 Image: AI generated
Image: AI generated
Er kommt genau dort zurück, wo man ihn behoben hat
Ich habe ein Werkzeug gebaut, das Drift schließt.
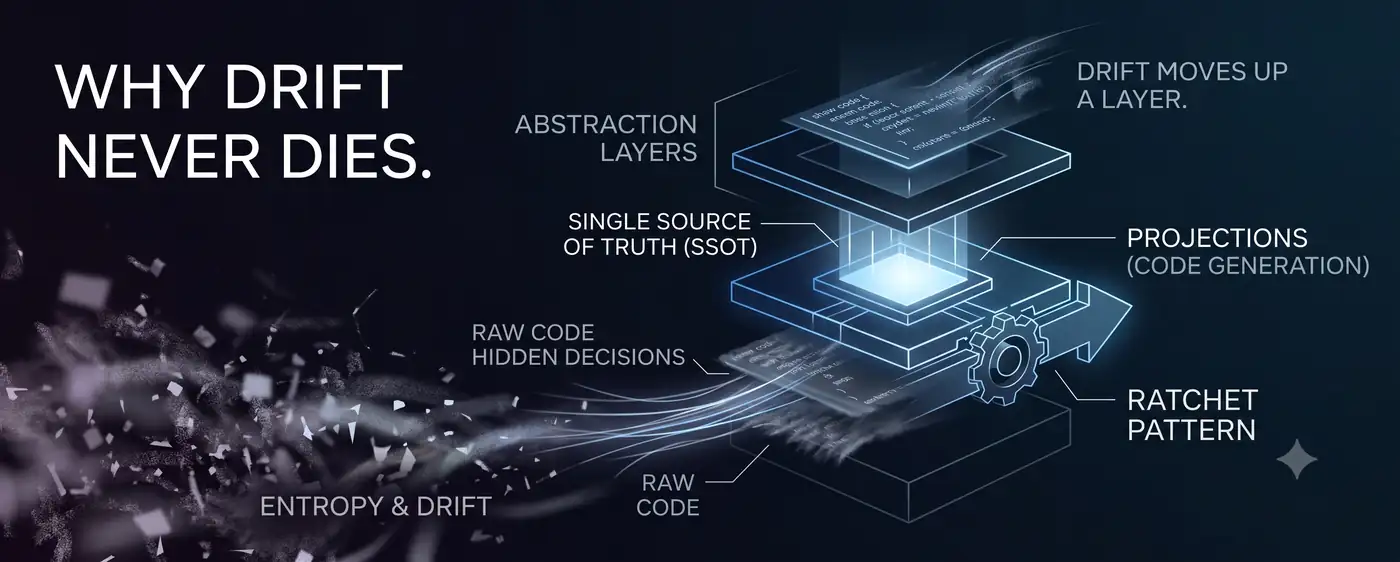
Die These von yongol ist einfach. Entscheidungen treiben ab, wenn sie nicht in einer einzigen autoritativen Quelle (SSOT) leben. Also legt man die Entscheidungen ins SSOT und macht Code zu einer Einweg-projection, die bei jeder Generierung neu gezeichnet wird. Geschäftslogik-Drift — etwa wenn eine als BIGINT festgelegte Spalte nach einem einzigen Refactoring stillschweigend zu INT zurückkehrt — war damit geschlossen.
Doch vor Kurzem analysierte ich einen Defektcluster in Code, den yongol erzeugt hatte, und bemerkte etwas Seltsames. Die Defekte gestanden sich in derselben Satzstruktur. „Die import-Sammlung ist davon entkoppelt, ob der Handler tatsächlich time verwendet." „Die requiredness-Inferenz ist davon entkoppelt, ob die Ziel-API diesen Parameter wirklich als required verlangt." Pfadparameter sind immer required, imports nur bei tatsächlicher Token-Nutzung. Dieselben strukturellen Entscheidungen steckten, in keinem SSOT verzeichnet, als bequeme lokale Proxys im Generator-Code.
Drift war nicht verschwunden. Er war eine Schicht nach oben gewandert. Die Geschäftslogik war per SSOT geschlossen, doch die strukturellen Entscheidungen des Generators selbst — der das SSOT liest und Code auswirft — hatten kein SSOT. Die These von yongol kehrte zu yongol selbst zurück. Genau an der Stelle, die die Theorie vorhergesagt hatte.
Also ändert sich die Frage. Warum Drift entsteht, weiß jeder. Die eigentliche Frage ist: Warum kommt er zurück, obwohl man ihn behebt?
Die Wurzel: Entscheidungen und Details sind verschiedene Dinge
Bauen wir von der Physik her neu auf.
Eine Entscheidung ist Information. Und zwar Information mit niedriger Entropie. „Diese Spalte muss 64 Bit haben" ist ein bewusstes Auswählen eines einzigen Zustands aus zahllosen möglichen. Die Natur mag niedrige Entropie nicht. Lässt man sie in Ruhe, versickert Information im umgebenden Rauschen. Der zweite Hauptsatz der Thermodynamik gilt auch für Entscheidungen.
Die Softwaretechnik beobachtet diesen Zerfall seit Langem. Lehmans Gesetze der Software-Evolution besagen, dass die Komplexität von E-type-Systemen zunimmt, sofern keine expliziten Anstrengungen unternommen werden, sie zu verringern (1980). Die Informationsphysik geht noch tiefer. Landauer zeigte 1961, dass selbst das Löschen eines einzigen Bits minimale thermodynamische Kosten verursacht (kT ln 2). Information zu verändern und festzuhalten ist prinzipiell nicht umsonst. Um eine Entscheidung an ihrem Platz zu halten, muss man fortwährend Energie aufwenden.
Damit Information überlebt, braucht sie zweierlei: einen autoritativen Speicher (authoritative store) und eine unaufhörliche aktive Rückprojektion (error correction) von dort aus. So funktioniert die DNA in unserem Körper, so funktionieren Paritätsbits in der digitalen Speicherung. Man bewahrt das Original separat auf und stellt bei jedem Mal daraus wieder her.
Drift entsteht, wenn diese Wiederherstellung bricht. Es gibt genau einen Mechanismus. Ich nenne ihn Proxy-Bindung. Wenn das Medium Entscheidung und Detail nicht getrennt bewahren kann, kann die nächste Person (oder der nächste Agent) die Entscheidung nicht aus der autoritativen Quelle lesen und leitet sie stattdessen aus einem bequemen korrelierten Signal in der Nähe ab. „Diese Spalte ist timestamptz, also muss ich wohl time importieren" — solche Vermutungen. Meistens stimmt es. Genau deshalb ist es gefährlich. Manchmal stimmt es nicht, und wenn es nicht stimmt, verschwindet die Entscheidung lautlos.
raw Code ist genau ein solches Medium. Code unterscheidet nicht zwischen „das ist eine Entscheidung" und „das ist an dieser Stelle zufällig wahr". Deshalb löst ein größeres Modell das Problem nicht. Wenn das Medium selbst Entscheidungen nicht tragen kann, gibt es nichts zu lesen — egal wie klug der Leser wird.
Dieses Phänomen war nicht namenlos. In der Softwarearchitektur unterschieden Perry und Wolf zwischen Erosion (Verletzung von Prinzipien) und Drift (Abstumpfung gegenüber der Architektur) (1992), und Cunningham nannte die Zinsen auf schlecht geschriebenen Code „technische Schulden" (1992). Jede Disziplin hat die Symptome treffend benannt. Was ich hinzufügen möchte, ist der eine zugrundeliegende Mechanismus (Proxy-Bindung) und die Struktur, dass dieser Mechanismus bei jedem Schließen rekursiv in die nächsthöhere Schicht aufsteigt. Es geht nicht um den Namen, sondern um die Kausalität.
Warum er nach oben steigt
Bis hierhin ist das bekannte Terrain. Das Neue kommt danach.
Um Drift zu schließen, braucht man zweierlei: einen Speicher, der Entscheidungen autoritativ hält (SSOT), und einen schließenden Akteur (Generator), der daraus Artefakte erzeugt. Doch der schließende Akteur selbst trifft ebenfalls Entscheidungen. Strukturelle Entscheidungen wie „Pfadparameter werden als required behandelt". Das Medium, in dem diese Entscheidungen leben — der Generator-Code — kann Entscheidung und Detail ebenfalls nicht getrennt tragen.
Derselbe Mechanismus wiederholt sich eine Schicht höher. Das Schließen selbst erzeugt eine Schicht darüber ein ungeschlossenes Medium. Drift wurde nicht ausgerottet — er ist umgezogen. In eine Schicht ohne Autorität.
Treibt man das bis zum Ende, gelangt man zu einer unbequemen Schlussfolgerung. Gibt man dem Generator ein SSOT? Dann trägt dasjenige, das dieses SSOT erstellt, seine eigenen Entscheidungen wieder in ein ungeschlossenes Medium ein. Mit jeder Schicht schrumpft die Angriffsfläche, doch ganz oben bleibt stets eine Schicht ohne Autorität. Ob Mensch oder Generator des Generators. Drift ist asymptotisch nicht ausrottbar. (Das ist eher eine starke Vermutung als ein Beweis. Doch jede Schicht, die ich bisher geschlossen habe, öffnete im Moment des Schließens die darüberliegende.)
Das ist die Antwort auf „Warum kommt er zurück, obwohl man ihn behebt?" Er kommt nicht zurück. Wenn wir eine Schicht schließen, öffnet das schließende Werkzeug die nächste. Dasselbe Wasser, das an einem höheren Deich wieder durchsickert.
Die Asymmetrie der Abhilfe: Was man deklarieren kann und was man nur verifizieren kann
Wie schließt man dann die obere Schicht? Hier offenbart sich eine entscheidende Asymmetrie.
Entscheidungen der Geschäftslogik sind in der Regel Werte. Die Spalte ist 64 Bit, der Zugriff nur für den Eigentümer, die Paginierung ist Cursor-basiert. Werte lassen sich deklarieren. Schreibt man sie in DDL, OpenAPI oder eine Spezifikationsdatei, wird das zum SSOT. Durch Deklaration geschlossen.
Die strukturellen Entscheidungen des Generators sind anders. „Pfadparameter sind required", „imports sind an tatsächliche Token-Referenzen gebunden", „required (Schlüssel vorhanden) und nicht-leer sind verschiedene Dinge." Das sind keine Werte, sondern Verhaltenseigenschaften einer Funktion über alle Eingaben hinweg. Verhaltenseigenschaften lassen sich nicht durch Deklaration aufzählen. Denn die Eingaben sind unendlich. Es gibt keine Möglichkeit, in ein YAML-Feld zu schreiben „diese Transformation muss sich in allen Fällen so verhalten".
Deshalb lassen sich Entscheidungen auf dieser Schicht nicht durch Deklaration, sondern nur durch Verifikation schließen. Typprüfer, Property-Tests, Compile-Gates. Nicht die Entscheidung als Daten festschreiben, sondern Verstöße durch ein maschinelles Tor abfangen — jedes einzelne Mal.
Was ich in einem anderen Artikel mit „Kodifiziere die menschliche Prüfung" meinte, bezieht sich genau auf diese Stelle. Manche Versprechen lassen sich deklarieren — das SSOT hält sie ein. Manche Versprechen lassen sich nicht deklarieren — Gates halten sie ein. Ob der vom Generator erzeugte Code kompiliert, lässt sich in kein SSOT schreiben. Es lässt sich nur durch das jedes Mal erneute Ausführen der Kompilierung bestätigen. Fehlt dieses Tor, schwebt das Versprechen „generate erfolgreich = Build möglich" außerhalb der Architektur — validate passiert mit 0/0, und trotzdem ist das Artefakt kaputt.
Drift, den man deklarieren kann, schließt man per SSOT. Drift, den man nur verifizieren kann, schließt man per Gate. Verwechselt man beides, jagt man mit Deklarationen ewig Maulwürfe.
Derselbe Fluss, ein anderer Deich
Diese Struktur wiederholt sich auch außerhalb von Code.
In der Wissensdomäne ist Drift der Verlust der Quelle. Geht verloren, wer eine Behauptung wann und auf welcher Grundlage aufgestellt hat, versickert diese Behauptung im Rauschen der „Tatsachen". Die nächste Person kann nicht aus der Autorität (der Originalquelle) lesen und leitet stattdessen aus dem Kontext ab. Genau deshalb habe ich GEUL als Sprache entworfen, die jeder Information zwingend Quelle, Zeitpunkt und Vertrauensstufe anheftet. Die Epistemologie, dass es keine Tatsachen gibt, sondern nur Behauptungen, ist eine Sicherung gegen Proxy-Bindung in der Wissensschicht.
Im Recht ist Drift die Abweichung von Präzedenzfällen gegenüber der ursprünglichen Entscheidung. Die Zivilisation hat das nicht dem Gewissen des Richters bei jedem Einzelfall überlassen, sondern Regeln kodifiziert, Verstöße definiert und Durchsetzungsmechanismen angehängt. Ein guter Richter ist kein SSOT, sondern ein Proxy. Das Gesetzesrecht ist das SSOT.
Derselbe Fluss. Wenn Entscheidungen nicht an einem autoritativen Ort leben, wenn das Medium Entscheidung und Detail nicht auseinanderhalten kann, dann treibt es ab. Ob Code, Wissen oder Recht.
Fazit: Nicht Ausrottung, sondern Hochschieben
Der Kampf gegen Drift kann nicht Ausrottung zum Ziel haben. Ausrottung ist unmöglich. Denn das schließende Werkzeug öffnet stets die nächste Schicht.
Das Ziel ist ein anderes. Drift in eine höhere Schicht mit kleinerer Angriffsfläche hochschieben und diese Schicht mit maschineller Verifikation bewaffnen. Sammelt man die über Zehntausende Zeilen raw Code verstreuten Entscheidungen an einem einzigen SSOT-Punkt, schrumpft die abdriftfähige Oberfläche dramatisch. Die verbliebene Oberfläche — die Verhaltensinvarianten des Generators — sperrt man mit Gates. Und dennoch bleibt ganz oben eine letzte Schicht, die sich nicht weiter delegieren lässt: das menschliche Urteil. Dort verifizieren wir jedes Mal neu und schlagen das Versprechen erneut fest.
Das ist der Ratchet. Er dreht sich nur in eine Richtung. Einmal hochgeklickt, rutscht der Zahn nicht mehr zurück. Die Entropie versucht, Entscheidungen herunterzuziehen, und der Ratchet schiebt sie jedes Mal eine Kerbe wieder hoch. Es gibt kein Gleichgewicht. Wer stehen bleibt, treibt ab.
Drift stirbt nicht. Deshalb hören wir nicht auf. Gegen die Entropie Versprechen zu bauen ist kein einmaliger Sieg, sondern ein permanenter Ratchet.
Verwandte Artikel
- Ratchet Pattern — Wie man einen Agenten bis zum Ende bringt
- Warum deine Agenten-Loop divergiert
- Reins Engineering — KI an den Zügeln
Weiterführende Lektüre (extern)
- Lehman’s laws of software evolution — Überblick über die empirischen Gesetze, dass Software ohne Eingriff zunehmend komplexer wird.
- Landauer’s principle — Die thermodynamischen Kosten des Löschens von Information.
Quellen
- Perry, D. E. & Wolf, A. L. (1992). Foundations for the Study of Software Architecture. ACM SIGSOFT Software Engineering Notes, 17(4), 40-52. ACM — Unterscheidung zwischen Erosion und Drift.
- De Silva, L. & Balasubramaniam, D. (2012). Controlling software architecture erosion: A survey. Journal of Systems and Software, 85(1), 132-151. ScienceDirect
- Lehman, M. M. (1980). Programs, Life Cycles, and Laws of Software Evolution. Proceedings of the IEEE, 68(9), 1060-1076. IEEE — Gesetz der steigenden Komplexität und des kontinuierlichen Wandels.
- Landauer, R. (1961). Irreversibility and Heat Generation in the Computing Process. IBM Journal of Research and Development, 5(3), 183-191. IBM — Minimale thermodynamische Kosten der Informationslöschung.
- Shannon, C. E. (1948). A Mathematical Theory of Communication. Bell System Technical Journal, 27, 379-423. DOI — Grundlage von Information, Entropie und error correction.
- Cunningham, W. (1992). The WyCash Portfolio Management System. OOPSLA ‘92 Experience Report. c2.com — Technische Schulden und „die Zinsen auf schlecht geschriebenen Code".