 Image: AI generated
Image: AI generated
Vuelve justo donde lo corregiste
Construí una herramienta para cerrar el drift.
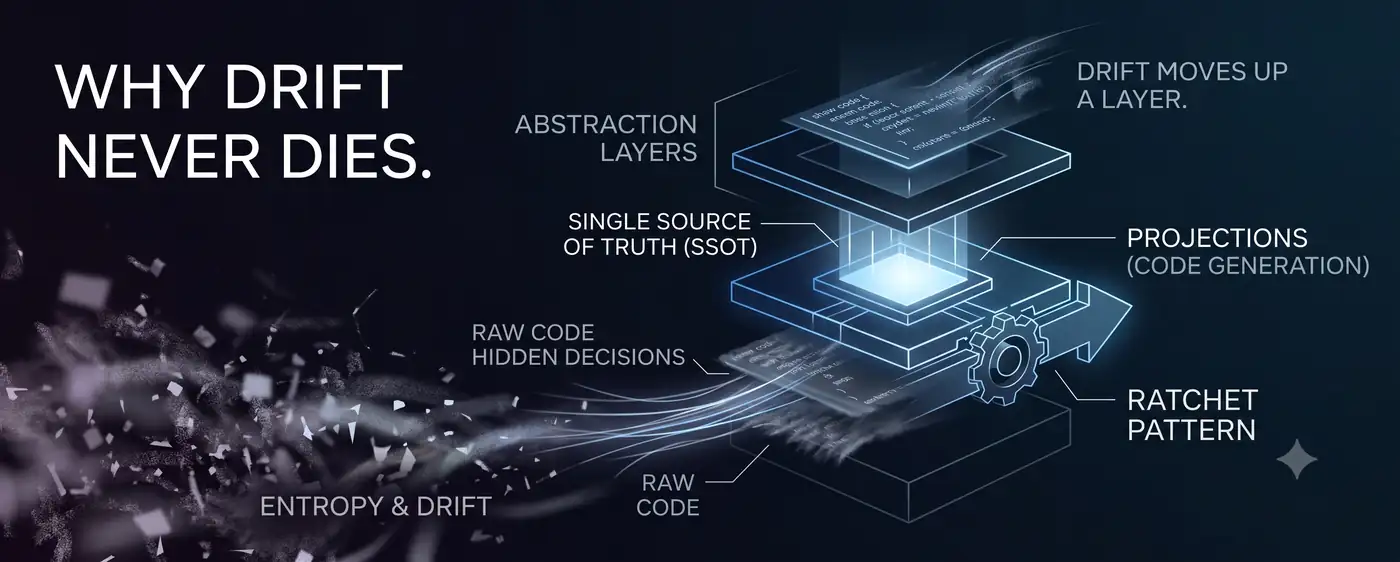
La tesis de yongol es simple. Si una decisión no vive en una fuente única autorizada (SSOT), deriva. Por eso puse las decisiones en un SSOT y convertí el código en una projection desechable que se redibuja en cada generación. El drift de lógica de negocio donde una columna definida como BIGINT se desliza silenciosamente a INT tras un solo refactoring quedó así cerrado.
Pero hace poco, al analizar un lote de defectos en código generado por yongol, vi algo extraño. Los defectos se confesaban con la misma estructura gramatical. “La recolección de import está separada de ‘¿el handler realmente usa time?’.” “La inferencia de required está separada de ‘¿la API objetivo realmente exige este parámetro como required?’.” Los parámetros de ruta son siempre required, los import solo cuando el token se usa realmente. Las mismas decisiones estructurales estaban incrustadas como proxies locales convenientes dentro del código del generador, sin quedar registradas en ningún SSOT.
El drift no había desaparecido. Se había movido una capa más arriba. La lógica de negocio estaba cerrada con un SSOT, pero las decisiones estructurales del propio generador que lee ese SSOT y produce código no tenían SSOT alguno. La tesis de yongol regresó contra yongol mismo. Exactamente en el lugar que la teoría predecía.
Así que la pregunta cambia. Todo el mundo sabe por qué se produce el drift. La verdadera pregunta es esta: ¿por qué vuelve aunque lo corrijas?
La raíz: decisión y detalle son cosas distintas
Reconstruyamos desde la física.
Una decisión es información. Información de baja entropía, además. “Esta columna debe ser de 64 bits” es elegir intencionalmente un estado entre innumerables posibilidades. La naturaleza aborrece la baja entropía. Si no se interviene, la información se disuelve en el ruido circundante. La segunda ley de la termodinámica se aplica también a las decisiones.
La ingeniería de software ha observado este colapso desde hace tiempo. Las leyes de evolución del software de Lehman afirman que la complejidad de los sistemas E-type aumenta a menos que haya un esfuerzo explícito por reducirla (1980). La física de la información va más profundo. Landauer demostró en 1961 que borrar siquiera 1 bit tiene un coste termodinámico mínimo (kT ln 2). Alterar y retener información nunca es gratis por principio. Mantener una decisión en su lugar exige gastar energía continuamente.
Para que la información sobreviva se necesitan dos cosas: un almacenamiento autoritativo (authoritative store) y una reproyección activa que redibuje incesantemente desde él (error correction). Así funciona el ADN en nuestros cuerpos y los bits de paridad en el almacenamiento digital. Se conserva el original por separado y se restaura cada vez tomándolo como referencia.
El drift ocurre cuando esta restauración se rompe. El mecanismo es uno solo. Lo llamo proxy binding. Cuando el medio no preserva la distinción entre decisión y detalle, la siguiente persona (o el siguiente agente) no puede leer la decisión de la fuente autoritativa y la rederiva de una señal correlacionada cercana y conveniente. Conjeturas como “esta columna es timestamptz, entonces debo hacer import de time”. La mayoría de las veces acierta. Por eso es peligroso. A veces falla, y cuando falla, la decisión desaparece en silencio.
El código raw es exactamente ese tipo de medio. El código no marca “esto es una decisión” frente a “esto resulta ser cierto aquí por casualidad”. Por eso un modelo más grande tampoco lo resuelve. Si el medio mismo no puede contener la decisión, por más inteligente que sea el lector, no hay nada que leer.
Este fenómeno no carecía de nombre. En arquitectura de software, Perry y Wolf distinguieron entre erosión (erosion) como violación de principios y drift como insensibilidad a la arquitectura (1992), y Cunningham llamó deuda técnica al interés acumulado del código mal hecho (1992). Cada campo nombró bien los síntomas. Lo que intento añadir es el mecanismo único subyacente (proxy binding) y la estructura por la cual ese mecanismo recurre capa arriba cuanto más se cierra. No pregunto por el nombre, sino por la causalidad.
Por qué asciende
Hasta aquí, la historia es conocida. Lo nuevo viene después.
Para cerrar el drift se necesitan dos cosas: un almacén que contenga las decisiones con autoridad (SSOT) y un agente de cierre que las lea y genere los artefactos (el generador). Pero el propio agente de cierre también toma decisiones. Decisiones estructurales como “los parámetros de ruta se tratan como required”. El medio donde vive esa decisión –el código del generador– tampoco distingue entre decisión y detalle.
El mismo mecanismo se repite una capa más arriba. El acto mismo de cerrar crea un medio no cerrado una capa por encima. El drift no fue exterminado; se mudó. A una capa sin autoridad.
Si se lleva esto hasta el final, se alcanza una conclusión incómoda. ¿Darle un SSOT al generador? Entonces lo que crea ese SSOT alojará sus propias decisiones en un medio no cerrado. Con cada capa que se sube, la superficie se reduce, pero en la cima siempre queda una capa sin autoridad. Sea una persona o un generador del generador. El drift es asintóticamente inerradicable. (Esto es más una conjetura fuerte que una demostración. Pero cada capa que he cerrado hasta ahora abrió la capa de arriba en el momento mismo de cerrarse.)
Esta es la respuesta a “¿por qué vuelve aunque lo corrijas?”. No vuelve. Cuando cerramos una capa, la herramienta que la cierra abre la siguiente. El mismo río filtrándose por un dique más alto.
La asimetría de la prescripción: lo que se puede declarar y lo que solo se puede verificar
Entonces, ¿cómo se cierra la capa superior? Aquí se revela una asimetría decisiva.
Las decisiones de la lógica de negocio suelen ser valores. La columna es de 64 bits, el acceso es solo del propietario, la paginación es por cursor. Los valores se pueden declarar. Si se escriben en DDL, en OpenAPI, en un archivo de especificación, eso se convierte en SSOT. Se cierran por declaración.
Las decisiones estructurales del generador son diferentes. “Los parámetros de ruta son required”, “los import se vinculan a las referencias reales de tokens”, “required (la clave existe) y no-vacío son cosas distintas”. Eso no son valores sino propiedades de comportamiento de una función sobre todas las entradas. Las propiedades de comportamiento no pueden enumerarse por declaración. Porque las entradas son infinitas. No hay manera de escribir en una línea de YAML “esta transformación debe comportarse así en todos los casos”.
Por eso las decisiones de esta capa solo se cierran mediante verificación, no declaración. Verificadores de tipos, tests de propiedades, gates de compilación. No se fijan las decisiones como datos, sino como compuertas donde la máquina detecta cada violación.
Lo que escribí en otro artículo como “codifica la revisión humana” apunta exactamente aquí. Algunas promesas se pueden declarar y el SSOT las guarda; otras no se pueden declarar y son los gates quienes las guardan. Que el código generado compile no puede escribirse en ningún SSOT. Solo se confirma ejecutando la compilación cada vez. Sin esa compuerta, la promesa “generate exitoso = compilable” flota fuera de la arquitectura, y validate pasa 0/0 mientras el artefacto está roto.
El drift que se puede declarar se cierra con un SSOT; el que solo se puede verificar, con un gate. Si se confunden ambos, se intenta bloquear con declaración y se persiguen topos eternamente.
El mismo río, diques diferentes
Esta estructura se repite fuera del código.
En el conocimiento, el drift es la pérdida del origen. Cuando se pierde quién hizo una afirmación, cuándo y con qué evidencia, esa afirmación se disuelve en el ruido de “es un hecho”. La siguiente persona no puede leer de la autoridad (la fuente original) y rederiva del contexto circundante. Por eso diseñé GEUL como un lenguaje que impone origen, momento y grado de confianza a toda información. La epistemología de que no hay hechos, solo afirmaciones, es un mecanismo de seguridad para prevenir el proxy binding en la capa del conocimiento.
En el derecho, el drift es que la jurisprudencia se desvíe de la decisión original. La civilización no dejó esto a la conciencia del juez en cada caso; codificó las reglas, definió las violaciones y añadió mecanismos de ejecución. Un buen juez no es un SSOT; es un proxy. La ley escrita es el SSOT.
Es el mismo río. Si una decisión no vive en un lugar autoritativo, si el medio no distingue entre decisión y detalle, deriva. Sea código, conocimiento o derecho.
Conclusión: no exterminar, sino empujar hacia arriba
La lucha contra el drift no puede tener como meta la erradicación. La erradicación es imposible. Porque la herramienta que cierra siempre abre la siguiente capa.
La meta es otra. Empujar el drift hacia capas más altas con menor superficie y armar esas capas con verificación mecánica. Cuando las decisiones dispersas en decenas de miles de líneas de código raw se concentran en un solo SSOT, la superficie susceptible de derivar se reduce drásticamente. La superficie restante –los invariantes de comportamiento del generador– se bloquea con gates. Aun así, en la cima queda una última capa que ya no puede delegarse: el juicio humano. Ahí verificamos de nuevo cada vez y volvemos a fijar la promesa.
Esto es un ratchet. Solo gira en una dirección. Un diente que subió no resbala hacia abajo. La entropía intenta arrastrar las decisiones hacia abajo y el ratchet las sube un diente cada vez. No hay equilibrio. Si te detienes, derivas.
El drift no muere. Por eso nosotros no nos detenemos. Construir promesas contra la entropía no es una victoria única, sino un ratchet permanente.
Artículos relacionados
- Ratchet Pattern – el método para que el agente llegue hasta el final
- Por qué tu bucle de agente diverge
- Reins Engineering – IA con riendas
Lecturas recomendadas (externas)
- Lehman’s laws of software evolution — Resumen de las leyes empíricas según las cuales el software se vuelve más complejo si no se interviene.
- Landauer’s principle — El coste termodinámico de borrar información.
Referencias
- Perry, D. E. & Wolf, A. L. (1992). Foundations for the Study of Software Architecture. ACM SIGSOFT Software Engineering Notes, 17(4), 40-52. ACM — La distinción entre erosión (erosion) y drift.
- De Silva, L. & Balasubramaniam, D. (2012). Controlling software architecture erosion: A survey. Journal of Systems and Software, 85(1), 132-151. ScienceDirect
- Lehman, M. M. (1980). Programs, Life Cycles, and Laws of Software Evolution. Proceedings of the IEEE, 68(9), 1060-1076. IEEE — Las leyes de aumento de complejidad y cambio continuo.
- Landauer, R. (1961). Irreversibility and Heat Generation in the Computing Process. IBM Journal of Research and Development, 5(3), 183-191. IBM — El coste termodinámico mínimo de borrar información.
- Shannon, C. E. (1948). A Mathematical Theory of Communication. Bell System Technical Journal, 27, 379-423. DOI — Los fundamentos de la información, la entropía y la corrección de errores.
- Cunningham, W. (1992). The WyCash Portfolio Management System. OOPSLA ‘92 Experience Report. c2.com — La deuda técnica y “el interés del código mal hecho”.