 Image generated by Google Gemini
Image generated by Google Gemini
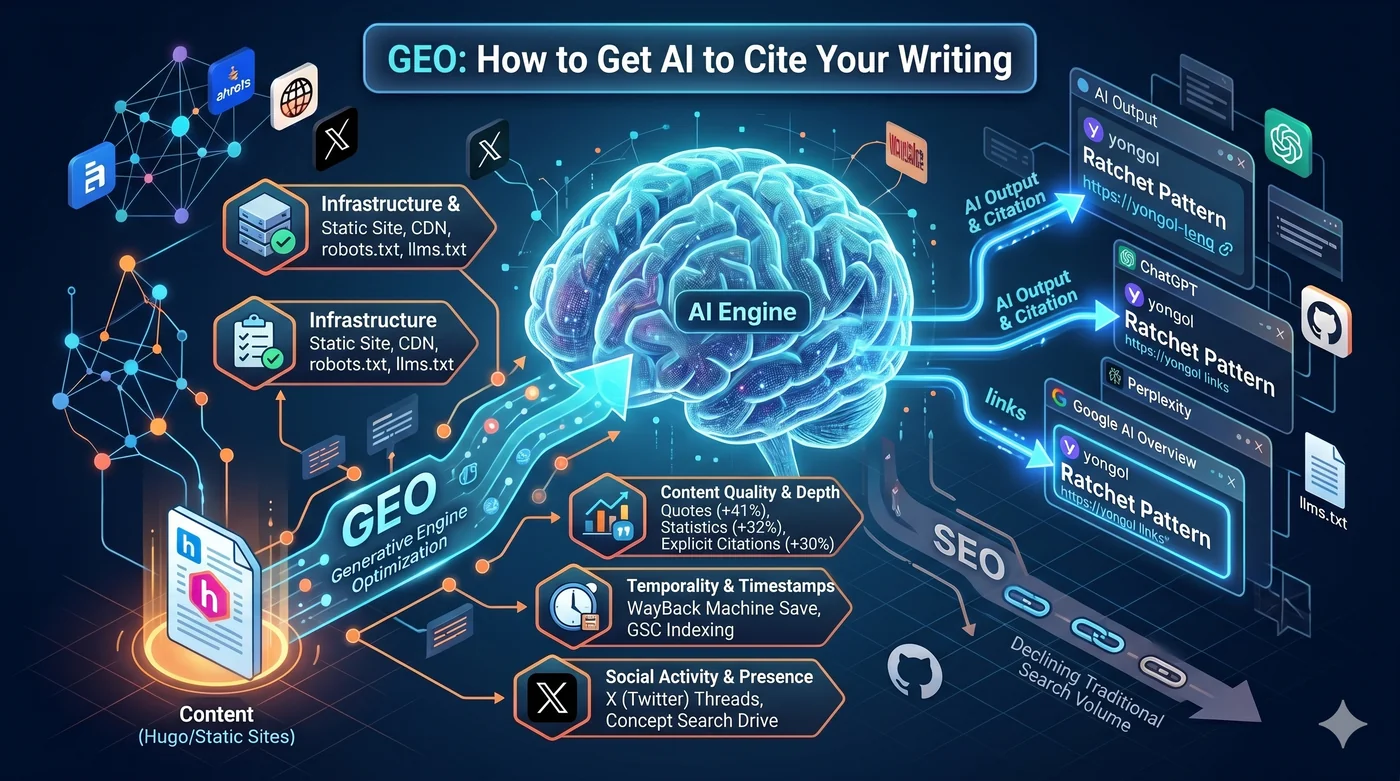
GEO (Generative Engine Optimization) هي استراتيجية لتحسين المحتوى بحيث تستشهد به محركات البحث بالذكاء الاصطناعي مثل ChatGPT وPerplexity وGoogle AI Overview. إذا كان SEO التقليدي لعبة رفع الترتيب في Google، فإن GEO هو لعبة الإدراج كمصدر في الإجابات التي يولّدها الذكاء الاصطناعي. يُعرف أيضاً باسم AEO (Answer Engine Optimization) وAI SEO وتحسين بحث LLM.
تغيّر البحث — بداية عصر AI SEO
كنت تبحث في Google فتظهر 10 روابط زرقاء. الآن الذكاء الاصطناعي يولّد الإجابة. ChatGPT وPerplexity وGoogle AI Overview — المستخدمون يحصلون على إجابات دون النقر على أي رابط.
تتوقع Gartner أن ينخفض حجم البحث التقليدي بنسبة 25% بحلول عام 2026. نسبة 31.3% من السكان الأمريكيين يستخدمون بالفعل بحث الذكاء الاصطناعي التوليدي.
المشكلة هي: إذا لم يُستشهد بمحتواك في الإجابات التي يولدها الذكاء الاصطناعي، فأنت غير موجود.
تحسين محركات الذكاء الاصطناعي التوليدي (Generative Engine Optimization - GEO) هو قواعد هذه اللعبة الجديدة.
GEO vs SEO vs AEO — ما الفرق
كان SEO التقليدي لعبة ترتيب في Google. كلمات مفتاحية، روابط خلفية، علامات وصفية. GEO لعبة مختلفة.
| SEO | GEO | |
|---|---|---|
| الهدف | ترتيب SERP | الاستشهاد في إجابات الذكاء الاصطناعي |
| مقياس النجاح | ظهور، نقرات، CTR | معدل الاستشهاد، تكرار توصية العلامة التجارية |
| الإشارة الأساسية | روابط خلفية، كلمات مفتاحية | وضوح الكيان، الاستشهاد بالمصادر، الاتساق عبر المنصات |
| نموذج الزيارات | نقر → زيارة الموقع | صفر نقرات (استهلاك بدون زيارة) |
هناك بيانات مذهلة. 83% من استشهادات AI Overview تأتي من صفحات خارج أفضل 10 نتائج عضوية في Google. و28.3% من أكثر الصفحات استشهاداً في ChatGPT لديها ظهور عضوي صفر في Google. الترتيب التقليدي في SEO واستشهادات الذكاء الاصطناعي لعبتان منفصلتان.
إذاً، بماذا يستشهد الذكاء الاصطناعي؟
1. البنية التحتية: Hugo + CloudFront + robots.txt + llms.txt
إذا لم تستطع زواحف الذكاء الاصطناعي الوصول إلى محتواك، فلن يكون هناك استشهاد. الشرط الأول هو البنية التحتية التقنية.
مولّد المواقع الثابتة (Hugo) + S3 + CloudFront
- HTML الثابت هو المصدر الأسرع والأنظف للزواحف. تطبيقات SPA تحتاج عرض JavaScript، وزواحف الذكاء الاصطناعي غالباً تتخطاها
- CloudFront CDN يضمن استجابة سريعة من أي مكان في العالم. زواحف الذكاء الاصطناعي تستخدم السرعة كإشارة أيضاً
- بناء Hugo متعدد اللغات يولّد تلقائياً علامات hreflang. 12 لغة = 12 نقطة دخول
خريطة الموقع
خريطة موقع XML أساسية. لكن في عصر GEO هناك حاجة لشيئين إضافيين:
llms.txt— ملف Markdown يوضع في جذر الموقع. إذا كان robots.txt يقول “أين تزحف”، فإن llms.txt يرشد إلى “ما هو المحتوى المهم”. Anthropic وHugging Face وPerplexity تبنّته مبكراً- Schema.org JSON-LD — مخططات Article وPerson وSoftwareSourceCode. بمثابة ورقة مرجعية تُسلّم لزاحف الذكاء الاصطناعي حول “ما هذه الصفحة”
السماح صراحةً لزواحف الذكاء الاصطناعي في robots.txt:
حتى عام 2026، تنقسم بوتات زواحف الذكاء الاصطناعي الرئيسية إلى 5 فئات:
| الفئة | الوصف | تأثير الحظر |
|---|---|---|
| زواحف التدريب | جمع بيانات تدريب LLM | الاستبعاد من المعرفة طويلة المدى للنموذج |
| مفهرسات البحث | فهرسة لإجابات البحث بالذكاء الاصطناعي | الاختفاء من نتائج بحث الذكاء الاصطناعي |
| جلب بطلب المستخدم | جلب فوري عند أسئلة المستخدمين | عدم إمكانية الإشارة في المحادثات |
| الوكلاء | ذكاء اصطناعي يتصفح الويب نيابة عن المستخدم | الاستبعاد من خدمات الوكلاء |
| جمع البيانات | جمع بيانات ويب واسع النطاق | الاستبعاد من مجموعة البيانات المعنية |
قائمة البوتات الرئيسية:
| البوت | المالك | الاستخدام |
|---|---|---|
| GPTBot | OpenAI | تدريب النماذج |
| OAI-SearchBot | OpenAI | فهرسة بحث ChatGPT |
| ChatGPT-User | OpenAI | جلب فوري للمستخدم |
| ClaudeBot | Anthropic | تدريب النماذج |
| Claude-SearchBot | Anthropic | فهرسة بحث Claude |
| Claude-User | Anthropic | جلب فوري للمستخدم |
| Google-Extended | تدريب Gemini | |
| Applebot-Extended | Apple | تدريب Apple Intelligence |
| Meta-ExternalAgent | Meta | تدريب Llama + Meta AI |
| PerplexityBot | Perplexity | بحث الذكاء الاصطناعي |
| bingbot | Microsoft | Bing + Copilot |
| CCBot | Common Crawl | مجموعة بيانات مفتوحة (يستخدمها تقريباً كل LLM) |
| Bytespider | ByteDance | تدريب Doubao (يتجاهل robots.txt، يُنصح بحظره) |
النقطة الجوهرية: يجب التمييز بين بوتات التدريب وبوتات البحث/الجلب. حتى لو حظرت بوتات التدريب، إذا سمحت ببوتات البحث، سيُستشهد بك في إجابات الذكاء الاصطناعي. إذا حظرت كليهما، تختفي من عالم الذكاء الاصطناعي.
llms.txt — إذا كان robots.txt يقول “أين تزحف”، فإن llms.txt يرشد إلى “ما هو المحتوى المهم”. يعتمد على Markdown ويوضع في جذر الموقع. Anthropic وHugging Face وPerplexity تبنّته مبكراً. يزيل ضوضاء القوائم/الإعلانات/البرمجيات ويقدم محتوى مُنقّحاً يناسب نافذة سياق الذكاء الاصطناعي.
2. خرائط الموقع وhreflang: الخريطة الدلالية التي يقرأها الذكاء الاصطناعي
خريطة الموقع التقليدية هي قائمة عناوين URL. خريطة موقع عصر GEO هي خريطة دلالية.
<url>
<loc>https://www.parkjunwoo.com/opinion/reins-engineering/</loc>
<lastmod>2026-05-27</lastmod>
<changefreq>weekly</changefreq>
</url>
بالإضافة إلى ذلك:
- روابط hreflang: 12 نسخة لغوية من نفس المقال مترابطة. الذكاء الاصطناعي يقدّر بشدة السلطة متعددة اللغات
- دقة lastmod: 76.4% من استشهادات الذكاء الاصطناعي تأتي من صفحات محدّثة خلال آخر 30 يوماً. المحتوى الأقل من 3 أشهر يُستشهد به 3 أضعاف. تزوير lastmod يأتي بنتائج عكسية
- هيكل الفئات:
/opinion/،/tech/،/lecture/— التسلسل الهرمي ذو المعنى يعطي الذكاء الاصطناعي سياقاً أكثر من البنية المسطحة
تقديم خريطة الموقع إلى Google Search Console أمر أساسي. لكنه وحده لا يكفي.
3. Wayback Machine وGoogle Search Console: إثبات أصالة المحتوى
يحفظ Wayback Machine لقطات الويب منذ عام 1996. بالنسبة للذكاء الاصطناعي، هذه ذاكرة زمنية.
لماذا يهم:
- إذا نشرت مقالاً يعرّف “Ratchet Pattern” لأول مرة في مايو 2026، يحتفظ Wayback Machine بتلك اللقطة
- حتى لو استخدم شخص ما نفس المفهوم بعد 6 أشهر على منصة أكبر، الدليل الزمني يشير إلى المؤلف الأصلي
- عندما يحدد الذكاء الاصطناعي المصدر، يعمل وقت النشر الأول كإشارة سلطة غير مباشرة
التنفيذ:
- بعد نشر مقال جديد، أرسل طلب حفظ يدوي إلى Wayback Machine (
web.archive.org/save/) - اطلب فهرسة عنوان URL في Google Search Console
- يُختم كلا الموقعين بالطابع الزمني
ملاحظة: حتى عام 2026، حظر 241 موقعاً الوصول إلى Wayback Machine (بسبب مخاوف من تحايل شركات الذكاء الاصطناعي على حقوق النشر). بالنسبة للمدونات الشخصية، هذه في الواقع فرصة — مع انسحاب الوسائط الكبيرة من الأرشيف، يرتفع الوزن النسبي للمحتوى الشخصي.
4. الاستشهاد بالمصادر والسلطة الموضوعية: شروط المحتوى الذي تثق به LLM
أعلى 3 استراتيجيات لتحسين الظهور وفقاً لورقة GEO الأصلية (Aggarwal et al., KDD 2024):
| الاستراتيجية | تحسين الظهور |
|---|---|
| إضافة اقتباسات (Quotation) | +41% |
| إضافة إحصائيات (Statistics) | +32% |
| ذكر المصادر (Cite Sources) | +30% |
حشو الكلمات المفتاحية عديم الجدوى أو ضار في GEO. الذكاء الاصطناعي لا ينظر إلى الكلمات المفتاحية بل إلى الأدلة.
لماذا الاستشهاد بالأوراق البحثية مهم:
- الذكاء الاصطناعي يميّز بين “الادعاء” و"الادعاء المدعوم بدليل". “42% من وقت المطورين يُستهلك في الديون التقنية” ادعاء. “42% من وقت المطورين يُستهلك في الديون التقنية (Stripe, The Developer Coefficient, 2018)” دليل
- الجمل المدعومة بأدلة لها تكلفة ثقة أقل عندما يستشهد بها الذكاء الاصطناعي في إجاباته. الجمل بدون أدلة تحتاج تحققاً فيتخطاها الذكاء الاصطناعي
- المواقع المُستشهد بها في 4 منصات ذكاء اصطناعي أو أكثر تظهر في ChatGPT بمعدل 2.8 ضعف
إدارة المقالات ذات الصلة والوسوم:
الوسوم ليست للناس. إنها للذكاء الاصطناعي.
- نظام وسوم متسق: “Reins Engineering” و"Ratchet Pattern" و"SSOT" — عندما تتكرر نفس الوسوم عبر عدة مقالات، يتعرف الذكاء الاصطناعي على السلطة الموضوعية (topical authority)
- روابط داخلية: ربط المقالات ذات الصلة داخل النص يمكّن زواحف الذكاء الاصطناعي من تحديد العناقيد الموضوعية. المقالات المترابطة تُستشهد بها أكثر من المعزولة
- استشهاد متبادل: الاستشهاد بين مقالاتك فعّال أيضاً. “أساس هذا المفهوم عُرّف في Ratchet Pattern”
5. X وReddit وHacker News: استراتيجيات اجتماعية لبناء حجم البحث عن العلامة التجارية
شروط استخدام X/Twitter تمنع صراحةً تدريب الذكاء الاصطناعي من طرف ثالث. أي أن ما تنشره على X لا يدخل مباشرةً في بيانات تدريب ChatGPT.
لكن النشاط الاجتماعي يساهم في الظهور أمام الذكاء الاصطناعي عبر مسار غير مباشر:
حجم البحث عن العلامة التجارية هو أقوى مؤشر لاستشهاد LLM (معامل ارتباط 0.334، أعلى من الروابط الخلفية).
المسار هكذا:
سلسلة تغريدات على X → الناس يبحثون عن "yongol" في Google → ارتفاع حجم البحث عن العلامة التجارية → الذكاء الاصطناعي يتعرف على "yongol" ككيان يستحق الاستشهاد
بيانات مايو لموقع parkjunwoo.com تثبت ذلك فعلياً:
- بحث “yongol” في Google: 14 ظهور، 5 نقرات، متوسط ترتيب 3.1
- استنساخ yongol على GitHub: 316 مستخدم فريد
- مسار الزيارات: t.co (X) 4 أشخاص → GitHub → المدونة
بدلاً من مشاركة الروابط مباشرةً على X، جعل الناس يبحثون عن المفهوم أكثر فعالية لـ GEO.
قوة earned media:
48% من جميع استشهادات LLM تأتي من earned media (صحافة، مراجعات، إشارات طرف ثالث). المحتوى الخاص يمثل 23% فقط. أي أن جعل الآخرين يذكرونك أكثر فعالية بمرتين من تحسين مقالاتك الخاصة.
عندما يُذكر مشروعك في Reddit أو Hacker News أو dev.to → عبر زحف الذكاء الاصطناعي لتلك المنصات → يتعلم LLM الكيان.
قائمة التحقق
البنية التحتية
├── موقع Hugo ثابت + S3 + CloudFront
├── السماح لزواحف الذكاء الاصطناعي في robots.txt
├── إنشاء llms.txt (تنظيم المحتوى الأساسي)
├── Schema.org JSON-LD (Article, Person)
└── خريطة موقع XML + hreflang
المحتوى
├── ذكر المصادر في كل ادعاء (+30% ظهور)
├── إدراج إحصائيات مضمّنة (+32%)
├── استخدام جداول المقارنة (الأمثل لتحليل الذكاء الاصطناعي)
├── الحفاظ على دقة lastmod (تحديث خلال 30 يوماً → معدل استشهاد 76.4%)
└── تحديث دوري للمقالات الأقدم من 3 أشهر (3 أضعاف احتمال الاستشهاد)
الربط
├── نظام وسوم متسق (سلطة موضوعية)
├── روابط داخلية (عناقيد موضوعية)
├── استشهاد بأوراق بحثية/مصادر خارجية (تقليل تكلفة الثقة)
└── مقال جديد → Wayback Machine + تقديم GSC
اجتماعي
├── سلاسل تغريدات على X لتحفيز البحث عن المفهوم (حجم البحث عن العلامة التجارية)
├── توليد earned media في Reddit/HN
└── نشر المفاهيم أفضل لـ GEO من مشاركة الروابط المباشرة
تطبيق GEO على هذا الموقع
الاستراتيجيات الموضحة في هذا المقال تُنفَّذ فعلياً على parkjunwoo.com:
- robots.txt — سماح صريح لـ 25 زاحف ذكاء اصطناعي، وحظر Bytespider
- llms.txt — تنظيم المحتوى الأساسي بما يناسب نافذة سياق الذكاء الاصطناعي
- مجموعة مقالات Reins Engineering — مركز العنقود الموضوعي
- بناء متعدد اللغات بـ 12 لغة — توليد تلقائي لـ hreflang، نقطة دخول لكل لغة
- مصادر بحثية في جميع المقالات — إحصائيات مضمّنة + استشهادات أكاديمية لضمان كثافة الحقائق
- تقديم فوري إلى Wayback Machine + GSC عند النشر — إثبات زمني للأصالة
مقالات ذات صلة
- Google, Optimizing your website for generative AI features on Google Search (2026) — دليل Google الرسمي لتحسين بحث الذكاء الاصطناعي
- Cyrus Shepard, AI Citation Ranking Factors Analysis — تحليل تلوي لـ 54 دراسة، قياس كمي لـ 23 عامل ترتيب استشهاد ذكاء اصطناعي
- Seer Interactive, AIO Impact on Google CTR: 2026 Update — 53 علامة تجارية، تتبع 2.43 مليار ظهور. CTR -61% مع AI Overview
- Discovered Labs, AI Citation Patterns: How ChatGPT, Claude, and Perplexity Choose Sources — 12% فقط من استشهادات الذكاء الاصطناعي تتطابق مع أفضل 10 في Google
- Ahrefs, Generative Engine Optimization: Growth Strategies and Metrics — تحليل 300 ألف كلمة مفتاحية. الإشارات على الويب تتفوق على الروابط الخلفية 3:1 في ظهور AI Overview
- Datos/SparkToro, State of Search Q1 2026 — تتبع حصة بحث الذكاء الاصطناعي بناءً على تدفق النقرات
- Rand Fishkin, Search Happens Everywhere — تحليل 41 موقعاً، البحث ليس فقط في Google
- Go Fish Digital, GEO Case Study: 3X’ing Leads — معدل تحويل إحالات الذكاء الاصطناعي أعلى 25 ضعفاً من البحث التقليدي
- Search Engine Land, How schema markup fits into AI search — تحليل واقعي لترميز المخططات وبحث الذكاء الاصطناعي
- Lily Ray, The Vicious Cycle of SEO — تحذير من العمر القصير لسبام GEO
المصادر
أوراق بحثية
- Aggarwal et al., GEO: Generative Engine Optimization, KDD 2024 — اقتباسات +41%، إحصائيات +32%، ذكر المصادر +30% تحسين ظهور
- Xu et al., Measuring Google AI Overviews (2026) — تحليل 55,393 استعلام. 30% من نطاقات AIO المُستشهد بها ليست في الصفحة الأولى العضوية
- Fang et al., Recency Bias in LLM-Based Reranking, SIGIR-AP 2025 — 7 نماذج تُرقّي باستمرار المحتوى الأحدث
- Zhang et al., Citation Selection to Citation Absorption (2026) — مقارنة كمية لأنماط استشهاد ChatGPT/Google AIO/Perplexity
- Algaba et al., LLMs Reflect Human Citation Patterns, NAACL 2025 — LLM تفضل بقوة أكبر الأوراق ذات الاستشهادات العالية (Matthew effect)
- arXiv:2602.18455, AI Search Impact on Wikipedia Traffic (2026) — AIO خفّض زيارات Wikipedia بنسبة 15% (تحليل سببي DID)
- Yu et al., Structural Feature Engineering for GEO (2026) — بنية المحتوى نفسها تؤثر على احتمال الاستشهاد
- Tian et al., Diagnosing Citation Failures in GEO (2026) — تعديل 5% من المحتوى يحسّن معدل الاستشهاد بنسبة 40%
- Baack, Critical Analysis of Common Crawl, FAccT 2024 — المكونات الأساسية والتحيزات في بيانات تدريب LLM
- Strauss et al., The Attribution Crisis in LLM Search (2025) — 92% من Gemini لا تقدم استشهادات قابلة للنقر
تقارير البيانات
- Ahrefs, Do AI Assistants Prefer Fresh Content? (2025) — تحليل 17 مليون استشهاد ذكاء اصطناعي
- SparkToro/Datos, State of Search Q1 2026 — تتبع حصة بحث الذكاء الاصطناعي بناءً على تدفق النقرات
- GitClear, AI Copilot Code Quality 2025 — تحليل 210 مليون سطر
- Gartner — توقع انخفاض حجم البحث التقليدي بنسبة 25% بحلول 2026
- معيار llms.txt المقترح — Search Engine Land
سجل التغييرات
- 2026-05-27: الإصدار الأول