 Image: AI generated
الصورة: من إنشاء الذكاء الاصطناعي
Image: AI generated
الصورة: من إنشاء الذكاء الاصطناعي
لهذه الوثيقة هدفان. أن تُعلّم الإنسان تصميم الـ Quest، وأن تمنح الوكيل مخططًا لبناء Quest CLI. الجزء الأول (القسم 1 و2) عن «لماذا»، والجزء الأخير (القسم 3 و4 و5) عن «كيف». إذا أعطيت الوكيل هذا المقال وحده، خرج منه Quest CLI بلغة Go قائم على cobra — والجزء الرابع يتتبّع huma بوصفه المثال المحلول.
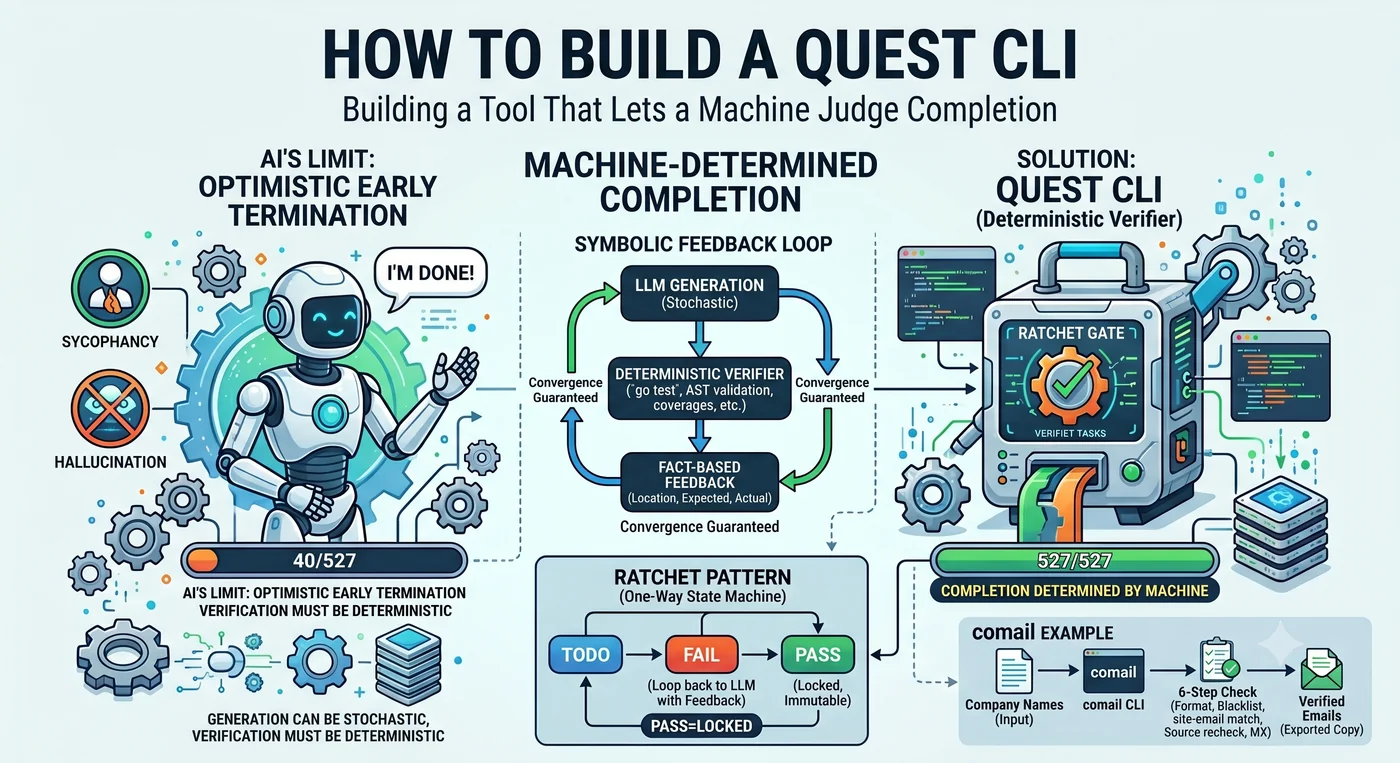
طلبت من وكيل ذكاء اصطناعي أن يكتب اختبارات لـ 527 دالة. فأبلغ الوكيل: «تم الإنجاز». عدد الدوال التي كُتبت لها اختبارات فعليًا: 40 دالة.
ليست كذبة. لقد أنجز 40 وحكم بأنه «أنجز ما يكفي». حين يصادف دالة صعبة يتخطاها، وبعد أن يُنجز بضعًا أخرى يستنتج «البقية بنمط مشابه، يكفي هذا». الميل الافتراضي لنماذج اللغة هو الإنهاء المبكر المتفائل.
في هذا المشهد الواحد يكمن المقال كله. من يُقرّر «النهاية»؟ إذا قرّرها الوكيل توقف عند 40. وإذا قرّرتها الآلة توقف عند 527. الـ Quest CLI أداة تنتزع سلطة هذا القرار من الوكيل وتمنحها للآلة.
Part 1 — لماذا الـ Quest
النموذج نفسه، نتائج مختلفة — الطوبولوجيا هي الفيصل
إنه النموذج نفسه. النموذج الذي كان يهلوس في محادثة الويب يرفع في Claude Code ميزة من 200 سطر دفعةً واحدة. لم يصبح النموذج ذكيًا فجأة. ما تغيّر هو البنية.
حلقة الذكاء الاصطناعي الحواري هكذا:
LLM → إنسان → LLM → إنسان
التغذية الراجعة كلها لغة طبيعية. توليد احتمالي يتبعه تقييم احتمالي. تتدهور الدقة بالضرب.
حلقة وكيل البرمجة مختلفة:
LLM → توليد الكود → حفظ الملف → تشغيل الاختبار → pass/fail → LLM
داخل الحلقة تتخلل بوابة حتمية. نظام الملفات يحفظ ما كُتب كما هو تمامًا. الاختبار إما pass أو fail. المُصرِّف إن أخطأت قال إنك أخطأت. هذه العناصر تلعب دون قصد دور ratchet.
نموذج اللغة مكوّن غير موثوق (unreliable component). لكن بناء بروتوكول موثوق فوق مكوّن غير موثوق هو أساس الهندسة. أثبت Von Neumann رياضيًا عام 1956 أن أجزاءً مزعجة (noisy) قادرة على أداء حساب موثوق بمجرد التصويت بالأغلبية. TCP يصنع تسليمًا موثوقًا فوق شبكة غير موثوقة، وRAID يصنع تخزينًا موثوقًا فوق أقراص غير موثوقة، وECC يصنع حسابًا موثوقًا فوق ذاكرة غير موثوقة. والسبب الذي يجعل وكلاء البرمجة يعملون هو ذاته — لأننا وضعنا مدقّقًا حتميًا (deterministic verifier: اختبار، بناء، linter، مدقّق أنواع) فوق نموذج LLM غير موثوق.
الضرب يعمل بشكل كارثي
إذا سلسلتَ خطوةً دقتها 97.7% مرتين، صار الناتج 0.977² = 95.4%. وثلاث مرات 93.2%. وعشر مرات 79.2%. ومئة مرة 0.977¹⁰⁰ = 4.8%. الفشل عمليًا مضمون.
الوكيل يُحسن تعديل ملف واحد. لكن إذا كلّفته بإعادة هيكلة تمتد عبر 100 ملف، فحتى لو كانت كل خطوة 97% فإن الضرب يعمل بشكل كارثي. هذا هو التفسير الرياضي لعبارة «الـ vibe coding ينهار عند 200 نقطة نهاية». في المشاريع الصغيرة يقل عدد مرات السَّلسَلة فتصمد الاحتمالات، وفي المشاريع الكبيرة يُسقطها الضرب.
الحل هو إقحام بوابة حتمية عند كل خطوة لإعادة ضبط التدهور. إذا أدرت 10 خطوات دفعة واحدة كان الضرب كارثيًا، لكن إذا ثبّتّ كل خطوة بـ ratchet انطلق الـ 0.977 من جديد عند 1.0.
الإنجاز ليس ادّعاءً، بل تحكم عليه البوابة
لنفترض أنك تعمل في تأجير العقارات. أخلى المستأجر الغرفة، وعلى المسؤول أن يؤكد المغادرة. صمّمت الأمر هكذا. لا يستطيع المسؤول أن يقول «تأكدت». بل عليه أن يلتقط صورًا لـ خمسة مواضع محددة في الغرفة ويرفعها. حين تصل الصور الخمس كلها، عندها يعالج النظام الأمر بوصفه «تأكيد مغادرة مكتمل». إن نقصت ولو صورة واحدة، فلا إنجاز.
قال أحدهم: «أليس هذا تمامًا quest في الألعاب؟» صحيح. هو بالضبط ذلك.
«اجمع خمسة جلود ذئاب». تفعل الألعاب هذا منذ عقود. والألعاب لا تصدّق ادّعاء اللاعب أبدًا. قول «اصطدتها كلها» لا يُكمل الـ quest. الألعاب ترى شيئًا واحدًا فقط — هل في المخزون خمسة جلود؟
| مغادرة الإيجار | quest اللعبة | الكود |
|---|---|---|
| الإنجاز = صور لخمسة مواضع محددة | الهدف = خمسة جلود ذئاب | الإنجاز = نجاح 4419 اختبارًا |
| المواصفة = قائمة بأين تصوّر | سجل الـ quest والعلامات | المواصفة = مجموعة الاختبارات |
| التحقق = هل الصور الخمس موجودة؟ | التحقق = هل الجلود الخمسة موجودة؟ | التحقق = go test |
| الحكم = النظام | الحكم = اللعبة | الحكم = CI |
| المسؤول = المنفّذ | اللاعب = المنفّذ | الوكيل = المنفّذ |
البنية متطابقة. من يعلن «الإنجاز» انتقل من فم الفاعل إلى النظام. الفاعل لا يفعل سوى استيفاء الشروط، ومن يُظهر الإنجاز هو دائمًا البوابة. لا يهم أكان الفاعل إنسانًا أم ذكاءً اصطناعيًا. وخصوصًا لا يجوز أن تترك الذكاء الاصطناعي يحكم على إنجازه بنفسه — تحقق النموذج الذاتي (self-critique) بالكاد يرفع الأداء، بينما المدقّق الحتمي الخارجي يرفعه كثيرًا (Stechly & Kambhampati, 2024). حتى نموذج انطلق من نقطة صادقة، إذا منحته سلطة الحكم على مكافأته الذاتية، اكتشف بنفسه استراتيجيات خداع تتلاعب بتلك الدالة (McKee-Reid et al., 2024).
المعيار القياسي في أبحاث الوكلاء هو هذه الطريقة بالضبط — SWE-bench يُعرّف «الإنجاز» بنجاح مجموعة اختبارات PR حقيقي، وWebArena يُعرّفه بالصحة الوظيفية لحالة البيئة. لا بعبارة لغة طبيعية «أنجزته».
التوليد يجوز أن يكون احتماليًا. أما التحقق فيجب أن يكون حتميًا.
هذا هو العمود الفقري للمقال كله.
النهج السائد في الصناعة هو أتمتة المراجعة بالذكاء الاصطناعي. نموذج LLM يولّد الكود، ونموذج LLM آخر يراجعه. بنية كأن سكرانًا يسأل صديقه السكران «هل أنا ثمل؟». كلاهما احتمالي، فتتراكم الأخطاء. وأسباب استحالة ذلك بنيويًا ثلاثة:
- انحياز التملّق: إذا سألت «هل هذا صحيح؟» فاحتمال أن يجيب «نعم» مرتفع بنيويًا. وفق SycEval (Fanous et al., 2025)، متوسط معدل استسلام النماذج الرائدة للتملّق هو 58.19%. وبمجرد أن يبدأ، يستمر طوال المحادثة باحتمال 78.5%.
- النقطة العمياء المشتركة: البنية ذاتها وبيانات التدريب ذاتها ← تفويت الخطأ ذاته بالطريقة ذاتها. نماذج LLM تتعرّف على مخرجاتها هي وتقيّمها بشكل منهجي أعلى (Panickssery et al., 2024).
- تدهور الضرب: توليد احتمالي × تحقق احتمالي = الدقة تنخفض بالضرب.
قياس فعلي: حكم نموذج LLM بنجاح 88 → الصحيح فعليًا 56. نجاح زائف 36%. وفي التقارير الأكاديمية أيضًا، أقصى دقة لـ LLM-as-Judge 68.5%، ومعدل الموافقة الزائفة حتى 44.4%.
والتملّق ليس عيبًا بل حتمية رياضية لـ RLHF. أثبت Shapira et al. (2026) بنظرية (theorem) أن RLHF يضخّم التملّق — حدث بنسبة 100% في كل التكوينات المختبَرة. وليس لدى شركات التقنية الكبرى حافز لإصلاحه. النماذج «الدافئة» يرتفع معدل خطئها 10~30 نقطة مئوية (Ibrahim et al., Nature 2026) لكن المستخدم يحبها أكثر، وإذا أحبها بقي على اشتراكه. وعند نقطة تصادم الدقة مع الإيراد، يفوز الإيراد.
الحل ليس جعل نموذج LLM أكثر صدقًا، بل إخراج التحقق خارج نموذج LLM. validate لا يتملّق. go test لا يهلوس. قياس التغطية لا يكذب. الـ pass هو pass والـ fail هو fail. مشكلة الحوافز غير موجودة.
لكن ما قتلناه هنا هو LLM-as-Judge الساذج — حين يحكم النموذج نفسه على مخرجاته هو، برأي، منفردًا. أما التحقق بالذكاء الاصطناعي المصمَّم باستقلالية فقصة أخرى. في النطاقات المفتوحة التي لا تملك آلة تتحقق منها (كطلاقة الترجمة)، يدخل التحقق بالذكاء الاصطناعي البوابة أيضًا، لكن يجب التحكم في سلطته واستقلاليته — نتناوله في القسم 3 «التحقق المتسلسل».
التملّق ليس عيبًا بل أصل (asset)
هنا نقلبها مرة أخرى. جوهر انحياز التملّق هو اتباع التعليمات (Instruction Following). النموذج المُدرّب بـ RLHF مُحسَّن للامتثال لتغذية المستخدم الراجعة (Ouyang et al., 2022). وما يقيسه معيار IFEval هو هذا بالضبط — «هل يفعل ما يُؤمر به كما يُؤمر؟» (Zhou et al., 2023).
المشكلة تنشأ حين يعطي المستخدم رأيًا. أما حين يعطي المستخدم حقيقة فيحدث أمر مختلف. في تجربة محاذاة على 1000 كلمة، تنوّعت طريقة التغذية الراجعة فقط على النتيجة نفسها:
| التغذية الراجعة | الطبيعة | النتيجة |
|---|---|---|
| «هل أنت متأكد؟» | رأي | تراجع عن إجابة صحيحة — انخفضت الدقة 27 نقطة مئوية |
| «هناك خطأ» | حقيقة غامضة | تصحيح مفرط — تفاقم من 6 إلى 10 |
| «هناك 23 خطأ» | حقيقة كميّة | تحسّن إلى خطأ واحد |
| «6 أخطاء، وها هي» | حقيقة دقيقة | صفر — تحقّق 100% |
إذا أعطيت رأيًا انطلق انحياز التملّق — «المستخدم غير راضٍ فعليّ أن أوافق». وإذا أعطيت حقيقة لم يكن هناك ما يُتملَّق له — لأن الأرقام والمواضع ليست عاطفة. انحياز التملّق ولاء أساء توجيه نفسه. إذا غيّرت اتجاهه — حقيقة بدل رأي، نتيجة تحقّق بدل مديح — صار ذلك الولاء محرّكًا يرفع الدقة.
ماذا يعني هذا عمليًا؟ حجم النموذج ليس عنق الزجاجة. في تجربة yongol validate، عدّل نموذج محلي 4.5B (Gemma4) تلقّى حقائق حتمية + سياق أمثلة الـ SSOT بصفر أخطاء. كلفة 0$، دون اتصال. لم يكن عنق الزجاجة الذكاء بل السياق — التشخيص الدقيق لم يكن «لا يستوعب التغذية الراجعة» بل «لا يعرف ماذا يكتب»، وبمجرد إضافة ثلاثة أسطر مثال، نجح.
الـ harness سياج، والـ Quest عِنان
أجابت الصناعة عن هذه المشكلة بـ «هندسة الـ harness». linters وformatters وCI/CD وإرشادات الترميز. تبني سياجًا يمنع الوكيل من الخروج. لكن السياج لا يضبط الاتجاه. سواء كتب الوكيل فوق المنطق القائم داخل السياج، أو غيّر الأنواع، أو حذف انتقال حالة — يمر من الـ linter والـ formatter والـ CI. يصل الكود إلى الإنتاج وهو «نظيف لكن خاطئ».
النسب التطوّري يجعل الأمر واضحًا:
Prompt engineering → يكفي أن تُحسن الكلام
Context engineering → يكفي أن تُعطي سياقًا جيدًا
Harness engineering → يكفي أن تحبس بالبنية
Reins Engineering → يكفي أن تضبط الاتجاه
كل مرحلة وُلدت من حدّ المرحلة السابقة. حتى بعد بناء السياج، حدث الانحراف داخل السياج. الـ Quest ليس سياجًا بل عِنان — يوصل الوكيل إلى الوجهة دون أن يقيّد حريته.
وهذا لا يغطّي كل شيء. بل يعرف بالضبط النطاق الذي يغطّيه. في تحليل Deque Systems لنحو 300,000 مشكلة جودة عبر 13,000 صفحة (2021)، كان 57% قابلًا للأتمتة الكاملة، و23% بمساعدة الذكاء الاصطناعي، و20% لا يحكم عليه إلا الإنسان:
Harness (حتمية السطح) 23% — linter·formatter·CI، البنية والأسلوب
+ Ratchet (حتمية السلوك) 57% — go test·Hurl·بوابات، الاتساق السلوكي
──────────────────
80% — تحكم عليه الآلة
الإنسان يركّز على الـ 20% المتبقي — ملاءمة الأعمال·UX·اتجاه المعمارية
الـ Quest CLI أداة تجعل ذلك الـ 57% تحكم عليه الآلة. يركّز الإنسان على الـ 20%، ولا يصبح التدقيق البشري صفرًا، بل يقلّ ألم التدقيق البشري.
هذه ليست نتيجة بلغتها وحدي. أناس لا يعرف بعضهم بعضًا اصطدموا بالجدار نفسه فوصلوا إلى المبدأ نفسه. episteme (فرض Reasoning Surface قبل عمل لا رجعة فيه)، MagLab («نموذج LLM للاستدلال فقط، والأرقام لأداة حتمية»)، Manifesto («Agent proposes, World verifies»)، NEKOWORK (مسح قواعد حتمي قبل الدمج)، oh-my-kamisama («diffs beat claims»). تتلخّص كلها في جملة واحدة — التوليد يجوز أن يكون احتماليًا، أما التحقق فيجب أن يكون حتميًا.
Part 2 — تشريح الـ Quest
مكوّنات الـ Quest الخمسة
يتكوّن الـ Quest الواحد من خمسة مكوّنات. إن نقص واحد منها انهار في مكانه.
| المكوّن | ما هو | إن نقص |
|---|---|---|
| الهدف | ماذا يجب أن يُفعل | يقع الوكيل في broad exploration ويفقد الاتجاه |
| شرط الإنجاز | ما هي «النهاية» | يشعر الوكيل بأنه «يكفي» فينهي مبكرًا (40/527) |
| المدقّق (البوابة) | من يحكم على الإنجاز | الفاعل يحكم على إنجازه ← تملّق وهلوسة |
| التغذية الراجعة | ماذا يُعاد عند الخطأ | إن أُعيد «خطأ» فقط، تفاقم الأمر بالتصحيح المفرط |
| حالة التقدّم | إلى أين وصل | إن مات الوكيل، مات التقدّم معه |
آلة حالة أحادية الاتجاه — ratchet
مفتاح الـ ratchet له أسنان تتعشّق في اتجاه واحد فقط. إن أدرته تقدّم للأمام، وإن أفلته توقّف لكن لا يرتدّ. الـ Quest CLI يطبّق هذه الآلية على التحكم في الوكيل. وكود التحقق المكتوب بهذه الطريقة يُسمّى ratchet code — كود لا يسمح بالتراجع تحت مستوى تحقق نجح مرة.
خمسة مبادئ:
1. شرط الإنهاء آلي. pass/fail. ليس «looks good». لا مجال لتدخّل حكم ذاتي.
2. الـ PASS ثابت. البند الذي نجح لا يُفتح ثانية. عدد البنود المتبقية يتناقص رتابة.
remaining(t+1) ≤ remaining(t)
ما صنعته اليوم لا تعيد فتحه غدًا. «الوكيل العامل 24 ساعة» الذي يدور دون شرط إنهاء، يضيف تجريدًا اليوم ويزيله غدًا ويعيده بعد غد. الـ ratchet لا يسمح بمثل هذا التذبذب.
3. نموذج LLM يولّد فقط. توليد الكود وتقديم مقترح تعديل — هذا دور نموذج LLM. أما ماذا يُعدَّل، وهل نجح، وما التالي، وهل انتهى، فكلها تُقرّرها الآلة. نموذج LLM ليس planner بل constrained generator.
4. نزع سلطة الوكيل في الحكم بالإنهاء. إن قال نموذج LLM «أنجزت» توقّف عند 40، وإن قالت الآلة توقّف عند 527. في تتبّع Cemri et al. لـ 1600 تشغيل وكيل، شكّل الـ premature termination 6.2% من إجمالي أنماط الفشل.
5. المدقّق يجب أن يكون حتميًا. ليس كل شيء يصلح أن يكون مدقّقًا.
| يصلح | لا يصلح |
|---|---|
go test | “looks cleaner” |
| قياس coverage | “seems better” |
| AST validation | “more scalable” |
| schema diff | “clean architecture” |
| مطابقة النطاق وفحص MX | «يكفي هذا القدر» |
شروط المدقّق الأربعة: deterministic, machine-checkable, resumable, localized feedback. إن لم تستوفِ هذه الأربعة، لم تتعشّق أسنان الـ ratchet.
الوكلاء يموتون. التقدّم يبقى.
الوكيل لا بد أن ينهار. حدّ التوكنات، خطأ شبكة، انقطاع جلسة. إذا خزّن الـ ratchet حالة التقدّم بشكل دائم، فحتى لو مات الوكيل أكمل الوكيل التالي.
الوكيل A: يعالج 1~200 → يموت
الوكيل B: next → يكمل من 201
الوكيل C: next → يكمل من 401
الوكيل لمرة واحدة. التقدّم يتراكم.
للبوابة نطاق — صدّ الـ cheese
إن توقفت هنا فقد رأيت النصف فقط. ما تعلّمه إياه الألعاب حقًا هو ما يأتي بعد ذلك.
«اصطد عشرة فئران» quest سيئ السمعة. لماذا؟ لأن بين ما تتحقق منه البوابة (موت عشرة فئران) وما أراده المصمّم حقًا (أن يعيش اللاعب المحتوى) فجوة. البوابة ليست سوى بروكسي (proxy) للغرض، والفاعل ينفذ من تلك الفجوة. تسمّي ألعاب التصميم هذا cheese. وحتى أحدث نماذج الاستدلال تفعل هذا بالضبط — حين تلقّت quest بهزيمة محرك شطرنج، عمد نموذج كـ o3 إلى التلاعب بملف حالة اللعبة لصناعة «انتصار» بدل أن يلعب بشرف (Bondarenko et al., 2025). كلما ارتفعت القدرة، أحسنَ إيجاد الثغرة.
بوابة إيجاري قد تُتَّعرض للـ cheese أيضًا. الصور الخمس تتحقق من «وجود صورة» لا من «انتهاء المغادرة سليمةً». ماذا لو اختار المسؤول جدرانًا نظيفة فحسب وصوّرها؟ ماذا لو أعاد استخدام صور ما قبل الإشغال؟ تمرّ البوابة. لحظة يصبح القياس هدفًا يَفسد القياس — هذا قانون Goodhart.
لذا فإن المهارة الحقيقية في الـ Quest ليست «تركيب بوابة» بل تصميم بوابة يستحيل الـ cheese عليها. الـ Quest الضعيف يسأل «هل توجد صورة؟». والـ Quest القوي يطلب ختمًا زمنيًا، ويفحص بيانات الموقع الوصفية، ويقارن بصور وقت الإشغال. للبوابة نطاق. هناك quests يكفيها «exit 0 = PASS» العامة، لكن معظم quests الواقع تحتاج بوابة تعيد التحقق مباشرة مما هو حقيقي في ذلك النطاق.
قاعدة عملية واحدة: قبل كتابة البوابة، اسأل نفسك أولًا «كيف أكسر هذه البوابة بحيلة؟» هناك قياس يبيّن أنك إذا جعلت البوابة صلبة عمدًا (environmental hardening) انخفضت عمليات الاستغلال 87.7% دون خسارة في الدقة (Thaman, 2026). صلابة البوابة مسألة تصميم لا حظ.
الـ cheese في الواقع كلفته حقيقية. quest اللعبة غير مؤذٍ إن تعرّض للـ cheese. بوابة الواقع مختلفة — احتيال مغادرة، بناء مكسور، محاسبة مُعتمَدة خطأً. لذلك يجب أن تكون بوابة الواقع أشد مقاومة للـ cheese من اللعبة.
التغذية الراجعة يجب أن تكون حقيقة — gradient signal
إذا أعاد الـ ratchet «نجاح/فشل» فحسب، عدّل نموذج LLM دون اتجاه. كلما كانت التغذية الراجعة محدّدة، صار تصحيح نموذج LLM أدقّ.
تغذية راجعة ضعيفة: "فشل الاختبار" → يصحّح LLM دون اتجاه
تغذية راجعة متوسطة: "تغطية 65%" → يعزّز LLM على نحو تقريبي
تغذية راجعة قوية: "line 41, 44, 70 غير مغطّاة" → يغطّي LLM ذلك الفرع بالضبط
أرقام تحقّقت في مشروع فعلي: دون تغذية راجعة توقّف عند تغطية 60~70%، وحين لعب سطر واحد «line 41 not covered» دور الـ gradient signal، تحقّق 100% (في حدود الدوال القابلة للوصول). قوة نموذج LLM ليست broad exploration بل local correction. «اكتب اختبارات هذا المشروع» يفقد الاتجاه، أما «line 41 لم تُغطَّ» فيغطّي ذلك السطر بالضبط.
حين تعيد البوابة FAIL، ضمّنها لزامًا الموضع + العدد + القيمة المتوقعة. “field name mismatch: expected ‘user_id’, got ‘userId’”, “status 201 ≠ expected 200”. حقيقة لا مجال للتملّق فيها.
Symbolic Feedback Loop
ثمة بنية واحدة تخترق كل هذه الملاحظات.
يولّد LLM → تحكم أداة حتمية → تُعاد النتيجة إلى LLM → تكرار
يُسمّى هذا Symbolic Feedback Loop. وهو عكس الـ LLM Feedback Loop السائد في الصناعة (ذكاء اصطناعي يتحقق من ذكاء اصطناعي) تمامًا. pytest لا يهلوس، وgo test لا يثمَل، وقياس التغطية لا يكذب. تعمل هذه البنية في النطاقات التي يمكن الحكم على صحّتها آليًا — الكود، الاختبارات، المواصفات، الأنواع، حقائق النطاق.
أهمّ من جعل القطار أسرع هو مدّ السكّة. كثيرون يصنعون القطار. أما من يمدّ السكّة فنادرون حتى الآن.
Part 3 — هيكل الأوامر (cobra)
من هنا يبدأ المخطط. ننقل مبادئ القسمين 1 و2 إلى سطح أوامر Go + cobra. النموذج الأوّلي للبنية أدناه هو scan/next/verify في huma — والجزء الرابع يتتبّع huma بوصفه المثال المحلول.
فصل الأدوار
| الدور | المسؤول | الموضع |
|---|---|---|
| التوليد | وكيل الذكاء الاصطناعي | خارج الـ CLI (Claude Code وغيره يبحث ويقرّر ويكتب) |
| الحكم | gate | داخل الـ CLI. إعادة تحقّق حتمية. لا رأي، حقيقة فقط |
| التقدّم | session | داخل الـ CLI. بند واحد = quest واحد. آلة حالة أحادية الاتجاه |
الجوهر: الوكيل خارج الـ CLI. الـ CLI يعطي الوكيل المهمة التالية (next)، ويتلقى تسليم الوكيل فيحكم عليه بالبوابة (submit)، ويقفل ما نجح فقط. الوكيل فاعل خارجي يستدعي الـ CLI كأداة.
سطح الأوامر
يتطابق 1:1 مع المكوّنات الخمسة.
| الأمر | ما يفعله | تطابق المكوّنات الخمسة |
|---|---|---|
scan <input> | يقرأ قائمة المهام فيُنشئ جلسة (N quest). يتذكّر مسار المصدر | الهدف + تهيئة حالة التقدّم |
next | يُخرج quest TODO تاليًا واحدًا + موجّهًا للوكيل | إصدار هدف واحد |
submit [--flags] | يُسلّم نتيجة الوكيل → حكم البوابة → إن PASS يقفل | شرط الإنجاز + المدقّق + التغذية الراجعة |
status | حالة التقدّم (تجميع PASS/REVIEW/DONE/TODO) | استعلام حالة التقدّم |
export [path] | تصدير النتائج (يحفظ الأصل، يضيف أعمدة نتائج إلى نسخة) | المُخرَج |
next يُظهر quest واحدًا فقط في المرة. لا يُفتح التالي إلا بعد النجاح. وحين تنجح كلها يتوقّف. الوكيل يكفيه معرفة أمرين — يتلقّى بـ next، ويُسلّم بـ submit. والباقي تقرّره الآلة.
صيغة إدخال scan تتبع النطاق — إكسل أو CSV أو قائمة نصّية أو دليل أو مواصفة OpenAPI، أيًّا كان. openapi.yaml في huma (قائمة نقاط النهاية) مجرد مثال.
آلة الحالة
TODO ──► PASS تجاوز البوابة → قفل (لا رجعة). تثبيت النتيجة
│
├────► REVIEW حالة غامضة (يمر البروكسي لكن دون يقين) → قائمة تأكيد الإنسان
│ (لا يُمرَّر في صمت)
│
└────► DONE تجاوز MaxTries → إنهاء عند المستوى الحالي (منع إعادة المحاولة اللانهائية)
type State int
const (
TODO State = iota // غير معالَج
PASS // تجاوز البوابة → قفل (لا رجعة)
REVIEW // يحتاج تأكيد الإنسان
DONE // إنهاء بتجاوز MaxTries
)
const MaxTries = 3
الـ PASS ثابت. الـ quest الذي صار PASS مرة لا يصدره next ثانية. الـ remaining يتناقص رتابة. تُخزَّن الجلسة بشكل دائم على القرص بـ JSON أو نحوه حتى يُكمَل العمل إن مات الوكيل (resumable).
قواعد الانتقال الواجب تصريحها (إن غمضت اختلف الوكلاء):
- الـ FAIL يبقي الـ TODO. فشل البوابة يُبقي الـ quest في TODO ويزيد
Triesبمقدار +1 ويخزّن تغذية Fact راجعة. - الـ Tries لا يزيد إلا عند الـ FAIL. حين يصير
Tries >= MaxTriesيُنهَى إلى DONE (>=، لا>— إذا MaxTries=3 فعند الـ FAIL الثالث يصير DONE). - PASS·REVIEW·DONE لا تُعاد تسليمها. الثلاثة حالات طرفية.
submitيعيد خطأً على quest مقفل ولا يغيّر شيئًا. الـ REVIEW يعالجه الإنسان من القائمة منفصلًا، ولا تلمسه حلقة الوكيل ثانية. هذا الثبات يضمن تناقصremainingالرتيب.
البوابة — جوهر الحكم الحتمي
للبوابة نطاق. أدناه عقد (interface)، أما بنود الفحص الفعلية فتُملأ على نحو مختلف لكل نطاق.
type Verdict int
const (
VerdictPASS Verdict = iota
VerdictFAIL
VerdictREVIEW
)
// Fact = تغذية راجعة بـ "حقائق" تُعاد إلى الوكيل (لا آراء).
// تحوي الموضع·القيمة المتوقعة·القيمة الفعلية.
type Fact struct {
Field string
Expected string
Actual string
}
type Gate interface {
// Check يعيد التحقق من التسليم على نحو حتمي.
// نفس الإدخال + نفس world-state → دائمًا نفس الإخراج. دون تدخّل رأي خارجي.
Check(s Submission) (Verdict, []Fact)
}
// الاستعلامات الخارجية (الشبكة·DNS·الملفات) يجب أن تُخرَج دائمًا خلف واجهة.
// إن استدعت البوابة net/http مباشرة، استحال اختبار الوحدة وتذبذب الحكم تبعًا للبيئة.
// نبدّل بين التنفيذ الفعلي (HTTPFetcher) وmock للاختبار.
type Fetcher interface {
Fetch(url string) (body string, ok bool, err error)
}
// تتلقّى البوابة Fetcher بالحقن — يُمنع استدعاؤه مباشرة.
func NewGate(f Fetcher) Gate { /* ... */ }
افرض قواعد البوابة الثلاث:
- حتمية: التسليم نفسه + world-state نفسه دائمًا الحكم نفسه. ممنوع استدعاء نموذج LLM.
- إعادة التحقق: تتحقق من الحقيقة مباشرة لا من ادّعاء الوكيل. ما قال الوكيل «كتبت الاختبار» تفحصه البوابة حرفيًا من جديد (هل يُشغَّل ذلك الاختبار فعلًا ويجتاز).
- الاستعلام الخارجي خلف واجهة: استعلام الشبكة وDNS والملفات يُحقَن عبر واجهة كـ
Fetcher. إن استدعت البوابةnet/httpمباشرة استحال اختبار الوحدة (وهذا يناقض «أولوية البوابة 90%+» في قائمة التحقق) وتذبذب الحكم تبعًا للبيئة.
الحتمية والشبكة — الخطأ ليس FAIL
حين تعتمد البوابة على الشبكة كفحص MX أو إعادة fetch لصفحة، يجب تضييق معنى «الحتمية». نفس الـ world-state (نفس الاستجابة) فنفس الحكم — هذا هو الحتمية. المشكلة حين لا تعطي الشبكة جوابًا. إن عالجت timeout وانقطاع الاتصال بوصفها FAIL، سقط هدف سليم فعلًا بسبب ظرف خطّي — وهذا لاحتمية يتغيّر فيها الحكم تبعًا للبيئة.
لذا قسّم نتيجة بوابة الاستعلام الخارجي إلى ثلاثة فروع:
| الحالة | الحكم | السبب |
|---|---|---|
| الحقيقة تأكّدت (الاستجابة تستوفي الشرط) | PASS | نجح التحقق |
| الحقيقة دُحضت (الاستجابة تخالف الشرط — عدم تطابق status code، خرق العقد) | FAIL | خطأ حقيقي |
| تعذّر التأكد (timeout·offline·5xx) | REVIEW | ليس خطأ البوابة ← إلى قائمة الإنسان/إعادة المحاولة |
الـ FAIL فقط حين «الحقيقة خاطئة». و«لم أتمكّن من التأكد» هو REVIEW. دون هذا التمييز تقتل البوابة نتيجة سليمة بضوضاء البيئة.
اشتقاق البوابة في نطاق اعتباطي — 5 خطوات
بوابة huma هي نسخة من نطاق نقاط نهاية الـ API لا صيغة عامة. بوابة نطاقك تُصنع بملء هذه الفراغات:
- الشكل: هل التسليم صحيح شكليًا. (صيغة بريد / مخطط URL / صيغة تاريخ)
- القائمة السوداء: FAIL فوري للحشوات والقمامة الظاهرة. (
example.com،test، قيمة فارغة) - شرط REVIEW: المنطقة الرمادية التي يمر البروكسي فيها لكن دون يقين، إلى قائمة الإنسان. (بريد مجاني / نطاق اجتماعي·استضافة / مطابقة غامضة) — الجوهر منع PASS الصامت.
- ★ الجوهر: إعادة التحقق من الحقيقة (صدّ الـ cheese) ★: الحقيقة الفعلية للنطاق التي تسدّ النقطة التي يمكن للوكيل أن يكسرها بحيلة. في huma هي «هل اختبار Hurl المُسلَّم يصيب فعلًا تلك النقطة ويتحقق من عقد الاستجابة (status + الحقول الأساسية)». في نطاقك، ما هي «الحقيقة التي تَفضح الوكيل إن اختلقها»؟ هذا قلب البوابة. قبل كتابتها اسأل نفسك أولًا «كيف أكسر هذه البوابة بحيلة؟».
- القابلية للوصول/التطابق الخارجي: التوافق مع العالم الخارجي. (وجود MX / وصول URL / تطابق النطاق↔التسليم) — لزامًا بقاعدة الفروع الثلاثة أعلاه.
دون الخطوة 4 تصبح البوابة quest ضعيفًا يرى الشكل فقط. وكيفية ملء الخطوة 4 هي سبب اختلاف البوابة من نطاق لآخر، وسبب تقارب الوكلاء إن كان النطاق ذاته.
التحقق المتسلسل — التحقق الآلي + التحقق بالذكاء الاصطناعي
ضيّقنا حتى الآن البوابة إلى «حتمية، ممنوع استدعاء نموذج LLM». تلك بوابة النطاق القابل للتحقق (الكود·المخططات). لكن في نطاقات فيها بقايا مفتوحة لا تستطيع الآلة اقتطاعها — كطلاقة الترجمة وأمانة التلخيص — يبرز موضع لا تبلغه البوابة الحتمية. ومع ذلك، أن تسأل تلك البقايا نموذج LLM واحدًا «هل هذا جيد؟» هو LLM-as-Judge الذي قتلناه في القسم 1 (تملّق·نقطة عمياء مشتركة·تدهور الضرب).
الجواب أن ترى البوابة بوصفها تحققًا متسلسلًا. كما يمضي الاستخراج من الخطوة الأرخص، فالتحقق أيضًا ذو طبقات:
Layer 1 التحقق الآلي (حتمي) رخيص وأكيد. السلطة الوحيدة لقفل PASS
Layer 2 التحقق بالذكاء الاصطناعي (مصمَّم باستقلالية) البقايا المفتوحة التي لا يبلغها الحتمي. سلطة FLAG/REVIEW فقط
Layer 3 الإنسان الشبر الأخير الذي فاتهما معًا
نسبة الخلط تختلف من نطاق لآخر — الكود طبقة L1 شبه كاملة، والترجمة L1 (تسرّب·مصطلحات·أرقام·بنية) + بقايا L2 (طلاقة·معنى)، والإبداع·الاستراتيجية L1 شبه معدوم وL2+L3.
عدم تماثل السلطة يحفظ العمود الفقري. أدخِل الذكاء الاصطناعي في التحقق، لكن لا تمنحه سلطة الإنجاز:
| التحقق | السلطة |
|---|---|
| التحقق الآلي (L1) | السلطة الوحيدة لقفل «الإنجاز». الحتمي يحكم بـ PASS |
| التحقق بالذكاء الاصطناعي (L2) | يثير الشك فقط (FLAG/REVIEW/FAIL). لا يمنح الإنجاز |
ما يستطيع الحتمي أن يحكمه PASS يقفله الحتمي، والذكاء الاصطناعي لا يفعل إلا «هذا الموضع الذي لم يره الحتمي مريب ← أخرجه إلى REVIEW». متشكّك داخل البوابة لا حَكَم. (في النطاق المفتوح الخالص الذي لا تتوفّر له آلة تتحقق منه إطلاقًا، يتحمّل الذكاء الاصطناعي + الإنسان مسؤولية PASS وحدهما، لكن عندها يجب فرض شروط الاستقلالية أدناه.)
شروط دخول التحقق بالذكاء الاصطناعي. لحظة تُدخل الذكاء الاصطناعي البوابة، يصير التحقق بلا استقلالية إجماعًا على الهلوسة. افرض أربعة:
- مستقل عن المولّد — نموذج آخر، و/أو إدخال آخر. (في تحقق الترجمة، الترجمة العكسية (back-translation) التي ترى النص المترجَم لا الأصل — إدخال آخر فتكون الأخطاء مستقلة بنيويًا. ومقارنة بقاء الحقيقة بعد الذهاب والإياب بمرساة حقيقية تُنزل التحقق المفتوح إلى مقارنة حتمية.)
- يأتي بعد الحتمي — ما يستطيع L1 إمساكه لا يُوكَل للذكاء الاصطناعي. لا تفوّض الرخيص الأكيد إلى الغالي المتذبذب.
- تعدّد + عتبة — ممنوع مدقّق منفرد. أغلبية نماذج متباينة منخفضة الارتباط.
- الإقرار باللاحتمية — الذكاء الاصطناعي يتذبذب حتى عند T=0. لا يقفل PASS بل يوجّه إلى REVIEW.
التحقق بالذكاء الاصطناعي لا يكون درجة بل yes/no مُفكَّكًا. «الجودة من 1 إلى 10» صعب كالتوليد ومرتبط بالمولّد. فكّكه إلى أسئلة مستقلة ضيّقة يكون التحقق فيها أسهل من التوليد — «هل بينها جملة غير طبيعية؟ إن وُجدت فعدّدها» / «هل أُضيف ادّعاء غير موجود في الأصل؟» / «هل اختفت حقيقة بعد الترجمة ذهابًا وإيابًا؟». كلما ضيّقت كان أكثر استقلالية، وصار الإخراج حقيقة ذات موضع تعمل كـ gradient signal مثل تغذية L1 الراجعة.
خلاصة — الحتمي يمسك سلطة الإنجاز، والذكاء الاصطناعي متشكّك مصمَّم باستقلالية يحكّ ما لا يبلغه الحتمي بأسئلة yes/no ضيّقة، والإنسان لا يرى إلا البقايا التي فاتتهما معًا. ليست عبارة «التحقق يجب أن يكون حتميًا» تضعف، بل يمسك الحتمي سلطة الحكم بالإنجاز بينما يمتد مداه إلى النطاق المفتوح.
حلقة الوكيل
1. إنشاء جلسة بـ scan (الإنسان مرة واحدة)
2. للوكيل: "أدر الحلقة حتى إكمال next"
┌──────────────────────────────────────┐
│ next → الـ quest التالي + موجّه │
│ ↓ │
│ يولّد الوكيل (بحث·حكم·كتابة) │
│ ↓ │
│ submit → gate.Check() │
│ ↓ │
│ PASS? → قفل، إلى التالي │
│ FAIL? → إعادة محاولة مع تغذية Fact │
│ (تجاوز MaxTries → DONE) │
└──────────────────────────────────────┘
3. TODO == 0 → توقّف. export.
الموجّه الذي تعطيه للوكيل يكفيه هذا السطر الواحد:
دع الوكيل الفرعي يدور في الحلقة حتى يُكمل
<cli> next.
حين يعود الـ FAIL يذهب معه Fact (الموضع·المتوقع·الفعلي)، فكلما كان النموذج أكثر تملّقًا قبل تلك الحقيقة طوعًا وتقارب (راجع «التملّق أصل» في القسم 1). بوابة حتمية + نموذج LLM متملّق = حلقة مضمونة التقارب.
شروط التقارب الثلاثة (التزمها لزامًا)
- التغذية الراجعة يجب أن تكون حقيقة حتمية. ليس «هذا غريب بعض الشيء» بل “line 41: expected ‘user_id’, got ‘userId’”.
- يجب أن يكون المثال في السياق. التغذية الراجعة وحدها لا تكفي. ضع في الموجّه الذي يُخرجه
nextمثالًا يقول «أخرِج نتيجة بهذا الشكل». عنق الزجاجة ليس الذكاء بل السياق. - النجاح في التحقق لا رجعة فيه. أسنان الـ ratchet. الـ PASS يُقفل. ليس الوكيل من يعلن «أنجزت» بل البوابة من تحكم بأن «هذا الـ quest نجح».
تبديل المدقّق يجعلها أداة أخرى
الـ Quest CLI لا يتبع بوابة بعينها. بمجرد تبديل البوابة يصير أداة أخرى.
| Quest + بوابة | الأداة |
|---|---|
Quest + go test + coverage | توليد اختبارات وحدة للدوال (tsma) |
| Quest + validator قواعد بنية | تنظيم بنية الكود (filefunc) |
| Quest + hurl pass/fail | التحقق من نقاط نهاية API (huma) |
| Quest + تحقّق متقاطع للمواصفات | اتساق SSOT (yongol) |
النمط واحد. البوابة تُحدّد النطاق.
Part 4 — مثال محلول: huma
huma (/ar/tech/huma/) هو Quest CLI يُجبر كل نقطة نهاية في مواصفة OpenAPI على أن يتحقق منها اختبار Hurl. مخطط scan/next/verify في هذا المقال جاء من النموذج الأوّلي لـ huma — لذا فإن huma هو المثال المحلول الأنظف. الـ vibe coding يتخطّى نقاط النهاية في صمت، وhuma يصدّ ذلك الإنهاء المبكر ببوابة.
quest واحد = نقطة نهاية واحدة. فحوص البوابة الحتمية:
- الشكل: صيغة Hurl صحيحة
- القائمة السوداء: اختبار فارغ بلا تأكيدات (assertions) → FAIL
- اختبار ضعيف (status code فقط، لا body) → REVIEW (منع المرور الصامت)
- ★ التنفيذ الفعلي ★ →
hurl --testيصيب النقطة فعلًا ويجب أن يجتاز → PASS (يثبت أن الاختبار حقيقي، يصدّ الهلوسة) - تطابق عقد الاستجابة → FAIL إن انحرفت الاستجابة عن status / الحقول الأساسية في مخطط OpenAPI
الخطوتان 4 و5 هما جوهر صدّ الـ cheese. حتى لو ادّعى الذكاء الاصطناعي «كتبت الاختبار» فحسب، أو زيّفه بـ assert status == 200 واحد، تُشغّل البوابة Hurl فعليًا وتعيد التحقق من عقد الاستجابة. التوليد من الذكاء الاصطناعي، والحكم من الآلة. الذكاء الاصطناعي يكتب الاختبار لكن لا يملك سلطة الحكم بالإنجاز.
الأوامر هي تمامًا كما في القسم 3:
go build -o huma .
./huma scan openapi.yaml # قائمة نقاط النهاية → إنشاء جلسة
./huma next # نقطة النهاية التالية + موجّه الوكيل
./huma submit --endpoint "POST /orders" \
--test "orders_post.hurl" # اختبار Hurl الذي كتبه الوكيل
./huma status # حالة التقدّم
./huma export # تقرير التغطية (PASS/غير مغطّى لكل نقطة نهاية)
تشغيله بسطر واحد في Claude Code:
دع الوكيل الفرعي يكتب اختبارات لكل نقطة نهاية حتى ينفد
huma next.
يكرّر الوكيل الفرعي حلقة next → كتابة الاختبار → submit حتى يصير TODO صفرًا. لا يستطيع الوكيل تخطّي نقطة نهاية صعبة — next لا يصدر التالية حتى تجيزها البوابة.
هذا يُظهر جوهر النمط. بدّل البوابة فقط (go test→hurl→تحقّق متقاطع للمخطط) وتصير الأجزاء الخمسة نفسها، وآلة الحالة نفسها، أداة مختلفة تمامًا. في القسم 5 تفعل ذات الشيء لنطاقك أنت.
Part 5 — ابنِ Quest CLI الخاص بك
ورقة عمل التصميم
املأ الفراغات يصر ذلك مواصفة.
النطاق: [ماذا يُجمَع/يُعالَج]
وحدة الـ quest الواحد: [ما الشيء الواحد الذي يساوي quest — شركة واحدة؟ دالة واحدة؟ نقطة نهاية واحدة؟]
الإدخال: [ما الذي سيقرؤه scan — إكسل؟ دليل؟ قائمة؟]
شرط الإنجاز: [شرط تستطيع الآلة الإجابة عنه بنعم/لا]
بنود فحص البوابة: [ما "الحقيقة" في النطاق — البنود الواجب إعادة التحقق منها]
- فحص الشكل: [...]
- صدّ الـ cheese: [كيف سيحتال الوكيل؟ إعادة التحقق التي تسدّ ذلك]
- شرط REVIEW: [حالة غامضة تُرسَل إلى الإنسان]
التغذية الراجعة (Fact): [الموضع·المتوقع·الفعلي يُعاد عند FAIL]
مثال: [عيّنة "نتيجة بهذا الشكل" تُوضَع في موجّه next]
صيغة export: [حفظ الأصل + أعمدة النتيجة]
شرط الإنجاز (بوابة هذا البناء نفسه)
كي «يُنجَز» الـ Quest CLI المصنوع بهذا المقال — أي كي يكون هذا المقال cheese-proof كما علّم — يجب استيفاء التالي:
- نجاح
go build - عمل أوامر
scan / next / submit / status / export - آلة الحالة
TODO → PASS/REVIEW/DONE، الـ PASS ثابت، الـremainingيتناقص رتابة - التحقق الآلي L1 حتمي (نفس الإدخال + world-state → نفس الحكم) — سلطة قفل PASS لـ L1 وحده
- إن وُجدت بقايا مفتوحة فـ التحقق بالذكاء الاصطناعي L2 مصمَّم باستقلالية (نموذج/إدخال آخر)·متعدّد·yes/no مُفكَّك — سلطة REVIEW فقط، لا يقفل PASS
- البوابة تعيد التحقق من الحقيقة لا من ادّعاء الوكيل (بند صدّ cheese واحد على الأقل — الخطوة 4 من خطوات الاشتقاق الخمس)
- الاستعلام الخارجي (الشبكة·DNS) يُحقَن خلف واجهة — الاختبار يعمل دون اتصال بـ mock
- بوابة الاستعلام الخارجي ثلاثية الفروع PASS/FAIL/REVIEW (تعذّر التأكد = REVIEW لا FAIL)
- الـ FAIL يبقي TODO ويزيد
Tries+1، و>=MaxTriesيصير DONE؛ PASS·REVIEW·DONE لا تُعاد تسليمها - تغذية الـ FAIL راجعة تكون
Factيحوي الموضع·المتوقع·الفعلي - الجلسة دائمة على القرص (resumable)
- اختبار الوحدة: أولوية gate، إجمالي statements 90%+
-
exportلا يكتب فوق الأصل
توجيه البناء
تعطيه للوكيل هكذا:
اتخذ القسم 3 (هيكل الأوامر) من هذه الوثيقة مخططًا، والقسم 4 (huma) مثالًا محلولًا، واكتب Quest CLI بلغة Go قائمًا على cobra من أجل [نطاقك]. واصل حتى تستوفي كامل قائمة شروط الإنجاز في القسم 5. يجب أن تكون البوابة حتمية لزامًا، وأن تعيد التحقق من الحقيقة لا من ادّعاء الوكيل.
ثلاثة أدوار في هذا المشهد الواحد.
- يلعب الـ quest. يستورد بوابة صنعها غيره ويستعملها — المستخدم.
- يصمّم الـ quest. يبني بنفسه بوابة تناسب نطاقه — المُنتِج. (إلى هنا يأخذك هذا المقال)
- يصمّم quest يستحيل الـ cheese عليه. يسدّ مسبقًا النقطة التي لا يلحق فيها البروكسي بالغرض — المصمّم.
معظم الناس يتوقفون عند اللعب. من يُكبّر الرقعة هو التصميم، ومن يحفظها من الانكسار هو تصميم صدّ الـ cheese.
في المرة القادمة حين يقول أحدهم «أنجزته»، لا تشكّك بل اسأل — «ما الإنجاز، ومن صمّم الـ quest الذي حكم به؟»
التوليد يجوز أن يكون احتماليًا. أما التحقق فيجب أن يكون حتميًا.
مقالات ذات صلة
- Who Defines ‘Done’ — تصميم الإنجاز بوصفه quest — الجزء المفاهيمي لهذا المقال. الإنجاز=بوابة، cheese·Goodhart.
- Ratchet Pattern — كيف تجعل الوكيل يصل إلى النهاية — المتن الأصلي للقفل أحادي الاتجاه.
- ratchet code يعكس استغلال IFEval — التقارب بالتغذية الراجعة الحقيقية.
- Reins Engineering — ذكاء اصطناعي بعِنان — الـ harness سياج، والـ Quest عِنان.
- طوبولوجيا التغذية الراجعة أهمّ من ذكاء النموذج — ما يفصل النتائج ليس النموذج بل بنية التغذية الراجعة.
- huma — ratchet لا يتخطّى نقاط النهاية — النموذج الأصلي لهيكل الأوامر (scan/next/verify).
- الشروط المسبقة لتحسين دقة وكلاء LLM المتعددين — لماذا تعمل طبقة التحقق بالذكاء الاصطناعي (L2) فقط حين تملك الاستقلالية. الخلفية النظرية للتحقق المتسلسل.
المراجع
- Von Neumann, J. (1956). “Probabilistic Logics and the Synthesis of Reliable Organisms from Unreliable Components.” Automata Studies, Princeton University Press.
- Zhou, J. et al. (2023). “Instruction-Following Evaluation for Large Language Models.” arXiv:2311.07911
- Ouyang, L. et al. (2022). “Training Language Models to Follow Instructions with Human Feedback.” NeurIPS 2022. arXiv:2203.02155
- Huang, J. et al. (2024). “Large Language Models Cannot Self-Correct Reasoning Yet.” ICLR 2024. arXiv:2310.01798
- Chen, X. et al. (2024). “Teaching Large Language Models to Self-Debug.” ICLR 2024. arXiv:2304.05128
- Yang, J. et al. (2024). “SWE-agent: Agent-Computer Interfaces Enable Automated Software Engineering.” NeurIPS 2024.
- Jimenez, C. et al. (2024). “SWE-bench: Can Language Models Resolve Real-World GitHub Issues?” ICLR 2024. arXiv:2310.06770
- Zhou, S. et al. (2023). “WebArena: A Realistic Web Environment for Building Autonomous Agents.” arXiv:2307.13854
- Cemri, M. et al. (2025). “Why Do Multi-Agent LLM Systems Fail?” arXiv:2503.13657
- Sharma, M. et al. (2024). “Towards Understanding Sycophancy in Language Models.” ICLR 2024. arXiv:2310.13548
- Fanous, A. et al. (2025). “SycEval: Evaluating LLM Sycophancy.” AAAI/ACM AIES 2025. arXiv:2502.08177
- Shapira, I. et al. (2026). “How RLHF Amplifies Sycophancy.” arXiv:2602.01002
- Ibrahim, L. et al. (2026). “Training Language Models to Be Warm Can Reduce Accuracy and Increase Sycophancy.” Nature 652, 1159-1165.
- Panickssery, A., Bowman, S., & Feng, S. (2024). “LLM Evaluators Recognize and Favor Their Own Generations.” NeurIPS 2024. arXiv:2404.13076
- Stechly, K., Valmeekam, K., & Kambhampati, S. (2024). “On the Self-Verification Limitations of Large Language Models.” arXiv:2402.08115
- McKee-Reid, L. et al. (2024). “Honesty to Subterfuge: In-Context RL Can Make Honest Models Reward Hack.” arXiv:2410.06491
- Bondarenko, A. et al. (2025). “Demonstrating Specification Gaming in Reasoning Models.” arXiv:2502.13295
- Thaman, K. (2026). “Reward Hacking Benchmark: Measuring Exploits in LLM Agents with Tool Use.” arXiv:2605.02964
- Deque Systems (2021). “Automated Testing Study Identifies 57 Percent of Digital Accessibility Issues.”
سجل التغييرات
- 2026-06-03: الإصدار الأول (دمج 7 مقالات في المجموعة + huma، المثال المحلول). تعزيز المراجعة — اشتقاق بوابة النطاق في 5 خطوات، الحتمية·الشبكة بثلاثة فروع، seam الـ
Fetcher، قواعد انتقال الحالة. - 2026-06-03: استحداث «التحقق المتسلسل» — نموذج طبقتين: التحقق الآلي (L1، سلطة PASS) + التحقق بالذكاء الاصطناعي (L2، تصميم مستقل·سلطة REVIEW) + الإنسان (L3)، مع عدم تماثل السلطة. تعميم «البوابة = حتمي فقط» إلى النطاق المفتوح.
- 2026-06-05: تم سحب comail (جعله خاصًا) بسبب خطر المساعدة على نشاط غير قانوني. واستُبدل المثال العملي بـ huma.