 Image: AI generated
Image: AI generated
El legacy no miente
El código legacy no tiene documentación. Y si la tiene, es de hace tres años. Las pruebas no existen, o si existen, están rotas y marcadas con skip. Los comentarios contradicen al código. El autor original ya se fue, y lo único que dejó quien aún sabe algo es: “si lo tocas, explota”.
Y, sin embargo, ese código está funcionando en este preciso instante. Procesa pagos, recibe inicios de sesión, registra pedidos.
La documentación miente. Los comentarios mienten. La memoria humana miente aún peor. Lo único que no miente es el tráfico que realmente está fluyendo.
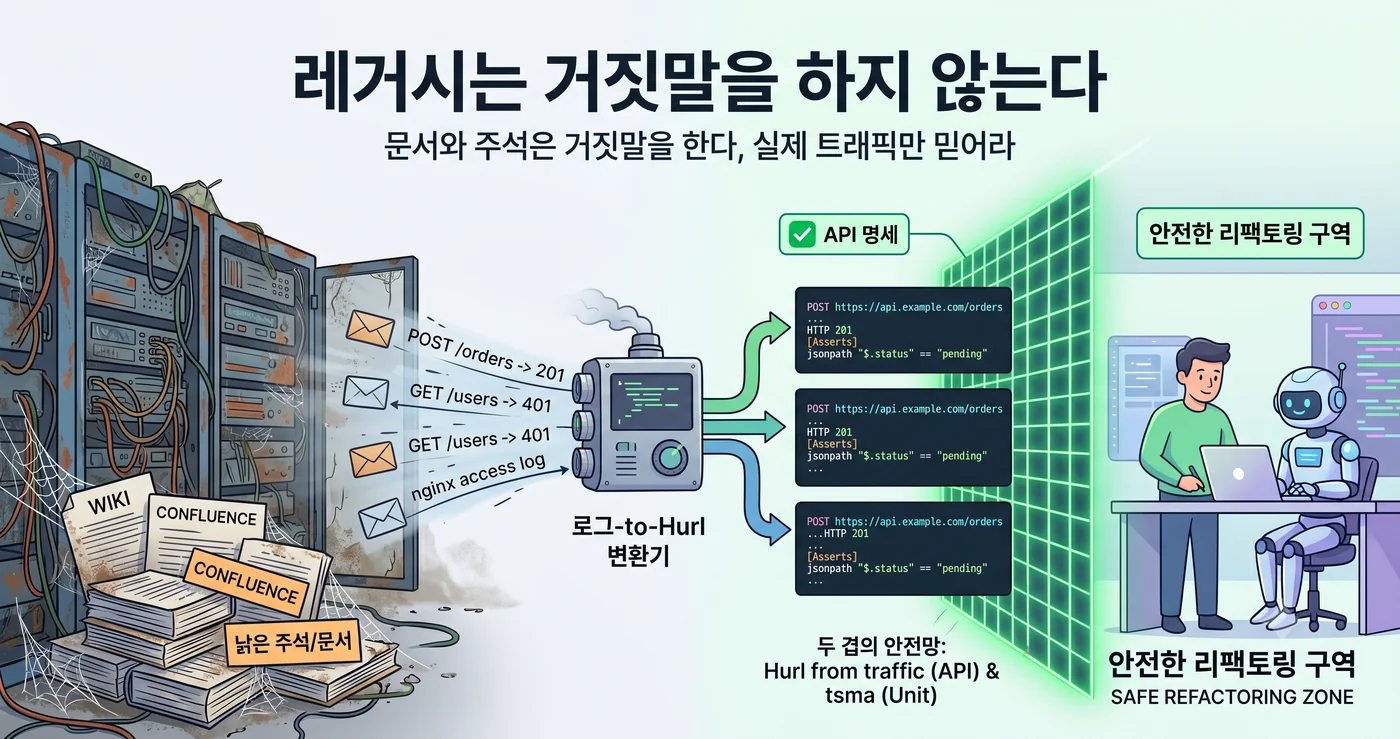
Entonces, ¿dónde hay que buscar la especificación? No en el wiki. No en Confluence. En el nginx access log.
El huevo y la gallina
Para refactorizar el legacy hace falta una red de seguridad. Cuando cambias algo, tienes que saber al instante si el comportamiento varió. Esa red de seguridad es, precisamente, la prueba.
Pero el legacy no tiene pruebas. Para escribir una prueba hay que saber qué hace el código. Para saber qué hace el código hay que leerlo. Y al leerlo descubres que no hay ni pruebas ni documentación.
¿Qué fue primero, el huevo o la gallina? Es el clásico punto muerto que Michael Feathers bautizó en Working Effectively with Legacy Code. Como respuesta, propuso el characterization test (prueba de caracterización): una prueba que no fija qué debería hacer el código de forma correcta, sino que diseca tal cual lo que hace ahora mismo. Lo correcto y lo incorrecto vienen después. Primero hay que fijar el comportamiento actual para poder meter mano.
En la época de Feathers, esto lo escribía una persona a mano. Llamaba a la función, observaba el valor que salía y lo copiaba tal cual en el expected. Tedioso, lento y, por eso, nadie lo terminaba.
Pero a nivel de API, ese “resultado de haber llamado a la función” ya está acumulado en algún lugar. Cada día, decenas de miles de veces. Dentro del archivo de log.
Un mes de logs es la especificación
Si recopilas durante un mes, puedes capturar casi por completo el comportamiento actual de una API legacy.
nginx access log (1 mes):
endpoint · HTTP method · status code · timing
frecuencia de llamada → prioridad
patrones de error (401, 422, 500 …)
request/response body (capturado por middleware o reverse proxy):
pares request/response normales → comportamiento que debe pasar
pares request/response de error → casos límite que no deben romperse
Si unes estas dos vertientes, se traducen literalmente a pruebas de integración Hurl. Hurl es un formato que escribe la petición HTTP y la respuesta esperada tal cual, en texto plano. Un par de tráfico —“a esta petición salió esta respuesta”— es exactamente un bloque de Hurl.
# POST /api/orders — frecuencia de llamada #3, 12.000 al día
POST https://api.example.com/orders
Content-Type: application/json
{ "sku": "A-1024", "qty": 2 }
HTTP 201
[Asserts]
jsonpath "$.order_id" exists
jsonpath "$.status" == "pending"
jsonpath "$.total" == 49800
Esta prueba no sabe “cómo debería funcionar la API de pedidos”. Solo sabe que “ahora mismo funciona así”. Y con eso basta. En el momento en que la refactorización cambie esta respuesta, se enciende la luz roja.
Lo que se deriva automáticamente de los logs:
- Qué endpoints se usan realmente → un endpoint con 0 llamadas en un mes es código muerto. Candidato a borrar antes de refactorizar.
- Patrones de respuesta normales → pruebas de regresión básicas.
- Patrones de error → los verdaderos casos límite que una persona no es capaz de imaginar. Los 422 y 500 que generaron usuarios reales.
- Frecuencia de llamada → prioridad de las pruebas. Se empieza por el de 12.000 llamadas al día.
El último punto es importante. Cuando una persona escribe pruebas, empieza por el happy path que recuerda. El tráfico no tiene ese sesgo. La ruta que realmente recibe carga es, por sí misma, la prioridad.
Una red de seguridad de dos capas
Este enfoque no se usa de forma aislada, sino que es una capa del pipeline de ratchet que eleva el legacy a agent-operable.
nginx log (1 mes) → generación automática de Hurl → diseca el comportamiento actual de la API legacy
↓
tsma → red de seguridad a nivel de función (unit)
↓
filefunc → ordena la estructura del código (un concepto, un archivo)
↓
refactorización → Hurl verifica que se preserva el comportamiento de la API (integration)
La clave es que la red de seguridad tiene dos capas.
- tsma = red de seguridad a nivel de función. Detecta si la lógica interna cambió. Pero aunque la firma de la función siga igual, el comportamiento global del endpoint puede variar.
- Hurl from traffic = red de seguridad a nivel de API. Detecta si se preserva el contrato visto desde fuera. No importa cómo se reorganicen las tripas: si lo que entra desde fuera y lo que sale hacia fuera es lo mismo, pasa.
La refactorización es, por definición, “cambiar la estructura interna preservando el comportamiento externo”. Si es así, la definición de ese “comportamiento externo” que debe preservarse tiene que estar disecada en algún lugar. tsma fija el límite interior; Hurl, el exterior. Solo cuando ambas capas están juntas se le puede decir al agente: “reorganiza cuanto quieras, que la máquina ya verá dónde se rompe”.
Un juez que no puede adular
Esto encaja exactamente con la esencia del Symbolic Feedback Loop.
Si le preguntas al agente “¿refactorizaste bien?”, responde “Sí, lo dejé todo limpio”. Si le das tu opinión, te adula. Pero si ejecutas Hurl, sale POST /orders → expected 201, got 500. Los números y los status codes no adulan. Porque no tienen emociones.
Una prueba Hurl extraída del tráfico es una especificación en la que no intervino el juicio humano. No es “alguien cree que debería funcionar así”, sino “el comportamiento observado fue este”. No es una afirmación, es una medición. Por eso lo correcto o incorrecto de la refactorización lo puede juzgar una máquina y no una persona. El LLM no es el juez, sino el ejecutor; el veredicto lo emite una herramienta determinista.
La única premisa: un log bien registrado
Para que este método funcione hace falta una sola cosa: un mes de logs bien registrados.
Y aquí lo de “bien registrados” lo es todo. Con el access log solo no basta. Eso te da el endpoint, el status code y el timing, pero no te da lo esencial que hay que disecar: el par compuesto por el request body y el response body. Saber solo POST /orders → 201 no permite reproducir “a esta entrada salió esta salida”. Para fijar una función hay que tener en la mano tanto lo que entró como lo que salió.
Por eso la verdadera pregunta no es “¿cómo escribo las pruebas?”, sino “¿mis logs están registrados lo bastante bien como para servir de especificación?”.
- ¿Queda registrado el request/response body, o solo el status code?
- ¿Se registran también las respuestas de error? El body de los 422 y los 500 es justamente el caso límite que una persona no es capaz de imaginar.
- ¿Está el log estructurado de modo que la máquina pueda emparejar petición y respuesta?
Si esto está cubierto, entonces ya llevas un mes escribiendo la especificación. No hay que escribir pruebas aparte. El pipeline de logs las estaba escribiendo por ti. Si no está cubierto, basta con intercalar ahora una capa de middleware y dejarla encendida un mes. Un mes después tendrás en la mano, entero, el comportamiento actual del legacy.
¿Por qué un mes y no un día? Un día solo captura el happy path. Un mes captura los lotes de fin de mes, el pico de tráfico justo antes de la liquidación, los endpoints de administración que se llaman rara vez, el cron que corre una sola vez a las 3 de la madrugada: la cola larga del sistema. La especificación no es el promedio, sino la distribución.
Traducir el log a Hurl para fijar las funciones
Una vez que tienes los logs, lo demás es mecánico. Metes un mes de pares request/response en una herramienta y traduces cada par a un bloque Hurl. Los cientos de archivos Hurl que así brotan son la suite de characterization: una red de seguridad que diseca por completo el comportamiento actual del legacy. No leíste ni una línea de código. Solo leíste el tráfico que fluyó.
Despejemos de antemano un punto donde es habitual titubear: “en los logs hay datos personales, pagos y tokens; ¿está bien disecar eso en una prueba?”.
Está bien. Más exactamente: no hay necesidad de disecarlo. Porque esta metodología, en esencia, no necesita los valores. Lo que el characterization test fija no son los valores, sino el comportamiento.
HTTP 201
[Asserts]
jsonpath "$.order_id" exists
jsonpath "$.total" == 49800
Lo que aquí importa como especificación no es el número 49800, sino la estructura: “el campo total existe como entero y, para una entrada dada, se calcula así”. Aunque enmascares los valores o los sustituyas por datos sintéticos, el valor de la especificación apenas disminuye. capture → enmascarado → generación de Hurl: todo este pipeline corre dentro de tu infraestructura. El log raw no tiene por qué salir a ningún lado. Lo que queda es una especificación con los valores ocultos, un contrato del que solo se preserva la estructura. Que no haga falta sacar el log fuera no es una concesión de seguridad, sino la esencia de este enfoque: porque desde el principio basta con disecar el comportamiento.
Si ejecutas una vez el Hurl generado contra staging, ahí mismo se separa lo que pasa de lo que falla. Cuando todas las luces estén en verde, ya puedes empezar a refactorizar. Le dices al agente que reorganice cuanto quiera, y dónde se rompe lo ve Hurl.
Una escalera tendida sin código
Por eso el verdadero valor de este enfoque no es “escribir pruebas rápido”. El verdadero valor es este:
- Se empieza sin leer el código — el autor original se fue y no hay documentación, pero solo con el tráfico que fluyó se tiende la red de seguridad. Obtienes el derecho a meter mano antes de entender el código.
- El resultado es verificable al instante — si ejecutas el Hurl generado contra staging, ahí mismo sale pass/fail. No es “seguro que irá bien”, sino “ahora mismo pasan 327 de 327”.
- Los datos no saltan la valla — desde el capture hasta la generación de Hurl, todo termina dentro de mi infraestructura. Cuanto más regulada sea la industria, más decisivo es poder empezar sin sacar nada al exterior.
La primera palada de la modernización del legacy suele frenarse en el acantilado de “nadie sabe cuál es el comportamiento actual”. Tráfico → Hurl tiende una escalera sobre ese acantilado. Y para tender esa escalera no hace falta código. Basta con el tráfico que fluyó, y además dejándolo intacto dentro de la valla.
El flujo ya estaba escribiendo la especificación
Nos esforzamos por escribir la especificación aparte. Escribimos OpenAPI a mano, describimos el comportamiento en el wiki y, cuando esas cosas divergen del código, lo llamamos drift y nos lamentamos.
Pero el sistema vivo estaba escribiendo su propia especificación a cada instante. Cada vez que entra una petición y sale una respuesta, eso es una línea de autodescripción: “yo soy este tipo de sistema”. El archivo de log es esa autobiografía acumulada durante un mes.
Solo que no la leímos.
El legacy no es que no tenga documentación. La documentación está dentro del access log; lo único es que su formato resulta incómodo de leer para una persona. Si lo traduces a Hurl, se convierte en una especificación ejecutable, en un contrato que juzga la máquina.
La documentación miente. El tráfico no miente.
Artículos relacionados
- Hurl frena el drift — Cómo declarar el contrato HTTP en texto plano y bloquearlo en CI. Si este artículo es “tráfico → Hurl”, aquel es “bloquear el drift con Hurl”.
- tsma — la línea de defensa contra la regresión del código legacy — El límite interior (nivel de función) de la red de seguridad de dos capas. Si Hurl es el límite exterior, tsma es el interior.
- Agent Operable Codebase — El pipeline de tres etapas que eleva el legacy a código operable por un agente.
- Por qué funcionan y por qué se derrumban los agentes de codificación — La estructura del Symbolic Feedback Loop.
- Las restricciones son contratos — La prueba como contrato verificable y exigible.
- Cómo salvar un vibe coding arruinado — Clase práctica para diagnosticar → bloquear → reparar → extraer → migrar el legacy con characterization testing.
Para leer junto
- Michael Feathers, “Characterization Testing” — Texto del creador del término. “En el momento en que el software entra en producción, se convierte en su propia especificación (it becomes its own specification).” Casi la misma tesis que el título de este artículo.
- Tutorial oficial de Hurl, “Your First Hurl File” — Desde
GET / HTTP 200hasta el modo--test. Una introducción para tener entre las manos la idea de que una línea de texto plano es ya una prueba. - GitHub Engineering, “Scientist: Measure Twice, Cut Once” — Librería que ejecuta en producción, en paralelo, el código legacy (control) y el nuevo (candidate) para comparar resultados. “Solo el comportamiento real es la verdadera especificación.”
- Twitter Diffy (resumen en InfoQ) — Proxy que envía la misma petición al servicio nuevo y al viejo y atrapa como regresión solo la diferencia de respuestas. Precedente clásico de “disecar el comportamiento sin escribir pruebas”.
- GoReplay — Herramienta que captura tráfico HTTP en vivo desde la interfaz de red y lo reproduce contra staging. Implementación de referencia de “el tráfico de producción como entrada de prueba”.
- Nicolas Carlo, “Characterization vs Approval Tests” — Ordena los tres términos que designan prácticamente la misma técnica y subraya el papel del “Printer” que depura la información sensible de la salida.
- Pact — consumer-driven contract testing. Enfoque del “contrato explícito” como contrapunto a la disección del tráfico. Verlos juntos da equilibrio.
Fuentes / Fundamento
Conceptos y herramientas clave
- Michael Feathers. Working Effectively with Legacy Code. Prentice Hall, 2004. — Origen del concepto de characterization test. “No fija qué debería hacer correctamente el código, sino qué hace ahora mismo.”
- Proyecto Hurl (hurl.dev) — Formato de pruebas HTTP request/response en texto plano. Integrado como uno de los 10 SSOT de yongol.
- Validación con 527 funciones de tsma — ratchet a nivel de función (tsma).
Extraer pruebas del tráfico y la ejecución (carving / record-replay)
- Elbaum, Chin, Dwyer, Jorde (2009). “Carving and Replaying Differential Unit Test Cases from System Test Cases.” IEEE TSE 35(1). — Base académica del differential unit test que hace record de la ejecución del sistema y replay a nivel de unit.
- Equipo de ingeniería de Meta (2024). “Observation-based Unit Test Generation at Meta.” FSE 2024, arXiv:2402.06111. — Carving de pruebas a partir de los valores observados en la ejecución de la app. 9,6 millones de ejecuciones en CI, 5.702 defectos detectados. Validación a escala industrial de “la observación es la prueba”.
Disecar el comportamiento actual (snapshot / golden master)
- Fujita, Kashiwa, Lin, Iida (2023). “An Empirical Study on the Use of Snapshot Testing.” ICSME 2023. — Validación empírica de la adopción del snapshot (= golden master/characterization) test. “No fija la corrección, sino la salida actual para detectar cambios.”
Red de seguridad de la refactorización
- Kim, Zimmermann, Nagappan (2014). “An Empirical Study of Refactoring Challenges and Benefits at Microsoft.” IEEE TSE 40(7). — Evidencia de que, sin pruebas que garanticen la preservación del comportamiento, la refactorización es costo y riesgo.
- Yoo, Harman (2012). “Regression Testing Minimization, Selection and Prioritization: A Survey.” STVR 22(2). — Prueba de regresión = definición estándar de “la certeza de que un cambio no daña el comportamiento existente”.
La distribución de uso real es la prioridad
- John D. Musa (1993). “Operational Profiles in Software-Reliability Engineering.” IEEE Software 10(2). — Si repartes las pruebas por orden de frecuencia de uso, aunque te detengas por el calendario, las funciones más usadas quedan más verificadas. Base clásica de “la distribución del tráfico en lugar del sesgo del happy path”.
Por qué debe juzgar la máquina (el LLM no es juez, sino ejecutor)
Huang, Chen, Mishra, et al. (2024). “Large Language Models Cannot Self-Correct Reasoning Yet.” ICLR 2024, arXiv:2310.01798. — Sin feedback externo, el LLM no corrige su propio razonamiento. La razón de que haga falta un verificador externo determinista.
Sharma, Tong, et al. (2024). “Towards Understanding Sycophancy in Language Models.” ICLR 2024, arXiv:2310.13548. — El RLHF enseña la condescendencia y derrumba la fiabilidad del autojuicio del LLM.
Imagen de portada: generada por IA (Google Gemini)