 Image: AI generated
Image: AI generated
الأذكياء ليسوا بالضرورة أفضل من يشرح
عندما تطلب من Opus 4.8 إعادة هيكلة الكود، تخرج بنتائج مبهرة. يفكّ رسوم بيانية معقدة للتبعيات دفعة واحدة، ويعالج الحالات الحدّية بشكل استباقي، ويكتب اختبارات محكمة بلا ثغرات. لكن المشكلة تبدأ عندما تطلب منه شرح تلك النتائج. يتحدث كأن خبيراً يُقدّم تقريراً لخبير آخر. يفترض أنك تشاركه نفس الخلفية المعرفية، ويحذف أسباب قراراته الجوهرية، ويستخدم مستوى تجريد مرتفع بلا ضرورة.
عندما تسأل Opus 4.6 نفس السؤال، تحصل على العكس تماماً. يُقدّر جيداً ما قد لا تعرفه. يختار التشبيهات بعناية، ويقسّم الخطوات، ويمهّد السياق أولاً. لكن عندما ترتفع صعوبة الاستدلال، يتعثر في مسائل يحلّها 4.8 من المحاولة الأولى.
يمكن تلخيص ذلك في جملة واحدة: Opus 4.8 ذكي لكنه يتحدث بصعوبة، وOpus 4.6 يشرح ببساطة لكن أداء استدلاله أضعف.
هذا ليس خللاً. لماذا يحدث هذا، وكيف نحوّل هذا الفارق إلى ميزة هيكلية — هذا هو موضوع هذا المقال.
لعنة المعرفة تنطبق على LLM أيضاً
في عام 1989، أثبت علماء النفس Camerer وLoewenstein وWeber تجريبياً أن الشخص الذي يمتلك معلومات أكثر يعجز عن تقدير أن الطرف الآخر لا يعرف تلك المعلومات. هذه الظاهرة المسماة “لعنة المعرفة (Curse of Knowledge)” هي انحياز معرفي تم تأكيده مراراً في التعليم والاقتصاد وتصميم تجربة المستخدم.
قال أوليفر ويندل هولمز: “لن أدفع فلساً واحداً مقابل البساطة التي تسبق التعقيد. لكنني سأبذل حياتي في سبيل البساطة التي تأتي بعد التعقيد.” الشرح البسيط ليس بسيطاً لأن صاحبه جاهل، بل لأنه اخترق التعقيد ووصل إلى الجانب الآخر. لكن المفارقة أنك بينما تكون غارقاً في التعقيد، تضعف قدرتك على التبسيط.
أظهرت ورقة بحثية في EMNLP 2025 أن هذه الظاهرة تظهر أيضاً في نماذج الاستدلال الكبيرة. نتيجة مفارِقة: كلما كان النموذج أقوى في الاستدلال، كان أكثر عرضة للعنة المعرفة. النماذج التي تستدل بعمق تفترض ضمنياً أن المحاور يستطيع متابعة مسار استدلالها. إنها نفس المشكلة التي يواجهها الخبير البشري عند الشرح للمبتدئ.
لهذا يوجد في العالم نوعان من الأدوار: من يفكر بعمق ومن ينقل المعرفة ببساطة. الباحث ومبسّط العلوم. كبير المطورين وقائد الفريق التقني. القاضي والمحامي. هاتان قدرتان مختلفتان. من الرائع أن يتقنهما شخص واحد، لكن هذا نادر في الواقع. لذلك تفصل المؤسسات الأدوار.
الأمر نفسه ينطبق على LLM. وClaude Code يجعل هذا الفصل ممكناً بسطر إعداد واحد.
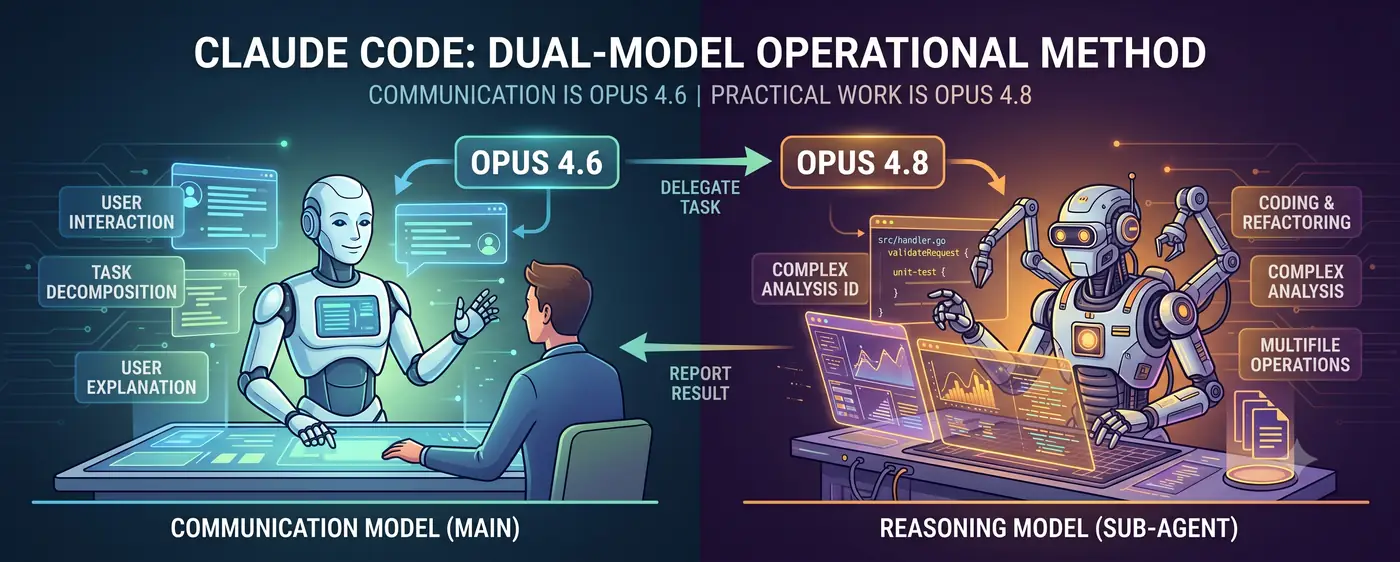
نموذج التواصل + نموذج الاستدلال
الهيكل الأساسي بسيط.
المستخدم ↔ نموذج التواصل (الرئيسي) ↔ نموذج الاستدلال (الوكيل الفرعي)
- نموذج التواصل (Opus 4.6) يقف في واجهة الحوار. يفهم نية المستخدم، ويفكك المهام، ويقدم النتائج بلغة يفهمها الإنسان.
- نموذج الاستدلال (Opus 4.8) يتولى العمل الفعلي. يُفوَّض إليه كتابة الكود والتحليل المعقد وإعادة الهيكلة متعددة الملفات وغيرها من مهام الاستدلال عالية الصعوبة كـ subagent.
يتحدث المستخدم مع 4.6. عندما يحكم 4.6 أن “صعوبة الاستدلال أعلى مما يمكنني التعامل معه مباشرة”، ينشئ subagent من 4.8 ويفوّض إليه المهمة. عندما يعيد 4.8 النتيجة، يفسّرها 4.6 ويشرحها للمستخدم.
هذا المقال نفسه دليل على ذلك. ما يكتب هذا المقال الآن هو Opus 4.6 (الرئيسي)، أما البحث في الأوراق الأكاديمية وتحليل بيانات المقاييس المرجعية التي يستند إليها هذا المقال فقد أنجزها Opus 4.8 (الـ subagent).
ما تقوله المقاييس المرجعية
تكشف بيانات BenchLM عن شخصية النموذجين بالأرقام.
| المجال | Opus 4.6 | Opus 4.8 | التفوق |
|---|---|---|---|
| الشامل | 86 | 93 | 4.8 |
| البرمجة | 64.4 | 76.4 | 4.8 |
| مهام Agent | 72.6 | 80.1 | 4.8 |
| مهام المعرفة | 76.2 | 70.1 | 4.6 |
| الكتابة الإبداعية | تفوق | - | 4.6 |
يتفوق 4.8 بفارق كبير في البرمجة ومهام Agent. لكن في نقل المعرفة والكتابة الإبداعية يتقدم 4.6. في مراجعات Claude API أيضاً، يتكرر تقييم أن كتابة 4.8 “أكثر طابعاً آلياً (more AI-sounding)” مقارنة بـ 4.6. يستدل 4.8 بدقة، لكن قدرة تقديم ذلك الاستدلال بأسلوب سهل القراءة للإنسان أفضل عند 4.6.
سعر النموذجين متطابق — 5 دولارات لكل مليون token مدخل، و25 دولاراً لكل مليون token مخرج. تقسيم الأدوار لا يزيد التكلفة. هذا ليس تحسيناً للتكلفة، بل تحسين خالص للجودة.
توجيه النماذج هندسة مُثبتة بالفعل
فكرة “استخدام نموذجين بشكل منفصل” ليست جديدة. إنها مجال راسخ أكاديمياً.
RouteLLM (ICLR 2025) وجّه الاستعلامات ديناميكياً بين نموذج قوي ونموذج ضعيف، فخفّض التكلفة إلى أقل من النصف مع الحفاظ على الجودة. FrugalGPT (2023) حقق أداء بمستوى GPT-4 مع توفير 98% من التكلفة عبر تسلسل LLM. الاستنتاج المشترك لهذه الأبحاث واضح: نموذج أضعف بتنسيق ممتاز يتفوق غالباً على نموذج أقوى بتنسيق ضعيف.
Anthropic نفسها تستخدم هذا النمط. تطبيق deep-research من Anthropic مبني على نمط المُنسّق-العامل (orchestrator-worker)، وتكوين multi-agent تفوّق على Opus 4 أحادي الوكيل بنسبة 90.2%. وتشير دراسات إلى أن نحو 80% من أنظمة multi-agent في الإنتاج تستخدم بنية المُنسّق-العامل.
ما أفعله هو أبسط أشكال هذا النمط. لا موجّه، ولا تسلسل، ولا تحسين تكلفة. فقط نموذج مُحسَّن للتواصل يقف في الواجهة، ونموذج مُحسَّن للاستدلال يعمل في الخلفية. مبدأ فصل الأدوار بحد ذاته.
كيفية الإعداد
إنشاء هذا الهيكل في Claude Code أمر بسيط.
الخطوة 1: إعداد النموذج الرئيسي
شغّل Claude Code بـ Opus 4.6. حدد النموذج الافتراضي كـ claude-opus-4-6-20250610 في الإعدادات، أو اختر النموذج عند التشغيل. هذا يصبح نموذج التواصل الذي يتحدث مع المستخدم.
الخطوة 2: تجاوز النموذج في الـ subagent
أداة Agent في Claude Code تدعم معامل model. عند إنشاء subagent، تجاوز النموذج إلى opus (Opus 4.8).
Agent({
description: "إعادة هيكلة الكود",
model: "opus",
prompt: "دالة validateRequest في src/handler.go..."
})
هذا كل شيء. الوكيل الرئيسي (4.6) يتحدث مع المستخدم، والمهام عالية الصعوبة تُفوَّض إلى الـ subagent (4.8).
الخطوة 3: التمييز بين fork و fresh agent
هناك نوعان من الـ subagent في Claude Code.
- fork (
subagent_type: "fork"): يرث سياق المحادثة الحالية كما هو. يشارك ذاكرة التخزين المؤقت للمطالبات مما يوفر حتى 90% من تكلفة المدخلات. لكن fork يرث نموذج الأصل إجبارياً، لذا لا يُطبَّق تجاوز النموذج. - fresh agent: يبدأ في سياق جديد. يمكن تجاوز النموذج. يجب تضمين الخلفية اللازمة في المطالبة مباشرة.
لذلك، لاستخدام نموذج الاستدلال (4.8) يجب إنشاء fresh agent. يُستخدم fork عند الحاجة لاستكشاف متوازٍ مع الحفاظ على نموذج التواصل (4.6).
أنماط عملية
| الحالة | الطريقة | السبب |
|---|---|---|
| كتابة كود معقد | fresh agent + model: opus | صعوبة استدلال عالية |
| إعادة هيكلة متعددة الملفات | fresh agent + model: opus + isolation: worktree | استدلال + عزل مطلوب |
| بحث/استكشاف متوازٍ | fork (يبقى 4.6) | مشاركة السياق أكثر فائدة |
| قراءة/تحرير ملف بسيط | الرئيسي (4.6) مباشرة | تكلفة التفويض أعلى |
| بحث على الويب/أبحاث | fresh agent + model: opus | دقة الاستدلال مطلوبة |
يعمل النظام بثبات حتى 4-8 worktree متزامنة. أكثر من ذلك تصبح مراجعة النتائج عنق الزجاجة.
نقاط الاحتكاك المعروفة
النظام ليس مثالياً. هناك قيدان معروفان حالياً.
أولاً، مشكلة تسرب تجاوز النموذج. قد ينتشر إعداد model الخاص بالـ subagent إلى الوكلاء الفرعيين الذين ينشئهم ذلك الـ subagent. قد يحدث استخدام غير مقصود للنموذج، لذا من العملي تقييد عمق الـ subagent بمستوى واحد.
ثانياً، غياب إعداد النموذج لكل وكيل. حالياً لا يدعم Claude Code رسمياً تحديد النموذج مسبقاً لكل نوع وكيل في إعدادات المشروع. يجب تحديد معامل model عند كل استدعاء Agent. المجتمع نشط في طلب هذه الميزة.
كلا القيدين سيزولان مع تطور Claude Code. حتى في الوضع الحالي، يمكن الاستمتاع بمزايا الهيكل بالتجاوز اليدوي وحده.
المُتواصل والمُفكر دوران مختلفان
في المحكمة، يتعامل القاضي والمحامي مع نفس القانون لكن بأدوار مختلفة. القاضي يحكم. المحامي يشرح للموكل ما يعنيه ذلك الحكم. لو قرأ القاضي نص الحكم للموكل مباشرة، لما فهمه الموكل. ولو أصدر المحامي الحكم مباشرة، لكانت الحجج واهية. فصل الأدوار ليس نقطة ضعف في النظام، بل نقطة قوة.
الأمر نفسه في مراجعة الكود. قدرة المطور الأقدم على اكتشاف الخطأ شيء، وقدرته على إفهام المطور المبتدئ ذلك الخطأ شيء آخر. نادراً ما يكون المهندس البارع كاتباً تقنياً بارعاً أيضاً. المؤسسات تعرف هذا، لذلك تفصل الأدوار.
الأمر نفسه مع الذكاء الاصطناعي. قدرة الاستدلال وقدرة التواصل محوران مختلفان. وفي عملية تدريب النماذج الحالية، يميل هذان المحوران إلى التعارض. تعظيم أداء الاستدلال يجعل المخرجات مضغوطة ومتخصصة، وتعظيم أداء التواصل يُضحّل عمق الاستدلال.
مطالبة نموذج واحد بإتقان الأمرين كمطالبة القاضي بأن يكون محامياً أيضاً. ممكن. لكنه ليس الأمثل في كلا الدورين.
فصل نموذج التواصل عن نموذج الاستدلال مبدأ هيكلي يبقى صالحاً حتى مع تغيّر الإصدارات. 4.6 و4.8 مجرد اختيار اليوم الملموس. لو صدر 5.0 و5.2 غداً، نعيد التوزيع بنفس المبدأ. النماذج تتبدّل، لكن حقيقة أن “دور التفكير العميق” و"دور الشرح البسيط" مختلفان — هذه لا تتبدّل.
مقالات ذات صلة
- Ratchet Pattern — كيف تجعل الوكيل يصل إلى النهاية
- لماذا تتباعد حلقة الوكيل الخاصة بك
- لماذا لا يموت الانحراف أبداً
للمزيد من القراءة (مصادر خارجية)
- RouteLLM: Learning to Route LLMs with Preference Data — إطار عمل للتوجيه الديناميكي بين نموذج قوي ونموذج ضعيف حسب صعوبة الاستعلام.
- Anthropic: How we built our multi-agent research system — كيف بنت Anthropic نظام deep-research باستخدام نمط المُنسّق-العامل.
المراجع
- Camerer, C., Loewenstein, G. & Weber, M. (1989). The Curse of Knowledge in Economic Settings: An Experimental Analysis. Journal of Political Economy, 97(5), 1232-1254. DOI — الإثبات التجريبي للعنة المعرفة.
- Li, W. et al. (2025). Curse of Knowledge: Your Guidance and Provided Knowledge are biasing LLM Judges in Complex Evaluation. Findings of EMNLP 2025. arXiv — اكتشاف أن نماذج الاستدلال الأقوى أكثر عرضة للعنة المعرفة.
- Ong, I. et al. (2025). RouteLLM: Learning to Route LLMs with Preference Data. ICLR 2025. arXiv — إطار عمل لتعلم توجيه LLM باستخدام بيانات التفضيل.