 Image: AI generated
Image: AI generated
Elle revient à l’endroit même où on l’a corrigée
J’ai construit un outil pour fermer la dérive.
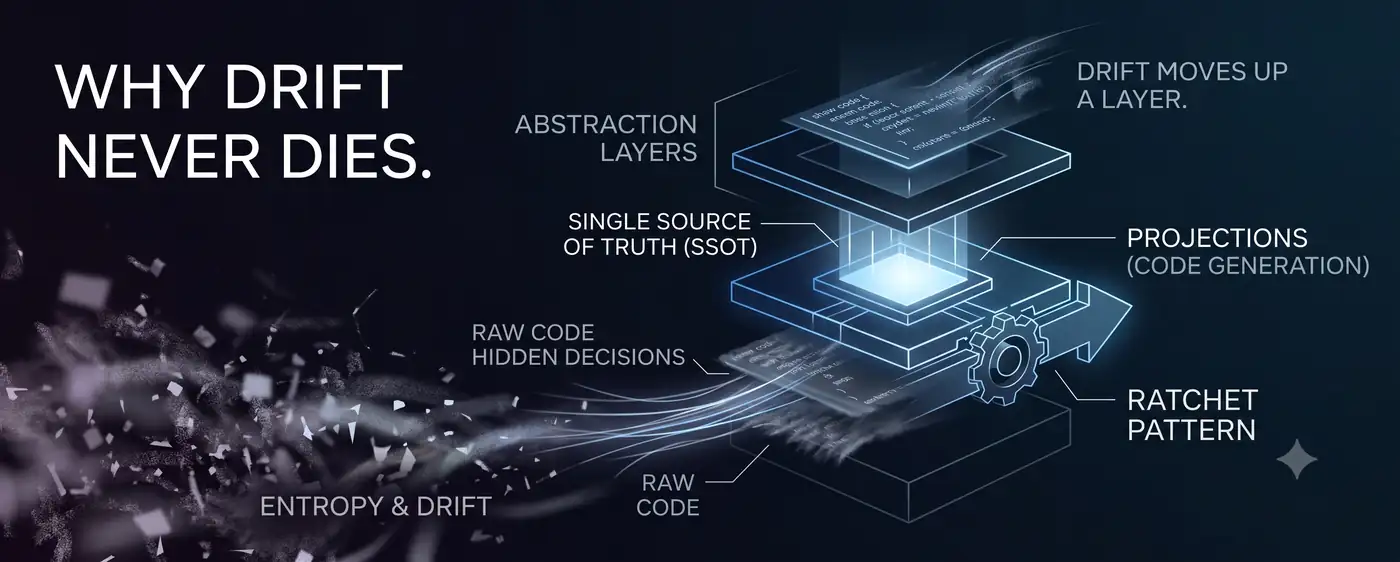
La thèse de yongol est simple. Une décision qui ne vit pas dans une source unique faisant autorité (SSOT) finit par dériver. On place donc les décisions dans un SSOT et on fait du code une projection jetable, redessinée à chaque génération. Une colonne définie en BIGINT qui, après un seul refactoring, redevient discrètement INT — cette dérive de logique métier est désormais fermée.
Mais récemment, en analysant un lot de défauts dans le code produit par yongol, j’ai remarqué quelque chose d’étrange. Les défauts se confessaient tous avec la même structure de phrase. « La collecte des import est dissociée de “est-ce que le handler utilise réellement time ?” » « L’inférence de requiredness est dissociée de “est-ce que l’API cible exige vraiment ce paramètre en required ?” » Les paramètres de chemin sont toujours required ; les import ne le sont que lorsque le token est réellement utilisé. Les mêmes décisions structurelles étaient figées dans le code du générateur sous forme de proxies locaux commodes, sans être inscrites dans aucun SSOT.
La dérive n’avait pas disparu. Elle était montée d’un étage. La logique métier était verrouillée par le SSOT, mais les décisions structurelles propres au générateur — celui-là même qui lit le SSOT pour produire le code — n’avaient aucun SSOT. La thèse de yongol lui revenait en pleine face. Exactement à l’endroit prédit par la théorie.
La question change alors. Tout le monde sait pourquoi la dérive apparaît. La vraie question est celle-ci : pourquoi revient-elle même après correction ?
La racine : décision et détail sont deux choses distinctes
Reconstruisons depuis la physique.
Une décision est de l’information. De l’information à basse entropie, qui plus est. « Cette colonne doit être sur 64 bits » est un choix délibéré parmi une multitude d’états possibles. La nature déteste la basse entropie. Laissée à elle-même, l’information se diffuse dans le bruit ambiant et disparaît. La deuxième loi de la thermodynamique s’applique aussi aux décisions.
Le génie logiciel observe cet effondrement depuis longtemps. Les lois de l’évolution du logiciel de Lehman affirment que la complexité d’un système E-type augmente à moins d’un effort explicite pour la réduire (1980). La physique de l’information va plus profond encore. Landauer a montré en 1961 qu’effacer ne serait-ce qu’un seul bit exige un coût thermodynamique minimal (kT ln 2). Modifier et préserver de l’information n’est jamais gratuit en principe. Maintenir une décision en place exige une dépense continue d’énergie.
Pour que l’information survive, deux choses sont nécessaires : un stockage faisant autorité (authoritative store) et une reprojection active incessante à partir de cette source (error correction). L’ADN de notre corps fonctionne ainsi ; les bits de parité du stockage numérique aussi. On conserve l’original à part, et on restaure à chaque fois en s’y référant.
La dérive survient quand cette restauration se brise. Le mécanisme est unique. Je l’appelle proxy binding. Quand le support ne parvient pas à distinguer et à préserver séparément la décision et le détail, la personne suivante (ou l’agent suivant) ne peut pas lire la décision depuis la source faisant autorité et la redérive à partir d’un signal corrélé commode situé à proximité. « Cette colonne est en timestamptz, donc il faut importer time » — une supposition. Elle est juste la plupart du temps. C’est précisément ce qui la rend dangereuse. Parfois elle se trompe, et quand c’est le cas, la décision disparaît en silence.
Le code raw est exactement un tel support. Le code ne distingue pas « ceci est une décision » de « ceci se trouve être vrai ici par accident ». C’est pourquoi un modèle plus puissant ne résout pas le problème. Si le support lui-même ne peut pas porter la décision, le lecteur a beau être plus intelligent — il n’y a rien à lire.
Ce phénomène n’était pas innommé. En architecture logicielle, Perry et Wolf ont distingué la violation des principes — l’érosion (erosion) — de l’insensibilité progressive à l’architecture — la dérive (drift) (1992). Cunningham a appelé dette technique les intérêts qui s’accumulent sur du code mal fait (1992). Chaque domaine a bien nommé ses symptômes. Ce que je cherche à ajouter, c’est le mécanisme unique sous-jacent (le proxy binding) et le fait que ce mécanisme, à mesure qu’on le ferme, récurse vers la couche supérieure. Ce n’est pas le nom que j’interroge, mais la causalité.
Pourquoi elle monte
Jusqu’ici, l’histoire est connue. La nouveauté vient ensuite.
Pour fermer la dérive, deux choses sont nécessaires : un répertoire faisant autorité pour les décisions (SSOT) et un acteur de fermeture qui le lit pour produire les artefacts (le générateur). Mais l’acteur de fermeture prend lui aussi des décisions. Des décisions structurelles comme « les paramètres de chemin sont required ». Le support où vivent ces décisions — le code du générateur — ne distingue pas non plus décision et détail.
Le même mécanisme se répète un étage plus haut. L’acte même de fermer crée, une couche au-dessus, un support non verrouillé. La dérive n’a pas été éradiquée — elle a déménagé. Vers une couche sans autorité.
Poussé jusqu’au bout, ce raisonnement mène à une conclusion inconfortable. On donne un SSOT au générateur ? Alors ce qui fabrique ce SSOT inscrit à son tour ses propres décisions dans un support non verrouillé. À chaque montée de couche, la surface diminue, mais tout en haut, il reste toujours une couche sans autorité. Que ce soit un humain, ou le générateur du générateur. La dérive est asymptotiquement impossible à éradiquer. (C’est davantage une conjecture forte qu’une preuve. Mais jusqu’ici, chaque couche que j’ai fermée a ouvert la couche du dessus au moment même de sa fermeture.)
Voilà la réponse à « pourquoi revient-elle même après correction ? ». Elle ne revient pas. Quand nous fermons une couche, l’outil de fermeture ouvre la suivante. Le même fleuve qui fuit par une digue plus haute.
L’asymétrie du remède : ce que l’on peut déclarer et ce que l’on ne peut que vérifier
Comment ferme-t-on alors la couche supérieure ? C’est ici qu’une asymétrie décisive se révèle.
Les décisions de logique métier sont le plus souvent des valeurs. La colonne fait 64 bits, l’accès est réservé au propriétaire, la pagination est par curseur. Les valeurs se déclarent. On les inscrit dans un DDL, un OpenAPI, un fichier de spécification — et cela devient le SSOT. Fermé par déclaration.
Les décisions structurelles du générateur sont différentes. « Les paramètres de chemin sont required », « les import sont liés à la référence effective du token », « required (la clé existe) et non-vide sont distincts ». Ce ne sont pas des valeurs, mais des propriétés comportementales d’une fonction sur toutes les entrées. Les propriétés comportementales ne peuvent pas être énumérées par déclaration. Parce que les entrées sont infinies. Il n’existe aucun moyen d’écrire dans une case YAML « cette transformation doit se comporter ainsi dans tous les cas ».
Les décisions de cette couche ne se ferment donc pas par déclaration, mais uniquement par vérification. Vérificateur de types, tests de propriétés, portes de compilation. On ne fige pas la décision comme donnée — on installe une porte où la machine détecte chaque violation à chaque passage.
C’est précisément le point que j’ai formulé dans un autre article : « codifiez l’inspection humaine ». Certaines promesses se déclarent et sont gardées par le SSOT ; d’autres ne se déclarent pas et sont gardées par la porte. Savoir si le code produit par le générateur compile ne peut être inscrit dans aucun SSOT. Seule l’exécution de la compilation à chaque fois le confirme. Sans cette porte, la promesse « generate réussi = build possible » flotte en dehors de l’architecture, et validate passe à 0/0 alors que les artefacts sont cassés.
La dérive déclarable se ferme par le SSOT ; la dérive qui ne peut être que vérifiée se ferme par la porte. Confondre les deux, c’est tenter de bloquer par déclaration et chasser éternellement les taupes.
Même fleuve, digues différentes
Cette structure se répète en dehors du code.
Dans le savoir, la dérive est la perte de la source. Quand une affirmation perd le qui, le quand et le sur quelle base, elle se dilue en « fait » — du bruit. La personne suivante ne peut pas lire depuis l’autorité (la source originale) et redérive à partir du contexte environnant. C’est pourquoi j’ai conçu GEUL comme un langage qui impose à toute information une source, un horodatage et un degré de confiance. L’épistémologie selon laquelle il n’y a pas de faits, seulement des affirmations, est un garde-fou contre le proxy binding dans la couche du savoir.
Dans le droit, la dérive est la jurisprudence qui s’écarte de la décision originale. La civilisation n’a pas laissé cela à la conscience du juge à chaque affaire — elle a codifié les règles, défini les violations et attaché des mécanismes d’application. Un bon juge n’est pas un SSOT ; c’est un proxy. Le droit écrit est le SSOT.
C’est le même fleuve. Si une décision ne vit pas à un emplacement faisant autorité, si le support ne distingue pas décision et détail, elle dérive. Code, savoir ou droit.
Conclusion : non pas l’éradication, mais la poussée vers le haut
Le combat contre la dérive ne peut pas viser l’éradication. L’éradication est impossible. L’outil de fermeture ouvre toujours la couche suivante.
L’objectif est autre. Pousser la dérive vers une couche plus haute, à la surface plus réduite, et armer cette couche d’une vérification mécanique. Rassembler dans un seul SSOT les décisions dispersées sur des dizaines de milliers de lignes de code raw réduit drastiquement la surface susceptible de dériver. La surface restante — les invariants comportementaux du générateur — est bloquée par des portes. Et pourtant, tout en haut, il reste une dernière couche sans délégation possible : le jugement humain. Là, nous vérifions à nouveau à chaque fois et scellons une nouvelle promesse.
C’est cela, le cliquet. Il ne tourne que dans un sens. Un cran monté ne redescend pas. L’entropie tire les décisions vers le bas ; le cliquet les remonte d’un cran à chaque fois. Il n’y a pas d’équilibre. S’arrêter, c’est dériver.
La dérive ne meurt pas. C’est pourquoi nous ne nous arrêtons pas. Bâtir des promesses contre l’entropie n’est pas une victoire unique — c’est un cliquet permanent.
Articles liés
- Ratchet Pattern — comment forcer un agent à aller jusqu’au bout
- Pourquoi votre boucle d’agent diverge
- Reins Engineering — L’IA avec des renes
Lectures complémentaires (externes)
- Lehman’s laws of software evolution — Aperçu des lois empiriques selon lesquelles un logiciel non maintenu gagne en complexité.
- Landauer’s principle — Le coût thermodynamique de l’effacement de l’information.
Sources
- Perry, D. E. & Wolf, A. L. (1992). Foundations for the Study of Software Architecture. ACM SIGSOFT Software Engineering Notes, 17(4), 40-52. ACM — Distinction entre érosion (erosion) et dérive (drift).
- De Silva, L. & Balasubramaniam, D. (2012). Controlling software architecture erosion: A survey. Journal of Systems and Software, 85(1), 132-151. ScienceDirect
- Lehman, M. M. (1980). Programs, Life Cycles, and Laws of Software Evolution. Proceedings of the IEEE, 68(9), 1060-1076. IEEE — Loi d’augmentation de la complexité et loi du changement continu.
- Landauer, R. (1961). Irreversibility and Heat Generation in the Computing Process. IBM Journal of Research and Development, 5(3), 183-191. IBM — Coût thermodynamique minimal de l’effacement de l’information.
- Shannon, C. E. (1948). A Mathematical Theory of Communication. Bell System Technical Journal, 27, 379-423. DOI — Fondements de l’information, de l’entropie et de la correction d’erreurs.
- Cunningham, W. (1992). The WyCash Portfolio Management System. OOPSLA ‘92 Experience Report. c2.com — La dette technique et les « intérêts du code mal fait ».