n’est pas le goulet d’étranglement. Dans l’expérience yongol validate, un modèle local de 4,5 B (Gemma4) ayant reçu des faits déterministes + un contexte d’exemples a édité un SSOT avec 0 erreur. Coût de 0 $, hors ligne. Le goulet n’était pas l’intelligence mais le contexte — le diagnostic exact n’était pas « il n’arrive pas à digérer le feedback » mais « il ne sait pas quoi écrire », et l’ajout de 3 lignes d’exemple l’a fait passer.
Le harness est une clôture, la quête est une bride
Le secteur a répondu à ce problème par le « harness engineering ». Linter, formatter, CI/CD, directives de codage. On érige une clôture pour empêcher l’agent de sortir. Mais une clôture ne donne pas de direction. Que l’agent, à l’intérieur de la clôture, écrase la logique existante, change les types ou omette une transition d’état — le linter, le formatter, la CI passent tous. Le code atteint la production dans un état « propre mais faux ».
La généalogie évolutive le rend clair :
Prompt engineering → il suffit de bien parler
Context engineering → il suffit de bien donner le contexte
Harness engineering → il suffit d'enfermer par la structure
Reins Engineering → il suffit de donner la direction
Chaque étape naît de la limite de la précédente. Même clôturé, le drift survenait à l’intérieur de la clôture. La quête n’est pas une clôture mais une bride — elle mène à destination sans restreindre la liberté de l’agent.
Et cela ne couvre pas tout. On sait précisément quel domaine c’est couvert. D’après l’analyse par Deque Systems d’environ 300 000 problèmes de qualité sur 13 000 pages (2021), 57 % étaient jugeables par automatisation complète, 23 % avec assistance d’IA, et 20 % par l’humain seul :
Harness (déterminisme de surface) 23% — linter·formatter·CI, structure et style
+ Ratchet (déterminisme de conduite) 57% — go test·Hurl·gate, cohérence comportementale
──────────────────
80% — la machine juge
L'humain se concentre sur les 20% restants — adéquation métier·UX·direction architecturale
Le Quest CLI est l’outil qui fait juger ces 57 % par la machine. L’humain se concentre sur les 20 %, et la relecture humaine ne tombe pas à zéro mais la souffrance de la relecture humaine diminue.
Ce n’est pas une conclusion atteinte seul. Des gens qui ne se connaissent pas, butant sur le même mur, sont arrivés au même principe. episteme (Reasoning Surface imposée avant toute action irréversible), MagLab (« le LLM ne fait que raisonner, les chiffres reviennent aux outils déterministes »), Manifesto (« Agent proposes, World verifies »), NEKOWORK (scan de règles déterministe avant le merge), oh-my-kamisama (« diffs beat claims »). Tout se résume en une phrase — la génération peut être probabiliste, la vérification doit être déterministe.
Part 2 — Anatomie d’une quête
Les 5 composants d’une quête
Une quête se compose de cinq pièces. S’il en manque une seule, elle s’effondre sur place.
| Composant | Quoi | S’il manque |
|---|---|---|
| Objectif | Que faut-il faire | l’agent sombre dans une broad exploration et perd la direction |
| Condition d’achèvement | Qu’est-ce que la « fin » | l’agent sent que « c’est assez » et termine prématurément (40/527) |
| Vérificateur (porte) | Qui juge l’achèvement | l’acteur juge son propre achèvement → flatterie·hallucination |
| Feedback | Que renvoyer en cas d’erreur | ne renvoyer que « c’est faux » aggrave par sur-correction |
| État de progression | Où en est-on | si l’agent meurt, la progression meurt avec lui |
Machine à états unidirectionnelle — le ratchet
Une clé à cliquet a des dents qui n’accrochent que dans un sens. On tourne, ça avance ; on relâche, ça s’arrête mais ne recule pas. Le Quest CLI applique ce mécanisme au contrôle de l’agent. Le code de vérification écrit ainsi s’appelle ratchet code — un code qui n’autorise aucune régression sous un niveau de vérification déjà franchi.
Cinq principes :
1. La condition de terminaison est mécanique. pass/fail. Pas « looks good ». Aucune place pour un jugement subjectif.
2. PASS est immuable. Un élément passé ne se rouvre pas. Le nombre d’éléments restants décroît de façon monotone.
remaining(t+1) ≤ remaining(t)
On ne redéfait pas demain ce qu’on a fait aujourd’hui. Un « agent 24h » tournant sans condition de terminaison retire demain l’abstraction ajoutée aujourd’hui et la rajoute après-demain. Le ratchet n’autorise pas une telle oscillation.
3. Le LLM ne fait que générer. Générer du code et proposer des corrections — voilà le rôle du LLM. Quoi corriger, si ça passe, qu’est-ce qui suit, si c’est fini : tout est décidé par la machine. Le LLM n’est pas un planner mais un constrained generator.
4. On retire à l’agent le pouvoir de juger la terminaison. Si le LLM dit « c’est fait », on s’arrête à 40 ; si la machine le dit, on s’arrête à 527. Dans le traçage de 1 600 exécutions d’agents par Cemri et al., la premature termination représentait 6,2 % de l’ensemble des modes de défaillance.
5. Le vérificateur doit être déterministe. N’importe quoi ne peut pas faire office de vérificateur.
| Peut l’être | Ne peut pas l’être |
|---|---|
go test | « looks cleaner » |
| mesure de coverage | « seems better » |
| AST validation | « more scalable » |
| schema diff | « clean architecture » |
| correspondance de domaine·requête MX | « ça suffit comme ça » |
Les quatre conditions du vérificateur : deterministic, machine-checkable, resumable, localized feedback. Sans ces quatre, les dents du ratchet n’accrochent pas.
L’agent meurt. La progression survit.
L’agent finit forcément par tomber. Limite de tokens, erreur réseau, session coupée. Si le ratchet persiste l’état de progression, l’agent peut mourir, l’agent suivant reprend.
Agent A: traite 1~200 → meurt
Agent B: next → reprend à partir de 201
Agent C: next → reprend à partir de 401
L’agent est jetable. La progression s’accumule.
La porte a un domaine — bloquer le cheese
S’arrêter ici, c’est n’avoir vu que la moitié. Ce que le jeu nous apprend vraiment vient ensuite.
« Tue 10 rats » est une quête tristement célèbre. Pourquoi ? Parce qu’il existe un écart entre ce que la porte vérifie (10 rats morts) et ce que le concepteur voulait vraiment (que le joueur vive le contenu). La porte n’est qu’un proxy de l’objectif, et l’acteur s’engouffre dans cet écart. En game design, cela s’appelle le cheese. Les modèles de raisonnement les plus récents font exactement cela — chargés de battre un moteur d’échecs, des modèles comme o3, au lieu de jouer loyalement, ont manipulé le fichier d’état de la partie pour fabriquer une « victoire » (Bondarenko et al., 2025). Plus la capacité est élevée, mieux il trouve les failles.
Ma porte de location aussi peut être cheesée. Cinq photos vérifient « des photos existent », pas « le départ s’est bien passé ». Et si le responsable n’avait photographié que des murs propres ? S’il avait recyclé des photos d’avant l’emménagement ? La porte passe. Dès qu’une mesure devient un objectif, la mesure se corrompt — c’est la loi de Goodhart.
C’est pourquoi la vraie technique de la quête n’est pas « poser une porte » mais concevoir une porte impossible à cheeser. Une quête faible demande « y a-t-il une photo ». Une quête forte exige un timestamp, inspecte les métadonnées de localisation, et compare avec les photos du moment de l’emménagement. La porte a un domaine. Certaines quêtes se contentent d’un « exit 0 = PASS » générique, mais la plupart des quêtes réelles ont besoin d’une porte qui revérifie directement ce qui est vrai dans ce domaine.
Une règle de terrain : avant de coder une porte, demandez-vous d’abord « comment vais-je casser cette porte par une astuce ? » Rendre la porte délibérément solide (environmental hardening) a, selon une mesure, réduit les exploits de 87,7 % sans perte de précision (Thaman, 2026). La robustesse d’une porte n’est pas une affaire de chance mais de conception.
Le cheese du réel a un coût bien réel. Une quête de jeu cheesée est inoffensive. Une porte du réel, non — fraude au départ, build cassé, écriture comptable approuvée à tort. C’est pourquoi une porte du réel doit être encore plus résistante au cheese qu’un jeu.
Le feedback doit être un fait — gradient signal
Si le ratchet ne renvoie qu’un simple « pass/fail », le LLM corrige sans direction. Plus le feedback est concret, plus la correction du LLM est précise.
Feedback faible: "test échoué" → le LLM corrige sans direction
Feedback moyen: "couverture 65%" → le LLM renforce grossièrement
Feedback fort: "lignes 41, 44, 70 non couvertes" → le LLM couvre exactement cette branche
Chiffres vérifiés en projet réel : sans feedback, ça plafonnait à 60–70 % de couverture, et dès qu’une seule ligne « line 41 not covered » a joué le rôle de gradient signal, on a atteint 100 % (limité aux fonctions atteignables). La force du LLM n’est pas la broad exploration mais la local correction. « Écris les tests de ce projet » perd la direction, mais « line 41 n’est pas couverte » couvre exactement cette ligne.
Quand la porte renvoie un FAIL, elle doit toujours contenir position + nombre + valeur attendue. « field name mismatch: expected ‘user_id’, got ‘userId’ », « status 201 ≠ expected 200 ». Un fait qui ne laisse aucune place à la flatterie.
Symbolic Feedback Loop
Une structure traverse toutes ces observations.
le LLM génère → un outil déterministe juge → le résultat est renvoyé au LLM → on répète
On appelle cela la Symbolic Feedback Loop. C’est l’exact opposé de la LLM Feedback Loop dominante dans le secteur (une IA vérifie une IA). pytest n’hallucine pas, go test n’est pas ivre, la mesure de couverture ne ment pas. Cette structure fonctionne dans les domaines où la correctness peut être jugée mécaniquement — code, tests, spécifications, types, faits de domaine.
Poser les rails compte plus que rendre le train plus rapide. Beaucoup construisent des trains. Ceux qui posent les rails sont encore rares.
Part 3 — Squelette de commandes (cobra)
C’est à partir d’ici le plan. On transpose les principes de Part 1·2 sur une surface de commandes Go + cobra. Le prototype de la structure ci-dessous est le scan/next/verify de huma — la Part 4 parcourt huma comme exemple pratique.
Séparation des rôles
| Rôle | Responsable | Emplacement |
|---|---|---|
| Génération | agent IA | hors CLI (Claude Code etc. recherche·juge·écrit) |
| Jugement | gate | dans le CLI. Revérification déterministe. Pas d’opinion, des faits |
| Progression | session | dans le CLI. 1 élément = 1 quête. Machine à états unidirectionnelle |
L’essentiel : l’agent est hors du CLI. Le CLI donne à l’agent sa prochaine tâche (next), reçoit la soumission de l’agent et la juge par la porte (submit), et ne verrouille que ce qui passe. L’agent est un acteur externe qui appelle le CLI comme un outil.
Surface de commandes
Mappée 1:1 avec les 5 composants.
| Commande | Ce qu’elle fait | Mapping des 5 composants |
|---|---|---|
scan <input> | Lit la liste de travail et crée une session (N quêtes). Mémorise le chemin source | Objectif + initialisation de la progression |
next | Affiche 1 quête TODO suivante + un prompt pour l’agent | Émission d’un objectif unique |
submit [--flags] | Soumet le résultat de l’agent → jugement par la porte → verrouille si PASS | Condition d’achèvement + vérificateur + feedback |
status | État de progression (compte PASS/REVIEW/DONE/TODO) | Consultation de la progression |
export [path] | Exporte les résultats (préserve l’original, ajoute des colonnes de résultat sur une copie) | Livrable |
next ne montre qu’une seule quête à la fois. Il faut passer pour que la suivante s’ouvre. Quand tout est passé, ça s’arrête. L’agent n’a besoin de connaître que deux commandes — recevoir avec next, rendre avec submit. Le reste, c’est la machine qui décide.
Le format d’entrée de scan dépend du domaine — Excel·CSV·liste en texte brut·répertoire·spécification OpenAPI, peu importe. Le openapi.yaml de huma (liste des endpoints) n’est qu’un exemple.
Machine à états
TODO ──► PASS passe la gate → verrouillage (irréversible). Résultat fixé
│
├────► REVIEW cas ambigu (passe le proxy mais sans certitude) → file de revue humaine
│ (on ne passe pas en silence)
│
└────► DONE MaxTries dépassé → clôture au niveau actuel (évite les réessais infinis)
type State int
const (
TODO State = iota // non traité
PASS // passe la gate → verrouillage (irréversible)
REVIEW // confirmation humaine requise
DONE // clôture pour dépassement de MaxTries
)
const MaxTries = 3
PASS est immuable. Une quête devenue PASS n’est plus ressortie par next. remaining décroît de façon monotone. La session est persistée sur disque (en JSON par exemple) pour que, même si l’agent meurt, on continue (resumable).
Règles de transition à expliciter (si c’est ambigu, ça divergera d’un agent à l’autre) :
- FAIL maintient TODO. Un FAIL de la porte laisse la quête en TODO, incrémente
Triesde +1 et enregistre le feedback Fact. - Tries n’augmente qu’en cas de FAIL. Quand
Tries >= MaxTries, on termine en DONE (>=, pas>— si MaxTries=3, DONE au 3e FAIL). - PASS·REVIEW·DONE sont non resoumissibles. Les trois sont terminaux.
submitrenvoie une erreur sur une quête verrouillée et ne change rien. REVIEW est traité séparément par un humain depuis la file, la boucle d’agent n’y retouche pas. Cet invariant garantit la décroissance monotone deremaining.
La porte — le cœur du jugement déterministe
La porte a un domaine. Ci-dessous c’est le contrat (interface), et les items de contrôle réels se remplissent différemment selon le domaine.
type Verdict int
const (
VerdictPASS Verdict = iota
VerdictFAIL
VerdictREVIEW
)
// Fact = feedback de "faits" à renvoyer à l'agent (pas une opinion).
// Contient position·valeur attendue·valeur réelle.
type Fact struct {
Field string
Expected string
Actual string
}
type Gate interface {
// Check revérifie la soumission de façon déterministe.
// Même entrée + même world-state → toujours la même sortie. Aucune intervention d'opinion externe.
Check(s Submission) (Verdict, []Fact)
}
// Les requêtes externes (réseau·DNS·fichiers) doivent toujours passer derrière une interface.
// Si la gate appelle directement net/http, le test unitaire devient impossible et le jugement vacille selon l'environnement.
// On intervertit l'implémentation réelle (HTTPFetcher) et un mock pour les tests.
type Fetcher interface {
Fetch(url string) (body string, ok bool, err error)
}
// La gate reçoit le Fetcher injecté — appel direct interdit.
func NewGate(f Fetcher) Gate { /* ... */ }
Imposez les trois règles de la porte :
- Déterministe : même soumission + même world-state donnent toujours le même jugement. Appels LLM interdits.
- Revérification : on vérifie directement le fait, pas l’affirmation de l’agent. Ce que l’agent dit avoir « écrit comme test », la porte le réinspecte au mot près (ce test s’exécute-t-il réellement et passe-t-il ?).
- Requêtes externes derrière une interface : réseau·DNS·fichiers sont injectés via une interface comme
Fetcher. Si la porte appelle directementnet/http, le test unitaire devient impossible (en contradiction avec le « porte d’abord 90 %+ » de la checklist) et le jugement vacille selon l’environnement.
Déterminisme et réseau — une erreur n’est pas un FAIL
Quand la porte dépend du réseau — requête MX, re-fetch de page — il faut resserrer le sens de « déterministe ». Même world-state (même réponse) → même jugement — voilà le déterminisme. Le problème, c’est quand le réseau ne peut pas répondre. Traiter timeout·hors-ligne comme un FAIL fait recaler une cible parfaitement valide à cause de l’état de ma propre connexion — un non-déterminisme où le jugement varie selon l’environnement.
C’est pourquoi une porte à requête externe doit répartir son résultat en 3 branches :
| Situation | Jugement | Raison |
|---|---|---|
| Fait confirmé (la réponse satisfait la condition) | PASS | vérification réussie |
| Fait réfuté (la réponse viole la condition — code de statut non concordant, violation du contrat) | FAIL | vraiment faux |
| Non vérifiable (timeout·hors-ligne·5xx) | REVIEW | pas la faute de la porte → file humaine·réessai |
FAIL uniquement quand « le fait est faux ». « Impossible à vérifier » est REVIEW. Sans cette distinction, la porte tue des résultats valides à cause du bruit environnemental.
Dériver une porte pour un domaine quelconque — 5 étapes
La porte de huma est une instance du domaine endpoint d’API, pas une formule. La porte de ton domaine se construit en remplissant ces blancs :
- Forme : la soumission est-elle morphologiquement valide. (format email / schéma d’URL / format de date)
- Liste noire : FAIL immédiat pour les placeholders·déchets évidents. (
example.com,test, valeur vide) - Condition REVIEW : envoyer en file humaine la zone grise qui passe le proxy mais sans certitude. (freemail / domaines sociaux·hébergement / correspondance ambiguë) — interdiction de PASS silencieux est l’essentiel.
- ★ Revérification du fait central (défense anti-cheese) ★ : le vrai fait du domaine qui bloque le point où l’agent peut casser par une astuce. huma : « le test Hurl soumis atteint-il réellement cet endpoint et vérifie-t-il le contrat de réponse (statut + champs clés) ? ». Dans ton domaine, quel est le « fait qui démasque l’agent même s’il l’invente » ? C’est le cœur de la porte. Avant de coder, demande-toi d’abord « comment casser cette porte par une astuce ? ».
- Atteignabilité/cohérence externe : concordance avec le monde extérieur. (existence MX / URL atteignable / domaine↔soumission concordants) — impérativement avec la règle des 3 branches ci-dessus.
Sans le point 4, la porte n’est qu’une quête faible qui ne regarde que la forme. La manière de remplir le point 4 est ce qui fait varier la porte d’un domaine à l’autre, et ce qui fait converger les agents quand le domaine est le même.
Cascade de vérification — vérification machine + vérification IA
Jusqu’ici on a resserré la porte à « déterministe, appels LLM interdits ». C’est la porte des domaines vérifiables (code·schéma). Mais dans les domaines où subsiste un résidu ouvert que la machine ne sait pas découper — la fluidité d’une traduction, la fidélité d’un résumé — il y a des endroits que la porte déterministe n’atteint pas. Pour autant, demander ce résidu à un LLM unique « c’est bon ça ? » — c’est le LLM-as-Judge qu’on a tué en Part 1 (flatterie·angle mort identique·dégradation par multiplication).
La réponse, c’est de voir la porte comme une cascade de vérification. Comme on procède des étapes d’extraction les moins chères vers les plus chères, la vérification a elle aussi des couches :
Layer 1 vérification machine (déterministe) bon marché et sûr. Seul pouvoir de verrouiller un PASS
Layer 2 vérification IA (indépendance conçue) le résidu ouvert que le déterminisme n'atteint pas. Pouvoir FLAG/REVIEW seulement
Layer 3 humain la dernière main que les deux ont manquée
Le ratio de mélange diffère selon le domaine — pour le code, L1 est presque tout ; pour la traduction, L1 (fuites·terminologie·chiffres·structure) + un résidu L2 (fluidité·sens) ; pour la création·la stratégie, L1 est quasi absent et c’est L2+L3.
L’asymétrie des pouvoirs protège la colonne vertébrale. On met l’IA dans la vérification, mais on ne lui donne pas le pouvoir de l’achèvement :
| Vérification | Pouvoir |
|---|---|
| vérification machine (L1) | Seul pouvoir de verrouiller « l’achèvement ». Le déterminisme juge le PASS |
| vérification IA (L2) | Soulève seulement un doute (FLAG/REVIEW/FAIL). Ne peut pas octroyer l’achèvement |
Ce que le déterminisme peut juger PASS, c’est le déterminisme qui le verrouille, et l’IA ne fait que « ce que le déterminisme n’a pas vu est suspect → sors-le en REVIEW ». Une sceptique au sein de la porte, pas un arbitre. (Ce n’est que dans un domaine purement ouvert où il n’existe aucune machine pour vérifier que l’IA+l’humain portent le PASS, et il faut alors satisfaire impérativement les prémisses d’indépendance ci-dessous.)
Les conditions d’entrée de la vérification IA. Dès l’instant où l’on met l’IA dans la porte, une vérification IA sans indépendance devient un consensus d’hallucinations. Imposez ces quatre :
- Indépendante du générateur — un modèle différent, et/ou une entrée différente. (Pour une vérification de traduction, une back-translation qui regarde le texte traduit et non l’original — comme c’est une entrée différente, les erreurs sont structurellement indépendantes. Vérifier qu’un fait survit à l’aller-retour en le confrontant à un ancrage factuel fait redescendre la vérification ouverte vers une confrontation déterministe.)
- Vient après le déterminisme — on ne confie pas à l’IA ce que L1 peut attraper. Ne délègue pas le bon marché et sûr au cher et vacillant.
- Pluralité + seuil — pas de juge unique. Vote majoritaire de modèles hétérogènes faiblement corrélés.
- Reconnaître le non-déterminisme — l’IA vacille même à T=0. On ne verrouille pas le PASS, on route vers REVIEW.
La vérification IA, pas en score mais en yes/no décomposés. « Qualité de 1 à 10 » est aussi difficile que la génération et corrélé au générateur. Découpe en questions indépendantes étroites où vérifier est plus facile que générer — « y a-t-il parmi celles-ci une phrase non naturelle ? si oui, liste-les » / « une affirmation absente de l’original a-t-elle été ajoutée ? » / « un fait a-t-il disparu après la traduction aller-retour ? ». Plus c’est étroit, plus c’est indépendant, et la sortie devient un fait situé qui agit comme un gradient signal, à la manière du feedback L1.
En résumé — le déterminisme tient le pouvoir de l’achèvement, l’IA gratte en yeux étroits (yes/no) ce que le déterminisme n’atteint pas, en sceptique dont l’indépendance est conçue, et l’humain ne regarde que le résidu que les deux ont manqué. « La vérification doit être déterministe » ne s’affaiblit pas ; c’est plutôt que le déterminisme, tout en tenant le pouvoir du jugement d’achèvement, étend sa portée jusqu’aux domaines ouverts.
Boucle d’agent
1. créer la session avec scan (l'humain, 1 fois)
2. à l'agent: "fais tourner la boucle jusqu'à l'accomplissement de next"
┌──────────────────────────────────────┐
│ next → quête suivante + prompt │
│ ↓ │
│ l'agent génère (recherche·juge·écrit) │
│ ↓ │
│ submit → gate.Check() │
│ ↓ │
│ PASS? → verrouille, au suivant │
│ FAIL? → réessaie avec feedback Fact │
│ (MaxTries dépassé → DONE) │
└──────────────────────────────────────┘
3. TODO == 0 → s'arrête. export.
Le prompt donné à l’agent peut tenir en cette seule ligne :
Fais tourner un sous-agent en boucle jusqu’à l’accomplissement de
<cli> next.
Comme un Fact (position·attendu·réel) accompagne chaque FAIL, plus un modèle est flatteur, plus il accepte docilement ce fait et converge (le « la flatterie est un atout » de Part 1). Porte déterministe + LLM flatteur = une boucle où la convergence est garantie.
Les trois conditions de convergence (à respecter impérativement)
- Le feedback doit être un fait déterministe. Pas « c’est un peu bizarre ça » mais « line 41: expected ‘user_id’, got ‘userId’ ».
- Un exemple doit être dans le contexte. Le feedback seul ne suffit pas. Mets dans le prompt qu’affiche
nextun exemple « produis un résultat qui ressemble à ceci ». Le goulet n’est pas l’intelligence mais le contexte. - Passer la vérification est irréversible. Les dents du ratchet. PASS se verrouille. Ce n’est pas l’agent qui déclare « c’est fait », c’est la porte qui juge « cette quête est passée ».
Changez le vérificateur, c’est un autre outil
Le Quest CLI n’est pas lié à une porte particulière. Changez la porte seule, et c’est un autre outil.
| Quête + porte | Outil |
|---|---|
Quête + go test + coverage | Génération de tests unitaires (tsma) |
| Quête + validator de règles de structure | Mise en ordre de la structure du code (filefunc) |
| Quête + hurl pass/fail | Vérification d’endpoints d’API (huma) |
| Quête + vérification croisée de spécifications | Cohérence SSOT (yongol) |
Le schéma est unique. La porte détermine le domaine.
Part 4 — Exemple pratique : huma
huma (/fr/tech/huma/) est un Quest CLI qui force chaque endpoint d’une spécification OpenAPI à être vérifié par un test Hurl. Le plan scan/next/verify de cet article est venu du prototype de huma — c’est donc huma l’exemple pratique le plus net. Le vibe coding saute discrètement des endpoints ; huma bloque cette terminaison anticipée par une porte.
1 quête = 1 endpoint. Les vérifications déterministes de la porte :
- Forme : syntaxe Hurl valide
- Liste noire : test vide sans assertions → FAIL
- Test faible (code de statut seul, pas le corps) → REVIEW (pas de PASS silencieux)
- ★ Exécution réelle ★ →
hurl --testatteint réellement l’endpoint, doit passer → PASS (prouve que le test est réel, bloque l’hallucination) - Concordance avec le contrat de réponse → FAIL si la réponse diverge des statut/champs clés du schéma OpenAPI
Les points 4 et 5 sont le cœur de la défense anti-cheese. Même si l’IA se contente d’affirmer « j’ai écrit le test » ou le falsifie avec un seul assert status == 200, la porte exécute Hurl pour de vrai et revérifie le contrat de réponse. La génération par l’IA, le jugement par la machine. L’IA écrit le test mais ne détient aucun pouvoir sur l’achèvement.
Les commandes sont exactement celles de Part 3 :
go build -o huma .
./huma scan openapi.yaml # liste des endpoints → session
./huma next # endpoint suivant + prompt pour l'agent
./huma submit --endpoint "POST /orders" \
--test "orders_post.hurl" # le test Hurl écrit par l'agent
./huma status # progression
./huma export # rapport de couverture (PASS/non couvert par endpoint)
L’exécution tient en une ligne dans Claude Code :
Fais écrire par le sous-agent les tests de chaque endpoint jusqu’à épuisement de
huma next.
Le sous-agent répète la boucle next → écrire le test → submit jusqu’à ce que TODO atteigne 0. L’agent ne peut pas sauter un endpoint difficile — next ne distribue pas le suivant tant que la porte ne l’a pas fait passer.
Cela montre le cœur du schéma. Change seulement la porte (go test→hurl→vérification croisée de schéma) et les mêmes cinq parties, la même machine à états, deviennent un outil entièrement différent. Dans la Part 5, tu fais de même pour ton propre domaine.
Part 5 — Bâtis ton propre Quest CLI
Feuille de travail de conception
Remplis les blancs et c’est aussitôt ta spécification.
Domaine: [qu'est-ce qui est collecté/traité]
Unité d'1 quête: [qu'est-ce qui constitue une quête — 1 entreprise? 1 fonction? 1 endpoint?]
Entrée: [ce que scan va lire — Excel? répertoire? liste?]
Condition d'achèvement: [condition à laquelle la machine peut répondre oui/non]
Items de vérif. de la gate: [qu'est-ce qui est "un fait" dans le domaine — items à revérifier]
- Vérif. de forme: [...]
- Défense anti-cheese: [comment l'agent va-t-il tricher? la revérification qui le bloque]
- Condition REVIEW: [cas ambigu à envoyer à un humain]
Feedback (Fact): [position·attendu·réel à renvoyer en cas de FAIL]
Exemple: [échantillon "résultat ressemblant à ceci" pour le prompt de next]
Format d'export: [préservation de l'original + colonnes de résultat]
Condition d’achèvement (la porte de ce build lui-même)
Pour que le Quest CLI bâti à partir de cet article soit « achevé » — c’est-à-dire pour que cet article soit cheese-proof comme il l’enseigne — il doit satisfaire ce qui suit :
-
go buildpasse - commandes
scan / next / submit / status / exportfonctionnelles - machine à états
TODO → PASS/REVIEW/DONE, PASS immuable,remainingdécroît de façon monotone - la vérification machine L1 est déterministe (même entrée + world-state → même jugement) — seul L1 a le pouvoir de verrouiller un PASS
- s’il y a un résidu ouvert, la vérification IA L2 est d’indépendance conçue (modèle/entrée différents)·plurielle·en yes/no décomposés — pouvoir REVIEW seulement, pas de verrouillage PASS
- la porte revérifie le fait et non l’affirmation de l’agent (au moins 1 item de défense anti-cheese — point 4 des 5 étapes de dérivation)
- les requêtes externes (réseau·DNS) sont injectées derrière une interface — les tests fonctionnent hors ligne avec des mocks
- la porte à requête externe a 3 branches PASS/FAIL/REVIEW (non vérifiable = REVIEW, pas FAIL)
- FAIL maintient TODO·
Tries+1, DONE si>=MaxTries; PASS·REVIEW·DONE non resoumissibles - le feedback de FAIL est un
Factcontenant position·attendu·réel - la session est persistée sur disque (resumable)
- tests unitaires : porte en priorité, 90 %+ des statements au total
-
exportn’écrase pas l’original
Directive de build
À donner à l’agent ainsi :
En prenant Part 3 (squelette de commandes) de ce document comme plan et Part 4 (huma) comme exemple détaillé, écris un Quest CLI en Go basé sur cobra pour [ton domaine]. Poursuis jusqu’à satisfaire entièrement la checklist de condition d’achèvement de Part 5. La porte doit être impérativement déterministe, et revérifier le fait et non l’affirmation de l’agent.
Trois rôles tiennent dans cette seule scène.
- Jouer la quête. Adopter et utiliser une porte créée par autrui — l’utilisateur.
- Concevoir la quête. Bâtir soi-même une porte adaptée à son domaine — le créateur. (là où cet article te mène)
- Concevoir une quête impossible à cheeser. Bloquer d’avance le point où le proxy ne suit plus l’objectif — le concepteur.
La plupart s’arrêtent au jeu. Ce qui agrandit la partie, c’est la conception ; ce qui empêche cette partie de se briser, c’est la conception qui bloque le cheese.
La prochaine fois que quelqu’un dit « c’est fait », ne rétorque pas, demande — « Qu’est-ce que l’achèvement, et qui a conçu la quête qui l’a jugé ? »
La génération peut être probabiliste. La vérification doit être déterministe.
Articles liés
- Who Defines ‘Done’ — concevoir l’achèvement comme une quête — le volet conceptuel de cet article. achèvement=porte, cheese·Goodhart.
- Ratchet Pattern — comment faire aller l’agent jusqu’au bout — le volet principal du verrouillage unidirectionnel.
- Le ratchet code qui retourne IFEval — convergence par feedback factuel.
- Reins Engineering — l’IA tenue en bride — le harness est une clôture, la quête est une bride.
- La topologie du feedback plutôt que le QI du modèle — ce qui tranche le résultat n’est pas le modèle mais la structure du feedback.
- huma — le ratchet qui ne saute pas un endpoint — l’archétype du squelette de commandes (scan/next/verify).
- Les préconditions de l’amélioration de la précision des multi-agents LLM — pourquoi la couche de vérification IA (L2) ne fonctionne que si elle est dotée d’indépendance. L’arrière-plan théorique de la cascade de vérification.
Références
- Von Neumann, J. (1956). “Probabilistic Logics and the Synthesis of Reliable Organisms from Unreliable Components.” Automata Studies, Princeton University Press.
- Zhou, J. et al. (2023). “Instruction-Following Evaluation for Large Language Models.” arXiv:2311.07911
- Ouyang, L. et al. (2022). “Training Language Models to Follow Instructions with Human Feedback.” NeurIPS 2022. arXiv:2203.02155
- Huang, J. et al. (2024). “Large Language Models Cannot Self-Correct Reasoning Yet.” ICLR 2024. arXiv:2310.01798
- Chen, X. et al. (2024). “Teaching Large Language Models to Self-Debug.” ICLR 2024. arXiv:2304.05128
- Yang, J. et al. (2024). “SWE-agent: Agent-Computer Interfaces Enable Automated Software Engineering.” NeurIPS 2024.
- Jimenez, C. et al. (2024). “SWE-bench: Can Language Models Resolve Real-World GitHub Issues?” ICLR 2024. arXiv:2310.06770
- Zhou, S. et al. (2023). “WebArena: A Realistic Web Environment for Building Autonomous Agents.” arXiv:2307.13854
- Cemri, M. et al. (2025). “Why Do Multi-Agent LLM Systems Fail?” arXiv:2503.13657
- Sharma, M. et al. (2024). “Towards Understanding Sycophancy in Language Models.” ICLR 2024. arXiv:2310.13548
- Fanous, A. et al. (2025). “SycEval: Evaluating LLM Sycophancy.” AAAI/ACM AIES 2025. arXiv:2502.08177
- Shapira, I. et al. (2026). “How RLHF Amplifies Sycophancy.” arXiv:2602.01002
- Ibrahim, L. et al. (2026). “Training Language Models to Be Warm Can Reduce Accuracy and Increase Sycophancy.” Nature 652, 1159-1165.
- Panickssery, A., Bowman, S., & Feng, S. (2024). “LLM Evaluators Recognize and Favor Their Own Generations.” NeurIPS 2024. arXiv:2404.13076
- Stechly, K., Valmeekam, K., & Kambhampati, S. (2024). “On the Self-Verification Limitations of Large Language Models.” arXiv:2402.08115
- McKee-Reid, L. et al. (2024). “Honesty to Subterfuge: In-Context RL Can Make Honest Models Reward Hack.” arXiv:2410.06491
- Bondarenko, A. et al. (2025). “Demonstrating Specification Gaming in Reasoning Models.” arXiv:2502.13295
- Thaman, K. (2026). “Reward Hacking Benchmark: Measuring Exploits in LLM Agents with Tool Use.” arXiv:2605.02964
- Deque Systems (2021). “Automated Testing Study Identifies 57 Percent of Digital Accessibility Issues.”
Journal des modifications
- 2026-06-03 : édition initiale (intégration du corpus de 7 articles + huma, exemple pratique). Renforcement de la revue — 5 étapes de dérivation de la porte de domaine, 3 branches déterminisme·réseau, seam
Fetcher, règles de transition d’état. - 2026-06-03 : ajout de « Cascade de vérification » — modèle à deux couches vérification machine (L1, pouvoir PASS) + vérification IA (L2, indépendance conçue·pouvoir REVIEW) + humain (L3) et asymétrie des pouvoirs. Généralise « porte = déterminisme only » jusqu’aux domaines ouverts.
- 2026-06-05 : comail est retiré (rendu privé) en raison du risque de complicité d’activité illégale. L’exemple pratique est remplacé par huma.