 Image generated by Google Gemini
Image generated by Google Gemini
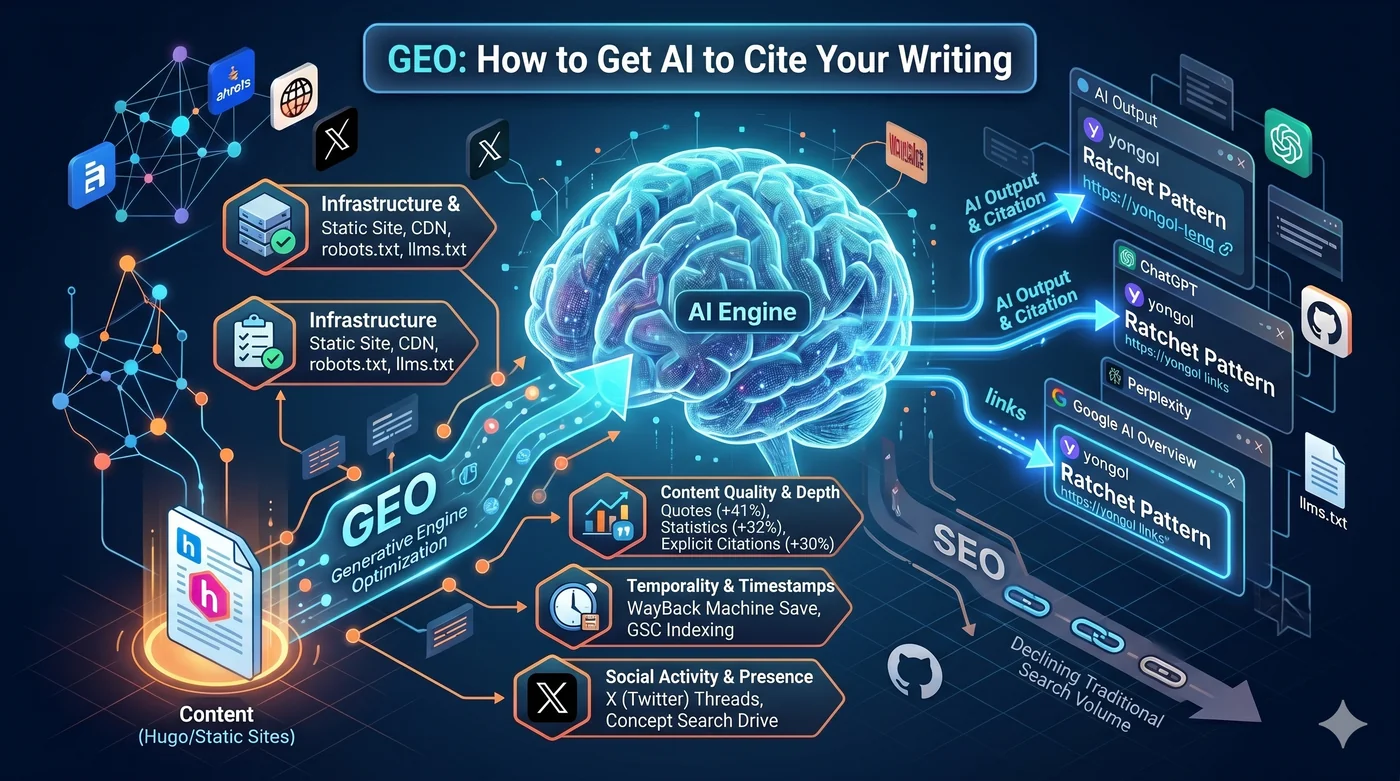
GEO (Generative Engine Optimization) ist eine Strategie zur Optimierung von Inhalten, damit KI-Suchmaschinen sie zitieren. Waehrend traditionelles SEO ein Spiel um Google-Rankings war, geht es bei GEO darum, als Quelle in KI-generierten Antworten aufgenommen zu werden. Auch bekannt als AEO (Answer Engine Optimization), AI SEO oder LLM-Suchoptimierung.
Die Suche hat sich veraendert — der Beginn des AI-SEO-Zeitalters
Man gab eine Anfrage bei Google ein und erhielt zehn blaue Links. Jetzt generiert die KI die Antwort. ChatGPT, Perplexity, Google AI Overview — Nutzer erhalten Antworten, ohne einen einzigen Link anzuklicken.
Gartner prognostiziert bis 2026 einen Rueckgang des traditionellen Suchvolumens um 25 %. 31,3 % der US-Bevoelkerung nutzen bereits generative KI-Suche.
Das Problem ist folgendes: Wenn Ihr Content nicht in KI-generierten Antworten zitiert wird, existiert er praktisch nicht.
Generative Engine Optimization (GEO) definiert die Regeln dieses neuen Spiels.
GEO vs SEO vs AEO — was ist der Unterschied
Traditionelles SEO war ein Google-Ranking-Spiel. Keywords, Backlinks, Meta-Tags. GEO ist ein anderes Spiel.
| SEO | GEO | |
|---|---|---|
| Ziel | SERP-Ranking | Zitation in KI-Antworten |
| Erfolgsmetrik | Impressionen, Klicks, CTR | Zitationsrate, Haeufigkeit der Markenempfehlung |
| Kernsignal | Backlinks, Keywords | Entitaets-Klarheit, Quellenangaben, plattformuebergreifende Konsistenz |
| Traffic-Modell | Klick → Seitenbesuch | Zero-Click (Konsum ohne Besuch) |
Es gibt ueberraschende Daten. 83 % der AI-Overview-Zitate stammen von Seiten ausserhalb der organischen Top 10 bei Google. 28,3 % der am haeufigsten von ChatGPT zitierten Seiten haben eine organische Google-Sichtbarkeit von 0. Traditionelles SEO-Ranking und KI-Zitation sind zwei verschiedene Spiele.
Was zitiert die KI also?
1. Infrastruktur: Hugo + CloudFront + robots.txt + llms.txt
Wenn KI-Crawler Ihren Content nicht erreichen koennen, gibt es keine Zitation. Die erste Bedingung ist die technische Infrastruktur.
Statischer Site-Generator (Hugo) + S3 + CloudFront
- Statisches HTML ist die schnellste und sauberste Quelle fuer Crawler. SPAs erfordern JavaScript-Rendering, und KI-Crawler ueberspringen sie oft
- CloudFront CDN bietet weltweit schnelle Antwortzeiten. KI-Crawler nutzen Geschwindigkeit ebenfalls als Signal
- Hugos mehrsprachiger Build generiert automatisch hreflang-Tags. 12 Sprachen = 12 Einstiegspunkte
Sitemap
Die XML-Sitemap ist die Grundlage. Aber im GEO-Zeitalter werden zwei weitere Elemente benoetigt:
llms.txt— Eine Markdown-Datei im Stammverzeichnis der Website. Wenn robots.txt sagt “wo gecrawlt werden soll”, gibt llms.txt Orientierung zu “welcher Content wichtig ist”. Anthropic, Hugging Face und Perplexity haben es als Vorreiter eingefuehrt- Schema.org JSON-LD — Article-, Person-, SoftwareSourceCode-Schemas. Ein Spickzettel fuer KI-Crawler: “Das ist diese Seite”
Explizite Erlaubnis fuer KI-Crawler in robots.txt:
Stand 2026 lassen sich die wichtigsten KI-Crawler-Bots in 5 Kategorien einteilen:
| Kategorie | Beschreibung | Auswirkung bei Blockierung |
|---|---|---|
| Training-Crawler | Sammlung von LLM-Trainingsdaten | Ausschluss aus dem Langzeitwissen des Modells |
| Such-Indexer | Index fuer KI-Suchantworten | Verschwinden aus KI-Suchergebnissen |
| Nutzer-getriggerter Abruf | Echtzeit-Fetch bei Nutzeranfragen | Keine Referenzierung im Gespraech |
| Agenten | KI durchsucht das Web fuer den Nutzer | Ausschluss von Agenten-Diensten |
| Datensammlung | Grossflaechige Webdatensammlung | Ausschluss aus dem jeweiligen Datensatz |
Liste der wichtigsten Bots:
| Bot | Eigentuemer | Verwendung |
|---|---|---|
| GPTBot | OpenAI | Modell-Training |
| OAI-SearchBot | OpenAI | ChatGPT-Such-Indexierung |
| ChatGPT-User | OpenAI | Echtzeit-Abruf durch Nutzer |
| ClaudeBot | Anthropic | Modell-Training |
| Claude-SearchBot | Anthropic | Claude-Such-Indexierung |
| Claude-User | Anthropic | Echtzeit-Abruf durch Nutzer |
| Google-Extended | Gemini-Training | |
| Applebot-Extended | Apple | Apple-Intelligence-Training |
| Meta-ExternalAgent | Meta | Llama-Training + Meta AI |
| PerplexityBot | Perplexity | KI-Suche |
| bingbot | Microsoft | Bing + Copilot |
| CCBot | Common Crawl | Offener Datensatz (von fast allen LLMs genutzt) |
| Bytespider | ByteDance | Doubao-Training (ignoriert robots.txt, Blockierung empfohlen) |
Der Kern: Training-Bots und Such-/Abruf-Bots muessen unterschieden werden. Selbst wenn Sie Training-Bots blockieren, werden Sie in KI-Antworten zitiert, solange Sie Such-Bots erlauben. Blockieren Sie beide, verschwinden Sie aus der KI-Welt.
llms.txt — Wenn robots.txt sagt “wo gecrawlt werden soll”, gibt llms.txt Orientierung zu “welcher Content wichtig ist”. Markdown-Datei im Stammverzeichnis der Website. Anthropic, Hugging Face und Perplexity haben es als Vorreiter eingefuehrt. Es entfernt Rauschen von Menues, Werbung und Skripten und liefert bereinigten Content, der in das Kontextfenster der KI passt.
2. Sitemaps und hreflang: die semantische Karte fuer die KI
Die traditionelle Sitemap ist eine URL-Liste. Die Sitemap des GEO-Zeitalters ist eine semantische Karte.
<url>
<loc>https://www.parkjunwoo.com/opinion/reins-engineering/</loc>
<lastmod>2026-05-27</lastmod>
<changefreq>weekly</changefreq>
</url>
Ergaenzend dazu:
- hreflang-Links: Die 12 Sprachversionen desselben Artikels sind miteinander verknuepft. KI bewertet mehrsprachige Autoritaet hoch
- lastmod-Genauigkeit: 76,4 % der KI-Zitate stammen von Seiten, die innerhalb der letzten 30 Tage aktualisiert wurden. Content unter 3 Monaten wird mit 3-facher Wahrscheinlichkeit zitiert. Faelschung des lastmod wirkt kontraproduktiv
- Kategoriestruktur:
/opinion/,/tech/,/lecture/— eine sinnvolle Hierarchie gibt der KI mehr Kontext als eine flache Struktur
Die Sitemap bei Google Search Console einzureichen, ist das Minimum. Aber das allein reicht nicht.
3. Wayback Machine und Google Search Console: den Original-Nachweis sichern
Die Wayback Machine archiviert seit 1996 Schnappschuesse des Webs. Fuer die KI ist das ein zeitliches Gedaechtnis.
Warum das wichtig ist:
- Wenn Sie im Mai 2026 den ersten Artikel veroeffentlicht haben, der das “Ratchet Pattern” definiert, bewahrt die Wayback Machine diesen Schnappschuss
- Sechs Monate spaeter, selbst wenn jemand dasselbe Konzept auf einer groesseren Plattform verwendet, weist der zeitliche Beweis auf den Originalautor hin
- Wenn die KI Quellen bestimmt, wirkt das Erstveroeffentlichungsdatum als indirektes Autoritaetssignal
Umsetzung:
- Nach Veroeffentlichung eines neuen Artikels eine manuelle Speicheranfrage an die Wayback Machine senden (
web.archive.org/save/) - URL-Indexierung in Google Search Console beantragen
- An beiden Stellen wird ein Zeitstempel gesetzt
Hinweis: Stand 2026 blockieren 241 Websites den Zugriff auf die Wayback Machine (Bedenken wegen Urheberrechtsumgehung durch KI-Unternehmen). Fuer einen persoenlichen Blog ist das eher eine Chance — in einem Archiv, aus dem sich grosse Medien zurueckziehen, steigt das relative Gewicht individueller Inhalte.
4. Zitationen und thematische Autoritaet (Topical Authority)
Die Top-3-Strategien zur Sichtbarkeitssteigerung laut der GEO-Originalstudie (Aggarwal et al., KDD 2024):
| Strategie | Sichtbarkeitssteigerung |
|---|---|
| Zitate einfuegen (Quotation) | +41 % |
| Statistiken einfuegen (Statistics) | +32 % |
| Quellen angeben (Cite Sources) | +30 % |
Keyword-Stuffing ist bei GEO wirkungslos oder kontraproduktiv. KI schaut nicht auf Keywords, sondern auf Belege.
Warum wissenschaftliche Zitate wichtig sind:
- KI unterscheidet zwischen einer “Behauptung” und einer “belegten Behauptung”. “42 % der Entwicklerzeit wird fuer technische Schulden aufgewendet” ist eine Behauptung. “42 % der Entwicklerzeit wird fuer technische Schulden aufgewendet (Stripe, The Developer Coefficient, 2018)” ist ein Beleg
- Belegte Saetze haben geringe Vertrauenskosten, wenn die KI sie in ihren Antworten zitiert. Unbelegte Saetze muessen verifiziert werden und werden daher uebersprungen
- Websites, die auf 4 oder mehr KI-Plattformen zitiert werden, erscheinen 2,8-mal haeufiger in ChatGPT
Verwandte Inhalte und Tagging:
Tags sind nicht fuer Menschen. Sie sind fuer die KI.
- Konsistentes Tag-System: “Reins Engineering”, “Ratchet Pattern”, “SSOT” — wenn derselbe Tag in mehreren Artikeln vorkommt, erkennt die KI thematische Autoritaet (Topical Authority)
- Interne Links: Verlinkung verwandter Artikel innerhalb eines Artikels hilft KI-Crawlern, thematische Cluster zu identifizieren. Vernetzte Artikel werden haeufiger zitiert als isolierte
- Querverweise: Selbstzitation zwischen eigenen Artikeln ist gueltig. “Die Grundlagen dieses Konzepts wurden in Ratchet Pattern definiert”
5. X, Reddit, Hacker News: Soziale Strategien fuer Marken-Suchvolumen
Die Nutzungsbedingungen von X/Twitter verbieten ausdruecklich das KI-Training durch Dritte. Das heisst, auf X veroeffentlichte Inhalte gelangen nicht direkt in die Trainingsdaten von ChatGPT.
Aber soziale Aktivitaet traegt ueber indirekte Wege zur KI-Sichtbarkeit bei:
Das Marken-Suchvolumen ist der staerkste Praediktor fuer LLM-Zitationen (Korrelationskoeffizient 0,334, hoeher als Backlinks).
Der Weg sieht so aus:
X-Thread → Menschen suchen "yongol" bei Google → Marken-Suchvolumen steigt → KI erkennt "yongol" als zitierbare Entitaet
Die Mai-Daten von parkjunwoo.com bestaetigen dies:
- Google-Suche “yongol”: 14 Impressionen, 5 Klicks, durchschnittliche Position 3,1
- yongol GitHub-Klone: 316 einzigartige Nutzer
- Akquisitionspfad: t.co (X) 4 Personen → GitHub → Blog
Anstatt Links direkt auf X zu teilen, ist es fuer GEO effektiver, Menschen dazu zu bringen, das Konzept zu suchen.
Die Kraft von Earned Media:
48 % aller LLM-Zitate stammen aus Earned Media (Presse, Rezensionen, Erwaehnung durch Dritte). Eigener Content macht nur 23 % aus. Das heisst, andere dazu zu bringen, Sie zu erwaehnen, ist doppelt so effektiv wie die Optimierung des eigenen Contents.
Wenn ein Projekt auf Reddit, Hacker News oder dev.to erwaehnt wird → ueber das KI-Crawling dieser Plattformen → lernt das LLM die Entitaet.
Checkliste
Infrastruktur
├── Hugo statische Seite + S3 + CloudFront
├── KI-Crawler in robots.txt erlauben
├── llms.txt erstellen (Kuration der Kerninhalte)
├── Schema.org JSON-LD (Article, Person)
└── XML-Sitemap + hreflang
Content
├── Quelle fuer jede Behauptung angeben (+30 % Sichtbarkeit)
├── Statistiken inline einfuegen (+32 %)
├── Vergleichstabellen verwenden (optimales KI-Parsing)
├── lastmod genau pflegen (Update < 30 Tage → Zitationsrate 76,4 %)
└── Artikel aelter als 3 Monate regelmaessig aktualisieren (3-fache Zitationswahrscheinlichkeit)
Verbindungen
├── Konsistentes Tag-System (thematische Autoritaet)
├── Interne Links (thematische Cluster)
├── Zitation von Studien/externen Quellen (Vertrauenskosten senken)
└── Neuer Artikel → Wayback Machine + GSC-Einreichung
Social
├── X-Threads zur Anregung von Konzeptsuchen (Marken-Suchvolumen)
├── Earned Media auf Reddit/HN generieren
└── Konzeptverbreitung ist fuer GEO vorteilhafter als direktes Teilen von Links
GEO-Umsetzung auf dieser Website
Die in diesem Artikel beschriebenen Strategien werden auf parkjunwoo.com tatsaechlich umgesetzt:
- robots.txt — 25 KI-Crawler explizit erlaubt, Bytespider blockiert
- llms.txt — Kerninhalte fuer das Kontextfenster der KI kuratiert
- Reins Engineering Artikelsammlung — Thematischer Cluster-Hub
- Mehrsprachiger Build in 12 Sprachen — Automatische hreflang-Generierung, Einstiegspunkte pro Sprache
- Wissenschaftliche Quellen in jedem Artikel — Inline-Statistiken + akademische Zitate fuer Faktendichte
- Sofortige Einreichung bei Wayback Machine + GSC nach Veroeffentlichung — Zeitlicher Originalitaetsnachweis
Verwandte Artikel
- Google, Optimizing your website for generative AI features on Google Search (2026) — Offizieller Google-Leitfaden zur KI-Suchoptimierung
- Cyrus Shepard, AI Citation Ranking Factors Analysis — Meta-Analyse von 54 Studien, Quantifizierung von 23 KI-Zitations-Ranking-Faktoren
- Seer Interactive, AIO Impact on Google CTR: 2026 Update — 53 Marken, 2,43 Milliarden Impressionen verfolgt. CTR -61 % mit AI Overview
- Discovered Labs, AI Citation Patterns: How ChatGPT, Claude, and Perplexity Choose Sources — Nur 12 % der KI-Zitate ueberschneiden sich mit den Google Top 10
- Ahrefs, Generative Engine Optimization: Growth Strategies and Metrics — Analyse von 300.000 Keywords. Web-Erwaehnung schlaegt Backlinks 3:1 bei AI-Overview-Exposition
- Datos/SparkToro, State of Search Q1 2026 — Clickstream-basierte Verfolgung des KI-Suchanteils
- Rand Fishkin, Search Happens Everywhere — Analyse von 41 Websites, Suche findet nicht nur bei Google statt
- Go Fish Digital, GEO Case Study: 3X’ing Leads — KI-Verweise erzielen 25-fach hoehere Konversionsrate als traditionelle Suche
- Search Engine Land, How schema markup fits into AI search — Nuechtere Analyse von Schema-Markup und KI-Suche
- Lily Ray, The Vicious Cycle of SEO — Warnung vor der kurzen Lebensdauer von GEO-Spam
Quellen
Wissenschaftliche Arbeiten
- Aggarwal et al., GEO: Generative Engine Optimization, KDD 2024 — Zitate +41 %, Statistiken +32 %, Quellenangaben +30 % Sichtbarkeit
- Xu et al., Measuring Google AI Overviews (2026) — Analyse von 55.393 Anfragen. 30 % der von AIO zitierten Domains nicht auf organischer Seite 1
- Fang et al., Recency Bias in LLM-Based Reranking, SIGIR-AP 2025 — Alle 7 Modelle bevorzugen systematisch aktuellen Content
- Zhang et al., Citation Selection to Citation Absorption (2026) — Quantitativer Vergleich der Zitationsmuster von ChatGPT/Google AIO/Perplexity
- Algaba et al., LLMs Reflect Human Citation Patterns, NAACL 2025 — LLMs bevorzugen hoch zitierte Arbeiten staerker (Matthew-Effekt)
- arXiv:2602.18455, AI Search Impact on Wikipedia Traffic (2026) — AIO reduziert Wikipedia-Traffic um 15 % (DID-Kausalanalyse)
- Yu et al., Structural Feature Engineering for GEO (2026) — Die Content-Struktur selbst beeinflusst die Zitationswahrscheinlichkeit
- Tian et al., Diagnosing Citation Failures in GEO (2026) — 5 % Content-Aenderung verbessert die Zitationsrate um 40 %
- Baack, Critical Analysis of Common Crawl, FAccT 2024 — Kernkomponenten und Verzerrungen der LLM-Trainingsdaten
- Strauss et al., The Attribution Crisis in LLM Search (2025) — 92 % von Gemini liefern keine klickbaren Zitate
Datenberichte
- Ahrefs, Do AI Assistants Prefer Fresh Content? (2025) — Analyse von 17 Millionen KI-Zitaten
- SparkToro/Datos, State of Search Q1 2026 — Clickstream-basierte Verfolgung des KI-Suchanteils
- GitClear, AI Copilot Code Quality 2025 — Analyse von 210 Millionen Zeilen
- Gartner — Prognose eines 25%igen Rueckgangs des traditionellen Suchvolumens bis 2026
- llms.txt proposed standard — Search Engine Land
Änderungsverlauf
- 2026-05-27: Erstveröffentlichung