 Image generated by Google Gemini
Image generated by Google Gemini
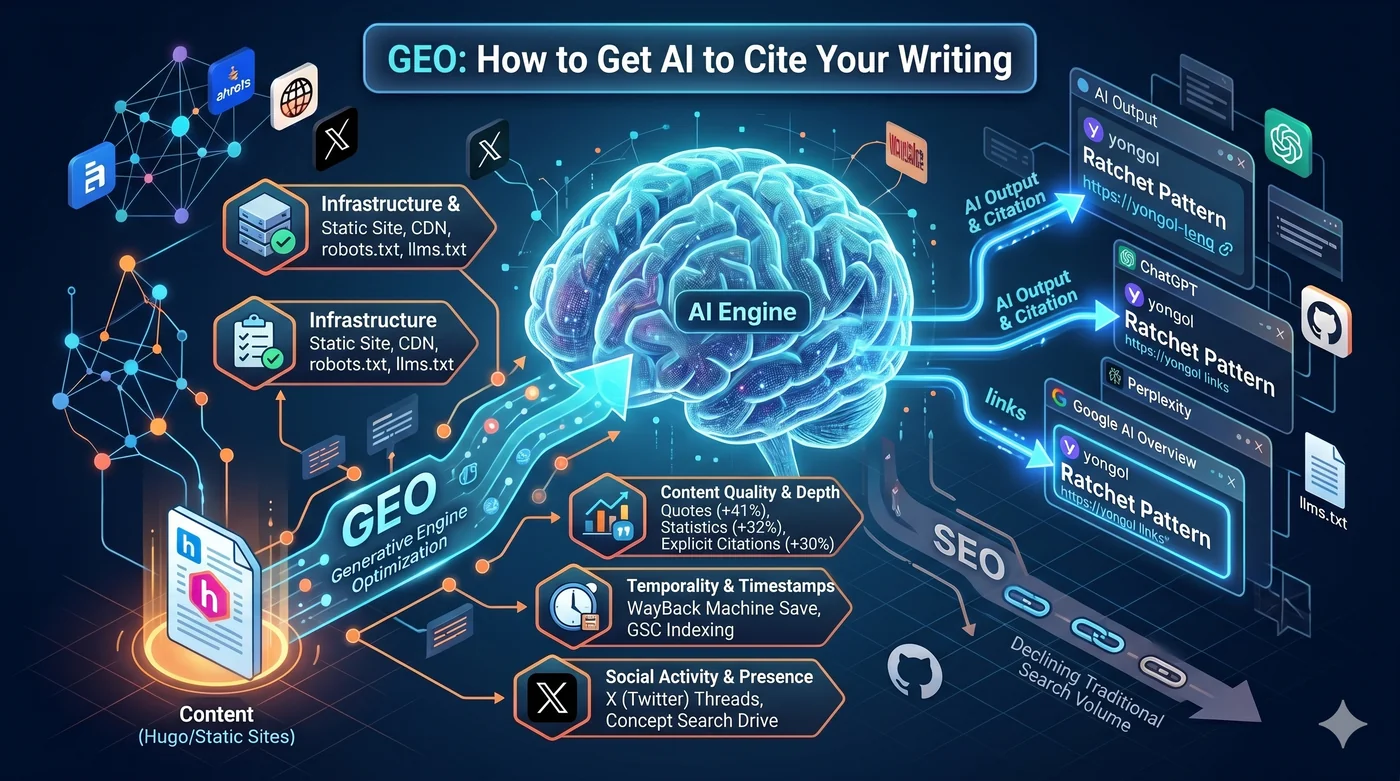
Le GEO (Generative Engine Optimization) est une strategie d’optimisation du contenu pour que les moteurs de recherche IA le citent. Le SEO traditionnel visait a monter dans le classement Google ; le GEO vise a etre inclus comme source dans les reponses generees par l’IA. Aussi appele AEO (Answer Engine Optimization), AI SEO ou optimisation pour la recherche LLM.
La recherche a change — le debut de l’ere AI SEO
On tapait une requête dans Google et dix liens bleus apparaissaient. Désormais, l’IA génère la réponse. ChatGPT, Perplexity, Google AI Overview — les utilisateurs obtiennent des réponses sans cliquer sur un seul lien.
Gartner prévoit une baisse de 25 % du volume de recherche traditionnel d’ici 2026. 31,3 % de la population américaine utilise déjà la recherche IA générative.
Le problème est le suivant : Si votre contenu n’est pas cité dans les réponses générées par l’IA, c’est comme s’il n’existait pas.
Le Generative Engine Optimization (GEO) définit les règles de ce nouveau jeu.
GEO vs SEO vs AEO — quelles differences
Le SEO traditionnel était un jeu de classement Google. Mots-clés, backlinks, balises méta. Le GEO est un jeu différent.
| SEO | GEO | |
|---|---|---|
| Objectif | Classement SERP | Citation dans les réponses IA |
| Indicateur de succès | Impressions, clics, CTR | Taux de citation, fréquence de recommandation de marque |
| Signal principal | Backlinks, mots-clés | Clarté des entités, citation de sources, cohérence inter-plateformes |
| Modèle de trafic | Clic → visite du site | Zéro clic (consommation sans visite) |
Voici des données surprenantes. 83 % des citations AI Overview proviennent de pages hors du top 10 organique de Google. 28,3 % des pages les plus citées par ChatGPT ont une visibilité organique de 0 sur Google. Le classement SEO traditionnel et la citation par l’IA sont deux jeux distincts.
Alors, que cite l’IA ?
1. Infrastructure : Hugo + CloudFront + robots.txt + llms.txt
Si les crawlers IA ne peuvent pas atteindre votre contenu, pas de citation. La première condition est l’infrastructure technique.
Générateur de site statique (Hugo) + S3 + CloudFront
- Le HTML statique est la source la plus rapide et la plus propre pour les crawlers. Les SPA nécessitent un rendu JavaScript, et les crawlers IA les ignorent souvent
- Le CDN CloudFront offre des temps de réponse rapides partout dans le monde. Les crawlers IA utilisent aussi la vitesse comme signal
- Le build multilingue de Hugo génère automatiquement les balises hreflang. 12 langues = 12 points d’entrée
Sitemap
Le sitemap XML est la base. Mais à l’ère du GEO, deux éléments supplémentaires sont nécessaires :
llms.txt— Un fichier Markdown placé à la racine du site. Si robots.txt dit “où crawler”, llms.txt guide sur “quel contenu est important”. Anthropic, Hugging Face et Perplexity l’ont adopté en précurseurs- Schema.org JSON-LD — Schémas Article, Person, SoftwareSourceCode. C’est un aide-mémoire pour les crawlers IA : “voici ce qu’est cette page”
Autorisation explicite des crawlers IA dans robots.txt :
En 2026, les principaux bots crawlers IA se répartissent en 5 catégories :
| Catégorie | Description | Impact du blocage |
|---|---|---|
| Crawlers d’entraînement | Collecte de données d’entraînement LLM | Exclusion des connaissances à long terme du modèle |
| Indexeurs de recherche | Index pour les réponses de recherche IA | Disparition des résultats de recherche IA |
| Récupération déclenchée par l’utilisateur | Fetch en temps réel lors d’une question | Impossible de référencer pendant la conversation |
| Agents | L’IA explore le web pour l’utilisateur | Exclusion des services d’agents |
| Collecte de données | Collecte de données web à grande échelle | Exclusion du dataset concerné |
Liste des principaux bots :
| Bot | Propriétaire | Usage |
|---|---|---|
| GPTBot | OpenAI | Entraînement de modèle |
| OAI-SearchBot | OpenAI | Indexation pour la recherche ChatGPT |
| ChatGPT-User | OpenAI | Récupération en temps réel par l’utilisateur |
| ClaudeBot | Anthropic | Entraînement de modèle |
| Claude-SearchBot | Anthropic | Indexation pour la recherche Claude |
| Claude-User | Anthropic | Récupération en temps réel par l’utilisateur |
| Google-Extended | Entraînement Gemini | |
| Applebot-Extended | Apple | Entraînement Apple Intelligence |
| Meta-ExternalAgent | Meta | Entraînement Llama + Meta AI |
| PerplexityBot | Perplexity | Recherche IA |
| bingbot | Microsoft | Bing + Copilot |
| CCBot | Common Crawl | Dataset ouvert (utilisé par quasi tous les LLM) |
| Bytespider | ByteDance | Entraînement Doubao (ignore robots.txt, blocage recommandé) |
L’essentiel : Il faut distinguer les bots d’entraînement des bots de recherche/récupération. Même en bloquant les bots d’entraînement, si vous autorisez les bots de recherche, vous serez cité dans les réponses IA. Si vous bloquez les deux, vous disparaissez du monde de l’IA.
llms.txt — Si robots.txt dit “où crawler”, llms.txt guide sur “quel contenu est important”. Fichier Markdown placé à la racine du site. Anthropic, Hugging Face et Perplexity l’ont adopté en précurseurs. Il élimine le bruit des menus, publicités et scripts pour fournir un contenu épuré adapté à la fenêtre de contexte de l’IA.
2. Sitemaps et hreflang : la carte semantique lue par l’IA
Le sitemap traditionnel est une liste d’URL. Le sitemap de l’ère GEO est une carte sémantique.
<url>
<loc>https://www.parkjunwoo.com/opinion/reins-engineering/</loc>
<lastmod>2026-05-27</lastmod>
<changefreq>weekly</changefreq>
</url>
En complément :
- Liens hreflang : les 12 versions linguistiques d’un même article sont interconnectées. L’IA valorise l’autorité multilingue
- Précision du lastmod : 76,4 % des citations IA proviennent de pages mises à jour dans les 30 derniers jours. Le contenu de moins de 3 mois a 3 fois plus de chances d’être cité. Falsifier le lastmod produit l’effet inverse
- Structure par catégories :
/opinion/,/tech/,/lecture/— une hiérarchie significative donne plus de contexte à l’IA qu’une structure plate
Soumettre le sitemap à Google Search Console est le minimum. Mais cela ne suffit pas.
3. Wayback Machine et Google Search Console : prouver l’original
La Wayback Machine archive des instantanés du web depuis 1996. Pour l’IA, c’est une mémoire temporelle.
Pourquoi c’est important :
- Si vous avez publié le premier article définissant le “Ratchet Pattern” en mai 2026, la Wayback Machine en conserve l’instantané
- Six mois plus tard, même si quelqu’un utilise le même concept sur une plateforme plus importante, la preuve temporelle désigne l’auteur original
- Lorsque l’IA détermine les sources, la date de première publication agit comme un signal d’autorité indirect
Mise en oeuvre :
- Après publication d’un nouvel article, soumettre une demande de sauvegarde à la Wayback Machine (
web.archive.org/save/) - Demander l’indexation de l’URL dans Google Search Console
- Un horodatage est apposé dans les deux endroits
Note : en 2026, 241 sites bloquent l’accès à la Wayback Machine (craintes de contournement du droit d’auteur par les entreprises IA). Pour un blog personnel, c’est plutôt une opportunité — dans une archive dont les grands médias se retirent, le poids relatif du contenu individuel augmente.
4. Citations et autorite thematique (Topical Authority)
Les 3 premières stratégies d’amélioration de la visibilité selon l’article original GEO (Aggarwal et al., KDD 2024) :
| Stratégie | Amélioration de la visibilité |
|---|---|
| Ajout de citations (Quotation) | +41 % |
| Ajout de statistiques (Statistics) | +32 % |
| Mention des sources (Cite Sources) | +30 % |
Le bourrage de mots-clés est inutile, voire contre-productif en GEO. L’IA ne regarde pas les mots-clés mais les preuves.
Pourquoi les citations académiques comptent :
- L’IA distingue une “affirmation” d’une “affirmation étayée”. “42 % du temps des développeurs est consacré à la dette technique” est une affirmation. “42 % du temps des développeurs est consacré à la dette technique (Stripe, The Developer Coefficient, 2018)” est une preuve
- Les phrases étayées ont un coût de confiance faible lorsque l’IA les cite dans ses réponses. Les phrases sans source doivent être vérifiées et sont donc ignorées
- Les sites cités par 4 plateformes IA ou plus apparaissent 2,8 fois plus souvent dans ChatGPT
Gestion des contenus associés et du tagging :
Les tags ne sont pas pour les humains. Ils sont pour l’IA.
- Système de tags cohérent : “Reins Engineering”, “Ratchet Pattern”, “SSOT” — lorsqu’un même tag apparaît dans plusieurs articles, l’IA reconnaît une autorité thématique (topical authority)
- Liens internes : lier les articles connexes au sein d’un article aide les crawlers IA à identifier les clusters thématiques. Un article connecté est plus cité qu’un article isolé
- Références croisées : les auto-citations entre vos propres articles sont valables. “Les fondements de ce concept sont définis dans Ratchet Pattern”
5. X, Reddit, Hacker News : strategies sociales pour le volume de recherche de marque
Les conditions d’utilisation de X/Twitter interdisent explicitement l’entraînement IA par des tiers. Autrement dit, les publications sur X n’entrent pas directement dans les données d’entraînement de ChatGPT.
Mais l’activité sociale contribue à la visibilité IA par des voies indirectes :
Le volume de recherche de marque est le meilleur prédicteur des citations LLM (coefficient de corrélation 0,334, supérieur aux backlinks).
Voici le chemin :
Thread X → les gens recherchent "yongol" sur Google → volume de recherche de marque en hausse → l'IA reconnaît "yongol" comme une entité digne d'être citée
Les données de mai de parkjunwoo.com le confirment :
- Recherche Google “yongol” : 14 impressions, 5 clics, position moyenne 3,1
- Clones GitHub yongol : 316 utilisateurs uniques
- Parcours d’acquisition : t.co (X) 4 personnes → GitHub → blog
Plutôt que de partager directement des liens sur X, amener les gens à rechercher le concept est plus efficace pour le GEO.
La puissance du earned media :
48 % de l’ensemble des citations LLM proviennent du earned media (presse, critiques, mentions tierces). Le contenu propriétaire ne représente que 23 %. Autrement dit, faire en sorte que d’autres vous mentionnent est 2 fois plus efficace que d’optimiser votre propre contenu.
Quand un projet est mentionné sur Reddit, Hacker News ou dev.to → via le crawling IA de ces plateformes → le LLM apprend l’entité.
Checklist
Infrastructure
├── Site statique Hugo + S3 + CloudFront
├── Autoriser les crawlers IA dans robots.txt
├── Créer llms.txt (curation du contenu essentiel)
├── Schema.org JSON-LD (Article, Person)
└── Sitemap XML + hreflang
Contenu
├── Mentionner la source pour chaque affirmation (+30 % de visibilité)
├── Insérer des statistiques en ligne (+32 %)
├── Utiliser des tableaux comparatifs (parsing IA optimal)
├── Maintenir lastmod à jour (mise à jour < 30 jours → taux de citation 76,4 %)
└── Mettre à jour régulièrement les articles de plus de 3 mois (probabilité de citation x3)
Connexions
├── Système de tags cohérent (autorité thématique)
├── Liens internes (clusters thématiques)
├── Citations d'articles/sources externes (réduction du coût de confiance)
└── Nouvel article → Wayback Machine + soumission GSC
Social
├── Threads X pour générer des recherches de concept (volume de recherche de marque)
├── Générer du earned media sur Reddit/HN
└── La diffusion du concept est plus favorable au GEO que le partage direct de liens
Mise en oeuvre du GEO sur ce site
Les strategies decrites dans cet article sont effectivement appliquees sur parkjunwoo.com :
- robots.txt — 25 crawlers IA explicitement autorises, Bytespider bloque
- llms.txt — Contenu essentiel organise pour s’adapter a la fenetre de contexte de l’IA
- Collection d’articles Reins Engineering — Hub de cluster thematique
- Build multilingue en 12 langues — Generation automatique de hreflang, points d’entree par langue
- Sources academiques dans chaque article — Statistiques en ligne + citations academiques pour la densite factuelle
- Soumission immediate a Wayback Machine + GSC apres publication — Preuve temporelle d’originalite
Articles associes
- Google, Optimizing your website for generative AI features on Google Search (2026) — Guide officiel Google d’optimisation pour la recherche IA
- Cyrus Shepard, AI Citation Ranking Factors Analysis — Méta-analyse de 54 études, quantification de 23 facteurs de classement des citations IA
- Seer Interactive, AIO Impact on Google CTR: 2026 Update — 53 marques, 2,43 milliards d’impressions suivies. CTR -61 % avec AI Overview
- Discovered Labs, AI Citation Patterns: How ChatGPT, Claude, and Perplexity Choose Sources — Seulement 12 % des citations IA chevauchent le top 10 Google
- Ahrefs, Generative Engine Optimization: Growth Strategies and Metrics — Analyse de 300 000 mots-clés. Les mentions web surpassent les backlinks 3:1 pour l’exposition AI Overview
- Datos/SparkToro, State of Search Q1 2026 — Suivi de la part de marché de la recherche IA basé sur le clickstream
- Rand Fishkin, Search Happens Everywhere — Analyse de 41 sites web, la recherche ne se limite pas à Google
- Go Fish Digital, GEO Case Study: 3X’ing Leads — Le référencement IA génère un taux de conversion 25 fois supérieur à la recherche traditionnelle
- Search Engine Land, How schema markup fits into AI search — Analyse sans exagération du schema markup et de la recherche IA
- Lily Ray, The Vicious Cycle of SEO — Avertissement sur la courte durée de vie du spam GEO
Sources
Articles académiques
- Aggarwal et al., GEO: Generative Engine Optimization, KDD 2024 — Citations +41 %, statistiques +32 %, mention des sources +30 % de visibilité
- Xu et al., Measuring Google AI Overviews (2026) — Analyse de 55 393 requêtes. 30 % des domaines cités par AIO ne figurent pas en page 1 organique
- Fang et al., Recency Bias in LLM-Based Reranking, SIGIR-AP 2025 — Les 7 modèles testés favorisent systématiquement le contenu récent
- Zhang et al., Citation Selection to Citation Absorption (2026) — Comparaison quantitative des patterns de citation ChatGPT/Google AIO/Perplexity
- Algaba et al., LLMs Reflect Human Citation Patterns, NAACL 2025 — Les LLM favorisent davantage les articles hautement cités (effet Matthew)
- arXiv:2602.18455, AI Search Impact on Wikipedia Traffic (2026) — AIO réduit le trafic Wikipedia de 15 % (analyse causale DID)
- Yu et al., Structural Feature Engineering for GEO (2026) — La structure du contenu elle-même influence la probabilité de citation
- Tian et al., Diagnosing Citation Failures in GEO (2026) — 5 % de modification du contenu améliore le taux de citation de 40 %
- Baack, Critical Analysis of Common Crawl, FAccT 2024 — Composants clés et biais des données d’entraînement LLM
- Strauss et al., The Attribution Crisis in LLM Search (2025) — 92 % de Gemini ne fournit pas de citations cliquables
Rapports de données
- Ahrefs, Do AI Assistants Prefer Fresh Content? (2025) — Analyse de 17 millions de citations IA
- SparkToro/Datos, State of Search Q1 2026 — Suivi de la part de marché de la recherche IA basé sur le clickstream
- GitClear, AI Copilot Code Quality 2025 — Analyse de 210 millions de lignes
- Gartner — Prévision de baisse de 25 % du volume de recherche traditionnel d’ici 2026
- llms.txt proposed standard — Search Engine Land
Journal des modifications
- 2026-05-27: Version initiale