 Image: AI generated
Image: AI generated
Legacy lügt nicht
Legacy-Code hat keine Dokumentation. Und wenn doch, dann ist sie drei Jahre alt. Tests gibt es nicht, oder sie sind kaputt und mit skip markiert. Die Kommentare widersprechen dem Code. Der ursprüngliche Autor ist längst gegangen und hat nur den Satz hinterlassen: “Wenn du das anfasst, fliegt alles in die Luft.”
Und doch läuft dieser Code in genau diesem Augenblick. Er verarbeitet Zahlungen, nimmt Logins entgegen, legt Bestellungen an.
Dokumentation lügt. Kommentare lügen. Das menschliche Gedächtnis lügt noch schlimmer. Das Einzige, das nicht lügt, ist der Verkehr, der tatsächlich fließt.
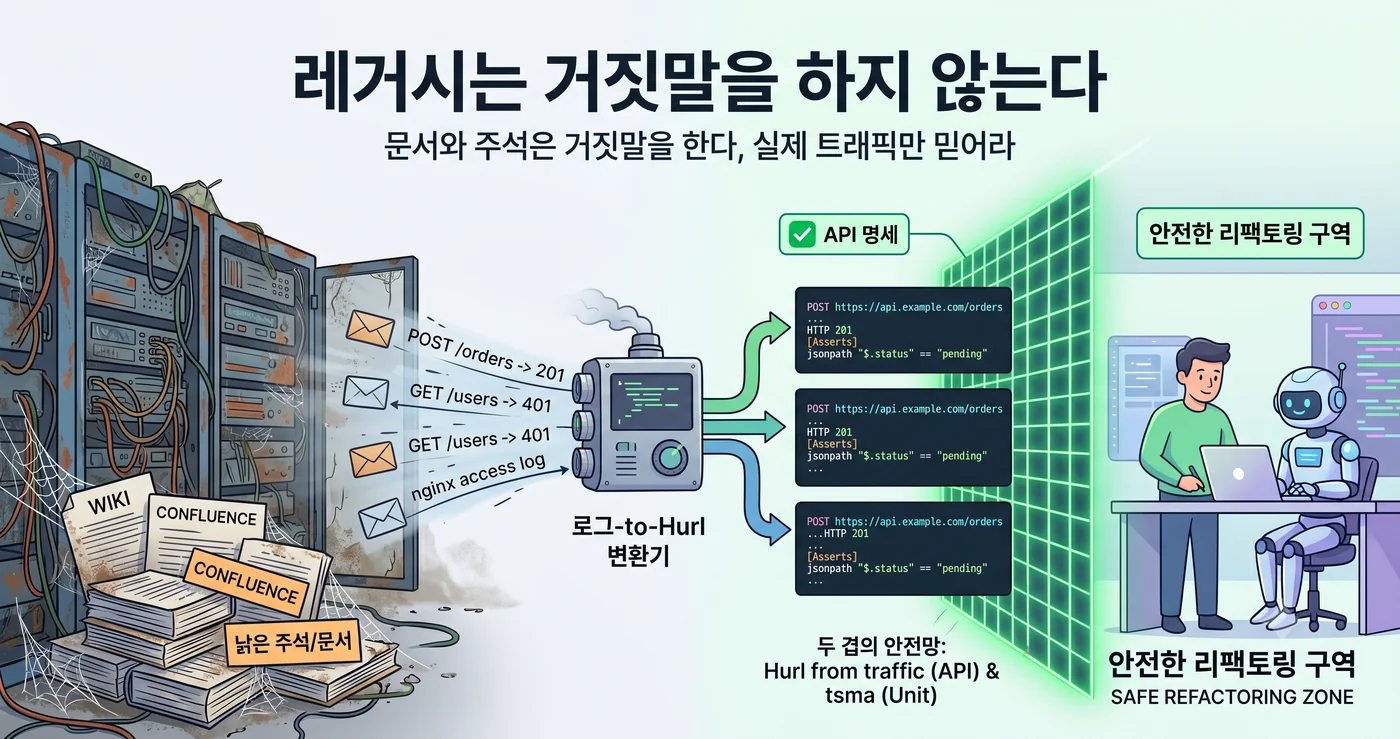
Wo also soll man die Spezifikation suchen? Nicht im Wiki. Nicht in Confluence. Im nginx access log.
Huhn und Ei
Um Legacy zu refactoren, braucht man ein Sicherheitsnetz. Wenn man etwas ändert, muss man sofort erkennen, ob sich das Verhalten verändert hat. Genau dieses Sicherheitsnetz ist der Test.
Aber Legacy hat keine Tests. Um einen Test zu schreiben, muss man wissen, was der Code tut. Um zu wissen, was der Code tut, muss man ihn lesen. Liest man ihn, findet man weder Tests noch Dokumentation.
Was war zuerst da, Huhn oder Ei? Eine klassische Pattsituation, die Michael Feathers in Working Effectively with Legacy Code benannt hat. Als Antwort schlug er den characterization test vor — einen Test, der nicht festhält, was der Code richtigerweise tun sollte, sondern was er aktuell tut, exakt so, wie es ist. Richtig oder falsch ist eine spätere Frage. Zuerst muss man das jetzige Verhalten fixieren, um überhaupt Hand anlegen zu können.
In Feathers’ Zeit schrieb man das von Hand. Man ruft die Funktion auf, schaut sich den herauskommenden Wert an und trägt ihn unverändert ins Expected ein. Langweilig, langsam — und deshalb hat es niemand bis zum Ende durchgezogen.
Auf API-Ebene aber liegt dieses “Ergebnis eines Funktionsaufrufs” längst irgendwo gestapelt. Täglich, zu Zehntausenden. In der Logdatei.
Ein Monat Logs ist die Spezifikation
Sammelt man einen Monat lang, lässt sich das aktuelle Verhalten der Legacy-API nahezu vollständig einfangen.
nginx access log (1 Monat):
Endpunkt · HTTP method · status code · timing
Aufruffrequenz → Priorität
Fehlermuster (401, 422, 500 …)
request/response body (per Middleware oder reverse proxy erfasst):
normale Request/Response-Paare → das Verhalten, das bestehen muss
Fehler-Request/Response-Paare → die Edge Cases, die nicht brechen dürfen
Verbindet man diese beiden Stränge, übersetzt sich das direkt in Hurl-Integrationstests. Hurl ist ein Format, das HTTP-Anfragen und erwartete Antworten unverändert im Klartext notiert. Ein Verkehrspaar — “auf diese Anfrage ging diese Antwort raus” — ist genau ein Hurl-Block.
# POST /api/orders — Aufruffrequenz #3, 12.000 Aufrufe pro Tag
POST https://api.example.com/orders
Content-Type: application/json
{ "sku": "A-1024", "qty": 2 }
HTTP 201
[Asserts]
jsonpath "$.order_id" exists
jsonpath "$.status" == "pending"
jsonpath "$.total" == 49800
Dieser Test weiß nicht, “wie die Order-API funktionieren sollte”. Er weiß nur, “sie funktioniert jetzt so”. Das genügt. In dem Moment, in dem das Refactoring diese Antwort verändert, springt die Ampel auf Rot.
Was sich automatisch aus den Logs ableitet:
- Welche Endpunkte tatsächlich genutzt werden → Ein Endpunkt, der einen Monat lang nullmal aufgerufen wurde, ist toter Code. Löschkandidat vor dem Refactoring.
- Muster normaler Antworten → grundlegende Regressionstests.
- Fehlermuster → die echten Edge Cases, die sich kein Mensch ausdenken kann. Es sind die 422er und 500er, die reale Nutzer erzeugt haben.
- Aufruffrequenz → die Test-Priorität. Man fixiert zuerst das, was 12.000-mal am Tag läuft.
Der letzte Punkt ist entscheidend. Wenn ein Mensch Tests schreibt, beginnt er mit dem Happy Path, an den er sich erinnert. Der Verkehr hat keine solche Verzerrung. Der Pfad, der tatsächlich Last trägt, ist die Priorität.
Ein Sicherheitsnetz aus zwei Schichten
Dieser Ansatz steht nicht für sich allein, sondern ist eine Schicht der Ratchet-Pipeline, die Legacy zu agent-operable hochzieht.
nginx log (1 Monat) → automatische Hurl-Generierung → aktuelles Verhalten der Legacy-API fixieren
↓
tsma → Sicherheitsnetz auf Funktionsebene (unit)
↓
filefunc → Code-Struktur aufräumen (ein Konzept, eine Datei)
↓
Refactoring → Hurl verifiziert die Erhaltung des API-Verhaltens (integration)
Der Kern ist, dass das Sicherheitsnetz zwei Schichten hat.
- tsma = Sicherheitsnetz auf Funktionsebene. Es erkennt, ob sich die innere Logik verändert hat. Doch selbst bei gleichbleibender Funktionssignatur kann sich das Verhalten des gesamten Endpunkts ändern.
- Hurl from traffic = Sicherheitsnetz auf API-Ebene. Es erkennt, ob der von außen sichtbare Vertrag erhalten bleibt. Wie auch immer man das Innere umwälzt — solange das, was von außen hinein- und nach außen hinausgeht, gleich bleibt, besteht es.
Refactoring ist per Definition “das Innere zu verändern, während das äußere Verhalten erhalten bleibt”. Dann muss die Definition dieses zu erhaltenden “äußeren Verhaltens” irgendwo fixiert sein. tsma fasst die innere Grenze, Hurl die äußere. Erst wenn beide Schichten zusammen vorhanden sind, kann man dem Agenten sagen: “Wälz alles um, wie du willst — wo etwas bricht, sieht die Maschine.”
Ein Schiedsrichter, der nicht schmeicheln kann
Das greift genau in das Wesen des Symbolic Feedback Loop ein.
Fragt man den Agenten “Hast du gut refactored?”, antwortet er “Ja, sauber aufgeräumt.” Gibt man ihm eine Meinung, schmeichelt er. Lässt man aber Hurl laufen, kommt heraus: POST /orders → expected 201, got 500. Zahlen und Statuscodes können nicht schmeicheln. Weil sie keine Gefühle haben.
Ein aus dem Verkehr gezogener Hurl-Test ist eine Spezifikation, in die kein menschliches Urteil eingeflossen ist. Es ist kein “jemand denkt, es sollte so funktionieren”, sondern “die Beobachtung ergab, dass es so funktioniert hat”. Keine Behauptung, sondern eine Messung. Deshalb kann über Richtig und Falsch des Refactorings nicht ein Mensch, sondern die Maschine entscheiden. Das LLM ist kein Richter, sondern ein Ausführender, und das Urteil fällt ein deterministisches Werkzeug.
Die einzige Voraussetzung: gut geführte Logs
Damit diese Methode funktioniert, braucht es genau eine Sache: einen Monat gut geführter Logs.
Hier liegt im “gut geführt” alles. Das access log allein reicht nicht. Es liefert Endpunkt, status code und timing, aber den Kern, der fixiert werden muss — das Paar aus request body und response body — liefert es nicht. Wer nur POST /orders → 201 kennt, kann nicht reproduzieren, dass “auf diese Eingabe diese Ausgabe herauskam”. Um eine Funktion zu fixieren, muss man sowohl das Hineingegangene als auch das Herausgekommene in der Hand halten.
Die wahre Frage lautet also nicht “Wie schreibe ich den Test?”, sondern “Sind meine Logs gut genug geschrieben, um zur Spezifikation zu werden?”.
- Bleiben request/response body erhalten, oder nur der status code?
- Bleiben auch die Fehlerantworten erhalten? Gerade die body von 422 und 500 sind die Edge Cases, die sich kein Mensch ausdenken kann.
- Sind die Logs strukturiert, sodass die Maschine Anfrage und Antwort als Paar zusammenführen kann?
Ist das gegeben, dann schreibst du seit einem Monat bereits an deiner Spezifikation. Du brauchst keinen separaten Test zu schreiben. Die Log-Pipeline hat ihn stellvertretend geschrieben. Ist es nicht gegeben, schiebst du jetzt eine Middleware-Schicht ein und lässt sie einen Monat laufen. Einen Monat später hältst du das gesamte aktuelle Verhalten des Legacy-Systems in der Hand.
Warum ein Monat und nicht ein Tag? Ein Tag fängt nur den Happy Path. Ein Monat fängt den Monatsabschluss-Batch, den Verkehrsstoß kurz vor der Abrechnung, die nur selten aufgerufenen Admin-Endpunkte, den Cron, der um 3 Uhr nachts einmal läuft — den langen Schwanz des Systems. Die Spezifikation ist kein Durchschnitt, sondern eine Verteilung.
Die Logs zu Hurl übersetzen und Funktionen fixieren
Sind die Logs vorhanden, ist der Rest mechanisch. Man gibt einen Monat request/response-Paare in das Werkzeug und übersetzt jedes Paar in einen Hurl-Block. Die so ausgeschütteten Hunderte von Hurl-Dateien sind die characterization-Suite — ein Sicherheitsnetz, das das aktuelle Verhalten des Legacy-Systems im Ganzen fixiert. Keine einzige Zeile Code wurde gelesen. Nur der verflossene Verkehr.
Einen Punkt, an dem man hier häufig stockt, sei vorab geklärt: “In den Logs stecken personenbezogene Daten, Zahlungen, Tokens — darf man das überhaupt in einem Test fixieren?”
Man darf. Genauer: Man muss es nicht fixieren. Denn diese Methodik braucht die Werte von vornherein nicht. Was der characterization test fixiert, ist nicht der Wert, sondern das Verhalten.
HTTP 201
[Asserts]
jsonpath "$.order_id" exists
jsonpath "$.total" == 49800
Als Spezifikation zählt hier nicht die Zahl 49800, sondern die Struktur, dass “das Feld total als Ganzzahl existiert und für eine gegebene Eingabe so berechnet wird”. Maskiert man die Werte oder ersetzt sie durch synthetische Daten, verringert sich der Wert der Spezifikation kaum. capture → Maskierung → Hurl-Generierung, diese gesamte Pipeline läuft innerhalb deiner eigenen Infrastruktur. Die raw Logs verlassen sie nirgendwohin. Übrig bleibt nur eine Spezifikation mit verdeckten Werten, ein Vertrag, der nur die Struktur erhält. Dass die Logs das Haus nicht verlassen müssen, ist kein sicherheitstechnisches Zugeständnis, sondern das Wesen dieses Ansatzes — weil von Anfang an nur das Verhalten fixiert werden muss.
Lässt man die erzeugten Hurl einmal gegen Staging laufen, entscheidet sich auf der Stelle Bestehen oder Scheitern. Sind alle grünen Lichter an, kann das Refactoring beginnen. Sag dem Agenten, er soll alles umwälzen, wie er will — wo etwas bricht, sieht Hurl.
Eine Leiter, die ohne Code angelegt wird
Der wahre Wert dieses Ansatzes ist also nicht “Tests schnell schreiben”. Der wahre Wert ist dieser:
- Es beginnt, ohne den Code zu lesen — der ursprüngliche Autor ist weg und es gibt keine Dokumentation, doch allein aus dem verflossenen Verkehr wird ein Sicherheitsnetz gespannt. Man erhält das Recht, Hand anzulegen, bevor man den Code versteht.
- Das Ergebnis ist sofort verifizierbar — lässt man die erzeugten Hurl gegen Staging laufen, kommt auf der Stelle pass/fail heraus. Nicht “wird schon klappen”, sondern “jetzt bestehen 327 von 327”.
- Die Daten klettern nicht über den Zaun — von capture bis Hurl-Generierung endet alles innerhalb meiner eigenen Infrastruktur. Gerade in regulierten Branchen ist es entscheidend, beginnen zu können, ohne irgendetwas nach außen zu geben.
Der erste Spatenstich der Legacy-Modernisierung bleibt meist an der Klippe stecken: “Niemand weiß, wie das aktuelle Verhalten aussieht.” Verkehr → Hurl legt eine Leiter an diese Klippe. Um die Leiter anzulegen, braucht es keinen Code. Der verflossene Verkehr genügt — und selbst dieser Verkehr bleibt unverändert hinter dem Zaun.
Der Fluss schrieb die Spezifikation längst
Wir mühen uns ab, die Spezifikation separat zu schreiben. Wir tippen OpenAPI von Hand, beschreiben das Verhalten im Wiki, und wenn beides vom Code abweicht, nennen wir es Drift und beklagen es.
Doch ein lebendes System schrieb in jedem Augenblick seine eigene Spezifikation. Jedes Mal, wenn eine Anfrage hereinkommt und eine Antwort hinausgeht, ist das eine Zeile Selbstbeschreibung: “Ich bin ein solches System.” Die Logdatei ist diese Autobiografie, einen Monat lang gestapelt.
Wir haben sie nur nicht gelesen.
Es ist nicht so, dass Legacy keine Dokumentation hätte. Die Dokumentation steckt im access log, nur ist ihr Format für Menschen unbequem zu lesen. Übersetzt man sie nach Hurl, wird sie zu einer ausführbaren Spezifikation, einem Vertrag, über den die Maschine urteilt.
Dokumentation lügt. Der Verkehr lügt nicht.
Verwandte Texte
- Hurl stoppt den Drift — Wie man HTTP-Verträge im Klartext deklariert und in CI einsperrt. Wenn dieser Text “Verkehr → Hurl” ist, dann ist jener “Drift mit Hurl einsperren”.
- tsma — die Regressions-Verteidigungslinie für Legacy-Code — Die innere Grenze (Funktionsebene) des zweischichtigen Sicherheitsnetzes. Ist Hurl die äußere Grenze, so ist tsma die innere.
- Agent Operable Codebase — Die dreistufige Pipeline, die Legacy zu Code hochzieht, an dem ein Agent arbeiten kann.
- Warum Coding-Agenten funktionieren und warum sie zusammenbrechen — Die Struktur des Symbolic Feedback Loop.
- Constraints sind Verträge — Der Test als verifizierbarer und erzwingbarer Vertrag.
- Wie man gescheitertes Vibe-Coding rettet — Eine Praxisvorlesung, die Legacy mit characterization testing diagnostiziert → einsperrt → repariert → extrahiert → umstellt.
Weiterführende Lektüre
- Michael Feathers, “Characterization Testing” — Der Text des Begriffsschöpfers. “In dem Moment, in dem Software in Produktion geht, wird sie zu ihrer eigenen Spezifikation (it becomes its own specification).” Nahezu dieselbe These wie der Titel dieses Textes.
- Hurl Offizielles Tutorial, “Your First Hurl File” — Von
GET / HTTP 200bis zum--test-Modus. Ein Einstieg, der einem direkt in die Hand gibt, dass eine Klartextzeile bereits ein Test ist. - GitHub Engineering, “Scientist: Measure Twice, Cut Once” — Eine Bibliothek, die Legacy- (control) und neuen (candidate) Code in Produktion gleichzeitig ausführt und die Ergebnisse vergleicht. “Nur das reale Verhalten ist die echte Spezifikation.”
- Twitter Diffy (InfoQ-Zusammenfassung) — Ein Proxy, der dieselbe Anfrage an alten/neuen Service schickt und nur die Antwortunterschiede als Regression fängt. Ein klassischer Vorläufer von “Verhalten fixieren, ohne Tests zu schreiben”.
- GoReplay — Ein Werkzeug, das live HTTP-Verkehr von der Netzwerkschnittstelle erfasst und nach Staging wiedergibt. Die paradigmatische Umsetzung von “Produktionsverkehr als Testeingabe”.
- Nicolas Carlo, “Characterization vs Approval Tests” — Ordnet drei Begriffe für faktisch dieselbe Technik und betont die Rolle des “Printer”, der sensible Informationen aus der Ausgabe scrubbt.
- Pact — consumer-driven contract testing. Der “explizite Vertrag”-Ansatz im Kontrast zur Verkehrsfixierung. Beide Methoden zusammen betrachtet ergeben ein ausgewogenes Bild.
Quellen / Belege
Kernkonzepte und Werkzeuge
- Michael Feathers. Working Effectively with Legacy Code. Prentice Hall, 2004. — Ursprung des Konzepts characterization test. “Festhalten, was der Code aktuell tut, nicht was er richtigerweise tun sollte.”
- Hurl-Projekt (hurl.dev) — Klartext-Format für HTTP-Request/Response-Tests. Als eine der 10 SSOTs von yongol integriert.
- tsma — empirischer Nachweis an 527 Funktionen — Ratchet auf Funktionsebene (tsma).
Tests aus Verkehr und Ausführung gewinnen (carving / record-replay)
- Elbaum, Chin, Dwyer, Jorde (2009). “Carving and Replaying Differential Unit Test Cases from System Test Cases.” IEEE TSE 35(1). — Die akademische Grundlage des differential unit test, der eine Systemausführung aufzeichnet (record) und auf Unit-Ebene wiedergibt (replay).
- Meta Engineering Team (2024). “Observation-based Unit Test Generation at Meta.” FSE 2024, arXiv:2402.06111. — Tests aus beobachteten Werten der App-Ausführung carving. 9,6 Millionen Läufe in CI, 5.702 erkannte Defekte. Industrieller Nachweis von “Beobachtung ist Test”.
Aktuelles Verhalten fixieren (snapshot / golden master)
- Fujita, Kashiwa, Lin, Iida (2023). “An Empirical Study on the Use of Snapshot Testing.” ICSME 2023. — Empirischer Nachweis der Adoption von snapshot- (= golden master/characterization) Tests. “Nicht Korrektheit, sondern die aktuelle Ausgabe fixieren, um Änderungen zu erkennen.”
Sicherheitsnetz fürs Refactoring
- Kim, Zimmermann, Nagappan (2014). “An Empirical Study of Refactoring Challenges and Benefits at Microsoft.” IEEE TSE 40(7). — Empirischer Nachweis, dass Refactoring ohne Tests, die die Verhaltenserhaltung garantieren, Kosten und Risiko zugleich ist.
- Yoo, Harman (2012). “Regression Testing Minimization, Selection and Prioritization: A Survey.” STVR 22(2). — Regressionstest = die Standarddefinition der “Gewissheit, dass eine Änderung bestehendes Verhalten nicht beschädigt”.
Die reale Nutzungsverteilung ist die Priorität
- John D. Musa (1993). “Operational Profiles in Software-Reliability Engineering.” IEEE Software 10(2). — Verteilt man Tests nach Nutzungsfrequenz, wird selbst bei terminbedingtem Abbruch die meistgenutzte Funktion am häufigsten verifiziert. Klassische Grundlage von “Verkehrsverteilung statt Happy-Path-Verzerrung”.
Warum die Maschine urteilen muss (das LLM ist kein Richter, sondern ein Ausführender)
Huang, Chen, Mishra, et al. (2024). “Large Language Models Cannot Self-Correct Reasoning Yet.” ICLR 2024, arXiv:2310.01798. — Ohne externes Feedback kann das LLM sein eigenes Schlussfolgern nicht korrigieren. Der Grund, warum ein deterministischer externer Verifizierer nötig ist.
Sharma, Tong, et al. (2024). “Towards Understanding Sycophancy in Language Models.” ICLR 2024, arXiv:2310.13548. — RLHF lehrt Konformität und untergräbt damit die Zuverlässigkeit der LLM-Selbstbeurteilung.
Titelbild: KI-generiert (Google Gemini)