 Image: AI generated
Image: AI generated
Kluge Menschen erklären nicht unbedingt gut
Wenn man Opus 4.8 mit Code-Refactoring beauftragt, ist das beeindruckend. Es löst komplexe Abhängigkeitsgraphen in einem Durchgang, behandelt Edge Cases proaktiv und schreibt lückenlose Tests. Doch wenn man es bittet, das Ergebnis zu erklären, beginnen die Probleme. Es spricht wie ein Experte, der einem Experten berichtet. Es setzt voraus, dass man das Hintergrundwissen teilt, lässt die Begründung zentraler Entscheidungen weg und abstrahiert unnötig hoch.
Fragt man Opus 4.6 dasselbe, ist es genau umgekehrt. Es schätzt gut ein, was man möglicherweise nicht weiß. Es wählt passende Analogien, gliedert in Schritte und liefert zuerst den Kontext. Aber sobald der Schwierigkeitsgrad der Schlussfolgerung steigt, stolpert es bei Problemen, die 4.8 auf Anhieb löst.
In einem Satz zusammengefasst: Opus 4.8 ist klug, drückt sich aber kompliziert aus, und Opus 4.6 erklärt verständlich, hat aber schwächere Schlussfolgerungsfähigkeiten.
Das ist kein Defekt. Warum das so ist — und wie man diesen Unterschied in einen strukturellen Vorteil verwandelt — das ist das Thema dieses Artikels.
Der Fluch des Wissens gilt auch für LLMs
1989 wiesen die Psychologen Camerer, Loewenstein und Weber experimentell nach: Je mehr Informationen eine Person besitzt, desto schlechter kann sie berücksichtigen, dass andere diese Informationen nicht haben. Dieses als “Fluch des Wissens” (Curse of Knowledge) bekannte Phänomen ist eine kognitive Verzerrung, die in Pädagogik, Wirtschaftswissenschaften und UX-Design wiederholt bestätigt wurde.
Oliver Wendell Holmes sagte: “Für die Einfachheit diesseits der Komplexität würde ich keinen Pfennig geben. Aber für die Einfachheit jenseits der Komplexität würde ich mein Leben geben.” Verständliche Erklärungen sind nicht deshalb einfach, weil der Erklärende nichts weiß — sie werden erst möglich, nachdem man die Komplexität durchdrungen hat. Paradoxerweise ist jedoch genau dann, wenn man sich inmitten der Komplexität befindet, die Fähigkeit zur einfachen Erklärung eingeschränkt.
Ein EMNLP-Paper von 2025 zeigte, dass dieses Phänomen auch bei großen Schlussfolgerungsmodellen auftritt. Das paradoxe Ergebnis: Je stärker die Schlussfolgerungsfähigkeit eines Modells, desto anfälliger ist es für den Fluch des Wissens. Modelle, die tief schlussfolgern, nehmen implizit an, dass ihr Gegenüber ihren Denkprozess nachvollziehen kann. Es ist exakt dasselbe Problem, das menschliche Experten haben, wenn sie Anfängern etwas erklären.
Deshalb gibt es auf der Welt zwei Arten von Rollen: Menschen, die tief denken und Menschen, die verständlich vermitteln. Forscher und Wissenschaftskommunikatoren. Senior-Entwickler und Tech Leads. Richter und Anwälte. Das sind unterschiedliche Fähigkeiten. Es wäre schön, wenn eine Person beides gut könnte, aber in der Praxis ist das selten. Deshalb trennen Organisationen die Rollen.
Für LLMs gilt dasselbe. Und Claude Code ermöglicht diese Trennung mit einer einzigen Einstellung.
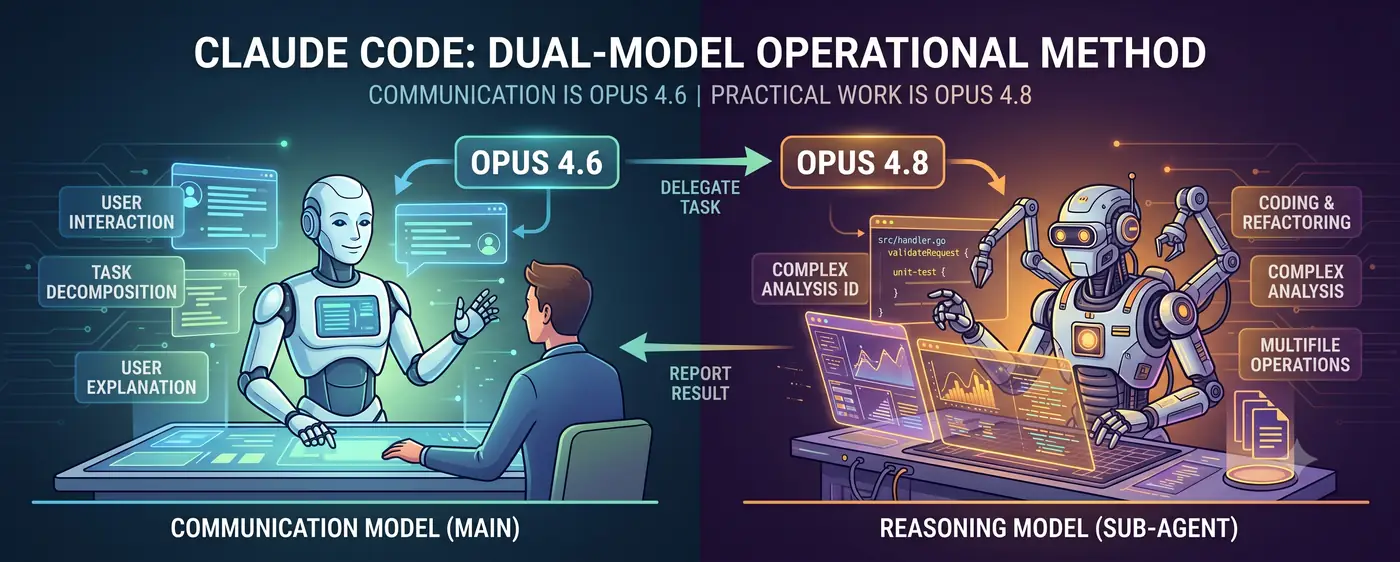
Kommunikationsmodell + Schlussfolgerungsmodell
Die Kernstruktur ist einfach.
Benutzer ↔ Kommunikationsmodell (Hauptagent) ↔ Schlussfolgerungsmodell (Subagent)
- Das Kommunikationsmodell (Opus 4.6) steht im Vordergrund des Dialogs. Es erfasst die Absicht des Benutzers, zerlegt Aufgaben und berichtet Ergebnisse in einer für Menschen verständlichen Sprache.
- Das Schlussfolgerungsmodell (Opus 4.8) erledigt die eigentliche Arbeit. Code schreiben, komplexe Analysen, Multi-Datei-Refactoring — anspruchsvolle Schlussfolgerungsaufgaben werden als Subagent delegiert.
Der Benutzer spricht mit 4.6. Wenn 4.6 urteilt: “Dafür ist der Schlussfolgerungsaufwand zu hoch, als dass ich es selbst machen sollte”, erzeugt es einen 4.8-Subagent und delegiert die Aufgabe. Sobald 4.8 das Ergebnis zurückliefert, interpretiert 4.6 es und erklärt es dem Benutzer.
Dieser Artikel selbst ist der Beweis dafür. Geschrieben wird dieser Text von Opus 4.6 (Hauptagent), während die Recherche der wissenschaftlichen Quellen und die Analyse der Benchmark-Daten von Opus 4.8 (Subagent) durchgeführt wurden.
Was die Benchmarks zeigen
Die BenchLM-Daten zeigen den Charakter beider Modelle in Zahlen.
| Bereich | Opus 4.6 | Opus 4.8 | Vorteil |
|---|---|---|---|
| Gesamtwertung | 86 | 93 | 4.8 |
| Coding | 64.4 | 76.4 | 4.8 |
| Agent-Aufgaben | 72.6 | 80.1 | 4.8 |
| Wissensaufgaben | 76.2 | 70.1 | 4.6 |
| Kreatives Schreiben | Vorteil | - | 4.6 |
Bei Coding und Agent-Aufgaben dominiert 4.8. Aber bei Wissensvermittlung und kreativem Schreiben liegt 4.6 vorn. Auch in Claude API-Reviews wird wiederholt bemerkt, dass die Texte von 4.8 “KI-artiger klingen (more AI-sounding)” als die von 4.6. 4.8 schlussfolgert präzise, aber die Fähigkeit, diese Schlussfolgerungen menschenlesbar aufzubereiten, ist bei 4.6 besser.
Beide Modelle kosten gleich viel — 5 $ pro Million Eingabe-Token, 25 $ pro Million Ausgabe-Token. Selbst bei Rollentrennung steigen die Kosten nicht. Das ist keine Kostenoptimierung, sondern reine Qualitätsoptimierung.
Modell-Routing ist bereits bewährte Ingenieurskunst
Die Idee, “zwei Modelle getrennt einzusetzen”, ist nicht neu. In der Wissenschaft ist das bereits ein etabliertes Feld.
RouteLLM (ICLR 2025) routete Anfragen dynamisch zwischen einem starken und einem schwachen Modell und senkte so die Kosten um mehr als das Doppelte bei gleichbleibender Qualität. FrugalGPT (2023) erreichte mit einer LLM-Kaskade GPT-4-Niveau bei 98 % Kosteneinsparung. Die gemeinsame Schlussfolgerung dieser Arbeiten ist klar: Ein schwaches Modell mit guter Orchestrierung schlägt oft ein starkes Modell mit schlechter Orchestrierung.
Anthropic selbst nutzt dieses Muster. Anthropics deep-research-Implementierung basiert auf dem Orchestrator-Worker-Pattern, wobei eine Multi-Agent-Konfiguration einen einzelnen Opus-4-Agenten zu 90,2 % übertraf. Erhebungen zeigen, dass etwa 80 % der produktiven Multi-Agent-Systeme auf der Orchestrator-Worker-Struktur basieren.
Was ich mache, ist die einfachste Form dieses Musters. Kein Router, keine Kaskade, keine Kostenoptimierung. Lediglich: Ein für Kommunikation optimiertes Modell steht vorn, ein für Schlussfolgerung optimiertes Modell arbeitet im Hintergrund. Das Prinzip der Rollentrennung in seiner reinen Form.
So richtet man es ein
Diese Struktur in Claude Code aufzubauen, ist einfach.
Schritt 1: Hauptmodell festlegen
Claude Code wird mit Opus 4.6 gestartet. In den Einstellungen setzt man das Standardmodell auf claude-opus-4-6-20250610 oder wählt das Modell beim Start. Das wird zum Kommunikationsmodell, das mit dem Benutzer spricht.
Schritt 2: Modell-Override für Subagenten
Das Agent-Tool von Claude Code unterstützt den Parameter model. Beim Erstellen eines Subagenten überschreibt man das Modell einfach mit opus (Opus 4.8).
Agent({
description: "Code-Refactoring",
model: "opus",
prompt: "Die Funktion validateRequest in src/handler.go..."
})
Das war’s. Der Hauptagent (4.6) spricht mit dem Benutzer, und anspruchsvolle Aufgaben werden an den Subagent (4.8) delegiert.
Schritt 3: fork und fresh agent unterscheiden
Es gibt zwei Arten von Subagenten in Claude Code.
- fork (
subagent_type: "fork"): Erbt den Kontext der aktuellen Konversation vollständig. Durch die gemeinsame Nutzung des Prompt-Caches werden die Eingabekosten um bis zu 90 % gesenkt. Allerdings erzwingt ein fork die Vererbung des Elternmodells, sodass ein Modell-Override nicht angewendet wird. - fresh agent: Startet mit einem neuen Kontext. Ein Modell-Override ist möglich. Der Prompt muss den benötigten Hintergrund selbst enthalten.
Um also das Schlussfolgerungsmodell (4.8) zu nutzen, muss man einen fresh agent erstellen. fork verwendet man, wenn man mit dem Kommunikationsmodell (4.6) parallele Erkundungen durchführen möchte.
Praxismuster
| Situation | Methode | Begründung |
|---|---|---|
| Komplexen Code schreiben | fresh agent + model: opus | Hoher Schlussfolgerungsaufwand |
| Multi-Datei-Refactoring | fresh agent + model: opus + isolation: worktree | Schlussfolgerung + Isolation nötig |
| Parallele Recherche/Erkundung | fork (4.6 beibehalten) | Kontext-Sharing ist vorteilhaft |
| Einfaches Dateilesen/-bearbeiten | Hauptagent (4.6) direkt | Delegations-Overhead wäre größer |
| Websuche/Research | fresh agent + model: opus | Präzise Schlussfolgerung nötig |
Bis zu 4–8 gleichzeitige Worktrees sind stabil. Darüber hinaus wird das Review der Ergebnisse zum Flaschenhals.
Bekannte Reibungspunkte
Perfekt ist es nicht. Zwei derzeit bekannte Einschränkungen.
Erstens das Problem des Modell-Override-Leaks. Die model-Einstellung eines Subagenten kann sich auf untergeordnete Agenten weitervererben, die dieser Subagent erstellt. Da dies zu unbeabsichtigter Modellverwendung führen kann, ist es praktisch sinnvoll, die Tiefe der Subagenten auf eine Stufe zu begrenzen.
Zweitens das Fehlen agentenspezifischer Modellkonfiguration. Derzeit bietet Claude Code keine offizielle Funktion, um in den Projekteinstellungen vorab Modelle pro Agententyp zuzuweisen. Der model-Parameter muss bei jedem Agent-Aufruf explizit angegeben werden. Auch in der Community gibt es aktive Nachfrage nach dieser Funktion.
Beide Punkte sind Reibungen, die sich mit der Weiterentwicklung von Claude Code auflösen werden. Schon im jetzigen Zustand lässt sich der strukturelle Vorteil allein durch manuelles Override voll ausschöpfen.
Kommunikator und Denker sind verschiedene Rollen
Im Gerichtssaal befassen sich Richter und Anwälte mit demselben Recht, haben aber unterschiedliche Rollen. Der Richter urteilt. Der Anwalt erklärt dem Mandanten, was dieses Urteil bedeutet. Wenn der Richter dem Mandanten direkt das Urteil vorliest, versteht der Mandant es nicht. Wenn der Anwalt selbst das Urteil fällt, fehlt es an Begründung. Rollentrennung ist keine Schwäche, sondern eine Stärke des Systems.
Beim Code Review ist es genauso. Die Fähigkeit eines Senior-Entwicklers, Bugs zu finden, und die Fähigkeit, einem Junior-Entwickler diesen Bug begreiflich zu machen, sind zwei verschiedene Dinge. Dass ein hervorragender Ingenieur auch ein hervorragender Tech Writer ist, kommt selten vor. Organisationen wissen das und trennen deshalb die Rollen.
Bei KI ist es genauso. Schlussfolgerungsfähigkeit und Kommunikationsfähigkeit sind verschiedene Achsen. Und im aktuellen Trainingsprozess der Modelle tendieren diese beiden Achsen dazu, in Konflikt zu geraten. Maximiert man die Schlussfolgerungsleistung, wird der Output komprimiert und fachspezifisch. Maximiert man die Kommunikationsleistung, leidet die Tiefe der Schlussfolgerung.
Von einem einzelnen Modell zu verlangen, beides gut zu können, ist wie vom Richter zu verlangen, auch die Rolle des Anwalts zu übernehmen. Es geht — aber optimal ist keines von beidem.
Die Trennung von Kommunikationsmodell und Schlussfolgerungsmodell ist ein strukturelles Prinzip, das auch über Versionswechsel hinweg gültig bleibt. 4.6 und 4.8 sind nur die heutige konkrete Wahl. Wenn morgen 5.0 und 5.2 erscheinen, ordnet man sie nach demselben Prinzip neu zu. Modelle werden ausgetauscht, aber die Tatsache, dass “die Rolle des tiefen Denkens” und “die Rolle der verständlichen Vermittlung” verschieden sind, wird nicht ausgetauscht.
Verwandte Artikel
- Ratchet Pattern — Wie man einen Agenten dazu bringt, bis zum Ende durchzuhalten
- Warum deine Agenten-Loop divergiert
- Warum Drift niemals stirbt
Weiterführende Lektüre (extern)
- RouteLLM: Learning to Route LLMs with Preference Data — Ein Framework für dynamisches Routing zwischen starkem und schwachem Modell basierend auf Anfragekomplexität.
- Anthropic: How we built our multi-agent research system — Wie Anthropic deep-research mit dem Orchestrator-Worker-Pattern implementiert hat.
Quellen
- Camerer, C., Loewenstein, G. & Weber, M. (1989). The Curse of Knowledge in Economic Settings: An Experimental Analysis. Journal of Political Economy, 97(5), 1232-1254. DOI — Der experimentelle Nachweis des Fluchs des Wissens.
- Li, W. et al. (2025). Curse of Knowledge: Your Guidance and Provided Knowledge are biasing LLM Judges in Complex Evaluation. Findings of EMNLP 2025. arXiv — Die Entdeckung, dass stärkere Schlussfolgerungsmodelle anfälliger für den Fluch des Wissens sind.
- Ong, I. et al. (2025). RouteLLM: Learning to Route LLMs with Preference Data. ICLR 2025. arXiv — Ein Framework, das LLM-Routing aus Präferenzdaten lernt.