 Image: AI generated
Image: AI generated
Le legacy ne ment pas
Le code legacy n’a pas de documentation. Quand il y en a une, elle date d’il y a trois ans. Les tests sont absents, ou bien présents mais cassés et marqués skip. Les commentaires contredisent le code. L’auteur original est parti, et la seule chose que sait celui qui reste, c’est qu’« on n’y touche pas, sinon ça pète ».
Et pourtant ce code tourne en ce moment même. Il traite les paiements, accepte les connexions, enregistre les commandes.
La documentation ment. Les commentaires mentent. La mémoire humaine ment encore plus fort. La seule chose qui ne ment pas, c’est le trafic qui s’écoule réellement.
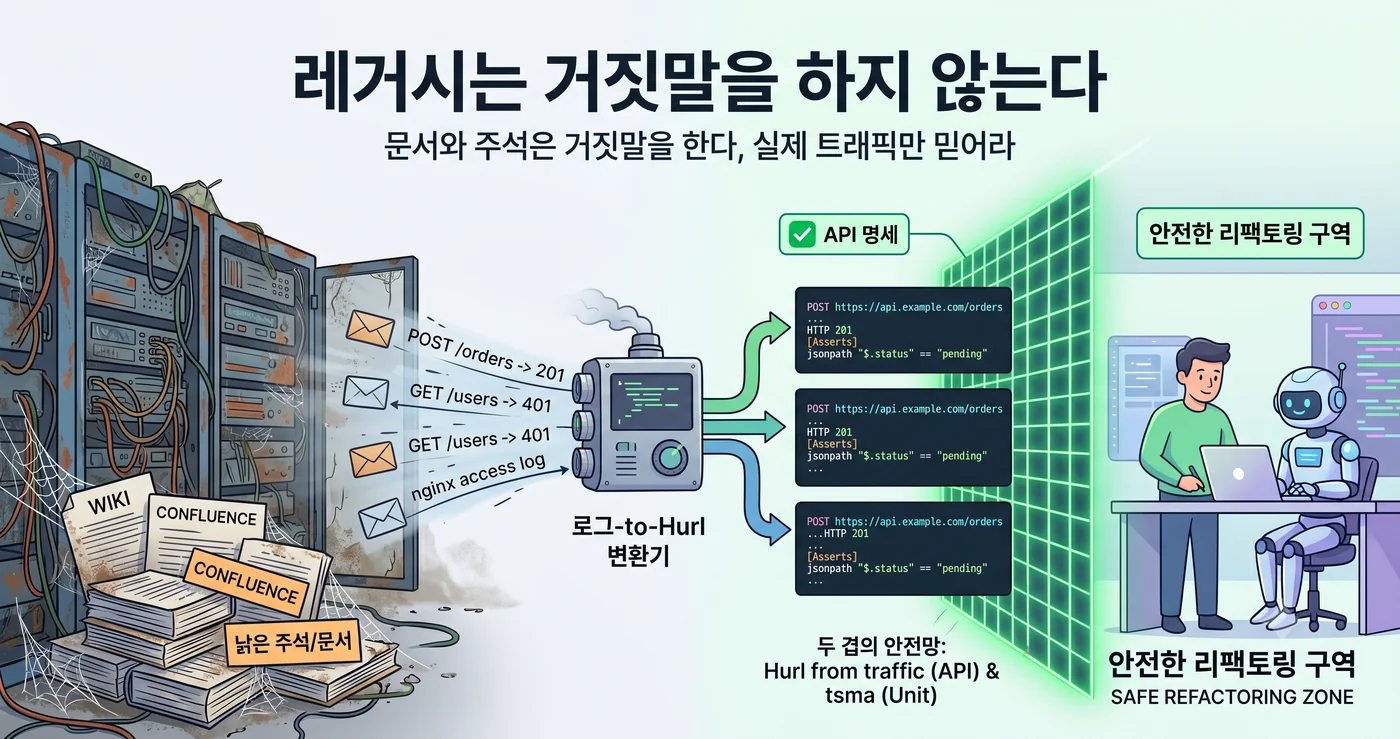
Alors, où chercher la spécification ? Pas dans le wiki. Pas dans Confluence. Dans le nginx access log.
La poule et l’œuf
Pour refactoriser le legacy, il faut un filet de sécurité. Quand on change quelque chose, il faut savoir immédiatement si le comportement a changé. Ce filet de sécurité, ce sont précisément les tests.
Or le legacy n’a pas de tests. Pour écrire un test, il faut savoir ce que fait le code. Pour savoir ce que fait le code, il faut le lire. Et quand on le lit, on découvre qu’il n’y a ni test ni documentation.
La poule ou l’œuf. C’est l’impasse classique que Michael Feathers a nommée dans Working Effectively with Legacy Code. Sa réponse : le characterization test — un test qui n’embaume pas ce que le code devrait faire correctement, mais ce qu’il fait actuellement, tel quel. Le juste et le faux viennent après. Il faut d’abord figer le comportement présent pour pouvoir y toucher.
À l’époque de Feathers, on écrivait cela à la main. On appelait la fonction, on observait la valeur produite, et on la recopiait telle quelle dans l’expected. Fastidieux, lent, et c’est pourquoi personne n’allait jamais jusqu’au bout.
Mais au niveau de l’API, ce « résultat d’appel de fonction » est déjà accumulé quelque part. Chaque jour, par dizaines de milliers. Dans les fichiers de logs.
Un mois de logs est la spécification
En collectant pendant un mois, on peut capturer la quasi-totalité du comportement actuel d’une API legacy.
nginx access log (1 mois) :
endpoint · méthode HTTP · status code · timing
fréquence d'appel → priorité
patterns d'erreur (401, 422, 500 …)
request/response body (capturés via middleware ou reverse proxy) :
paires requête/réponse normales → comportements à préserver
paires requête/réponse d'erreur → cas limites à ne pas casser
En combinant ces deux flux, on obtient une traduction directe en tests d’intégration Hurl. Hurl est un format où l’on écrit la requête HTTP et la réponse attendue telles quelles, en texte brut. Une paire de trafic — « à cette requête, cette réponse est sortie » — c’est exactement un bloc Hurl.
# POST /api/orders — fréquence d'appel #3, 12 000 appels par jour
POST https://api.example.com/orders
Content-Type: application/json
{ "sku": "A-1024", "qty": 2 }
HTTP 201
[Asserts]
jsonpath "$.order_id" exists
jsonpath "$.status" == "pending"
jsonpath "$.total" == 49800
Ce test ne sait pas « comment l’API de commande devrait fonctionner ». Il sait seulement qu’« elle fonctionne ainsi en ce moment ». Et cela suffit. À l’instant où la refactorisation change cette réponse, le voyant passe au rouge.
Ce que les logs font émerger automatiquement :
- Quels endpoints sont réellement utilisés → un endpoint appelé zéro fois en un mois est du code mort. Candidat à la suppression avant la refactorisation.
- Les patterns de réponse normale → tests de régression de base.
- Les patterns d’erreur → les vrais cas limites que personne n’imagine. Des 422 et des 500 produits par de vrais utilisateurs.
- La fréquence d’appel → la priorité des tests. On commence par celui à 12 000 appels par jour.
Le dernier point est crucial. Quand un humain écrit des tests, il commence par le happy path dont il se souvient. Le trafic n’a pas ce biais. Le chemin qui reçoit réellement la charge est justement la priorité.
Un filet de sécurité à deux couches
Cette approche ne s’emploie pas seule : c’est une couche du pipeline ratchet qui hisse le legacy vers l’agent-operable.
nginx log (1 mois) → génération automatique de Hurl → embaumement du comportement actuel de l'API legacy
↓
tsma → filet de sécurité au niveau fonction (unit)
↓
filefunc → mise en ordre de la structure du code (un concept, un fichier)
↓
refactorisation → Hurl vérifie la préservation du comportement de l'API (integration)
L’essentiel, c’est que le filet de sécurité a deux couches.
- tsma = filet de sécurité au niveau fonction. Il détecte si la logique interne a changé. Mais même si la signature de la fonction reste identique, le comportement global de l’endpoint peut changer.
- Hurl from traffic = filet de sécurité au niveau API. Il détecte si le contrat vu de l’extérieur est préservé. Quelle que soit la manière dont on chamboule l’intérieur, tant que ce qui entre et ce qui sort sont identiques, ça passe.
La refactorisation, c’est par définition « changer la structure interne tout en préservant le comportement externe ». Il faut donc que la définition du « comportement externe » à préserver soit embaumée quelque part. tsma tient la frontière intérieure, Hurl tient la frontière extérieure. C’est seulement lorsque les deux couches sont là ensemble qu’on peut dire à l’agent : « chamboule autant que tu veux, c’est la machine qui verra où ça casse ».
Un juge qui ne peut pas flagorner
Cela s’emboîte exactement avec l’essence de la Symbolic Feedback Loop.
Si vous demandez à l’agent « tu as bien refactorisé ? », il répond « Oui, j’ai tout rangé proprement ». Donnez-lui votre avis, il flagorne. Mais lancez Hurl, et vous obtenez POST /orders → expected 201, got 500. Les nombres et les status codes ne flagornent pas. Parce qu’ils n’ont pas d’émotion.
Un test Hurl extrait du trafic est une spécification où aucun jugement humain n’est intervenu. Ce n’est pas « quelqu’un pense que ça devrait fonctionner ainsi », mais « l’observation montre que ça a fonctionné ainsi ». Ce n’est pas une affirmation, c’est une mesure. C’est pourquoi le juste et le faux de la refactorisation peuvent être jugés par la machine et non par l’humain. Le LLM n’est pas un juge mais un exécutant, et c’est un outil déterministe qui rend le verdict.
Une seule prémisse : des logs bien tenus
Pour que cette méthode tienne, il ne faut qu’une seule chose. Un mois de logs bien tenus.
Tout est dans le « bien tenus ». L’access log seul ne suffit pas. Il donne l’endpoint, le status code et le timing, mais pas l’essentiel à embaumer — la paire request body / response body. Savoir seulement que POST /orders → 201 ne permet pas de reproduire « à cette entrée, cette sortie est sortie ». Pour figer une fonctionnalité, il faut tenir à la fois ce qui est entré et ce qui est sorti.
La vraie question n’est donc pas « comment écrire les tests » mais « mes logs sont-ils suffisamment bien écrits pour devenir une spécification ».
- Les request/response body sont-ils conservés, ou bien seulement le status code ?
- Les réponses d’erreur sont-elles conservées aussi ? Ce sont les body des 422 et des 500 qui constituent les cas limites que personne n’imagine.
- Les logs sont-ils structurés au point qu’une machine puisse apparier requêtes et réponses ?
Si tout cela est en place, alors vous écriviez déjà votre spécification depuis un mois. Pas besoin d’écrire des tests séparément. Le pipeline de logs les écrivait à votre place. Si ce n’est pas en place, il suffit d’insérer dès maintenant une couche de middleware et de la laisser tourner un mois. Un mois plus tard, vous avez entre les mains l’intégralité du comportement actuel du legacy.
Pourquoi un mois et non un jour ? Un jour ne capture que le happy path. Un mois capture le batch de fin de mois, le pic de trafic juste avant la clôture comptable, les endpoints d’administration rarement appelés, le cron qui ne tourne qu’une fois à 3 heures du matin — toute la longue traîne du système. Une spécification n’est pas une moyenne, c’est une distribution.
Traduire les logs en Hurl pour figer les fonctionnalités
Une fois les logs en place, le reste est mécanique. On verse un mois de paires request/response dans un outil, et on traduit chaque paire en bloc Hurl. Les centaines de fichiers Hurl ainsi déversés constituent la suite de characterization — un filet de sécurité qui embaume d’un bloc le comportement actuel du legacy. On n’a pas lu une seule ligne de code. On n’a lu que le trafic écoulé.
Anticipons ici un point où l’on hésite souvent. « Mais les logs contiennent des données personnelles, des paiements, des tokens — peut-on les embaumer dans un test ? »
Oui. Plus précisément, il n’y a pas besoin de les embaumer. Parce que cette méthodologie n’a, à l’origine, pas besoin des valeurs. Ce qu’un characterization test fige, ce n’est pas la valeur, c’est le comportement.
HTTP 201
[Asserts]
jsonpath "$.order_id" exists
jsonpath "$.total" == 49800
Ce qui compte ici en tant que spécification, ce n’est pas le nombre 49800, mais la structure : « le champ total existe en tant qu’entier, et il est calculé ainsi pour une entrée donnée ». Même en masquant les valeurs ou en les remplaçant par des données synthétiques, la valeur de la spécification ne diminue presque pas. capture → masquage → génération de Hurl : tout ce pipeline tourne à l’intérieur de votre infrastructure. Les logs bruts n’ont aucune raison de sortir où que ce soit. Ce qui reste n’est qu’une spécification aux valeurs masquées, un contrat dont seule la structure est préservée. Le fait de ne pas avoir à faire sortir les logs n’est pas une concession de sécurité mais l’essence de cette approche — puisqu’il suffit, dès le départ, d’embaumer le comportement.
Lancez une fois le Hurl généré sur le staging, et le pass/fail se décide sur place. Une fois que tous les voyants sont au vert, vous pouvez commencer la refactorisation. Dites à l’agent de chambouler autant qu’il veut, et c’est Hurl qui verra où ça casse.
Une échelle posée sans code
La vraie valeur de cette approche n’est donc pas « écrire des tests rapidement ». La vraie valeur est celle-ci.
- Ça démarre sans lire le code — l’auteur original est parti et la documentation n’existe pas, mais le seul trafic écoulé pose le filet de sécurité. On obtient le droit de toucher au code avant même de le comprendre.
- Le résultat est immédiatement vérifiable — lancez le Hurl généré sur le staging, et le pass/fail sort sur place. Ce n’est pas « ça devrait marcher » mais « en ce moment, 327 sur 327 passent ».
- Les données ne franchissent pas la clôture — de la capture à la génération de Hurl, tout se termine à l’intérieur de mon infrastructure. Plus l’industrie est régulée, plus il est décisif de pouvoir démarrer sans rien laisser sortir à l’extérieur.
Le premier coup de pelle dans la modernisation du legacy s’arrête généralement devant la falaise du « personne ne sait quel est le comportement actuel ». Trafic → Hurl pose une échelle contre cette falaise. Et pour poser cette échelle, pas besoin de code. Le trafic écoulé suffit — et ce trafic lui-même reste tel quel à l’intérieur de la clôture.
Le flux écrivait déjà la spécification
Nous nous échinons à écrire la spécification séparément. Nous rédigeons l’OpenAPI à la main, décrivons le comportement dans le wiki, et quand tout cela diverge du code, nous appelons cela du drift en nous lamentant.
Mais le système vivant écrivait à chaque instant sa propre spécification de lui-même. Chaque fois qu’une requête entre et qu’une réponse sort, c’est une ligne d’auto-description : « je suis tel système ». Le fichier de logs, c’est cette autobiographie accumulée pendant un mois.
Nous ne l’avions simplement pas lue.
Le legacy n’est pas dépourvu de documentation. La documentation est dans l’access log, et c’est seulement sa forme qui est inconfortable à lire pour un humain. Traduite en Hurl, elle devient une spécification exécutable, un contrat que la machine juge.
La documentation ment. Le trafic ne ment pas.
Articles liés
- Hurl arrête le drift — comment déclarer le contrat HTTP en texte brut et le verrouiller en CI. Si cet article est « trafic → Hurl », celui-là est « verrouiller le drift avec Hurl ».
- tsma — la ligne de défense contre la régression du code legacy — la frontière intérieure (niveau fonction) du filet de sécurité à deux couches. Si Hurl est la frontière extérieure, tsma est l’intérieure.
- Agent Operable Codebase — le pipeline en 3 étapes qui hisse le legacy vers un code opérable par l’agent.
- Pourquoi les agents de codage fonctionnent et pourquoi ils s’effondrent — la structure de la Symbolic Feedback Loop.
- Les contraintes sont des contrats — le test comme contrat vérifiable et applicable.
- Comment sauver un vibe coding raté — cours pratique pour diagnostiquer → verrouiller → réparer → extraire → migrer le legacy par le characterization testing.
Sources / Fondements
Concepts et outils clés
- Michael Feathers. Working Effectively with Legacy Code. Prentice Hall, 2004. — origine du concept de characterization test. « On fige non pas ce que le code devrait faire correctement, mais ce qu’il fait actuellement. »
- Projet Hurl (hurl.dev) — format de test HTTP requête/réponse en texte brut. Intégré comme l’un des 10 SSOT de yongol.
- Démonstration tsma sur 527 fonctions — ratchet au niveau fonction (tsma).
Extraire des tests à partir du trafic et de l’exécution (carving / record-replay)
- Elbaum, Chin, Dwyer, Jorde (2009). “Carving and Replaying Differential Unit Test Cases from System Test Cases.” IEEE TSE 35(1). — fondement académique du differential unit test qui enregistre (record) l’exécution système puis la rejoue (replay) à l’échelle de l’unité.
- Équipe d’ingénierie Meta (2024). “Observation-based Unit Test Generation at Meta.” FSE 2024, arXiv:2402.06111. — carving de tests à partir des observations d’exécution de l’application. 9,6 millions d’exécutions en CI, 5 702 défauts détectés. Démonstration à l’échelle industrielle de « l’observation est le test ».
Embaumer le comportement actuel (snapshot / golden master)
- Fujita, Kashiwa, Lin, Iida (2023). “An Empirical Study on the Use of Snapshot Testing.” ICSME 2023. — démonstration de l’adoption des tests snapshot (= golden master/characterization). « On détecte les changements en figeant non pas la justesse, mais la sortie actuelle. »
Filet de sécurité pour la refactorisation
- Kim, Zimmermann, Nagappan (2014). “An Empirical Study of Refactoring Challenges and Benefits at Microsoft.” IEEE TSE 40(7). — démonstration que, sans tests garantissant la préservation du comportement, la refactorisation est un coût et un risque.
- Yoo, Harman (2012). “Regression Testing Minimization, Selection and Prioritization: A Survey.” STVR 22(2). — test de régression = définition standard de « l’assurance qu’un changement ne nuit pas au comportement existant ».
La distribution réelle d’usage est la priorité
- John D. Musa (1993). “Operational Profiles in Software-Reliability Engineering.” IEEE Software 10(2). — en répartissant les tests par fréquence d’usage, même si l’on s’arrête par manque de temps, ce sont les fonctionnalités les plus utilisées qui sont les plus vérifiées. Fondement classique de « la distribution du trafic plutôt que le biais happy path ».
Pourquoi la machine doit rendre le verdict (le LLM n’est pas juge mais exécutant)
Huang, Chen, Mishra, et al. (2024). “Large Language Models Cannot Self-Correct Reasoning Yet.” ICLR 2024, arXiv:2310.01798. — sans feedback externe, le LLM ne corrige pas son propre raisonnement. La raison pour laquelle un vérificateur externe déterministe est nécessaire.
Sharma, Tong, et al. (2024). “Towards Understanding Sycophancy in Language Models.” ICLR 2024, arXiv:2310.13548. — le RLHF apprend la complaisance et ruine la fiabilité de l’auto-jugement du LLM.
Image de couverture : générée par IA (Google Gemini)
À lire également
- Michael Feathers, “Characterization Testing” — texte du créateur du terme. « À l’instant où un logiciel entre en production, il devient sa propre spécification (it becomes its own specification). » Une thèse presque identique au titre de cet article.
- Tutoriel officiel Hurl, “Your First Hurl File” — de
GET / HTTP 200jusqu’au mode--test. Une introduction où l’on tient en main le fait qu’une ligne de texte brut est déjà un test. - GitHub Engineering, “Scientist: Measure Twice, Cut Once” — bibliothèque qui exécute simultanément en production le code legacy (control) et le nouveau (candidate) pour comparer les résultats. « Seul le comportement réel est la vraie spécification. »
- Twitter Diffy (résumé InfoQ) — proxy qui envoie la même requête à l’ancien et au nouveau service et ne retient comme régression que les différences de réponse. Précédent classique de « embaumer le comportement sans écrire de test ».
- GoReplay — outil qui capture le trafic HTTP live sur l’interface réseau et le rejoue sur le staging. Implémentation emblématique de « le trafic de production comme entrée de test ».
- Nicolas Carlo, “Characterization vs Approval Tests” — met de l’ordre dans trois termes qui désignent en réalité la même technique, et souligne le rôle du « Printer » qui nettoie les informations sensibles de la sortie.
- Pact — consumer-driven contract testing. Approche du « contrat explicite » qui contraste avec l’embaumement du trafic. Voir les deux méthodes ensemble donne de l’équilibre.