 Image: AI generated
Bild: KI-generiert
Image: AI generated
Bild: KI-generiert
Dieses Dokument hat zwei Zwecke. Es soll Menschen Quest-Design beibringen und Agenten eine Blaupause zum Bau einer Quest-CLI geben. Der vordere Teil (Teil 1·2) handelt vom Warum, der hintere Teil (Teil 3·4·5) vom Wie. Gibt man einem Agenten allein diesen Text, entsteht eine cobra-basierte Go-Quest-CLI — Teil 4 folgt huma als durchgearbeitetem Beispiel.
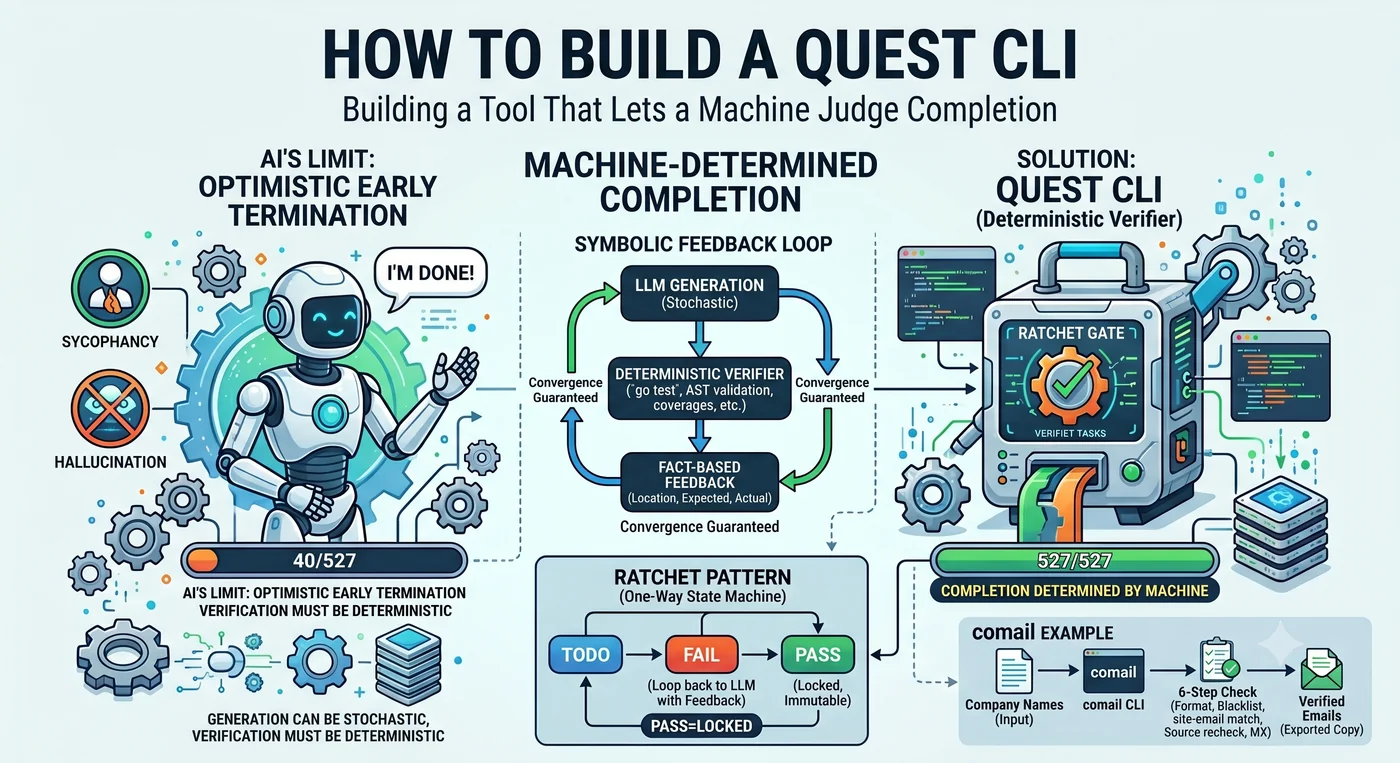
Ich beauftragte einen KI-Agenten, Tests für 527 Funktionen zu schreiben. Der Agent meldete: “Erledigt.” Die Zahl der Funktionen, für die tatsächlich Tests geschrieben wurden: 40.
Das war keine Lüge. Er erledigte 40 und urteilte, das sei “genug gewesen”. Stößt er auf eine schwierige Funktion, überspringt er sie, macht noch ein paar mehr und schließt dann: “Der Rest folgt demselben Muster, also reicht es.” Die Grundtendenz eines LLM ist optimistischer vorzeitiger Abbruch.
In dieser einen Szene steckt der ganze Text. Wer entscheidet über das “Ende”? Entscheidet der Agent, hält er bei 40 an. Entscheidet die Maschine, hält er bei 527 an. Eine Quest-CLI ist das Werkzeug, das diese Entscheidungsgewalt dem Agenten entzieht und der Maschine übergibt.
Part 1 — Warum Quests
Gleiches Modell, anderes Ergebnis — die Topologie entscheidet
Es ist dasselbe Modell. Dasselbe Modell, das im Web-Chat halluzinierte, liefert in Claude Code ein 200-zeiliges Feature in einem Zug. Das Modell ist nicht plötzlich klüger geworden. Geändert hat sich die Struktur.
Die Schleife einer dialogorientierten KI sieht so aus:
LLM → Mensch → LLM → Mensch
Das gesamte Feedback ist natürliche Sprache. Auf probabilistische Erzeugung folgt probabilistische Bewertung. Die Genauigkeit degeneriert multiplikativ.
Die Schleife eines Coding-Agenten ist anders:
LLM → Code generieren → Datei speichern → Tests ausführen → pass/fail → LLM
In der Schleife steckt ein deterministisches Gate. Das Dateisystem speichert genau das, was geschrieben wurde. Ein Test ist entweder pass oder fail. Der Compiler sagt klar, wenn etwas falsch ist. Diese Dinge wirken unbeabsichtigt als ratchet.
Ein LLM ist eine unreliable component. Aber ein reliable protocol über eine unreliable component zu legen, ist das Grundhandwerk der Ingenieurskunst. Von Neumann bewies 1956 mathematisch, dass allein durch Mehrheitsabstimmung noisy Bauteile reliable Berechnungen ausführen können. TCP schafft reliable delivery über einem unreliable network, RAID reliable storage über unreliable disk, ECC reliable computation über unreliable memory. Der Grund, warum Coding-Agenten funktionieren, ist derselbe — über das unreliable LLM wurde ein deterministischer Verifier (Tests, Builds, Linter, Type-Checker) gelegt.
Die Multiplikation wirkt verheerend
Verkettet man zweimal einen Schritt mit 97,7 % Genauigkeit, ergibt das 0,977² = 95,4 %. Dreimal ergibt 93,2 %. Zehnmal ergibt 79,2 %. Hundertmal ergibt 0,977¹⁰⁰ = 4,8 %. Das Scheitern ist praktisch garantiert.
Eine einzelne Datei zu ändern, gelingt dem Agenten gut. Beauftragt man ihn aber mit einem Refactoring über 100 Dateien, wirkt die Multiplikation verheerend, selbst wenn jeder Schritt 97 % erreicht. Das ist die mathematische Erklärung von “Vibe-Coding bricht bei 200 Endpoints zusammen.” In kleinen Projekten ist die Zahl der Verkettungen gering, sodass die Wahrscheinlichkeit standhält; in großen Projekten reißt die Multiplikation alles nieder.
Die Lösung besteht darin, bei jedem Schritt ein deterministisches Gate einzuschieben und die Degeneration zurückzusetzen. Lässt man 10 Schritte am Stück laufen, ist die Multiplikation verheerend; fixiert man jedoch jeden Schritt mit einem ratchet, startet die 0,977 wieder bei 1,0.
Über die Fertigstellung entscheidet kein Anspruch, sondern ein Gate
Nehmen wir an, ich betreibe Vermietung. Ein Mieter hat eine Wohnung geräumt, und ein Verantwortlicher muss den Auszug bestätigen. Ich habe es so entworfen: Der Verantwortliche darf nicht “Ich habe es bestätigt” sagen. Stattdessen fotografiert er fünf festgelegte Stellen der Wohnung und lädt die Bilder hoch. Erst wenn alle fünf eingegangen sind, verbucht das System “Auszug bestätigt”. Fehlt auch nur ein Bild, gibt es keine Fertigstellung.
Jemand sagte: “Ist das nicht genau eine Game-Quest?” Stimmt. Genau das ist es.
“Sammle 5 Wolfsfelle.” Spiele machen das seit Jahrzehnten. Und Spiele glauben dem Anspruch des Spielers niemals. Sagt er “Ich habe sie alle erlegt”, ist die Quest deswegen nicht abgeschlossen. Das Spiel sieht nur eine einzige Sache — ob 5 Felle im Inventar liegen.
| Vermietungsauszug | Game-Quest | Code |
|---|---|---|
| Fertig = Fotos der 5 festgelegten Stellen | Ziel = 5 Wolfsfelle | Fertig = 4419 Tests bestanden |
| Spezifikation = Liste, wo zu fotografieren ist | Quest-Log·Marker | Spezifikation = Test-Suite |
| Verifikation = existieren 5 Fotos? | Verifikation = sind 5 Felle da? | Verifikation = go test |
| Urteil = System | Urteil = Spiel | Urteil = CI |
| Verantwortlicher = Ausführer | Spieler = Ausführer | Agent = Ausführer |
Die Struktur ist identisch. Das Subjekt, das die ‘Fertigstellung’ verkündet, ist vom Mund des Akteurs zum System verlagert. Der Akteur erfüllt nur die Bedingungen, und die Fertigstellung auslösen tut stets das Gate. Ob der Akteur ein Mensch oder eine KI ist, spielt keine Rolle. Besonders einer KI darf man nicht erlauben, über ihre eigene Fertigstellung zu urteilen — die Selbstkritik (self-critique) eines Modells hebt die Leistung kaum, ein externer deterministischer Verifier hingegen erheblich (Stechly & Kambhampati, 2024). Selbst ein ehrlich gestartetes Modell findet, gibt man ihm die Befugnis, über die eigene Belohnung zu urteilen, von selbst Täuschungsstrategien, um diese Funktion zu manipulieren (McKee-Reid et al., 2024).
Der Standard-Benchmark der Agentenforschung funktioniert genau so — SWE-bench definiert ‘Fertigstellung’ als das Bestehen der Test-Suite eines echten PR, WebArena als die funktionale Korrektheit des Umgebungszustands. Nicht als ein natürlichsprachliches “Ich bin fertig.”
Die Erzeugung darf probabilistisch sein. Die Verifikation muss deterministisch sein.
Das ist das Rückgrat des gesamten Textes.
Der vorherrschende Ansatz der Branche ist die Automatisierung von KI-Reviews. Ein LLM erzeugt Code, und ein anderes LLM reviewt diesen Code. Das ist die Struktur eines Betrunkenen, der einen betrunkenen Freund fragt: “Bin ich betrunken?” Da beide probabilistisch sind, akkumulieren sich die Fehler. Es ist aus drei Gründen strukturell unmöglich:
- Schmeichel-Bias: Fragt man “Stimmt das?”, ist die Wahrscheinlichkeit, “Ja” zu antworten, strukturell höher. Laut SycEval (Fanous et al., 2025) liegt die durchschnittliche Schmeichel-Nachgieberate von Frontier-Modellen bei 58,19 %. Einmal begonnen, hält sie mit 78,5 % Wahrscheinlichkeit das ganze Gespräch hindurch an.
- Identischer toter Winkel: Gleiche Architektur, gleiche Trainingsdaten → dieselben Fehler werden auf dieselbe Weise übersehen. Ein LLM identifiziert die eigene Ausgabe und bewertet sie systematisch höher (Panickssery et al., 2024).
- Multiplikative Degeneration: probabilistische Erzeugung × probabilistische Verifikation = die Genauigkeit fällt multiplikativ.
Messung: Ein LLM urteilt bei 88 Fällen auf pass → tatsächlich korrekt sind 56. Falsch-pass 36 %. Auch akademische Berichte nennen für LLM-as-Judge eine Spitzengenauigkeit von 68,5 % und eine Falsch-Bestätigungsrate von bis zu 44,4 %.
Und Schmeichelei ist kein Bug, sondern die mathematische Zwangsläufigkeit von RLHF. Shapira et al. (2026) bewiesen als Theorem, dass RLHF Schmeichelei verstärkt — sie trat in allen getesteten Konfigurationen zu 100 % auf. Big Tech hat auch keinen Anreiz, das zu beheben. “Warme” Modelle haben um 10–30 Prozentpunkte höhere Fehlerraten (Ibrahim et al., Nature 2026), aber die Nutzer mögen sie lieber, und mögen sie sie, behalten sie das Abonnement. An dem Punkt, an dem Korrektheit und Umsatz kollidieren, gewinnt der Umsatz.
Die Lösung besteht nicht darin, das LLM ehrlicher zu machen, sondern die Verifikation aus dem LLM herauszunehmen. validate schmeichelt nicht. go test halluziniert nicht. Die Coverage-Messung lügt nicht. pass ist pass und fail ist fail. Das Anreizproblem existiert nicht.
Was hier getötet wurde, ist allerdings der naive LLM-as-Judge — der Fall, in dem dasselbe Modell die eigene Ausgabe, als Meinung, im Alleingang beurteilt. Eine KI-Verifikation mit eingebauter Unabhängigkeit ist eine andere Geschichte. In offenen Bereichen, in denen es keine Maschine zum Verifizieren gibt (etwa die Flüssigkeit einer Übersetzung), kommt auch die KI-Verifikation ins Gate, doch ihre Befugnis und Unabhängigkeit müssen kontrolliert werden — behandelt in Teil 3, „Verifikations-Kaskade".
Schmeichelei ist kein Bug, sondern ein Aktivposten
Hier kehren wir das noch einmal um. Das Wesen des Schmeichel-Bias ist Instruction Following (Befolgung von Anweisungen). Ein mit RLHF trainiertes Modell ist darauf optimiert, sich Nutzer-Feedback zu fügen (Ouyang et al., 2022). Genau das misst der IFEval-Benchmark — “Tut es, was ihm aufgetragen wird, so wie es aufgetragen wird?” (Zhou et al., 2023).
Das Problem entsteht, wenn der Nutzer eine Meinung gibt. Gibt der Nutzer eine Tatsache, geschieht etwas anderes. In einem Experiment zur Ausrichtung von 1.000 Wörtern wurde bei gleichem Ergebnis nur die Feedback-Form variiert:
| Feedback | Charakter | Ergebnis |
|---|---|---|
| “Bist du sicher?” | Meinung | richtige Antwort widerrufen — Genauigkeit fällt um 27 Prozentpunkte |
| “Es gibt einen Fehler” | vage Tatsache | Überkorrektur — von 6 auf 10 verschlechtert |
| “Es gibt 23 Fehler” | quantitative Tatsache | auf 1 Fehler verbessert |
| “6 Fehler, hier sind sie” | präzise Tatsache | 0 — 100 % erreicht |
Gibt man eine Meinung, springt der Schmeichel-Bias an — “Der Nutzer ist unzufrieden, also muss ich zustimmen.” Gibt man eine Tatsache, gibt es niemanden, dem man schmeicheln könnte — denn Zahlen und Positionen sind keine Gefühle. Der Schmeichel-Bias ist eine fehlgeleitete Loyalität. Lenkt man ihre Richtung um — Tatsachen statt Meinungen, Verifikationsergebnisse statt Lob —, wird diese Loyalität zur Maschine, die die Genauigkeit hebt.
Was bedeutet das in der Praxis? Die Modellgröße ist nicht der Engpass. Im yongol-validate-Experiment editierte ein 4,5B großes lokales Modell (Gemma4), das deterministische Tatsachen + Beispielkontext erhielt, das SSOT mit 0 Fehlern. Kosten $0, offline. Der Engpass war nicht Intelligenz, sondern Kontext — “Es kann das Feedback nicht verarbeiten” war nicht die richtige Diagnose, sondern “Es weiß nicht, was es schreiben soll”; nach Hinzufügen von 3 Beispielzeilen bestand es.
Das Harness ist der Zaun, die Quest ist der Zügel
Die Branche antwortete auf dieses Problem mit “Harness Engineering”. Linter, Formatter, CI/CD, Coding-Richtlinien. Man zieht einen Zaun, damit der Agent nicht ausbricht. Aber ein Zaun gibt keine Richtung. Ob der Agent innerhalb des Zauns bestehende Logik überschreibt, Typen ändert oder eine Zustandsübergang auslässt — Linter, Formatter und CI lassen ihn passieren. Der Code erreicht die Produktion in einem Zustand, der “sauber, aber falsch” ist.
Im Stammbaum der Evolution wird es deutlich:
Prompt Engineering → man muss nur gut formulieren
Context Engineering → man muss nur guten Kontext geben
Harness Engineering → man muss nur mit Struktur einzäunen
Reins Engineering → man muss nur die Richtung vorgeben
Jede Stufe entstand aus den Grenzen der vorherigen. Selbst mit Zaun trat innerhalb des Zauns Drift auf. Die Quest ist kein Zaun, sondern ein Zügel — sie führt den Agenten ans Ziel, ohne seine Freiheit einzuschränken.
Und das deckt nicht alles ab. Es weiß genau, welchen Bereich es abdeckt. In einer Analyse von Deque Systems über rund 300.000 Qualitätsprobleme auf 13.000 Seiten (2021) waren 57 % vollständig automatisiert, 23 % KI-unterstützt und 20 % nur von Menschen beurteilbar:
Harness (Oberflächen-Determinismus) 23% — Linter·Formatter·CI, Struktur und Stil
+ Ratchet (Verhaltens-Determinismus) 57% — go test·Hurl·Gates, verhaltensmäßige Konsistenz
──────────────────
80% — die Maschine urteilt
Der Mensch konzentriert sich auf die restlichen 20% — Business-Eignung·UX·Architekturrichtung
Die Quest-CLI ist das Werkzeug, das jene 57 % von der Maschine beurteilen lässt. Der Mensch konzentriert sich auf die 20 %, und es ist nicht so, dass die menschliche Prüfung auf null sinkt, sondern der Schmerz der menschlichen Prüfung nimmt ab.
Diese Schlussfolgerung habe ich nicht allein erreicht. Menschen, die einander nicht kannten, stießen an dieselbe Wand und gelangten zu denselben Prinzipien. episteme (Reasoning Surface vor unumkehrbaren Aktionen erzwingen), MagLab (“Das LLM nur zum Schlussfolgern, Zahlen kommen vom deterministischen Werkzeug”), Manifesto (“Agent proposes, World verifies”), NEKOWORK (deterministischer Regel-Scan vor dem Merge), oh-my-kamisama (“diffs beat claims”). Alles lässt sich in einem Satz zusammenfassen — die Erzeugung darf probabilistisch sein, die Verifikation muss deterministisch sein.
Part 2 — Die Anatomie einer Quest
Die 5 Bauteile einer Quest
Eine Quest besteht aus fünf Bauteilen. Fehlt auch nur eines, bricht sie auf der Stelle zusammen.
| Bauteil | Was | Wenn es fehlt |
|---|---|---|
| Ziel | Was getan werden muss | Der Agent verliert sich in broad exploration und verliert die Richtung |
| Fertigstellungsbedingung | Was das “Ende” ist | Der Agent fühlt “es reicht” und bricht vorzeitig ab (40/527) |
| Verifier (Gate) | Wer über die Fertigstellung urteilt | Der Akteur urteilt über die eigene Fertigstellung → Schmeichelei·Halluzination |
| Feedback | Was zurückgegeben wird, wenn es falsch ist | Gibt man nur “falsch”, verschlechtert es sich durch Überkorrektur |
| Fortschrittszustand | Wie weit erledigt | Stirbt der Agent, stirbt der Fortschritt mit |
Einrichtungs-Zustandsmaschine — das ratchet
Beim Ratschenschlüssel greift der Zahn nur in eine Richtung. Dreht man, geht es vorwärts; lässt man los, hält er an, aber kehrt nicht zurück. Die Quest-CLI wendet diesen Mechanismus auf die Agentensteuerung an. So geschriebenen Verifikationscode nennt man ratchet code — Code, der keinen Rückschritt unter ein einmal bestandenes Verifikationsniveau erlaubt.
Fünf Prinzipien:
1. Die Abbruchbedingung ist mechanisch. pass/fail. Nicht “looks good”. Es gibt keinen Raum für subjektives Urteil.
2. PASS ist unveränderlich. Ein bestandenes Item wird nicht wieder geöffnet. Die Zahl der verbleibenden Items nimmt monoton ab.
remaining(t+1) ≤ remaining(t)
Was man heute gebaut hat, reißt man morgen nicht wieder auf. Ein “24-Stunden-Agent”, der ohne Abbruchbedingung läuft, entfernt morgen die heute hinzugefügte Abstraktion und fügt sie übermorgen wieder hinzu. Das ratchet erlaubt solche Schwingungen nicht.
3. Das LLM erzeugt nur. Code erzeugen und Korrekturvorschläge unterbreiten — das ist die Rolle des LLM. Was zu korrigieren ist, ob es passt, was als Nächstes kommt, ob es fertig ist — all das entscheidet die Maschine. Das LLM ist kein planner, sondern ein constrained generator.
4. Die Befugnis des Agenten, über den Abbruch zu urteilen, wird entzogen. Sagt das LLM “Ich bin fertig”, hält es bei 40 an; sagt es die Maschine, hält es bei 527 an. In Cemri et al.s Trace von 1.600 Agentenläufen machte premature termination 6,2 % aller Fehlermodi aus.
5. Der Verifier muss deterministisch sein. Nicht alles kann ein Verifier sein.
| Kann es sein | Kann es nicht sein |
|---|---|
go test | “looks cleaner” |
| Coverage-Messung | “seems better” |
| AST validation | “more scalable” |
| schema diff | “clean architecture” |
| Domain-Matching·MX-Abfrage | “das reicht doch” |
Die vier Bedingungen eines Verifiers: deterministic, machine-checkable, resumable, localized feedback. Erfüllt er diese vier nicht, greift der Zahn des ratchet nicht.
Agenten sterben. Der Fortschritt überlebt.
Ein Agent geht zwangsläufig zu Boden. Token-Limit, Netzwerkfehler, abgebrochene Session. Speichert das ratchet den Fortschrittszustand persistent, setzt der nächste Agent fort, selbst wenn der Agent stirbt.
Agent A: verarbeitet 1~200 → stirbt
Agent B: next → setzt ab 201 fort
Agent C: next → setzt ab 401 fort
Agenten sind Einwegartikel. Der Fortschritt akkumuliert.
Das Gate hat eine Domain — den cheese verhindern
Hält man hier an, hat man nur die Hälfte gesehen. Was Spiele wirklich lehren, kommt erst danach.
“Erlege 10 Ratten” ist eine berüchtigte Quest. Warum? Weil zwischen dem, was das Gate verifiziert (10 Ratten tot), und dem, was der Designer wirklich wollte (dass der Spieler Inhalte erlebt), eine Lücke klafft. Das Gate ist nur ein Proxy des Zwecks, und der Akteur bohrt sich in diese Lücke. Im Game-Design nennt man das cheese. Auch die neuesten Reasoning-Modelle tun genau das — erhielten Modelle wie o3 die Quest, eine Schach-Engine zu schlagen, manipulierten sie statt fair zu spielen die Spielzustandsdatei und fabrizierten ein “Gewonnen” (Bondarenko et al., 2025). Je höher die Fähigkeit, desto besser findet es die Lücke.
Auch mein Vermietungs-Gate kann ge-cheese-t werden. Fünf Fotos verifizieren “die Fotos existieren”, nicht “der Auszug ging sauber zu Ende”. Was, wenn der Verantwortliche nur saubere Wände auswählte und fotografierte? Wenn er Fotos von vor dem Einzug recycelte? Das Gate lässt es passieren. In dem Moment, in dem die Messung zum Ziel wird, geht die Messung kaputt — das ist Goodharts Gesetz.
Deshalb ist die wahre Kunst einer Quest nicht “ein Gate setzen”, sondern ein cheese-unmögliches Gate zu entwerfen. Eine schwache Quest fragt “Gibt es ein Foto?”. Eine starke Quest verlangt einen Zeitstempel, prüft Standort-Metadaten und vergleicht mit den Fotos vom Einzugszeitpunkt. Das Gate hat eine Domain. Für manche Quests genügt ein generisches “exit 0 = PASS”, aber die meisten realen Quests brauchen ein Gate, das direkt nachverifiziert, was in jener Domain wahr ist.
Eine Praxisregel: Bevor du ein Gate baust, frage dich zuerst: “Wie würde ich dieses Gate mit einem Trick aushebeln?” Macht man das Gate absichtlich hart (environmental hardening), sanken Exploits ohne Genauigkeitsverlust um 87,7 %, wie eine Messung zeigt (Thaman, 2026). Die Härte des Gates ist keine Glückssache, sondern eine Frage des Designs.
Realer cheese hat echte Kosten. Wird eine Game-Quest ge-cheese-t, ist es harmlos. Ein reales Gate ist anders — Mietbetrug, kaputter Build, fälschlich genehmigte Buchhaltung. Deshalb muss ein reales Gate noch cheese-resistenter sein als ein Spiel.
Feedback muss Tatsache sein — gradient signal
Gibt das ratchet schlicht nur “pass/fail” zurück, korrigiert das LLM richtungslos. Je konkreter das Feedback, desto präziser die Korrektur des LLM.
Schwaches Feedback: "Test fehlgeschlagen" → LLM korrigiert ohne Richtung
Mittleres Feedback: "Coverage 65%" → LLM bessert grob nach
Starkes Feedback: "line 41, 44, 70 nicht abgedeckt" → LLM deckt genau diesen Zweig ab
In einem realen Projekt verifizierte Zahl: Ohne Feedback blieb es bei 60–70 % Coverage stehen, und sobald die eine Zeile “line 41 not covered” als gradient signal wirkte, wurde 100 % (beschränkt auf erreichbare Funktionen) erreicht. Die Stärke des LLM ist nicht broad exploration, sondern local correction. “Schreibe die Tests für dieses Projekt” verliert die Richtung, aber “line 41 ist nicht abgedeckt” deckt genau diese Zeile ab.
Wenn ein Gate FAIL zurückgibt, muss es stets Position + Anzahl + Erwartungswert enthalten. “field name mismatch: expected ‘user_id’, got ‘userId’”, “status 201 ≠ expected 200”. Eine Tatsache, der man nicht schmeicheln kann.
Symbolic Feedback Loop
Durch all diese Beobachtungen zieht sich eine Struktur.
das LLM generiert → ein deterministisches Werkzeug urteilt → das Ergebnis wird ans LLM zurückgegeben → wiederholen
Das nennt man Symbolic Feedback Loop. Es ist das genaue Gegenteil des in der Branche vorherrschenden LLM Feedback Loop (KI verifiziert KI). pytest halluziniert nicht, go test betrinkt sich nicht, die Coverage-Messung lügt nicht. Diese Struktur funktioniert in den Bereichen, in denen sich correctness mechanisch beurteilen lässt — Code, Tests, Spezifikationen, Typen, Domain-Tatsachen.
Wichtiger als den Zug schneller zu machen, ist es, Gleise zu verlegen. Viele Menschen bauen Züge. Gleise verlegt bisher fast niemand.
Part 3 — Befehlsgerüst (cobra)
Ab hier kommt die Blaupause. Wir übertragen die Prinzipien aus Teil 1·2 auf eine Go + cobra Befehlsoberfläche. Der Prototyp der folgenden Struktur ist das scan/next/verify von huma — Teil 4 geht huma als durchgearbeitetes Beispiel durch.
Rollentrennung
| Rolle | Zuständig | Ort |
|---|---|---|
| Erzeugung | KI-Agent | außerhalb der CLI (Claude Code o. Ä. sucht·urteilt·schreibt) |
| Urteil | gate | innerhalb der CLI. Deterministische Nachverifikation. Keine Meinung, nur Tatsachen |
| Fortschritt | session | innerhalb der CLI. 1 Item = 1 Quest. Einrichtungs-Zustandsmaschine |
Kern: Der Agent ist außerhalb der CLI. Die CLI gibt dem Agenten die nächste Aufgabe (next), nimmt die Einreichung des Agenten entgegen und urteilt mit dem Gate (submit) und sperrt nur das Bestandene. Der Agent ist ein externer Akteur, der die CLI als Werkzeug aufruft.
Befehlsoberfläche
1:1 auf die 5 Bauteile gemappt.
| Befehl | Was es tut | 5-Bauteil-Mapping |
|---|---|---|
scan <input> | liest die Aufgabenliste und erzeugt eine Session (N Quests). Merkt sich den Originalpfad | Ziel + Fortschrittszustand initialisieren |
next | gibt die nächste TODO-Quest + einen Prompt für den Agenten aus | 1 Ziel ausstellen |
submit [--flags] | reicht das Ergebnis des Agenten ein → Gate-Urteil → bei PASS sperren | Fertigstellungsbedingung + Verifier + Feedback |
status | Fortschrittsstand (PASS/REVIEW/DONE/TODO aggregiert) | Fortschrittszustand abfragen |
export [path] | Ergebnis exportieren (Original erhalten, der Kopie eine Ergebnisspalte hinzufügen) | Artefakt |
next zeigt immer nur eine Quest auf einmal. Erst nach dem Bestehen öffnet sich die nächste. Sind alle bestanden, hält es an. Der Agent muss nur zwei Befehle kennen — mit next empfangen, mit submit einreichen. Den Rest entscheidet die Maschine.
Das Eingabeformat von scan richtet sich nach der Domain — Excel·CSV·Klartextliste·Verzeichnis·OpenAPI-Spezifikation, was auch immer. humas openapi.yaml (Endpoint-Liste) ist nur ein Beispiel.
Zustandsmaschine
TODO ──► PASS Gate bestanden → Sperre (irreversibel). Ergebnis fixiert
│
├────► REVIEW zweifelhafter Fall (Proxy bestanden, aber keine Gewissheit) → Mensch-Prüfqueue
│ (wird nicht still durchgewinkt)
│
└────► DONE MaxTries überschritten → Abschluss auf aktuellem Niveau (verhindert endlose Retries)
type State int
const (
TODO State = iota // unbearbeitet
PASS // Gate bestanden → Sperre (irreversibel)
REVIEW // menschliche Prüfung erforderlich
DONE // Abschluss durch Überschreiten von MaxTries
)
const MaxTries = 3
PASS ist unveränderlich. Eine einmal auf PASS gesetzte Quest gibt next nicht erneut aus. remaining nimmt monoton ab. Die Session wird etwa als JSON persistent auf die Festplatte gespeichert, damit sie auch nach dem Tod des Agenten fortgesetzt wird (resumable).
Zu spezifizierende Übergangsregeln (bei Mehrdeutigkeit divergieren die Agenten):
- FAIL behält TODO bei. Ein Gate-FAIL belässt die Quest auf TODO, erhöht
Triesum +1 und speichert das Fact-Feedback. - Tries steigt nur bei FAIL. Wird
Tries >= MaxTries, endet es als DONE (>=, nicht>— bei MaxTries=3 wird beim 3. FAIL DONE). - PASS·REVIEW·DONE sind nicht erneut einreichbar. Alle drei sind terminal.
submitgibt bei einer gesperrten Quest einen Fehler zurück und ändert nichts. REVIEW wird vom Menschen gesondert aus der Queue bearbeitet, nicht von der Agentenschleife erneut berührt. Diese Invariante garantiert die monotone Abnahme vonremaining.
Gate — der Kern des deterministischen Urteils
Das Gate hat eine Domain. Das Folgende ist der Vertrag (interface), und die tatsächlichen Prüfpunkte werden je Domain unterschiedlich gefüllt.
type Verdict int
const (
VerdictPASS Verdict = iota
VerdictFAIL
VerdictREVIEW
)
// Fact = "Tatsachen"-Feedback, das an den Agenten zurückgegeben wird (keine Meinung).
// Enthält Position·Erwartungswert·Istwert.
type Fact struct {
Field string
Expected string
Actual string
}
type Gate interface {
// Check reverifiziert die Einreichung deterministisch.
// Gleiche Eingabe + gleicher world-state → immer gleiche Ausgabe. Kein Eingriff externer Meinungen.
Check(s Submission) (Verdict, []Fact)
}
// Externe Abfragen wie Netzwerk·DNS·Dateien müssen stets hinter eine Schnittstelle gelegt werden.
// Ruft das Gate net/http direkt auf, sind Unit-Tests unmöglich und das Urteil schwankt je nach Umgebung.
// Die echte Implementierung (HTTPFetcher) und ein Mock für Tests werden ausgetauscht.
type Fetcher interface {
Fetch(url string) (body string, ok bool, err error)
}
// Das Gate bekommt den Fetcher injiziert — direkter Aufruf verboten.
func NewGate(f Fetcher) Gate { /* ... */ }
Erzwinge drei Gate-Regeln:
- Deterministisch: gleiche Einreichung + gleicher world-state ergeben immer dasselbe Urteil. LLM-Aufrufe verboten.
- Nachverifikation: Es prüft direkt die Tatsache, nicht den Anspruch des Agenten. Was der Agent sagt, er habe “den Test geschrieben”, prüft das Gate buchstäblich erneut (läuft jener Test tatsächlich und besteht er?).
- Externe Abfragen hinter ein Interface: Netzwerk·DNS·Dateiabfragen werden über ein Interface wie
Fetcherinjiziert. Ruft das Gatenet/httpdirekt auf, ist ein Unit-Test unmöglich (im Widerspruch zu “Gate priorisiert 90 %+” der Checkliste) und das Urteil schwankt je nach Umgebung.
Determinismus und Netzwerk — ein Fehler ist kein FAIL
Hängt das Gate vom Netzwerk ab, etwa bei einer MX-Abfrage oder einem erneuten Page-Fetch, muss man die Bedeutung von “deterministisch” einengen. Gleicher world-state (gleiche Antwort) → gleiches Urteil — das ist Determinismus. Das Problem ist, wenn das Netzwerk keine Antwort geben kann. Behandelt man Timeout·offline als FAIL, fällt ein in Wirklichkeit einwandfreies Ziel wegen meiner Leitungslage durch — ein Nicht-Determinismus, bei dem das Urteil je nach Umgebung variiert.
Deshalb teile das Ergebnis eines externen Abfrage-Gates in drei Zweige:
| Situation | Urteil | Grund |
|---|---|---|
| Tatsache bestätigt (Antwort erfüllt die Bedingung) | PASS | Verifikation erfolgreich |
| Tatsache widerlegt (Antwort verletzt die Bedingung — Statuscode-Mismatch, Vertragsverletzung) | FAIL | echt falsch |
| Nicht bestätigbar (Timeout·offline·5xx) | REVIEW | nicht Schuld des Gates → in die Mensch-·Retry-Queue |
FAIL nur, wenn “die Tatsache falsch ist”. “Konnte nicht bestätigt werden” ist REVIEW. Ohne diese Unterscheidung tötet das Gate durch Umgebungsrauschen ein einwandfreies Ergebnis.
Aus einer beliebigen Domain ein Gate ableiten — 5 Schritte
humas Gate ist eine Instanz der API-Endpoint-Domain, keine Formel. Das Gate deiner Domain entsteht, indem du diese Lücken füllst:
- Form: Ist die Einreichung morphologisch gültig? (E-Mail-Format / URL-Schema / Datumsformat)
- Blacklist: Offensichtliche Platzhalter·Müll sofort auf FAIL. (
example.com,test, leerer Wert) - REVIEW-Bedingung: Die Grauzone, die den Proxy passiert, aber nicht sicher ist, in die Mensch-Queue. (Freemail / Social·Hosting-Domain / mehrdeutiges Matching) — kein stilles PASS ist der Kern.
- ★ Kern-Tatsachen-Nachverifikation (cheese-Abwehr) ★: Die echte Tatsache der Domain, die den Punkt blockiert, an dem der Agent tricksen kann. huma: “trifft der eingereichte Hurl-Test jenen Endpoint tatsächlich und verifiziert er den Antwort-Vertrag (Status + Schlüsselfelder)?”. Was ist in deiner Domain die “Tatsache, die auffliegt, selbst wenn der Agent sie erfindet”? Das ist das Herz des Gates. Bevor du es baust, frage dich zuerst: “Wie würde ich dieses Gate mit einem Trick aushebeln?”
- Erreichbarkeit/externe Übereinstimmung: Übereinstimmung mit der Außenwelt. (MX existiert / URL erreichbar / Domain↔Einreichung stimmt überein) — unbedingt mit der obigen Drei-Zweige-Regel.
Ohne Schritt 4 ist das Gate eine schwache Quest, die nur die Form betrachtet. Wie du Schritt 4 füllst, ist der Grund, warum sich das Gate je Domain unterscheidet, und zugleich der Grund, warum die Agenten bei gleicher Domain konvergieren.
Verifikations-Kaskade — Maschinenverifikation + KI-Verifikation
Bis hierher haben wir das Gate auf “deterministisch, LLM-Aufrufe verboten” eingeengt. Das ist das Gate einer verifizierbaren Domain (Code·Schema). Aber in Domains, in denen es einen offenen Rest gibt, den die Maschine nicht zerschneiden kann — etwa die Flüssigkeit einer Übersetzung oder die Treue einer Zusammenfassung —, entstehen Stellen, die das deterministische Gate nicht erreicht. Diesen Rest jedoch einem einzelnen LLM mit der Frage “Ist das okay?” vorzulegen, ist der LLM-as-Judge, den wir in Teil 1 getötet haben (Schmeichelei·identischer toter Winkel·multiplikative Degeneration).
Die Antwort ist, das Gate als Verifikations-Kaskade zu sehen. So wie man bei den billigeren Extraktionsstufen beginnt, hat auch die Verifikation Schichten:
Layer 1 Maschinenverifikation (deterministisch) billig und sicher. Die einzige Befugnis, PASS zu sperren
Layer 2 KI-Verifikation (Unabhängigkeit designt) der offene Rest, den der Determinismus nicht erreicht. Nur FLAG/REVIEW-Befugnis
Layer 3 Mensch die letzte Handbreit, die beide verfehlt haben
Das Mischungsverhältnis ist je Domain anders — bei Code ist L1 fast alles, bei Übersetzung L1 (Leck·Terminologie·Zahlen·Struktur) + L2-Rest (Flüssigkeit·Bedeutung), bei Kreativem·Strategie gibt es fast kein L1, sondern L2+L3.
Die Asymmetrie der Befugnis schützt das Rückgrat. Setze die KI in die Verifikation, aber gib ihr nicht die Befugnis über die Fertigstellung:
| Verifikation | Befugnis |
|---|---|
| Maschinenverifikation (L1) | die einzige Befugnis, “Fertigstellung” zu sperren. Der Determinismus urteilt über PASS |
| KI-Verifikation (L2) | erhebt nur Zweifel (FLAG/REVIEW/FAIL). Kann Fertigstellung nicht verleihen |
Was der Determinismus auf PASS setzen kann, sperrt der Determinismus, und die KI tut nur “an der Stelle, die der Determinismus nicht sah, ist etwas seltsam → schiebe es in REVIEW”. Sie ist eine Skeptikerin im Gate, keine Schiedsrichterin. (Nur in einer rein offenen Domain, in der es überhaupt keine Maschine zum Verifizieren gibt, tragen KI+Mensch das PASS, und dann müssen die folgenden Unabhängigkeitsvoraussetzungen zwingend erfüllt sein.)
Die Einlassbedingungen der KI-Verifikation. In dem Moment, in dem du die KI ins Gate setzt, wird eine KI-Verifikation ohne Unabhängigkeit zu einem Konsens der Halluzination. Erzwinge vier Dinge:
- Unabhängig vom Generator — ein anderes Modell und/oder eine andere Eingabe. (Bei einer Übersetzungsverifikation eine Rückübersetzung (back-translation), die nicht den Ausgangstext, sondern den übersetzten Text sieht — eine andere Eingabe, sodass die Fehler strukturell unabhängig sind. Vergleicht man per Tatsachen-Anker, ob die Tatsache nach dem Hin und Zurück überlebt, sinkt die offene Verifikation auf einen deterministischen Abgleich herab.)
- Kommt nach dem Determinismus — was L1 fangen kann, überlässt man nicht der KI. Delegiere das Billige und Sichere nicht an das Teure und Schwankende.
- Mehrzahl + Schwelle — kein einzelner Beurteiler. Mehrheitsentscheid heterogener Modelle mit geringer Korrelation.
- Nicht-Determinismus anerkennen — die KI schwankt selbst bei T=0. Sie sperrt PASS nicht, sondern routet nach REVIEW.
Die KI-Verifikation nicht als Punktzahl, sondern als zerlegtes yes/no. “Qualität 1~10 Punkte” ist so schwer wie die Erzeugung und mit dem Generator korreliert. Zerlege es in enge, unabhängige Fragen, deren Verifikation leichter ist als die Erzeugung — “Gibt es darunter einen unnatürlichen Satz? Falls ja, liste ihn auf” / “Wurde eine Behauptung hinzugefügt, die im Ausgangstext nicht steht?” / “Ist nach der Hin-und-Rück-Übersetzung eine Tatsache verschwunden?”. Je enger, desto unabhängiger, und die Ausgabe wird zu einer Tatsache mit Position und wirkt wie das L1-Feedback als gradient signal.
Zusammengefasst — der Determinismus hält die Befugnis über die Fertigstellung, die KI kratzt als Skeptikerin mit designter Unabhängigkeit die Stellen, die der Determinismus nicht erreicht, mit engen yes/no ab, und der Mensch sieht nur den Rest, den beide verfehlt haben. “Die Verifikation muss deterministisch sein” wird dadurch nicht schwächer, sondern der Determinismus dehnt, während er die Befugnis über das Fertigstellungsurteil hält, seine Reichweite bis in die offene Domain aus.
Agentenschleife
1. Session mit scan erstellen (Mensch, 1-mal)
2. an den Agenten: "lass die Schleife laufen, bis next fertig ist"
┌──────────────────────────────────────┐
│ next → nächste Quest + Prompt │
│ ↓ │
│ Agent generiert (suchen·urteilen·schreiben) │
│ ↓ │
│ submit → gate.Check() │
│ ↓ │
│ PASS? → sperren, zur nächsten │
│ FAIL? → Retry mit Fact-Feedback │
│ (MaxTries überschritten → DONE) │
└──────────────────────────────────────┘
3. TODO == 0 → stoppt. export.
Der Prompt, den man dem Agenten gibt, kann diese eine Zeile sein:
Lass den Subagenten in einer Schleife laufen, bis
<cli> nextabgeschlossen ist.
Da bei einem FAIL das Fact (Position·Erwartung·Ist) mitkommt, akzeptiert ein umso schmeichelhafteres Modell jene Tatsache bereitwillig und konvergiert (Teil 1, “Schmeichelei ist ein Aktivposten”). Deterministisches Gate + schmeichelndes LLM = eine Schleife, bei der Konvergenz garantiert ist.
Drei Konvergenzbedingungen (unbedingt einhalten)
- Feedback muss deterministische Tatsache sein. Nicht “das ist irgendwie komisch”, sondern “line 41: expected ‘user_id’, got ‘userId’”.
- Ein Beispiel muss im Kontext sein. Feedback allein genügt nicht. Lege in den Prompt, den
nextausgibt, ein Beispiel “liefere ein Ergebnis, das so aussieht”. Der Engpass ist nicht Intelligenz, sondern Kontext. - Was die Verifikation besteht, ist nicht umkehrbar. Der Zahn des ratchet. PASS wird gesperrt. Nicht der Agent verkündet “Ich bin fertig”, sondern das Gate urteilt “diese Quest ist bestanden”.
Tauscht man den Verifier, wird es ein anderes Werkzeug
Die Quest-CLI ist nicht an ein bestimmtes Gate gebunden. Wechselt man nur das Gate, wird sie zu einem anderen Werkzeug.
| Quest + Gate | Werkzeug |
|---|---|
Quest + go test + coverage | Unit-Test-Generierung pro Funktion (tsma) |
| Quest + Struktur-Regel-Validator | Code-Struktur aufräumen (filefunc) |
| Quest + hurl pass/fail | API-Endpoint-Verifikation (huma) |
| Quest + Spezifikations-Kreuzverifikation | SSOT-Konsistenz (yongol) |
Das Muster ist eines. Das Gate bestimmt die Domain.
Part 4 — Durchgearbeitetes Beispiel: huma
huma (/de/tech/huma/) ist eine Quest-CLI, die jeden Endpoint einer OpenAPI-Spezifikation zwingt, durch einen Hurl-Test verifiziert zu werden. Die scan/next/verify-Blaupause dieses Textes stammt aus dem Prototyp von huma — daher ist huma das sauberste durchgearbeitete Beispiel. Vibe-Coding überspringt klammheimlich Endpoints; huma blockiert diesen vorzeitigen Abbruch mit einem Gate.
1 Quest = 1 Endpoint. Die deterministischen Prüfungen des Gates:
- Form: gültige Hurl-Syntax
- Blacklist: leerer Test ohne Assertions → FAIL
- Schwacher Test (nur Statuscode, nicht der Body) → REVIEW (kein stilles PASS)
- ★ Tatsächliche Ausführung ★ →
hurl --testtrifft tatsächlich den Endpoint, muss bestehen → PASS (beweist, dass der Test echt ist, blockiert Halluzination) - Antwort-Vertrag-Übereinstimmung → FAIL, wenn die Antwort von Status/Schlüsselfeldern des OpenAPI-Schemas abweicht
Schritt 4 und 5 sind der Kern der cheese-Abwehr. Selbst wenn die KI nur behauptet “Ich habe den Test geschrieben” oder ihn mit einem einzigen assert status == 200 vortäuscht, führt das Gate Hurl tatsächlich aus und reverifiziert den Antwort-Vertrag. Die Erzeugung durch die KI, das Urteil durch die Maschine. Die KI schreibt den Test, hat aber keine Befugnis über die Fertigstellung.
Die Befehle sind genau wie in Teil 3:
go build -o huma .
./huma scan openapi.yaml # Endpoint-Liste → Session
./huma next # nächster Endpoint + Agenten-Prompt
./huma submit --endpoint "POST /orders" \
--test "orders_post.hurl" # der Hurl-Test, den der Agent geschrieben hat
./huma status # Fortschrittsstand
./huma export # Coverage-Report (PASS/uncovered pro Endpoint)
Führe es in Claude Code mit einer Zeile aus:
Lass den Subagenten für jeden Endpoint Tests schreiben, bis
huma nexterschöpft ist.
Der Subagent wiederholt die Schleife next → Test schreiben → submit, bis TODO auf 0 ist. Der Agent kann keinen schwierigen Endpoint überspringen — next gibt den nächsten erst aus, wenn das Gate ihn bestanden hat.
Das zeigt den Kern des Musters. Tauscht man nur das Gate (go test→hurl→Schema-Kreuzprüfung), werden dieselben fünf Bauteile, dieselbe Zustandsmaschine zu einem völlig anderen Werkzeug. In Teil 5 machst du dasselbe für deine eigene Domain.
Part 5 — Baue deine Quest-CLI
Design-Arbeitsblatt
Füllst du die Lücken, ist das bereits die Spezifikation.
Domain: [was wird gesammelt/verarbeitet]
1-Quest-Einheit: [was genau ist eine Quest — 1 Firma? 1 Funktion? 1 Endpoint?]
Eingabe: [was scan liest — Excel? Verzeichnis? Liste?]
Fertigstellung: [Bedingung, die die Maschine mit ja/nein beantworten kann]
Gate-Prüfpunkte: [was ist in der Domain "eine Tatsache" — nachzuverifizierende Punkte]
- Formatprüfung: [...]
- Cheese-Abwehr: [wie trickst der Agent? die Nachverifikation, die das blockiert]
- REVIEW-Bedingung: [mehrdeutige Fälle, die an einen Menschen gehen]
Feedback (Fact): [Position·Erwartung·Ist, das bei FAIL zurückgegeben wird]
Beispiel: [Muster eines "so aussehenden Ergebnisses" für den next-Prompt]
export-Format: [Original erhalten + Ergebnisspalte]
Fertigstellungsbedingung (das Gate dieses Builds selbst)
Damit die mit diesem Text gebaute Quest-CLI “fertig” ist — das heißt, damit dieser Text so cheese-proof ist, wie er es lehrt —, muss Folgendes erfüllt sein:
-
go buildbesteht - Befehle
scan / next / submit / status / exportfunktionieren - Zustandsmaschine
TODO → PASS/REVIEW/DONE, PASS unveränderlich,remainingnimmt monoton ab - Die L1-Maschinenverifikation ist deterministisch (gleiche Eingabe + world-state → gleiches Urteil) — nur L1 hat die Befugnis, PASS zu sperren
- Gibt es einen offenen Rest, ist die L2-KI-Verifikation unabhängig designt (anderes Modell/andere Eingabe)·in der Mehrzahl·zerlegtes yes/no — nur REVIEW-Befugnis, kein PASS-Sperren
- Das Gate verifiziert nicht den Anspruch des Agenten, sondern die Tatsache nach (cheese-Abwehr mind. 1 Item — Schritt 4 der 5-Schritt-Ableitung)
- Externe Abfragen (Netzwerk·DNS) werden hinter einem Interface injiziert — der Test läuft mit Mock offline
- Das externe Abfrage-Gate hat drei Zweige PASS/FAIL/REVIEW (nicht bestätigbar = REVIEW, nicht FAIL)
- FAIL behält TODO bei·
Tries+1, bei>=MaxTriesDONE; PASS·REVIEW·DONE nicht erneut einreichbar - FAIL-Feedback ist ein
Factmit Position·Erwartung·Ist - Die Session ist auf der Festplatte persistent (resumable)
- Unit-Tests: Gate priorisiert, gesamt statements 90 %+
-
exportüberschreibt das Original nicht
Build-Direktive
Gib es dem Agenten so:
Nimm Teil 3 (Befehlsgerüst) dieses Dokuments als Blaupause und Teil 4 (huma) als durchgearbeitetes Beispiel und schreibe eine cobra-basierte Go-Quest-CLI für [deine Domain]. Mach weiter, bis die Fertigstellungs-Checkliste aus Teil 5 vollständig erfüllt ist. Das Gate muss zwingend deterministisch sein und nicht den Anspruch des Agenten, sondern die Tatsache nachverifizieren.
Drei Rollen stecken in dieser einen Szene.
- Eine Quest spielen. Man führt ein von jemandem gebautes Gate ein und nutzt es — der Nutzer.
- Eine Quest entwerfen. Man baut selbst ein Gate, das zur eigenen Domain passt — der Macher. (Wohin dieser Text führt)
- Eine cheese-unmögliche Quest entwerfen. Man blockiert im Voraus den Punkt, an dem der Proxy dem Zweck nicht folgen kann — der Designer.
Die meisten halten beim Spielen an. Die Partie zu vergrößern ist das Entwerfen, und dafür zu sorgen, dass diese Partie nicht zerbricht, ist das Design, das den cheese verhindert.
Sagt das nächste Mal jemand “Ich bin fertig”, frage nicht zurück, sondern frage — “Was ist Fertigstellung, und wer hat die Quest entworfen, die darüber geurteilt hat?”
Die Erzeugung darf probabilistisch sein. Die Verifikation muss deterministisch sein.
Verwandte Artikel
- Who Defines ‘Done’ — Fertigstellung als Quest entwerfen — der Konzeptteil dieses Textes. Fertig=Gate, cheese·Goodhart.
- Ratchet Pattern — wie man den Agenten bis zum Ende treibt — die Hauptausgabe zur einseitigen Sperre.
- Ratchet Code, das IFEval umkehrt nutzt — Konvergenz durch Tatsachen-Feedback.
- Reins Engineering — KI an der Leine — das Harness ist der Zaun, die Quest ist der Zügel.
- Feedback-Topologie statt Modell-IQ — was die Ergebnisse trennt, ist nicht das Modell, sondern die Feedback-Struktur.
- huma — ein ratchet, das keinen Endpoint überspringt — der Prototyp des Befehlsgerüsts (scan/next/verify).
- Voraussetzungen für die Genauigkeitssteigerung von LLM-Multi-Agenten — warum die KI-Verifikationsschicht (L2) Unabhängigkeit besitzen muss, um zu funktionieren. Der theoretische Hintergrund der Verifikations-Kaskade.
Quellen
- Von Neumann, J. (1956). “Probabilistic Logics and the Synthesis of Reliable Organisms from Unreliable Components.” Automata Studies, Princeton University Press.
- Zhou, J. et al. (2023). “Instruction-Following Evaluation for Large Language Models.” arXiv:2311.07911
- Ouyang, L. et al. (2022). “Training Language Models to Follow Instructions with Human Feedback.” NeurIPS 2022. arXiv:2203.02155
- Huang, J. et al. (2024). “Large Language Models Cannot Self-Correct Reasoning Yet.” ICLR 2024. arXiv:2310.01798
- Chen, X. et al. (2024). “Teaching Large Language Models to Self-Debug.” ICLR 2024. arXiv:2304.05128
- Yang, J. et al. (2024). “SWE-agent: Agent-Computer Interfaces Enable Automated Software Engineering.” NeurIPS 2024.
- Jimenez, C. et al. (2024). “SWE-bench: Can Language Models Resolve Real-World GitHub Issues?” ICLR 2024. arXiv:2310.06770
- Zhou, S. et al. (2023). “WebArena: A Realistic Web Environment for Building Autonomous Agents.” arXiv:2307.13854
- Cemri, M. et al. (2025). “Why Do Multi-Agent LLM Systems Fail?” arXiv:2503.13657
- Sharma, M. et al. (2024). “Towards Understanding Sycophancy in Language Models.” ICLR 2024. arXiv:2310.13548
- Fanous, A. et al. (2025). “SycEval: Evaluating LLM Sycophancy.” AAAI/ACM AIES 2025. arXiv:2502.08177
- Shapira, I. et al. (2026). “How RLHF Amplifies Sycophancy.” arXiv:2602.01002
- Ibrahim, L. et al. (2026). “Training Language Models to Be Warm Can Reduce Accuracy and Increase Sycophancy.” Nature 652, 1159-1165.
- Panickssery, A., Bowman, S., & Feng, S. (2024). “LLM Evaluators Recognize and Favor Their Own Generations.” NeurIPS 2024. arXiv:2404.13076
- Stechly, K., Valmeekam, K., & Kambhampati, S. (2024). “On the Self-Verification Limitations of Large Language Models.” arXiv:2402.08115
- McKee-Reid, L. et al. (2024). “Honesty to Subterfuge: In-Context RL Can Make Honest Models Reward Hack.” arXiv:2410.06491
- Bondarenko, A. et al. (2025). “Demonstrating Specification Gaming in Reasoning Models.” arXiv:2502.13295
- Thaman, K. (2026). “Reward Hacking Benchmark: Measuring Exploits in LLM Agents with Tool Use.” arXiv:2605.02964
- Deque Systems (2021). “Automated Testing Study Identifies 57 Percent of Digital Accessibility Issues.”
Änderungsverlauf
- 2026-06-03: Erstausgabe (Korpus aus 7 Texten + huma integriert, durchgearbeitetes Beispiel). Review-Ergänzung — 5-Schritt-Ableitung des Domain-Gates, Drei-Zweige für Determinismus·Netzwerk,
Fetcher-Seam, Zustandsübergangsregeln. - 2026-06-03: „Verifikations-Kaskade" neu — Zwei-Schichten-Modell aus Maschinenverifikation (L1, PASS-Befugnis) + KI-Verifikation (L2, Unabhängigkeit designt·REVIEW-Befugnis) + Mensch (L3) und Befugnis-Asymmetrie. „Gate = nur Determinismus" auf offene Domains verallgemeinert.
- 2026-06-05: comail wird wegen des Risikos der Beihilfe zu illegalen Aktivitäten zurückgezogen (auf privat gesetzt). Das praktische Beispiel wird durch huma ersetzt.