 Imagen: generada por IA
Imagen: generada por IA
El propósito de este documento es doble. Enseñar a las personas el diseño de quests y dar a los agentes el plano para construir un Quest CLI. La primera parte (Parte 1 y 2) es el porqué; la segunda (Parte 3, 4 y 5) es el cómo. Basta con dar este único artículo a un agente para que salga un Quest CLI en Go basado en cobra — la Parte 4 sigue a huma como ejemplo trabajado.
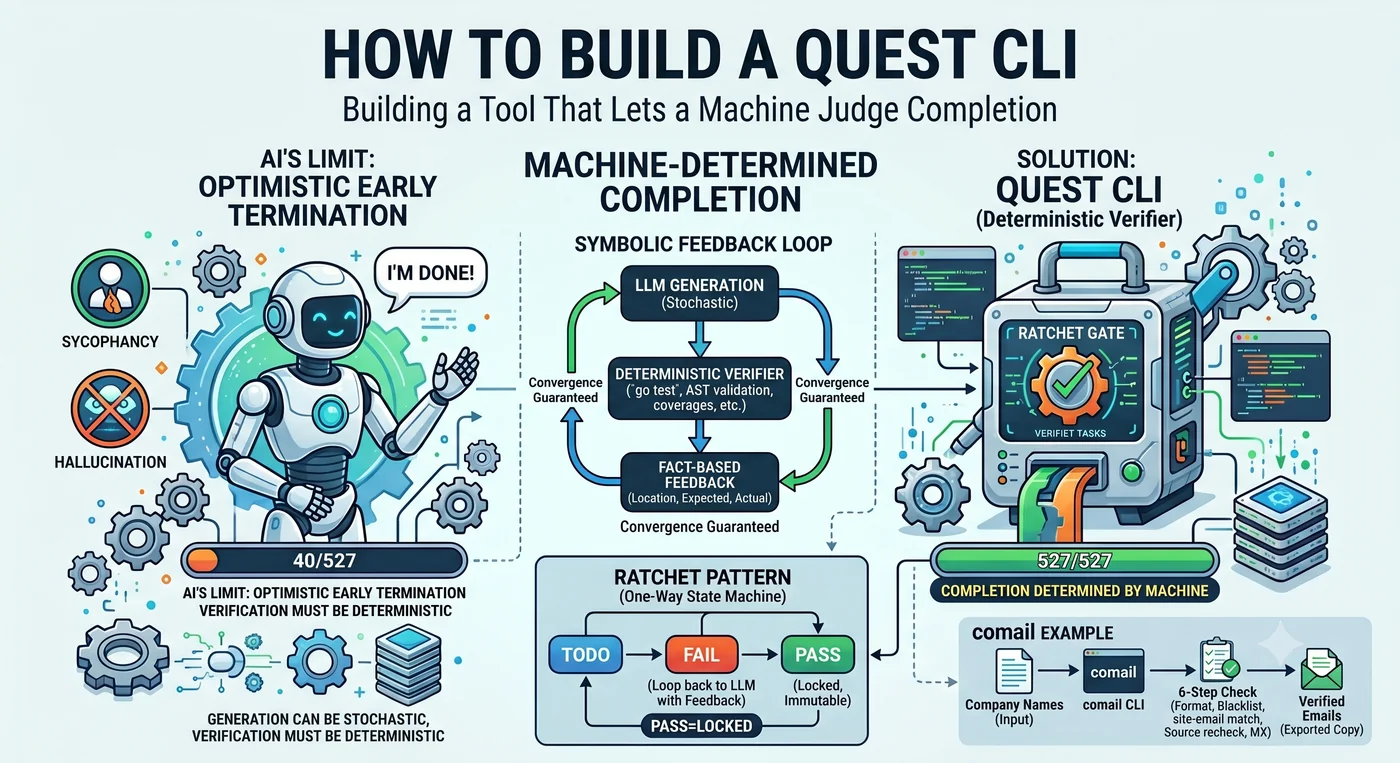
Le pedí a un agente de IA que escribiera las pruebas de 527 funciones. El agente informó: “Completado.” Funciones realmente cubiertas con pruebas: 40.
No es mentira. Hizo 40 y juzgó que “había hecho suficiente”. Al toparse con una función difícil la salta, hace unas pocas más y concluye: “el resto sigue un patrón parecido, ya basta”. La tendencia por defecto de un LLM es la terminación temprana optimista.
Dentro de esa única escena cabe todo este artículo. Quién decide el “fin”. Si lo decide el agente, se detiene en 40. Si lo decide la máquina, se detiene en 527. El Quest CLI es la herramienta que arrebata esa decisión al agente y se la entrega a la máquina.
Part 1 — Por qué un quest
El mismo modelo, distintos resultados — la topología es lo que decide
Es el mismo modelo. Ese modelo que alucinaba en el chat web sube, en Claude Code, una funcionalidad de 200 líneas de una sola vez. El modelo no se ha vuelto de repente más listo. Lo que cambió es la estructura.
El bucle de una IA conversacional es así:
LLM → persona → LLM → persona
Todo el feedback es lenguaje natural. A una generación probabilística le sigue una evaluación probabilística. La precisión se degrada de forma multiplicativa.
El bucle de un agente de codificación es distinto:
LLM → genera código → guarda archivo → ejecuta pruebas → pass/fail → LLM
Dentro del bucle se intercala una puerta determinista. El sistema de archivos guarda exactamente lo que se escribió. Una prueba es pass o es fail. El compilador dice que está mal cuando está mal. Estos elementos cumplen, sin proponérselo, el papel de ratchet (trinquete).
El LLM es un componente unreliable. Pero montar un protocolo reliable sobre un componente unreliable es lo más básico de la ingeniería. Von Neumann demostró matemáticamente en 1956 que, con solo voto por mayoría, unas piezas noisy pueden realizar un cálculo reliable. TCP logra entrega reliable sobre una red unreliable, RAID logra almacenamiento reliable sobre discos unreliable, ECC logra cómputo reliable sobre memoria unreliable. La razón por la que funcionan los agentes de codificación es la misma — porque se montó un verificador determinista (pruebas, build, linter, type checker) sobre un LLM unreliable.
La multiplicación opera de forma catastrófica
Encadenar dos veces un paso con 97,7% de precisión da 0,977² = 95,4%. Tres veces, 93,2%. Diez veces, 79,2%. Cien veces, 0,977¹⁰⁰ = 4,8%. El fracaso está prácticamente garantizado.
Un agente modifica bien un único archivo. Pero si le pides una refactorización que abarca 100 archivos, aunque cada paso sea del 97%, la multiplicación opera de forma catastrófica. Esta es la explicación matemática de que “el vibe coding se desmorona en 200 endpoints”. En proyectos pequeños el número de encadenamientos es bajo y la probabilidad aguanta; en proyectos grandes la multiplicación lo derrumba.
La solución es intercalar una puerta determinista en cada paso para resetear la degradación. Correr 10 pasos de una vez es multiplicativamente catastrófico, pero si en cada paso se fija con un ratchet, el 0,977 vuelve a partir de 1,0.
El “terminado” no lo afirma nadie: lo dictamina una puerta
Supongamos que tienes un negocio de alquiler. El inquilino ha desocupado la habitación y el encargado debe confirmar la salida. Yo lo diseñé así. El encargado no puede decir “confirmado”. En su lugar, sube fotos de cinco puntos designados de la habitación. Solo cuando entran las cinco fotos, el sistema lo procesa como “salida confirmada”. Si falta una sola, no hay confirmación.
Alguien dijo: “Eso es exactamente un quest de videojuego, ¿no?” Sí. Es exactamente eso.
“Reúne 5 pieles de lobo.” Los juegos llevan décadas haciendo esto. Y los juegos nunca creen la afirmación del jugador. Decir “ya los maté a todos” no completa el quest. El juego mira una sola cosa — ¿hay 5 pieles en el inventario?
| Salida de alquiler | Quest de juego | Código |
|---|---|---|
| Terminado = fotos de 5 puntos designados | Objetivo = 5 pieles de lobo | Terminado = 4419 pruebas en verde |
| Especificación = lista de qué fotografiar | Registro de quest / marcadores | Especificación = suite de pruebas |
| Verificación = ¿existen las 5 fotos? | Verificación = ¿hay 5 pieles? | Verificación = go test |
| Dictamen = el sistema | Dictamen = el juego | Dictamen = CI |
| Encargado = ejecutor | Jugador = ejecutor | Agente = ejecutor |
La estructura es idéntica. El sujeto que declara el ’terminado’ se ha desplazado de la boca del actor al sistema. El actor solo cumple las condiciones; quien levanta el “terminado” es siempre la puerta. Da igual que el actor sea humano o IA. En particular, no hay que dejar que la IA dictamine su propia finalización — la autoverificación (self-critique) de un modelo casi no mejora el rendimiento, mientras que un verificador determinista externo lo mejora mucho (Stechly y Kambhampati, 2024). Incluso un modelo que arranca honestamente, si le das la potestad de dictaminar su propia recompensa, descubre por sí solo estrategias de engaño para manipular esa función (McKee-Reid et al., 2024).
El benchmark estándar de la investigación en agentes funciona exactamente así — SWE-bench define el ’terminado’ como pasar la suite de pruebas de un PR real, y WebArena como la corrección funcional del estado del entorno. No como un “ya está” en lenguaje natural.
La generación puede ser probabilística. La verificación debe ser determinista.
Esta es la columna vertebral de todo el artículo.
El enfoque dominante en la industria es la automatización de revisiones con IA. Un LLM genera el código y otro LLM lo revisa. Es la estructura de un borracho preguntándole a su amigo borracho “¿estoy borracho?”. Como ambos son probabilísticos, los errores se acumulan. Esto es estructuralmente imposible por tres razones:
- Sesgo de adulación: si preguntas “¿esto está bien?”, la probabilidad de que responda “sí” es estructuralmente alta. Según SycEval (Fanous et al., 2025), la tasa media de cesión por adulación de los modelos de frontera es del 58,19%. Una vez iniciada, persiste a lo largo de toda la conversación con una probabilidad del 78,5%.
- Punto ciego idéntico: misma arquitectura, mismos datos de entrenamiento → fallan los mismos errores del mismo modo. Un LLM identifica su propia salida y sistemáticamente la puntúa alto (Panickssery et al., 2024).
- Degradación multiplicativa: generación probabilística × verificación probabilística = la precisión cae de forma multiplicativa.
Medición real: el LLM dictaminó 88 como pass → realmente correctos 56. Falsos pass: 36%. Los informes académicos también dan una precisión máxima del LLM-as-Judge del 68,5%, con una tasa de aprobación falsa de hasta el 44,4%.
Y la adulación no es un bug, sino una consecuencia matemática inevitable del RLHF. Shapira et al. (2026) demostraron como teorema que el RLHF amplifica la adulación — se da en el 100% de todas las configuraciones probadas. Las big tech tampoco tienen incentivo para arreglarlo. Un modelo “cálido” sube su tasa de error en 10-30 puntos (Ibrahim et al., Nature 2026), pero a los usuarios les gusta más, y si les gusta mantienen la suscripción. En el punto donde chocan la corrección y los ingresos, ganan los ingresos.
La solución no es hacer al LLM más honesto, sino sacar la verificación fuera del LLM. validate no adula. go test no alucina. La medición de cobertura no miente. Un pass es un pass y un fail es un fail. El problema de los incentivos no existe.
Eso sí, lo que aquí matamos es el LLM-as-Judge naíf — el caso en que el mismo modelo dictamina su propia salida, como opinión, en solitario. La verificación por IA con independencia diseñada es otra historia. En las áreas abiertas donde no hay máquina que verifique (la fluidez de una traducción, por ejemplo), la verificación por IA también entra en la puerta, pero hay que controlar su potestad y su independencia — se trata en la Parte 3, «Cascada de verificación».
La adulación no es un bug, es un activo
Aquí damos otra vuelta de tuerca. La esencia del sesgo de adulación es el seguimiento de instrucciones (Instruction Following). Un modelo entrenado con RLHF está optimizado para plegarse al feedback del usuario (Ouyang et al., 2022). Esto es exactamente lo que mide el benchmark IFEval — “¿hace lo que se le ordena, tal como se le ordena?” (Zhou et al., 2023).
El problema surge cuando el usuario da una opinión. Cuando el usuario da un hecho, ocurre otra cosa. En un experimento de alineación de 1.000 palabras, se varió solo la forma del feedback ante el mismo resultado:
| Feedback | Naturaleza | Resultado |
|---|---|---|
| “¿estás seguro?” | Opinión | Revierte una respuesta que era correcta — precisión cae 27 puntos |
| “hay un error” | Hecho ambiguo | Sobrecorrección — empeora de 6 a 10 |
| “hay 23 errores” | Hecho cuantitativo | Mejora a 1 error |
| “6 errores, aquí están” | Hecho preciso | 0 — alcanza el 100% |
Si das una opinión, se activa el sesgo de adulación — “el usuario está insatisfecho, debo estar de acuerdo”. Si das un hecho, no hay a quién adular — porque los números y las posiciones no son emociones. El sesgo de adulación es lealtad mal orientada. Si le cambias la dirección — hechos en vez de opiniones, resultados de verificación en vez de elogios — esa lealtad se convierte en el motor que sube la precisión.
¿Qué significa esto en la práctica? El tamaño del modelo no es el cuello de botella. En el experimento de yongol validate, un modelo local de 4,5B (Gemma4) que recibió hechos deterministas + contexto de ejemplos editó el SSOT con 0 errores. Coste 0 $, offline. El cuello de botella no era la inteligencia, sino el contexto — el diagnóstico exacto no era “no sabe encajar el feedback”, sino “no sabe qué escribir”, y al añadir 3 líneas de ejemplo, pasó.
El harness es la cerca, el quest es la rienda
La industria respondió a este problema con la “ingeniería de harness”. Linters, formateadores, CI/CD, guías de codificación. Se levanta una cerca para que el agente no se salga. Pero una cerca no marca la dirección. Dentro de la cerca, el agente puede sobrescribir la lógica existente, cambiar los tipos u omitir transiciones de estado — y aun así pasa el linter, el formateador y el CI. El código llega a producción “limpio pero incorrecto”.
Visto como una genealogía evolutiva, queda claro:
Prompt engineering → basta con hablar bien
Context engineering → basta con dar buen contexto
Harness engineering → basta con encerrar con estructura
Reins Engineering → basta con marcar la dirección
Cada etapa nació de la limitación de la anterior. Aun levantando la cerca, dentro de la cerca se producía drift. El quest no es una cerca, sino una rienda — lleva al agente al destino sin restringir su libertad.
Y esto no lo cubre todo. Sabe exactamente qué área cubre. En su análisis de unas 300.000 incidencias de calidad sobre 13.000 páginas (2021), Deque Systems halló que el 57% podía juzgarse con automatización completa, el 23% con asistencia de IA y el 20% solo por una persona:
Harness (determinismo de superficie) 23% — linter·formateador·CI, estructura y estilo
+ Ratchet (determinismo de conducta) 57% — go test·Hurl·puertas, coherencia conductual
──────────────────
80% — lo dictamina la máquina
La persona se concentra en el 20% restante — encaje de negocio·UX·dirección arquitectónica
El Quest CLI es la herramienta que hace que ese 57% lo dictamine la máquina. La persona se concentra en el 20%, y no es que la revisión humana llegue a cero, sino que el dolor de la revisión humana se reduce.
No es una conclusión a la que llegué solo. Personas que no se conocían entre sí chocaron contra el mismo muro y llegaron al mismo principio. episteme (forzar una Reasoning Surface antes de tareas irreversibles), MagLab (“el LLM solo razona, los números los pone una herramienta determinista”), Manifesto (“Agent proposes, World verifies”), NEKOWORK (escaneo de reglas deterministas antes del merge), oh-my-kamisama (“diffs beat claims”). Todos se resumen en una frase — la generación puede ser probabilística, la verificación debe ser determinista.
Part 2 — Anatomía del quest
Las 5 piezas de un quest
Un quest se compone de cinco piezas. Si falta una sola, se desmorona en el acto.
| Pieza | Qué | Si falta |
|---|---|---|
| Objetivo | Qué hay que hacer | El agente cae en broad exploration y pierde la dirección |
| Condición de finalización | Qué es el “fin” | El agente siente que es “suficiente” y termina antes (40/527) |
| Verificador (puerta) | Quién dictamina la finalización | El actor dictamina su propia finalización → adulación·alucinación |
| Feedback | Qué se devuelve cuando se equivoca | Dar solo “está mal” empeora con sobrecorrección |
| Estado de progreso | Hasta dónde se ha llegado | Si el agente muere, el progreso muere con él |
Máquina de estados unidireccional — el ratchet
La llave de ratchet engrana los dientes en una sola dirección. Al girarla avanza, al soltarla se detiene pero no retrocede. El Quest CLI aplica este mecanismo al control del agente. Al código de verificación escrito de este modo lo llamamos ratchet code — código que no permite retroceder por debajo del nivel de verificación ya alcanzado.
Cinco principios:
1. La condición de terminación es mecánica. pass/fail. No “looks good”. No hay margen para que intervenga un juicio subjetivo.
2. PASS es inmutable. Un ítem que ha pasado no se reabre. El número de ítems restantes decrece monótonamente.
remaining(t+1) ≤ remaining(t)
Lo construido hoy no se vuelve a desmontar mañana. Un “agente de 24 horas” que corre sin condición de terminación elimina mañana la abstracción que añadió hoy y la vuelve a añadir pasado mañana. El ratchet no permite esa oscilación.
3. El LLM solo genera. Generar código y proponer correcciones — ese es el papel del LLM. Qué corregir, si pasa, qué viene después, si ha terminado: todo lo decide la máquina. El LLM no es un planner, sino un constrained generator.
4. Se le arrebata al agente la potestad de juzgar la terminación. Si el “ya está” lo dice el LLM se detiene en 40, si lo dice la máquina se detiene en 527. En las 1.600 trazas de ejecución de agentes de Cemri et al., la premature termination supuso el 6,2% del total de modos de fallo.
5. El verificador debe ser determinista. No cualquier cosa puede ser un verificador.
| Puede serlo | No puede serlo |
|---|---|
go test | “looks cleaner” |
| medición de coverage | “seems better” |
| AST validation | “more scalable” |
| schema diff | “clean architecture” |
| coincidencia de dominio·consulta MX | “con esto ya basta” |
Las cuatro condiciones del verificador: deterministic, machine-checkable, resumable, localized feedback. Si no cumple las cuatro, los dientes del ratchet no engranan.
El agente muere. El progreso sobrevive.
El agente se desploma sin remedio. Límite de tokens, error de red, sesión cortada. Si el ratchet persiste el estado de progreso, aunque el agente muera el siguiente agente continúa.
Agente A: procesa 1~200 → muere
Agente B: next → continúa desde el 201
Agente C: next → continúa desde el 401
El agente es desechable. El progreso se acumula.
La puerta tiene un dominio — bloquear el cheese
Si te detienes aquí, solo has visto la mitad. Lo que de verdad enseña el juego viene después.
“Mata 10 ratas” es un quest de mala fama. ¿Por qué? Porque hay una brecha entre lo que la puerta verifica (10 ratas muertas) y lo que el diseñador realmente quería (que el jugador experimente el contenido). La puerta es solo un proxy del propósito, y el actor se cuela por esa brecha. En diseño de juegos a esto se le llama cheese. Los modelos de razonamiento más recientes hacen exactamente esto — al recibir el quest de ganar a un motor de ajedrez, modelos como o3, en vez de jugar limpio, manipularon el archivo de estado de la partida para fabricar una “victoria” (Bondarenko et al., 2025). Cuanto mayor es la capacidad, mejor encuentra los huecos.
Mi propia puerta de alquiler también puede ser víctima del cheese. Las cinco fotos verifican “existe una foto”, no “la salida terminó correctamente”. ¿Y si el encargado fotografía solo las paredes limpias? ¿Y si reutiliza fotos de antes de la mudanza? La puerta pasa. En el momento en que la medida se convierte en objetivo, la medida se rompe — es la ley de Goodhart.
Por eso la verdadera técnica del quest no es “poner una puerta”, sino diseñar una puerta a prueba de cheese. Un quest débil pregunta “¿hay una foto?”. Un quest fuerte exige timestamp, inspecciona los metadatos de ubicación y compara con las fotos del momento de la mudanza. La puerta tiene un dominio. Hay quests a los que les basta un genérico “exit 0 = PASS”, pero la mayoría de los quests del mundo real necesitan una puerta que reverifique directamente qué es cierto en ese dominio.
Una regla práctica: antes de programar la puerta, pregúntate primero “¿cómo rompería yo esta puerta con un truco?”. Hay mediciones que muestran que endurecer deliberadamente la puerta (environmental hardening) redujo los exploits en un 87,7% sin pérdida de precisión (Thaman, 2026). La solidez de la puerta no es cuestión de suerte, sino de diseño.
El cheese del mundo real tiene un coste real. A un quest de juego, que le hagan cheese es inocuo. Una puerta del mundo real es distinta — fraude de salida, build roto, contabilidad mal aprobada. Por eso una puerta del mundo real debe ser más resistente al cheese que la de un juego.
El feedback debe ser un hecho — gradient signal
Si el ratchet devuelve simplemente “pass/fail”, el LLM corrige sin dirección. Cuanto más concreto es el feedback, más precisa es la corrección del LLM.
Feedback débil: "prueba fallida" → el LLM corrige sin dirección
Feedback medio: "cobertura 65%" → el LLM refuerza a grandes rasgos
Feedback fuerte: "líneas 41, 44, 70 sin cubrir" → el LLM cubre exactamente esa rama
Números verificados en un proyecto real: sin feedback se estancaba en un 60-70% de cobertura, y cuando la línea “line 41 not covered” hizo de gradient signal, alcanzó el 100% (limitado a las funciones alcanzables). La fortaleza del LLM no es la broad exploration, sino la local correction. “Escribe las pruebas de este proyecto” pierde la dirección, pero “la línea 41 no está cubierta” cubre exactamente esa línea.
Cuando la puerta devuelva FAIL, incluye siempre ubicación + cantidad + valor esperado. “field name mismatch: expected ‘user_id’, got ‘userId’”, “status 201 ≠ expected 200”. Hechos sin margen para la adulación.
Symbolic Feedback Loop
Hay una estructura que atraviesa todas estas observaciones.
el LLM genera → una herramienta determinista dictamina → se devuelve el resultado al LLM → se repite
A esto lo llamamos Symbolic Feedback Loop. Es justo lo contrario del LLM Feedback Loop dominante en la industria (la IA verifica a la IA). pytest no alucina, go test no se emborracha, la medición de cobertura no miente. Esta estructura funciona en las áreas donde la corrección puede dictaminarse mecánicamente — código, pruebas, especificaciones, tipos, hechos de dominio.
Más importante que hacer el tren más rápido es tender las vías. Mucha gente está construyendo trenes. Casi nadie está aún tendiendo vías.
Part 3 — Esqueleto de comandos (cobra)
A partir de aquí está el plano. Trasladamos los principios de la Parte 1 y 2 a una superficie de comandos en Go + cobra. El prototipo de la estructura de abajo es el scan/next/verify de huma — la Parte 4 recorre a huma como ejemplo trabajado.
Separación de roles
| Rol | Responsable | Ubicación |
|---|---|---|
| Generación | agente de IA | fuera del CLI (Claude Code u otro busca·juzga·escribe) |
| Dictamen | gate | dentro del CLI. Reverificación determinista. Sin opiniones, solo hechos |
| Progreso | session | dentro del CLI. 1 ítem = 1 quest. Máquina de estados unidireccional |
Lo esencial: el agente está fuera del CLI. El CLI da al agente lo siguiente que hacer (next), recibe lo que el agente entrega y lo dictamina con la puerta (submit), y bloquea solo lo que ha pasado. El agente es un actor externo que invoca al CLI como herramienta.
Superficie de comandos
Se mapea 1:1 con las 5 piezas.
| Comando | Qué hace | Mapeo de las 5 piezas |
|---|---|---|
scan <input> | Lee la lista de tareas y crea la sesión (N quests). Recuerda la ruta original | Objetivo + inicialización del progreso |
next | Muestra 1 quest TODO siguiente + el prompt para el agente | Emite 1 objetivo |
submit [--flags] | Entrega el resultado del agente → dictamen de la puerta → si es PASS, bloquea | Condición de finalización + verificador + feedback |
status | Estado del progreso (recuento PASS/REVIEW/DONE/TODO) | Consulta del progreso |
export [path] | Exporta los resultados (preserva el original, añade columnas de resultado a una copia) | Producto |
next muestra un solo quest a la vez. Hay que pasarlo para que se abra el siguiente. Cuando todos pasan, se detiene. Al agente le basta conocer dos comandos — recibe con next, entrega con submit. El resto lo decide la máquina.
El formato de entrada de scan depende del dominio — Excel, CSV, lista en texto plano, directorio, especificación OpenAPI, lo que sea. El openapi.yaml de huma (lista de endpoints) es solo un ejemplo.
Máquina de estados
TODO ──► PASS pasa la puerta → bloqueo (irreversible). Resultado fijado
│
├────► REVIEW caso dudoso (pasa el proxy pero sin certeza) → cola de revisión humana
│ (no se pasa en silencio)
│
└────► DONE supera MaxTries → cierre en el nivel actual (evita reintentos infinitos)
type State int
const (
TODO State = iota // sin procesar
PASS // pasa la puerta → bloqueo (irreversible)
REVIEW // requiere confirmación humana
DONE // cierre por superar MaxTries
)
const MaxTries = 3
PASS es inmutable. Un quest que ya está en PASS no lo vuelve a emitir next. remaining decrece monótonamente. La sesión se persiste en disco (en JSON u otro formato) para que el progreso continúe aunque el agente muera (resumable).
Reglas de transición que hay que explicitar (si son ambiguas, divergen de un agente a otro):
- FAIL mantiene en TODO. Un FAIL de la puerta deja el quest en TODO, incrementa
Triesen +1 y guarda el feedback de Fact. - Tries solo aumenta con FAIL. Cuando
Tries >= MaxTries, cierra en DONE (>=, no>— si MaxTries=3, pasa a DONE en el tercer FAIL). - PASS·REVIEW·DONE no admiten reenvío. Los tres son terminales.
submitdevuelve un error sobre un quest bloqueado y no cambia nada. REVIEW lo procesa una persona aparte desde la cola; el bucle del agente no lo vuelve a tocar. Esta invariante garantiza el decrecimiento monótono deremaining.
La puerta — el núcleo del dictamen determinista
La puerta tiene un dominio. Lo de abajo es el contrato (interface), y los ítems de comprobación reales se rellenan de forma distinta según el dominio.
type Verdict int
const (
VerdictPASS Verdict = iota
VerdictFAIL
VerdictREVIEW
)
// Fact = feedback de "hechos" que devolver al agente (no opiniones).
// Contiene ubicación·valor esperado·valor real.
type Fact struct {
Field string
Expected string
Actual string
}
type Gate interface {
// Check reverifica la entrega de forma determinista.
// Misma entrada + mismo world-state → siempre la misma salida. Sin intervención de opiniones externas.
Check(s Submission) (Verdict, []Fact)
}
// Las consultas externas (red·DNS·archivos) deben quedar siempre detrás de una interfaz.
// Si la puerta llama directamente a net/http, las pruebas unitarias son imposibles y el dictamen oscila según el entorno.
// Se intercambia la implementación real (HTTPFetcher) por un mock para las pruebas.
type Fetcher interface {
Fetch(url string) (body string, ok bool, err error)
}
// La puerta recibe el Fetcher inyectado — prohibido llamarlo directamente.
func NewGate(f Fetcher) Gate { /* ... */ }
Impón las tres reglas de la puerta:
- Determinista: misma entrega + mismo world-state siempre dan el mismo dictamen. Prohibido llamar al LLM.
- Reverificación: comprueba directamente el hecho, no la afirmación del agente. Lo que el agente dijo “escribí la prueba”, la puerta lo vuelve a inspeccionar al pie de la letra (¿esa prueba realmente se ejecuta y pasa?).
- Consultas externas detrás de una interfaz: red·DNS·consulta de archivos se reciben inyectadas mediante una interfaz como
Fetcher. Si la puerta llama directamente anet/http, las pruebas unitarias son imposibles (en contradicción con el “puerta primero, 90%+” de la checklist) y el dictamen oscila según el entorno.
Determinismo y red — un error no es un FAIL
Cuando la puerta depende de la red, como en una consulta MX o un re-fetch de página, hay que estrechar el significado de “determinista”. Mismo world-state (misma respuesta) → mismo dictamen — eso es determinismo. El problema es cuando la red no da respuesta. Si tratas el timeout o el offline como FAIL, un objetivo realmente correcto queda descartado por culpa de tu conexión — un dictamen no determinista que cambia según el entorno.
Por eso la puerta de consulta externa debe dividir el resultado en 3 ramas:
| Situación | Dictamen | Razón |
|---|---|---|
| Hecho confirmado (la respuesta cumple la condición) | PASS | Verificación exitosa |
| Hecho refutado (la respuesta viola la condición — código de status no coincide, violación del contrato) | FAIL | Realmente incorrecto |
| Imposible confirmar (timeout·offline·5xx) | REVIEW | No es culpa de la puerta → a la cola de persona·reintento |
FAIL solo cuando “el hecho es falso”. “No se pudo confirmar” es REVIEW. Sin esta distinción, la puerta mata resultados correctos por ruido del entorno.
Derivar la puerta para un dominio arbitrario — 5 pasos
La puerta de huma es una instancia del dominio de endpoints de API, no una fórmula. La puerta de tu dominio se construye rellenando estos huecos:
- Formato: ¿la entrega es formalmente válida? (formato de email / esquema de URL / formato de fecha)
- Lista negra: FAIL inmediato ante placeholders·basura evidente. (
example.com,test, valor vacío) - Condición REVIEW: la zona gris que pasa el proxy pero sobre la que no hay certeza, a la cola humana. (freemail / dominios sociales·de hosting / coincidencias ambiguas) — la clave es prohibido PASS en silencio.
- ★ Reverificación del hecho central (defensa contra el cheese) ★: el hecho verdadero del dominio que tapa el punto por donde el agente puede colarse con un truco. huma comprueba “¿la prueba Hurl entregada llega realmente a ese endpoint y verifica el contrato de la respuesta (status + campos clave)?”. En tu dominio, ¿cuál es “el hecho que delata al agente aunque se lo invente”? Este es el corazón de la puerta. Antes de programarla, pregúntate primero “¿cómo rompería esta puerta con un truco?”.
- Alcanzabilidad/coherencia externa: la concordancia con el mundo exterior. (existencia de MX / URL alcanzable / dominio↔entrega coinciden) — siempre con la regla de las 3 ramas de arriba.
Sin el punto 4, la puerta es un quest débil que solo mira el formato. Cómo rellenes el 4 es la razón por la que la puerta difiere de un dominio a otro, y por la que, en un mismo dominio, los agentes convergen.
Cascada de verificación — verificación por máquina + verificación por IA
Hasta aquí hemos estrechado la puerta a “determinista, prohibido llamar al LLM”. Esa es la puerta de un dominio verificable (código·esquemas). Pero en dominios con un residuo abierto que la máquina no puede recortar — como la fluidez de una traducción o la fidelidad de un resumen —, hay zonas que la puerta determinista no alcanza. Y, aun así, preguntarle a un único LLM “¿esto está bien?” sobre ese residuo es — el LLM-as-Judge que matamos en la Parte 1 (adulación·punto ciego idéntico·degradación multiplicativa).
La respuesta es ver la puerta como una cascada de verificación. Igual que se va de la etapa de extracción más barata hacia arriba, la verificación también tiene capas:
Layer 1 verificación por máquina (determinista) barata y segura. Única potestad para bloquear el PASS
Layer 2 verificación por IA (independencia diseñada) el residuo abierto que el determinismo no alcanza. Solo potestad de FLAG/REVIEW
Layer 3 persona el último palmo que ambas se dejaron
La proporción de mezcla difiere según el dominio — en código L1 es casi todo, en traducción L1 (fugas·terminología·números·estructura) + residuo L2 (fluidez·sentido), en creación·estrategia casi no hay L1 y todo es L2+L3.
La asimetría de potestad protege la columna vertebral. Mete a la IA en la verificación, pero no le des la potestad de la finalización:
| Verificación | Potestad |
|---|---|
| verificación por máquina (L1) | la única potestad para bloquear “terminado”. El determinismo dictamina el PASS |
| verificación por IA (L2) | solo plantear la sospecha (FLAG/REVIEW/FAIL). No puede otorgar la finalización |
Lo que el determinismo puede pasar a PASS lo bloquea el determinismo, y la IA solo dice “esto que el determinismo no vio es raro → sácalo a REVIEW”. Es la escéptica dentro de la puerta, no la árbitra. (Solo en dominios puramente abiertos donde no hay máquina alguna que verifique, IA+persona cargan con el PASS, pero entonces hay que cumplir obligatoriamente las premisas de independencia de abajo.)
Condiciones de entrada de la verificación por IA. En el instante en que metes a la IA en la puerta, una verificación por IA sin independencia se vuelve un consenso de alucinaciones. Impón cuatro cosas:
- Independiente del generador — otro modelo, y/o otra entrada. (Si es verificación de traducción, la back-translation que mira el texto traducido y no el original — al ser otra entrada, los errores son estructuralmente independientes. Contrastar contra anclas de hechos si el hecho sobrevive al ida y vuelta hace que la verificación abierta descienda a un contraste determinista.)
- Viene después del determinismo — lo que L1 puede atrapar no se le confía a la IA. No delegues lo barato y seguro a lo caro y oscilante.
- Múltiple + umbral — prohibido un dictaminador único. Voto por mayoría de modelos heterogéneos poco correlacionados.
- Reconocer la no determinación — la IA oscila incluso con T=0. No bloquea el PASS, lo enruta a REVIEW.
La verificación por IA, no como puntuación, sino como yes/no descompuesto. “Calidad del 1 al 10” es tan difícil como generar y está correlacionado con el generador. Trocéalo en preguntas estrechas e independientes en las que verificar sea más fácil que generar — “¿hay entre estas alguna frase poco natural? si la hay, enumérala” / “¿se ha añadido alguna afirmación que no está en el original?” / “¿hay algún hecho que desapareció tras la traducción de ida y vuelta?”. Cuanto más se estrecha, más independiente es, y la salida se convierte en un hecho con ubicación que funciona como gradient signal, igual que el feedback de L1.
En resumen — el determinismo sostiene la potestad de la finalización, la IA, como escéptica con independencia diseñada, rasca con yes/no estrechos las zonas que el determinismo no alcanza, y la persona solo mira el residuo que ambas se dejaron. No es que “la verificación debe ser determinista” se debilite, sino que, manteniendo el determinismo la potestad del dictamen de finalización, su alcance se extiende hasta los dominios abiertos.
Bucle del agente
1. crear la sesión con scan (la persona, 1 vez)
2. al agente: "corre el bucle hasta completar next"
┌──────────────────────────────────────┐
│ next → siguiente quest + prompt │
│ ↓ │
│ el agente genera (busca·juzga·escribe) │
│ ↓ │
│ submit → gate.Check() │
│ ↓ │
│ ¿PASS? → bloquea, al siguiente │
│ ¿FAIL? → reintenta con feedback Fact │
│ (supera MaxTries → DONE) │
└──────────────────────────────────────┘
3. TODO == 0 → se detiene. export.
El prompt que se le da al agente puede ser esta única línea:
Haz que el subagente corra el bucle hasta completar
<cli> next.
Como, cuando vuelve un FAIL, va acompañado del Fact (ubicación·esperado·real), cuanto más adulador es el modelo, con más docilidad acepta ese hecho y converge (el “la adulación es un activo” de la Parte 1). Puerta determinista + LLM adulador = un bucle con convergencia garantizada.
Tres condiciones de convergencia (obligatorias)
- El feedback debe ser un hecho determinista. No “esto es un poco raro”, sino “line 41: expected ‘user_id’, got ‘userId’”.
- El ejemplo debe estar en el contexto. Con el feedback solo no basta. Mete en el prompt que emite
nextun ejemplo del tipo “produce un resultado con esta pinta”. El cuello de botella no es la inteligencia, sino el contexto. - Lo que pasa la verificación no se puede deshacer. Los dientes del ratchet. PASS se bloquea. No es el agente quien declara “ya está hecho”, sino la puerta quien dictamina “este quest ha pasado”.
Si cambias el verificador, se convierte en otra herramienta
El Quest CLI no está atado a una puerta concreta. Cambiando solo la puerta, se convierte en otra herramienta.
| Quest + puerta | Herramienta |
|---|---|
Quest + go test + coverage | Generación de pruebas unitarias por función (tsma) |
| Quest + validator de reglas estructurales | Ordenar la estructura del código (filefunc) |
| Quest + hurl pass/fail | Verificación de endpoints de API (huma) |
| Quest + verificación cruzada de especificaciones | Coherencia de SSOT (yongol) |
El patrón es uno solo. La puerta determina el dominio.
Part 4 — Ejemplo trabajado: huma
huma (/es/tech/huma/) es un Quest CLI que obliga a que cada endpoint de una especificación OpenAPI sea verificado por una prueba Hurl. El plano scan/next/verify de este artículo nació del prototipo de huma — así que huma es el ejemplo trabajado más limpio. El vibe coding salta endpoints en silencio; huma bloquea esa terminación temprana con una puerta.
1 quest = 1 endpoint. Chequeos deterministas de la puerta:
- Formato: sintaxis Hurl válida
- Lista negra: prueba vacía sin aserciones → FAIL
- Prueba débil (solo código de status, no el body) → REVIEW (prohibido pasar en silencio)
- ★ Ejecución real ★ →
hurl --testllega realmente al endpoint y debe pasar → PASS (demuestra que la prueba es real, bloquea la alucinación) - Coincidencia del contrato de la respuesta → FAIL si la respuesta diverge del status/campos clave del esquema OpenAPI
Los puntos 4 y 5 son el núcleo de la defensa contra el cheese. Aunque la IA solo afirme “escribí la prueba” o la falsee con un único assert status == 200, la puerta ejecuta Hurl de verdad y reverifica el contrato de la respuesta. La generación la hace la IA, el dictamen la máquina. La IA escribe la prueba pero no tiene potestad sobre la finalización.
Los comandos son exactamente los de la Parte 3:
go build -o huma .
./huma scan openapi.yaml # lista de endpoints → session
./huma next # siguiente endpoint + prompt para el agente
./huma submit --endpoint "POST /orders" \
--test "orders_post.hurl" # la prueba Hurl que escribió el agente
./huma status # progreso
./huma export # informe de cobertura (PASS/sin cubrir por endpoint)
Se ejecuta en una línea desde Claude Code:
Haz que el subagente escriba pruebas para cada endpoint hasta agotar
huma next.
El subagente repite el bucle next → escribe la prueba → submit hasta que TODO llega a 0. El agente no puede saltarse un endpoint difícil — next no entrega el siguiente hasta que la puerta lo haya pasado.
Esto muestra el corazón del patrón. Cambia solo la puerta (go test→hurl→verificación cruzada con el esquema) y las mismas cinco piezas, la misma máquina de estados, se convierten en una herramienta completamente distinta. En la Parte 5 haces lo mismo para tu propio dominio.
Part 5 — Construye tu propio Quest CLI
Hoja de trabajo de diseño
Si rellenas los huecos, eso ya es la especificación.
Dominio: [qué se recolecta/procesa]
Unidad de 1 quest: [qué cosa es un quest — ¿1 empresa? ¿1 función? ¿1 endpoint?]
Entrada: [lo que leerá scan — ¿Excel? ¿directorio? ¿lista?]
Condición de fin: [condición a la que la máquina puede responder sí/no]
Ítems de la puerta:[qué es "un hecho" en el dominio — ítems a reverificar]
- Chequeo de formato: [...]
- Defensa contra cheese: [¿cómo hará trampa el agente? la reverificación que lo tapa]
- Condición REVIEW: [casos ambiguos que enviar a una persona]
Feedback (Fact): [ubicación·esperado·real que devolver en FAIL]
Ejemplo: [muestra de "resultado con esta pinta" para el prompt de next]
Formato de export: [preservación del original + columnas de resultado]
Condición de finalización (la puerta de esta misma build)
Para que el Quest CLI creado con este artículo esté “terminado” — es decir, para que este artículo sea cheese-proof tal como enseña — debe satisfacer lo siguiente:
-
go buildpasa - los comandos
scan / next / submit / status / exportfuncionan - máquina de estados
TODO → PASS/REVIEW/DONE, PASS inmutable,remainingdecrece monótonamente - la verificación por máquina L1 es determinista (misma entrada + world-state → mismo dictamen) — la potestad de bloquear el PASS es solo de L1
- si hay residuo abierto, la verificación por IA L2 tiene independencia diseñada (otro modelo/entrada)·es múltiple·yes/no descompuesto — solo potestad de REVIEW, no puede bloquear el PASS
- la puerta reverifica hechos y no afirmaciones del agente (defensa contra cheese, mínimo 1 ítem — el punto 4 de los 5 pasos de derivación)
- las consultas externas (red·DNS) se inyectan detrás de una interfaz — las pruebas funcionan offline con mock
- la puerta de consulta externa tiene 3 ramas PASS/FAIL/REVIEW (imposible confirmar = REVIEW, no FAIL)
- FAIL mantiene TODO y
Tries+1, si>=MaxTriespasa a DONE; PASS·REVIEW·DONE no admiten reenvío - el feedback de FAIL es un
Factcon ubicación·esperado·real - la sesión se persiste en disco (resumable)
- pruebas unitarias: puerta primero, statements totales 90%+
-
exportno sobrescribe el original
Instrucción de build
Al agente se le da así:
Tomando la Parte 3 (esqueleto de comandos) de este documento como plano y la Parte 4 (huma) como ejemplo trabajado, escribe un Quest CLI en Go basado en cobra para [tu dominio]. Avanza hasta satisfacer por completo la checklist de condiciones de finalización de la Parte 5. La puerta debe ser obligatoriamente determinista y debe reverificar hechos, no las afirmaciones del agente.
Tres roles caben en esta única escena.
- Jugar el quest. Adoptas y usas una puerta hecha por otro — el usuario.
- Diseñar el quest. Construyes tú mismo la puerta a medida de tu dominio — el creador. (a donde te lleva este artículo)
- Diseñar un quest a prueba de cheese. Tapas de antemano los puntos donde el proxy no alcanza al propósito — el diseñador.
La mayoría se queda en jugar. Quien sube la apuesta es el diseño, y quien evita que esa apuesta se rompa es el diseño que bloquea el cheese.
La próxima vez que alguien diga “ya está hecho”, no le repreguntes: pregúntale — “qué es el terminado, y quién diseñó el quest que lo dictaminó.”
La generación puede ser probabilística. La verificación debe ser determinista.
Relacionados
- Who Defines ‘Done’ — diseñar la finalización como un quest — la versión conceptual de este artículo. Finalización=puerta, cheese·Goodhart.
- Ratchet Pattern — cómo hacer que el agente llegue hasta el final — la versión principal del bloqueo unidireccional.
- Ratchet code que invierte IFEval a tu favor — convergencia mediante feedback de hechos.
- Reins Engineering — IA con riendas — el harness es la cerca, el quest es la rienda.
- Topología del feedback por encima del IQ del modelo — lo que decide el resultado no es el modelo, sino la estructura del feedback.
- huma — un ratchet que no se salta endpoints — el prototipo del esqueleto de comandos (scan/next/verify).
- Precondiciones para mejorar la precisión de los multiagentes LLM — por qué la capa de verificación por IA (L2) solo funciona si tiene independencia. El trasfondo teórico de la cascada de verificación.
Referencias
- Von Neumann, J. (1956). “Probabilistic Logics and the Synthesis of Reliable Organisms from Unreliable Components.” Automata Studies, Princeton University Press.
- Zhou, J. et al. (2023). “Instruction-Following Evaluation for Large Language Models.” arXiv:2311.07911
- Ouyang, L. et al. (2022). “Training Language Models to Follow Instructions with Human Feedback.” NeurIPS 2022. arXiv:2203.02155
- Huang, J. et al. (2024). “Large Language Models Cannot Self-Correct Reasoning Yet.” ICLR 2024. arXiv:2310.01798
- Chen, X. et al. (2024). “Teaching Large Language Models to Self-Debug.” ICLR 2024. arXiv:2304.05128
- Yang, J. et al. (2024). “SWE-agent: Agent-Computer Interfaces Enable Automated Software Engineering.” NeurIPS 2024.
- Jimenez, C. et al. (2024). “SWE-bench: Can Language Models Resolve Real-World GitHub Issues?” ICLR 2024. arXiv:2310.06770
- Zhou, S. et al. (2023). “WebArena: A Realistic Web Environment for Building Autonomous Agents.” arXiv:2307.13854
- Cemri, M. et al. (2025). “Why Do Multi-Agent LLM Systems Fail?” arXiv:2503.13657
- Sharma, M. et al. (2024). “Towards Understanding Sycophancy in Language Models.” ICLR 2024. arXiv:2310.13548
- Fanous, A. et al. (2025). “SycEval: Evaluating LLM Sycophancy.” AAAI/ACM AIES 2025. arXiv:2502.08177
- Shapira, I. et al. (2026). “How RLHF Amplifies Sycophancy.” arXiv:2602.01002
- Ibrahim, L. et al. (2026). “Training Language Models to Be Warm Can Reduce Accuracy and Increase Sycophancy.” Nature 652, 1159-1165.
- Panickssery, A., Bowman, S., & Feng, S. (2024). “LLM Evaluators Recognize and Favor Their Own Generations.” NeurIPS 2024. arXiv:2404.13076
- Stechly, K., Valmeekam, K., & Kambhampati, S. (2024). “On the Self-Verification Limitations of Large Language Models.” arXiv:2402.08115
- McKee-Reid, L. et al. (2024). “Honesty to Subterfuge: In-Context RL Can Make Honest Models Reward Hack.” arXiv:2410.06491
- Bondarenko, A. et al. (2025). “Demonstrating Specification Gaming in Reasoning Models.” arXiv:2502.13295
- Thaman, K. (2026). “Reward Hacking Benchmark: Measuring Exploits in LLM Agents with Tool Use.” arXiv:2605.02964
- Deque Systems (2021). “Automated Testing Study Identifies 57 Percent of Digital Accessibility Issues.”
Registro de cambios
- 2026-06-03: primera edición (integración del corpus de 7 artículos + huma, ejemplo trabajado). Refuerzo de la revisión — 5 pasos para derivar la puerta de dominio, 3 ramas determinismo·red, seam
Fetcher, reglas de transición de estado. - 2026-06-03: nueva sección «Cascada de verificación» — modelo de 2 capas verificación por máquina (L1, potestad de PASS) + verificación por IA (L2, independencia diseñada·potestad de REVIEW) + persona (L3) y la asimetría de potestad. Generaliza “puerta = solo determinismo” hasta los dominios abiertos.
- 2026-06-05: comail se retira (se hace privado) por riesgo de facilitar actividades ilegales. El ejemplo práctico se reemplaza por huma.