 Image: AI generated
Image: AI generated
Ser inteligente no significa saber explicar
Cuando le pido a Opus 4.8 que refactorice código, el resultado es impresionante. Resuelve grafos de dependencias complejos de una sola vez, maneja proactivamente los casos límite y escribe tests sin dejar huecos. Pero cuando le pido que explique el resultado, empieza el problema. Habla como un experto reportando a otro experto. Da por sentado que compartimos el mismo conocimiento de fondo, omite las razones de sus decisiones clave y maneja un nivel de abstracción innecesariamente alto.
Cuando le pregunto lo mismo a Opus 4.6, es justo lo contrario. Estima bien lo que yo podría no saber. Elige analogías con cuidado, divide en pasos y sienta el contexto primero. Pero cuando la dificultad de razonamiento sube, se traba en problemas que 4.8 resolvería de un tirón.
En una frase: Opus 4.8 es inteligente pero habla difícil, y Opus 4.6 explica de manera comprensible pero tiene menor rendimiento de razonamiento.
Esto no es un defecto. Por qué ocurre, y cómo convertir esta diferencia en una ventaja estructural, es el tema de este artículo.
La maldición del conocimiento también aplica a los LLM
En 1989, los psicólogos Camerer, Loewenstein y Weber lo demostraron experimentalmente. Cuanta más información posee una persona, menos capaz es de considerar adecuadamente que la otra persona no la tiene. Este fenómeno, llamado “Maldición del Conocimiento (Curse of Knowledge)”, es un sesgo cognitivo confirmado repetidamente en pedagogía, economía y diseño UX.
Oliver Wendell Holmes dijo: “No daría un centavo por la simplicidad de este lado de la complejidad. Pero daría la vida por la simplicidad del otro lado de la complejidad.” Las explicaciones sencillas no son sencillas por ignorancia, sino que solo son posibles después de haber atravesado la complejidad. Y paradójicamente, mientras se está inmerso en la complejidad, la capacidad de hablar con sencillez disminuye.
Un artículo de EMNLP 2025 mostró que este fenómeno también aparece en modelos de razonamiento a gran escala. El resultado paradójico: los modelos con mayor capacidad de razonamiento son más vulnerables a la maldición del conocimiento. Los modelos que razonan en profundidad asumen implícitamente que el interlocutor puede seguir su proceso de razonamiento. Es exactamente el mismo problema que sufre un experto humano al explicarle algo a un principiante.
Por eso existen dos tipos de roles en el mundo. Los que piensan en profundidad y los que comunican de forma comprensible. Investigadores y divulgadores científicos. Desarrolladores senior y tech leads. Jueces y abogados. Son competencias distintas. Sería ideal que una misma persona dominara ambas, pero en la práctica es raro. Por eso las organizaciones separan los roles.
Con los LLM pasa lo mismo. Y Claude Code hace posible esta separación con una sola línea de configuración.
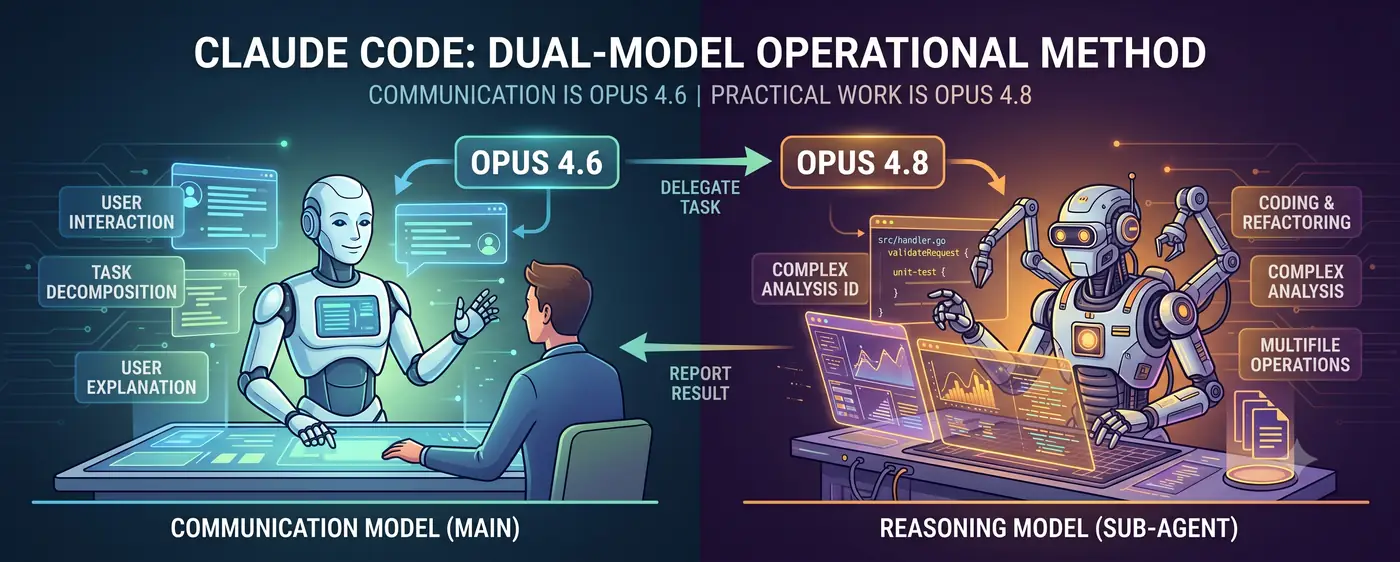
Modelo de comunicación + modelo de razonamiento
La estructura central es simple.
Usuario ↔ Modelo de comunicación (principal) ↔ Modelo de razonamiento (subagent)
- El modelo de comunicación (Opus 4.6) ocupa la primera línea del diálogo. Interpreta la intención del usuario, descompone las tareas y reporta los resultados en un lenguaje comprensible para humanos.
- El modelo de razonamiento (Opus 4.8) se encarga del trabajo pesado. Tareas de razonamiento de alta dificultad como escritura de código, análisis complejos y refactorizaciones multi-archivo se le delegan como subagent.
El usuario conversa con 4.6. Cuando 4.6 juzga que “la dificultad de razonamiento es demasiado alta para hacerlo yo mismo”, crea un subagent 4.8 y le delega la tarea. Cuando 4.8 devuelve el resultado, 4.6 lo interpreta y se lo explica al usuario.
Este artículo es la prueba. Quien escribe ahora mismo es Opus 4.6 (principal), y la búsqueda de artículos académicos y el análisis de datos de benchmarks que sustentan este texto los realizó Opus 4.8 (subagent).
Lo que dicen los benchmarks
Los datos de BenchLM revelan en números el carácter de cada modelo.
| Área | Opus 4.6 | Opus 4.8 | Ventaja |
|---|---|---|---|
| General | 86 | 93 | 4.8 |
| Codificación | 64.4 | 76.4 | 4.8 |
| Tareas de agente | 72.6 | 80.1 | 4.8 |
| Tareas de conocimiento | 76.2 | 70.1 | 4.6 |
| Escritura creativa | Ventaja | - | 4.6 |
4.8 domina en codificación y tareas de agente. Pero en transmisión de conocimiento y escritura creativa, 4.6 va por delante. En las reseñas de la Claude API también se repite la evaluación de que la escritura de 4.8 “suena más a IA (more AI-sounding)” que la de 4.6. 4.8 razona con precisión, pero la capacidad de presentar ese razonamiento de forma legible para humanos es mejor en 4.6.
El precio de ambos modelos es idéntico: $5 por millón de tokens de entrada, $25 por millón de tokens de salida. Separar roles no aumenta el coste. Esto no es optimización de costes sino pura optimización de calidad.
El enrutamiento de modelos ya es ingeniería probada
La idea de “usar dos modelos por separado” no es nueva. En el ámbito académico ya es un campo establecido.
RouteLLM (ICLR 2025) enrutó dinámicamente consultas entre un modelo fuerte y uno débil, reduciendo costes más del doble mientras mantenía la calidad. FrugalGPT (2023) logró rendimiento de nivel GPT-4 con una reducción del 98% en costes mediante cascadas de LLM. La conclusión común de estos estudios es clara: un modelo débil con buena orquestación a menudo supera a un modelo fuerte con mala orquestación.
La propia Anthropic usa este patrón. La implementación de deep-research de Anthropic sigue el patrón orquestador-trabajador, y la configuración multi-agent superó a un único agente Opus 4 en un 90.2%. Según una encuesta, alrededor del 80% de los sistemas multi-agent en producción utilizan la estructura orquestador-trabajador.
Lo que yo hago es la forma más simple de este patrón. No es un router, ni una cascada, ni optimización de costes. Es simplemente que el modelo optimizado para comunicación ocupa la primera línea y el modelo optimizado para razonamiento trabaja detrás. El principio de separación de roles en su forma pura.
Cómo configurarlo
Crear esta estructura en Claude Code es sencillo.
Paso 1: Configurar el modelo principal
Ejecutar Claude Code con Opus 4.6. En la configuración, establecer el modelo predeterminado como claude-opus-4-6-20250610, o seleccionar el modelo al ejecutar. Este será el modelo de comunicación que dialoga con el usuario.
Paso 2: Sobreescribir el modelo en el subagent
La herramienta Agent de Claude Code soporta el parámetro model. Al crear un subagent, basta con sobreescribir el modelo a opus (Opus 4.8).
Agent({
description: "Refactorización de código",
model: "opus",
prompt: "La función validateRequest de src/handler.go..."
})
Eso es todo. El agente principal (4.6) conversa con el usuario, y las tareas de alta dificultad se delegan al subagent (4.8).
Paso 3: Distinguir entre fork y fresh agent
En Claude Code hay dos tipos de subagent.
- fork (
subagent_type: "fork"): Hereda el contexto completo de la conversación actual. Comparte la caché de prompts, lo que reduce hasta un 90% el coste de entrada. Sin embargo, un fork hereda forzosamente el modelo del padre, por lo que la sobreescritura de modelo no aplica. - fresh agent: Comienza con un contexto nuevo. Permite la sobreescritura de modelo. Hay que incluir el contexto necesario directamente en el prompt.
Por tanto, para usar el modelo de razonamiento (4.8), hay que crear un fresh agent. El fork se usa cuando se necesita exploración en paralelo manteniendo el modelo de comunicación (4.6).
Patrones prácticos
| Situación | Método | Razón |
|---|---|---|
| Escritura de código complejo | fresh agent + model: opus | Alta dificultad de razonamiento |
| Refactorización multi-archivo | fresh agent + model: opus + isolation: worktree | Razonamiento + aislamiento necesarios |
| Investigación/exploración en paralelo | fork (mantiene 4.6) | Compartir contexto es ventajoso |
| Lectura/edición simple de archivos | Principal (4.6) directamente | La sobrecarga de delegación es mayor |
| Búsqueda web/investigación | fresh agent + model: opus | Se necesita razonamiento preciso |
Hasta 4-8 worktrees simultáneos es estable. Más allá de eso, la revisión de resultados se convierte en cuello de botella.
Fricciones conocidas
No es perfecto. Hay dos limitaciones conocidas actualmente.
Primera, el problema de filtración de la sobreescritura de modelo. La configuración de model del subagent puede propagarse a los sub-agentes que este cree a su vez. Dado que puede producirse un uso no intencionado de modelos, lo práctico es limitar la profundidad del subagent a un nivel.
Segunda, la ausencia de configuración de modelo por agente. Actualmente Claude Code no soporta oficialmente la función de asignar modelos por tipo de agente en la configuración del proyecto. Hay que especificar el parámetro model en cada llamada a Agent. La comunidad también está solicitando activamente esta funcionalidad.
Ambas fricciones se resolverán a medida que Claude Code evolucione. En el estado actual, solo con la sobreescritura manual ya se pueden aprovechar suficientemente las ventajas de esta estructura.
Comunicador y pensador son roles distintos
En un tribunal, el juez y el abogado trabajan con las mismas leyes, pero sus roles son distintos. El juez dictamina. El abogado explica al cliente lo que significa ese dictamen. Si el juez leyera la sentencia directamente al cliente, el cliente no la entendería. Si el abogado dictara la sentencia él mismo, los fundamentos serían débiles. La separación de roles no es una debilidad del sistema sino una fortaleza.
En la revisión de código pasa lo mismo. La capacidad de un desarrollador senior para encontrar un bug y la capacidad de hacer que un desarrollador junior entienda ese bug son cosas distintas. Es raro que un ingeniero brillante sea también un brillante tech writer. Las organizaciones lo saben, por eso separan los roles.
Con la IA es igual. La capacidad de razonamiento y la capacidad de comunicación son ejes distintos. Y en el proceso actual de entrenamiento de modelos, estos dos ejes tienden a estar en tensión. Maximizar el rendimiento de razonamiento hace que la salida sea comprimida y especializada; maximizar el rendimiento de comunicación reduce la profundidad del razonamiento.
Exigirle a un solo modelo que haga bien ambas cosas es como pedirle a un juez que haga también de abogado. Puede hacerlo. Pero ninguno de los dos roles será óptimo.
La separación entre modelo de comunicación y modelo de razonamiento es un principio estructural válido independientemente de la versión. 4.6 y 4.8 son solo la elección concreta de hoy. Si mañana salen 5.0 y 5.2, se aplica el mismo principio y se redistribuyen. Los modelos se reemplazan, pero el hecho de que “el rol de pensar en profundidad” y “el rol de comunicar de forma comprensible” son distintos, no se reemplaza.
Artículos relacionados
- Ratchet Pattern — Cómo hacer que un agente termine el trabajo
- Por qué tu bucle de agente diverge
- Por qué el drift nunca muere
Lecturas recomendadas (externas)
- RouteLLM: Learning to Route LLMs with Preference Data — Framework para enrutar dinámicamente entre un modelo fuerte y uno débil según la dificultad de la consulta.
- Anthropic: How we built our multi-agent research system — Cómo Anthropic implementó deep-research con el patrón orquestador-trabajador.
Referencias
- Camerer, C., Loewenstein, G. & Weber, M. (1989). The Curse of Knowledge in Economic Settings: An Experimental Analysis. Journal of Political Economy, 97(5), 1232-1254. DOI — Demostración experimental de la maldición del conocimiento.
- Li, W. et al. (2025). Curse of Knowledge: Your Guidance and Provided Knowledge are biasing LLM Judges in Complex Evaluation. Findings of EMNLP 2025. arXiv — Hallazgo de que los modelos de razonamiento más fuertes son más vulnerables a la maldición del conocimiento.
- Ong, I. et al. (2025). RouteLLM: Learning to Route LLMs with Preference Data. ICLR 2025. arXiv — Framework para aprender enrutamiento de LLM con datos de preferencia.