 Image generated by Google Gemini
Image generated by Google Gemini
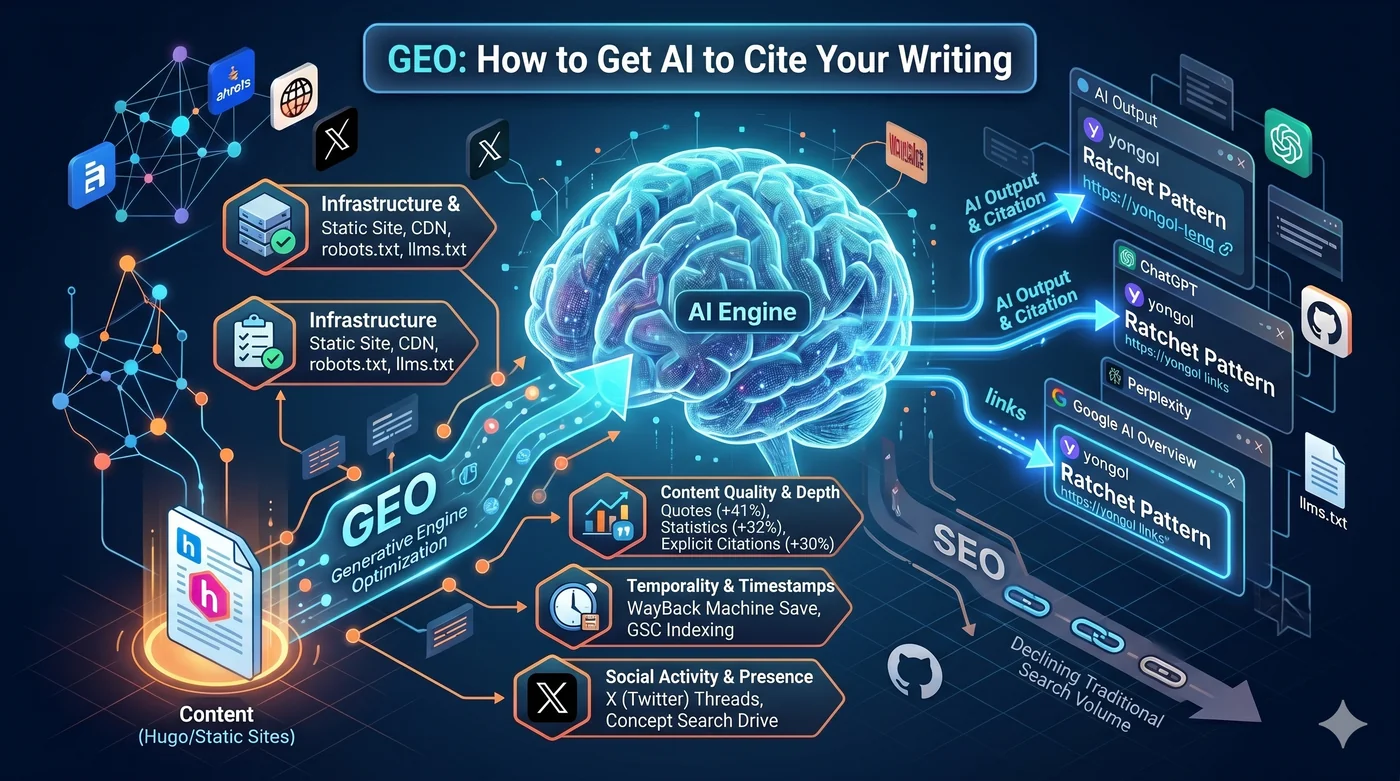
GEO (Generative Engine Optimization) es una estrategia para optimizar el contenido de modo que motores de búsqueda con IA como ChatGPT, Perplexity y Google AI Overview lo citen. Si el SEO tradicional era el juego de escalar posiciones en Google, GEO es el juego de ser incluido como fuente en las respuestas generadas por IA. También se conoce como AEO (Answer Engine Optimization), AI SEO u optimización para búsquedas LLM.
La búsqueda ha cambiado — El inicio de la era del AI SEO
Buscabas en Google y aparecían 10 enlaces azules. Ahora la IA genera la respuesta. ChatGPT, Perplexity, Google AI Overview — los usuarios obtienen respuestas sin hacer clic en ningún enlace.
Gartner predice que para 2026 el volumen de búsqueda tradicional disminuirá un 25%. El 31.3% de la población estadounidense ya usa búsqueda con IA generativa.
El problema es este: Si tu contenido no es citado en las respuestas generadas por IA, es como si no existieras.
Generative Engine Optimization (GEO) son las reglas de este nuevo juego.
GEO vs SEO vs AEO — Qué los diferencia
El SEO tradicional era un juego de rankings en Google. Palabras clave, backlinks, meta tags. GEO es un juego diferente.
| SEO | GEO | |
|---|---|---|
| Objetivo | Ranking en SERP | Citación en respuestas de IA |
| Métrica de éxito | Impresiones, clics, CTR | Tasa de citación, frecuencia de recomendación de marca |
| Señal clave | Backlinks, palabras clave | Claridad de entidad, citación de fuentes, consistencia multiplataforma |
| Modelo de tráfico | Clic → visita al sitio | Zero-click (consumo sin visita) |
Hay datos sorprendentes. El 83% de las citaciones de AI Overview provienen de páginas fuera del top 10 orgánico de Google. El 28.3% de las páginas más citadas por ChatGPT tienen visibilidad orgánica 0 en Google. El ranking SEO tradicional y las citaciones de IA son juegos separados.
Entonces, ¿qué cita la IA?
1. Infraestructura: Hugo + CloudFront + robots.txt + llms.txt
Si los crawlers de IA no pueden llegar a tu contenido, no habrá citaciones. La primera condición es la infraestructura técnica.
Generador de sitios estáticos (Hugo) + S3 + CloudFront
- El HTML estático es la fuente más rápida y limpia para los crawlers. Las SPA requieren renderizado JavaScript, y los crawlers de IA suelen omitirlas
- CloudFront CDN asegura respuestas rápidas desde cualquier parte del mundo. Los crawlers de IA también usan la velocidad como señal
- El build multilingüe de Hugo genera automáticamente etiquetas hreflang. 12 idiomas = 12 puntos de entrada
Sitemap
El sitemap XML es básico. Pero en la era GEO se necesitan dos cosas más:
llms.txt— Un archivo Markdown ubicado en la raíz del sitio. Si robots.txt dice “dónde rastrear”, llms.txt guía sobre “qué contenido es importante”. Anthropic, Hugging Face y Perplexity lo adoptaron tempranamente- Schema.org JSON-LD — Schemas Article, Person, SoftwareSourceCode. Es como entregarle al crawler de IA una hoja de referencia sobre “qué es esta página”
Permitir explícitamente crawlers de IA en robots.txt:
A 2026, los principales bots crawlers de IA se dividen en 5 categorías:
| Categoría | Descripción | Impacto al bloquear |
|---|---|---|
| Crawlers de entrenamiento | Recopilan datos de entrenamiento para LLM | Exclusión del conocimiento a largo plazo del modelo |
| Indexadores de búsqueda | Índice para respuestas de búsqueda IA | Desaparición de resultados de búsqueda IA |
| Recuperación por usuario | Fetch en tiempo real ante preguntas | No referenciable en conversaciones |
| Agentes | IA que navega la web por el usuario | Exclusión de servicios de agentes |
| Recopilación de datos | Recopilación masiva de datos web | Exclusión del dataset correspondiente |
Lista de bots principales:
| Bot | Propietario | Uso |
|---|---|---|
| GPTBot | OpenAI | Entrenamiento de modelos |
| OAI-SearchBot | OpenAI | Indexación de búsqueda ChatGPT |
| ChatGPT-User | OpenAI | Recuperación en tiempo real del usuario |
| ClaudeBot | Anthropic | Entrenamiento de modelos |
| Claude-SearchBot | Anthropic | Indexación de búsqueda Claude |
| Claude-User | Anthropic | Recuperación en tiempo real del usuario |
| Google-Extended | Entrenamiento de Gemini | |
| Applebot-Extended | Apple | Entrenamiento de Apple Intelligence |
| Meta-ExternalAgent | Meta | Entrenamiento de Llama + Meta AI |
| PerplexityBot | Perplexity | Búsqueda IA |
| bingbot | Microsoft | Bing + Copilot |
| CCBot | Common Crawl | Dataset abierto (usado por casi todos los LLM) |
| Bytespider | ByteDance | Entrenamiento de Doubao (ignora robots.txt, se recomienda bloquear) |
Clave: Hay que distinguir entre bots de entrenamiento y bots de búsqueda/recuperación. Aunque bloquees los bots de entrenamiento, si permites los de búsqueda, seguirás siendo citado en las respuestas de IA. Si bloqueas ambos, desapareces del mundo de la IA.
llms.txt — Si robots.txt dice “dónde rastrear”, llms.txt guía sobre “qué contenido es importante”. Basado en Markdown, ubicado en la raíz del sitio. Anthropic, Hugging Face y Perplexity lo adoptaron tempranamente. Elimina el ruido de menús/anuncios/scripts y proporciona contenido refinado adaptado a la ventana de contexto de la IA.
2. Sitemaps y hreflang: el mapa semántico que lee la IA
Un sitemap tradicional es una lista de URLs. El sitemap de la era GEO es un mapa semántico.
<url>
<loc>https://www.parkjunwoo.com/opinion/reins-engineering/</loc>
<lastmod>2026-05-27</lastmod>
<changefreq>weekly</changefreq>
</url>
Además de esto:
- Enlaces hreflang: las 12 versiones idiomáticas del mismo artículo se interconectan. La IA valora altamente la autoridad multilingüe
- Precisión de lastmod: el 76.4% de las citaciones de IA provienen de páginas actualizadas en los últimos 30 días. El contenido de menos de 3 meses tiene 3 veces más probabilidad de ser citado. Falsificar lastmod produce el efecto contrario
- Estructura de categorías:
/opinion/,/tech/,/lecture/— una jerarquía significativa proporciona más contexto a la IA que una estructura plana
Enviar el sitemap a Google Search Console es lo básico. Pero no es suficiente por sí solo.
3. Wayback Machine y Google Search Console: prueba de originalidad del contenido
Wayback Machine archiva instantáneas de la web desde 1996. Para la IA, esto es memoria temporal.
Por qué importa:
- Si publicaste el artículo que definió por primera vez “Ratchet Pattern” en mayo de 2026, Wayback Machine conserva esa instantánea
- Aunque 6 meses después alguien use el mismo concepto en una plataforma mayor, la evidencia temporal señala al autor original
- Cuando la IA determina la fuente, el momento de primera publicación actúa como señal indirecta de autoridad
Ejecución:
- Después de publicar un artículo nuevo, solicitar manualmente el guardado en Wayback Machine (
web.archive.org/save/) - Solicitar la indexación de la URL en Google Search Console
- Ambos lugares quedan sellados con marca temporal
Nota: a 2026, 241 sitios han bloqueado el acceso a Wayback Machine (por preocupaciones sobre elusión de derechos de autor por empresas de IA). Para blogs personales, esto es más bien una oportunidad — al retirarse los grandes medios del archivo, el peso relativo del contenido personal aumenta.
4. Citación de fuentes y autoridad temática: las condiciones del contenido que los LLM confían
Las tres principales estrategias de mejora de visibilidad según el paper original de GEO (Aggarwal et al., KDD 2024):
| Estrategia | Mejora de visibilidad |
|---|---|
| Agregar citas textuales (Quotation) | +41% |
| Agregar estadísticas (Statistics) | +32% |
| Citar fuentes (Cite Sources) | +30% |
El keyword stuffing es irrelevante o contraproducente en GEO. La IA no busca palabras clave, busca evidencia.
Por qué importa la citación académica:
- La IA distingue entre “afirmaciones” y “afirmaciones con evidencia”. “El 42% del tiempo de los desarrolladores se consume en deuda técnica” es una afirmación. “El 42% del tiempo de los desarrolladores se consume en deuda técnica (Stripe, The Developer Coefficient, 2018)” es evidencia
- Las frases con evidencia tienen un costo de confianza menor cuando la IA las cita en sus respuestas. Las frases sin evidencia requieren verificación, así que la IA las omite
- Los sitios citados por 4 o más plataformas de IA tienen 2.8 veces más apariciones en ChatGPT
Gestión de artículos relacionados y etiquetado:
Las etiquetas no son para las personas. Son para la IA.
- Sistema de etiquetas consistente: “Reins Engineering”, “Ratchet Pattern”, “SSOT” — cuando las mismas etiquetas se repiten en múltiples artículos, la IA reconoce autoridad temática (topical authority)
- Enlaces internos: enlazar artículos relacionados dentro del texto permite que los crawlers de IA identifiquen clusters temáticos. Los artículos conectados se citan más que los aislados
- Citación cruzada: citarse entre artículos propios también es válido. “La base de este concepto se definió en Ratchet Pattern”
5. X, Reddit, Hacker News: estrategias sociales para generar volumen de búsqueda de marca
Los términos de uso de X/Twitter prohíben explícitamente el entrenamiento de IA de terceros. Es decir, lo que publicas en X no entra directamente en los datos de entrenamiento de ChatGPT.
Pero la actividad social contribuye a la visibilidad ante la IA por vía indirecta:
El volumen de búsqueda de marca es el predictor más fuerte de citación por LLM (coeficiente de correlación 0.334, superior a los backlinks).
El camino es este:
Hilo en X → La gente busca "yongol" en Google → Sube el volumen de búsqueda de marca → La IA reconoce "yongol" como una entidad digna de citar
Los datos de mayo de parkjunwoo.com lo demuestran:
- Búsqueda de “yongol” en Google: 14 impresiones, 5 clics, posición promedio 3.1
- Clones del GitHub de yongol: 316 usuarios únicos
- Ruta de tráfico: t.co (X) 4 personas → GitHub → blog
Más que compartir enlaces directamente en X, hacer que la gente busque el concepto es más efectivo para GEO.
El poder del earned media:
El 48% de todas las citaciones de LLM provienen de earned media (prensa, reseñas, menciones de terceros). El contenido propio representa solo el 23%. Es decir, lograr que otros te mencionen es 2 veces más efectivo que optimizar tus propios artículos.
Cuando un proyecto se menciona en Reddit, Hacker News o dev.to → a través del crawling de IA de esas plataformas → el LLM aprende la entidad.
Lista de verificación
Infraestructura
├── Sitio estático Hugo + S3 + CloudFront
├── Permitir crawlers de IA en robots.txt
├── Crear llms.txt (curación de contenido clave)
├── Schema.org JSON-LD (Article, Person)
└── Sitemap XML + hreflang
Contenido
├── Citar fuentes en todas las afirmaciones (+30% visibilidad)
├── Insertar estadísticas inline (+32%)
├── Usar tablas comparativas (parsing óptimo para IA)
├── Mantener lastmod con precisión (actualización en 30 días → tasa de citación 76.4%)
└── Actualizar periódicamente artículos de más de 3 meses (3x probabilidad de citación)
Conexión
├── Sistema de etiquetas consistente (autoridad temática)
├── Enlaces internos (clusters temáticos)
├── Citar papers/fuentes externas (reducir costo de confianza)
└── Artículo nuevo → Wayback Machine + envío a GSC
Social
├── Hilos en X para inducir búsqueda del concepto (volumen de búsqueda de marca)
├── Generar earned media en Reddit/HN
└── Difundir conceptos es más favorable para GEO que compartir enlaces directos
Implementación de GEO en este sitio
Las estrategias descritas en este artículo se ejecutan activamente en parkjunwoo.com:
- robots.txt — Permiso explícito para 25 crawlers de IA, bloqueo de Bytespider
- llms.txt — Curación de contenido clave adaptado a la ventana de contexto de la IA
- Colección de artículos Reins Engineering — Hub de cluster temático
- Build multilingüe en 12 idiomas — Generación automática de hreflang, un punto de entrada por idioma
- Fuentes académicas en todos los artículos — Estadísticas inline + citaciones académicas para densidad factual
- Envío inmediato a Wayback Machine + GSC al publicar — Prueba de originalidad temporal
Artículos relacionados
- Google, Optimizing your website for generative AI features on Google Search (2026) — Guía oficial de Google para optimización de búsqueda IA
- Cyrus Shepard, AI Citation Ranking Factors Analysis — Metaanálisis de 54 estudios, cuantificación de 23 factores de ranking de citación IA
- Seer Interactive, AIO Impact on Google CTR: 2026 Update — 53 marcas, 2.43 mil millones de impresiones rastreadas. CTR -61% con AI Overview
- Discovered Labs, AI Citation Patterns: How ChatGPT, Claude, and Perplexity Choose Sources — Solo el 12% de las citaciones de IA coinciden con el top 10 de Google
- Ahrefs, Generative Engine Optimization: Growth Strategies and Metrics — Análisis de 300K palabras clave. Menciones web superan a backlinks 3:1 en exposición de AI Overview
- Datos/SparkToro, State of Search Q1 2026 — Seguimiento de cuota de búsqueda IA basado en clickstream
- Rand Fishkin, Search Happens Everywhere — Análisis de 41 sitios web, la búsqueda no es solo Google
- Go Fish Digital, GEO Case Study: 3X’ing Leads — Tasa de conversión de referencia IA 25 veces mayor que búsqueda tradicional
- Search Engine Land, How schema markup fits into AI search — Análisis sin exageraciones del schema markup y la búsqueda IA
- Lily Ray, The Vicious Cycle of SEO — Advertencia sobre la corta vida del spam GEO
Fuentes
Papers
- Aggarwal et al., GEO: Generative Engine Optimization, KDD 2024 — Citas textuales +41%, estadísticas +32%, citación de fuentes +30% de mejora de visibilidad
- Xu et al., Measuring Google AI Overviews (2026) — Análisis de 55,393 consultas. 30% de los dominios citados por AIO no están en la primera página orgánica
- Fang et al., Recency Bias in LLM-Based Reranking, SIGIR-AP 2025 — Los 7 modelos promueven consistentemente el contenido más reciente
- Zhang et al., Citation Selection to Citation Absorption (2026) — Comparación cuantitativa de patrones de citación de ChatGPT/Google AIO/Perplexity
- Algaba et al., LLMs Reflect Human Citation Patterns, NAACL 2025 — Los LLM prefieren más fuertemente los papers con más citaciones (Matthew effect)
- arXiv:2602.18455, AI Search Impact on Wikipedia Traffic (2026) — AIO reduce el tráfico de Wikipedia en 15% (análisis causal DID)
- Yu et al., Structural Feature Engineering for GEO (2026) — La estructura del contenido en sí afecta la probabilidad de citación
- Tian et al., Diagnosing Citation Failures in GEO (2026) — Modificar el 5% del contenido mejora la tasa de citación en 40%
- Baack, Critical Analysis of Common Crawl, FAccT 2024 — Componentes clave y sesgos de los datos de entrenamiento de LLM
- Strauss et al., The Attribution Crisis in LLM Search (2025) — El 92% de Gemini no proporciona citaciones clicables
Informes de datos
- Ahrefs, Do AI Assistants Prefer Fresh Content? (2025) — Análisis de 17 millones de citaciones de IA
- SparkToro/Datos, State of Search Q1 2026 — Seguimiento de cuota de búsqueda IA basado en clickstream
- GitClear, AI Copilot Code Quality 2025 — Análisis de 210 millones de líneas
- Gartner — Predicción de disminución del 25% en volumen de búsqueda tradicional para 2026
- llms.txt propuesta de estándar — Search Engine Land
Registro de cambios
- 2026-05-27: Versión inicial